基于SMART技术的片上网络低功耗策略P-SMART
2016-08-01董德尊
李 彬 董德尊 吴 际 夏 军
(国防科学技术大学计算机学院 长沙 410073)
基于SMART技术的片上网络低功耗策略P-SMART
李彬董德尊吴际夏军
(国防科学技术大学计算机学院长沙410073)
(xtlil3@163.com)
摘要片上网络(network-on-chip, NoC)消耗的功耗在整个芯片中所占比例不断增大,并且随着芯片工艺精度的提升和工作电压的不断降低,静态功耗占片上网络总功耗的比例也越来越大.当前芯片设计者致力于将未被使用的核设置为休眠状态来降低功耗.然而,即便是最前沿的芯片设计,当核休眠时与它连接的路由器都是保持在正常状态来进行报文传输.而与休眠核相连的片上网络路由器由于没有注入和吸收的报文,负载相对较低.在SMART(single-cycle multi-hop asynchronous repeated traversal)片上网络中,报文能够单周期从源路由器到目标路由器.基于单周期多跳旁路(SMART)技术,提出一种关闭低负载路由器虚通道的策略P-SMART,以在不影响网络性能的情况下节省片上网络功耗.实验结果表明:相对于SMART技术,P-SMART的性能损失不超过2%,而功耗节省13.4%.
关键词片上互连网络;功耗;旁路;延迟;虚通道
片上多核处理器成为越来越主流的硬件体系结构.片上网络(network-on-chip, NoC)作为片上多核系统的通信结构,能够为片上多核体系结构提供更高的通信带宽、更好的可扩展性.
片上网络消耗着很大比例的片上功耗.例如,在所有核满负荷工作时,Intel的 80-core chip[1]和MIT的 RAW chip[2]上的互连网络分别消耗了片上总功耗的 28%和36%.在核使用率较低的情况下,互连网络消耗的功耗比例更大.同时随着工艺精度的提升和工作电压的降低,静态功耗占总功耗的比例也在不断变大.根据IDC的研究[3],服务器中核的使用率只有10%~15%.在低利用率下,静态功耗占互连网络总功耗的比例预计会更大.
由于功耗已经成为高性能处理器设计的约束条件[4],设计高能效的片上互连网络变得十分重要.有研究提出以关闭与休眠核连接的片上网络路由器的方法减小片上网络静态功耗[5].这种方法可以选择将部分路由器完全关闭,能够较好地降低片上网络功耗.在片上网络路由器中,缓存消耗的功耗又占了整个路由器的很大一部分.有很多研究致力于降低路由器中的缓存[6-7],实现无缓存路由器.研究表明无缓存路由器相对于传统的有缓存路由器最多能够节省39%的片上网络功耗[8].但在这些无缓存设计中,报文出现竞争时竞争失败的报文被丢弃或是发生偏转,带来更大的时间和功耗开销.
不论是关闭路由器[9]、关闭路由器中的部件[10-11],还是无缓存路由器[12-15]都将减少网络中的可用资源,报文在网络中的延迟都将受到影响.降低功耗的同时性能也有降低,而更高的网络延迟会增加传输报文消耗的功耗.文献[16]提出了一种基于Mesh网络的单周期多跳异步中继传输网络SMART(single-cycle multi-hop asynchronous repeated traversal),报文能够一跳穿过路由路径中的多个路由器,减少了跳步数.跳步数的减少,相应的动态功耗也随之下降.
本文基于SMART网络,提出关闭相应路由器中输入虚通道的策略P-SMART来降低功耗.当计算核进入休眠状态时,与其相连的路由器没有注入和吸收报文,缓存使用率相对较低.关闭这些路由器输入端口的部分输入缓存以及注入端口的输入缓存,可以降低静态功耗.但是单纯的关闭虚通道会影响虚通道分配,SMART的运用,使得关闭部分虚通道,不会对后续的分配造成影响,所以我们将关闭虚通道与SMART结合起来,在低负载情况下既可以降低网络延迟,又能够节省网络功耗.
实验结果表明:在低负载情况下,P-SMART策略相对于现有的SMART技术,平均网络性能损耗不超过2%,而功耗平均节省了16.8%.
1SMART
SMART策略的核心思想是在路由器中加入旁路以及异步中继器,报文进入路由器后可以直接通过旁路穿过交叉开关离开路由器.增加异步中继器是减小线延迟的标准方法,路由器输出端口的中继器为报文创建虚拟的单周期多跳通路提供可能.在SMART网络中,同一维中的任意2个路由器之间都可以建立虚多跳通道.SMART路由器增加了3个控制位:写缓存(buffer write enable,BW),在每个输入端口确定是否锁存输入信号;旁路多路器选择(bypass mux select,BM),在每个交叉开关输入端,用来确定选择本地被缓存的报文还是旁路的报文;交叉开关选择(crossbar select,XB).SMART路由器的结构如图1所示:
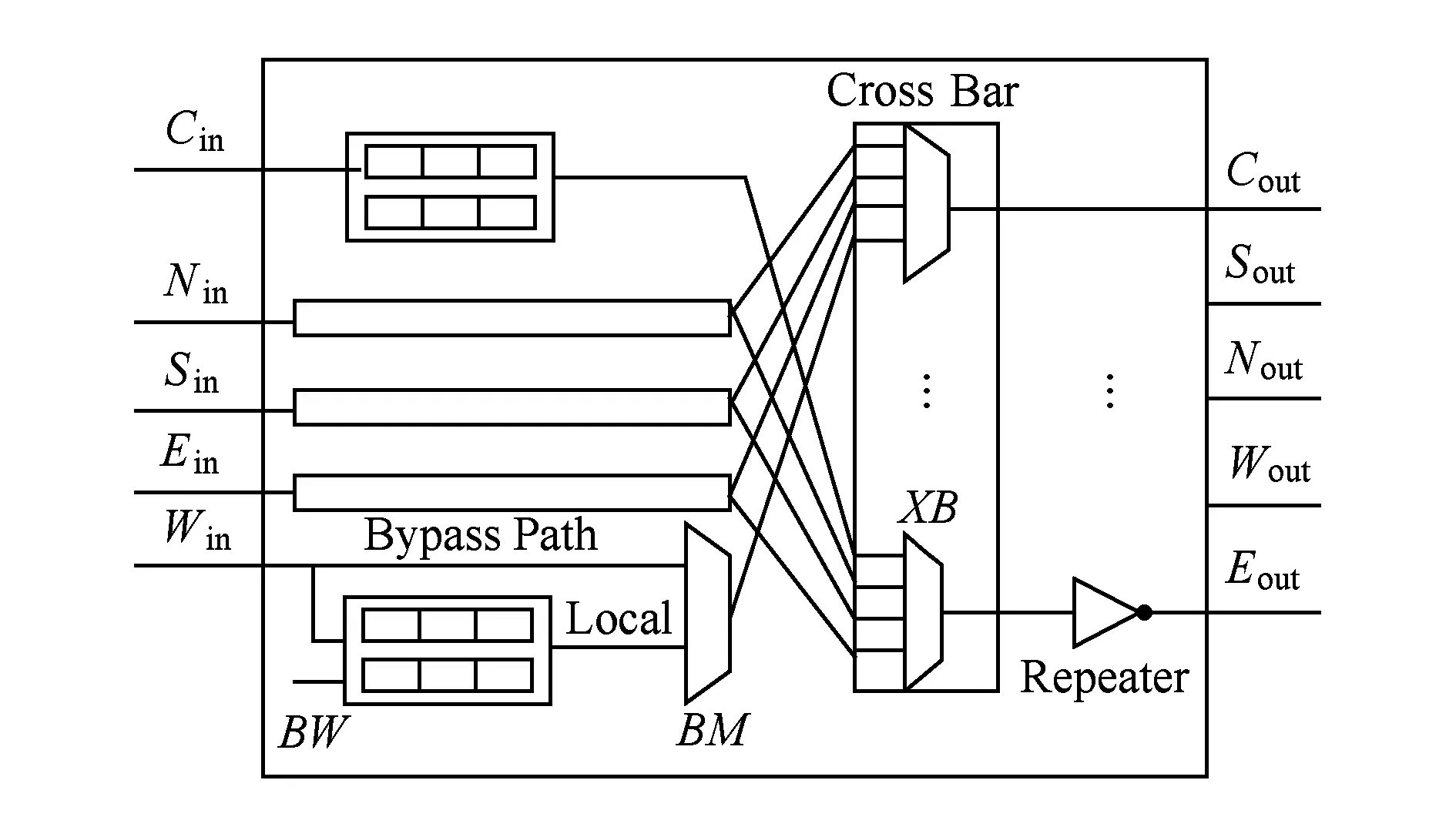
Fig. 1 SMART bypass router architecture.图1 SMART旁路由器体系结构
在SMART网络中,报文在同一个周期内申请多跳路由器和链路资源.它的实现方法是,报文在本地开关分配中获得输出端口之后,广播一个旁路建立请求信号(SMART-hop setup request, SSR),发给当前路由器输出端口下游的所有路由器,SSR携带着报文将要传输的跳步数信息.增加全局开关仲裁(switch allocation global, SA-G),在收到的多个SSR旁路请求和本地报文请求之间,根据优先级进行仲裁,通过仲裁结果设置3个控制信号:BW,BM和XB.SA-G仲裁确保路由器交叉开关的任意一个输入输出端只有一个报文被允许通过,将BW置为1就可以使冲突的报文缓存下来.单周期多跳通道是投机地建立,当报文的旁路请求总是不成功,像在传统网络中一样一跳一跳地传输.在一个报文特定的多跳传输中,所有路由器中的旁路请求是以分布式的方式在单周期内同时仲裁.这就需要确保报文被锁存在正确的路由器中,这是通过在路由器中设置相同优先级来实现.在SMART网络中,报文能够沿着同一维方向建立单周期任意跳数的通道,在需要转维时停下来.
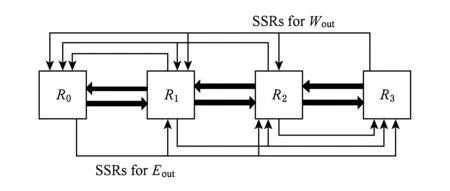
Fig. 2 SSR in SMART.图2 SMART中的SSR
2P-SMART策略
本文基于第1节所述的SMART路由器旁路策略,关闭与休眠核连接路由器中部分输入虚通道来降低片上网络功耗.目标是在较小的性能损失下降低片上网络的功耗.在SMART片上网络中,旁路是投机建立的.我们优先让本地路由器中的报文使用链路资源.当一个报文尝试建立多跳旁路时,如果中间路由器有本地报文与它冲突,旁路不成功,下次再申请多跳旁路,直到它到达同维上的目标路由器.与传统网络相比,SMART网络中报文的平均延迟低,同时虚通道的使用率也会低很多.
当负载较低时,片上系统将部分核置为休眠状态,片上网络中的报文较少.这种状态下,与休眠核连接的路由器不会被核注入报文,同时也不会有需要被核吸收的报文,路由器不会是任何一个报文的目标路由器.当一个报文被注入片上网络,进入源路由器,如果它在所有路由路径中旁路申请都成功,它就只需要使用路由路径中2个路由器的输入虚通道:转维路由器和目的路由器.部分报文不需转维,没有转维路由器,而且从路由算法的角度,考虑到Mesh中确定性维序路由,报文或者不转维,或者最多转维一次,所以目的路由器的比例要高于转维路由器.与休眠核连接的路由器仅作为旁路路由器或转维路由器,不会被核注入报文,注入端口中的输入虚通道不会被使用.
报文在网络中传输的路由路径可以分成2种情况:1)报文在同一维度上的传输,如图3中报文从R12到R15;2)报文需要转维,如图3中报文从R0到R11需要在R3转维.情况1中旁路成功时,报文只需使用到目的路由器的输入虚通道,而目的路由器只可能是与非休眠核连接的路由器;旁路不成功,需要进入路由路径中间的路由器的输入虚通道,由于与休眠核连接的路由器没有本地报文与旁路报文竞争,旁路报文不会停在与休眠核连接路由器的输入虚通道.所以在情况1下,只有与非休眠核连接的路由器输入虚通道被使用.情况2中旁路成功时,报文会进入目的路由器以及转维路由器的输入虚通道,转维路由器可能是与休眠核连接的路由器如R4,也可能是其他路由器如R3,但目的路由器也只能是与非休眠核连接的路由器;旁路不成功时,和情况1相同,报文只会停在与休眠核连接的路由器输入虚通道.
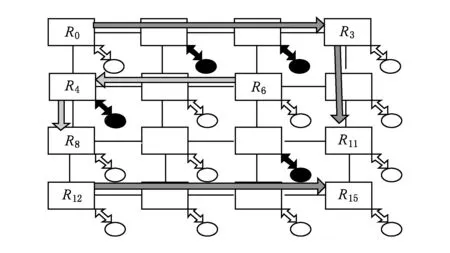
Fig. 3 Example of a single-cycle multi-hop path in core sleeping system.图3 在核休眠时的单周期多跳通道
与休眠核连接的路由器收到来自其他路由器中报文旁路的请求,不会有来自注入端的报文与它竞争输出端口,与在其他路由器中相比,没有核注入的报文竞争路由器输出端口.报文旁路不成功,进入休眠核连接路由器的输入缓存的几率比其他路由器小一些.综上,负载较低、部分核被置于休眠状态时,与休眠核连接的路由器中输入虚通道占用率要比其他路由器低,因此适当减少与休眠核连接路由器中的可用虚通道数量不会对报文在网络中的延迟产生较大影响.我们提出在基于SMART的Mesh网络中,关闭与休眠核连接的路由器中部分虚通道来减低片上网络功耗的方法P-SMART,对网络性能的影响不大.与文献[5]中提出的关闭部分休眠核连接路由器的方法比较,虽然只是关闭了部分虚通道,但目标路由器是所有与休眠核连接的路由器.缓存占整个路由器功耗的比例较大,关闭虚通道的方法能够获得较好的功耗节省效果.
P-SMART需要在原有的路由器体系结构上做一些改变.首先,核在被置为休眠状态后,需要通知与它连接的路由器,这些路由器再将输入端的部分虚通道关闭;然后就是怎样关闭以及关哪些虚通道.
我们将每个路由器中的输入虚通道分为2类:1)基本的虚通道;2)可以关闭的虚通道(图4中灰色部分虚通道),并在可关闭的虚通道前面加上一个开关,这个开关由核休眠信号控制.当核被置为休眠状态后,它就传输一个通知报文给路由器,路由器将可关闭的虚通道全部关掉.每个输入端口都配置一定比例的2类虚通道.由于核休眠后,不再往路由器注入报文,路由器注入端口全部为可关闭的虚通道.而在本文中将其他端口中的可关闭虚通道比例设置为0.5,并未探究最优的关停比例.而在休眠核被重新激活后,同样发送信号给路由器将虚通道激活.在关闭与休眠核连接路由器中的可关闭虚通道后,路由器之间的虚通道数目出现差异.这在传统路由器网络中,会给虚通道分配带来一定的麻烦,但在单周期多跳旁路的网络中并没有影响.在传统的路由器中,虚通道分配是给报文在相邻的下级路由器选择一个空的虚通道.而在SMART旁路网络中,报文从源路由器发出后可能停在路由路径中的任意一个路由器的输入虚通道,传统的虚通道分配无效,所以在虚通道分配阶段,只要下级路由器有空,虚通道就分配成功.在到达它需要停的路由器后,再选择进入哪个虚通道,所以虚通道数目的差异不会给虚通道分配带来影响.在原有的SMART的基础上,只需要增加比较简单的开关,就能够实现关闭与休眠核连接路由器中部分输入虚通道的功能.
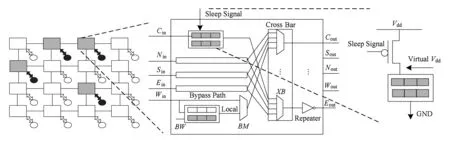
Fig. 4 power-gate virtual channel.图4 关停虚通道
3实验评估
本节对P-SMART进行实验评估.我们在片上网络模拟器Booksim2.0中模拟实现本文中提出的设计.Booksim2.0是基于周期flit(切片)级建模的模拟器,是当前比较主流的片上网络模拟器.实验用到3种片上网络:基本路由器网络、SMART和P-SMART.实验评测对象为64核8×8 mesh拓扑结构,baseline中实验配置为:每个输入端口8个输入虚通道,虚通道深度为1个切片,路由器为4周期流水,链路延迟为1个周期.SMART和P-SMART配置相同.在3种流量模式(Uniform random,Trans-pose,Bit-complement)下测试网络性能.路由算法为DOR(dimension order routing).在SMART中,每个虚通道中的缓存资源是私有的,也就是只给一个报文使用,虚通道的深度只需要报文最大报文数量,虚通道深度设为一个报文.在每个路由器中,与处理核连接的注入端口虚通道关停比例为100%,其他端口比例为50%.P-SMART中,除注入端口外的4个端口的可关闭虚通道比例设置为12,核休眠的比例是18,14或12. 3种网络路由器的其他配置均相同.图5所示为SMART和P-SMART性能比较.如图6所示,图6(a)(b)(c)中最上面的图给出的是核休眠比例为18时不同路由器结构在不同流量模式下的性能图.2种旁路路由器低注入率下的延迟较基本路由器低;而P-SMART相对SMART延迟增加不明显,只是饱和吞吐率下降.而在实际片上系统中,当负载较低、片上网络流量较少时,才会将核休眠.我们只在较低注入率下(低于0.14)比较它们的性能,在核休眠比例为14和12时显示出相近的结果.
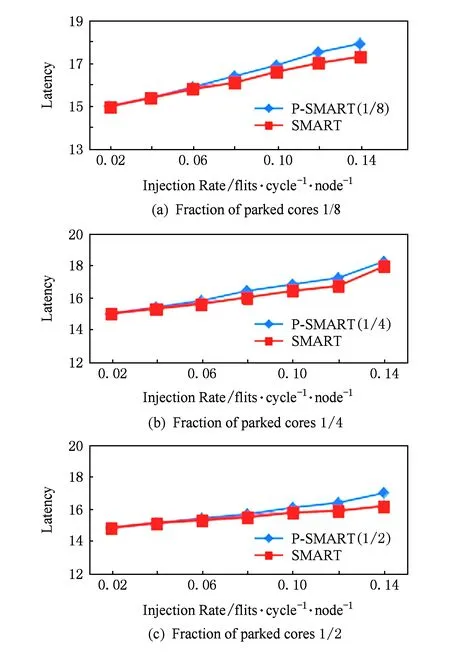
Fig. 5 Performance evaluation results under uniform traffic patterns.图5 uniform流量模式下性能评测结果
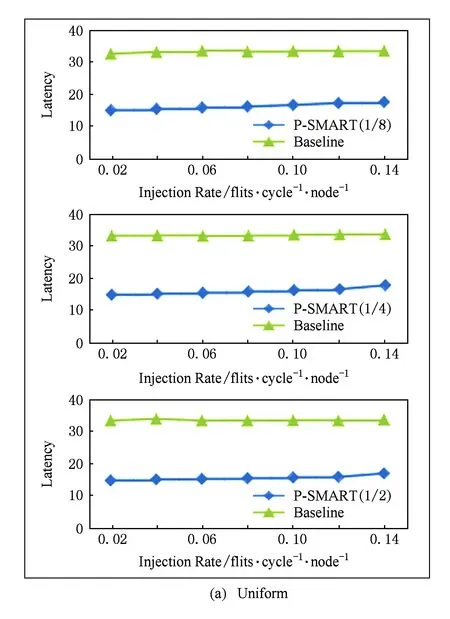
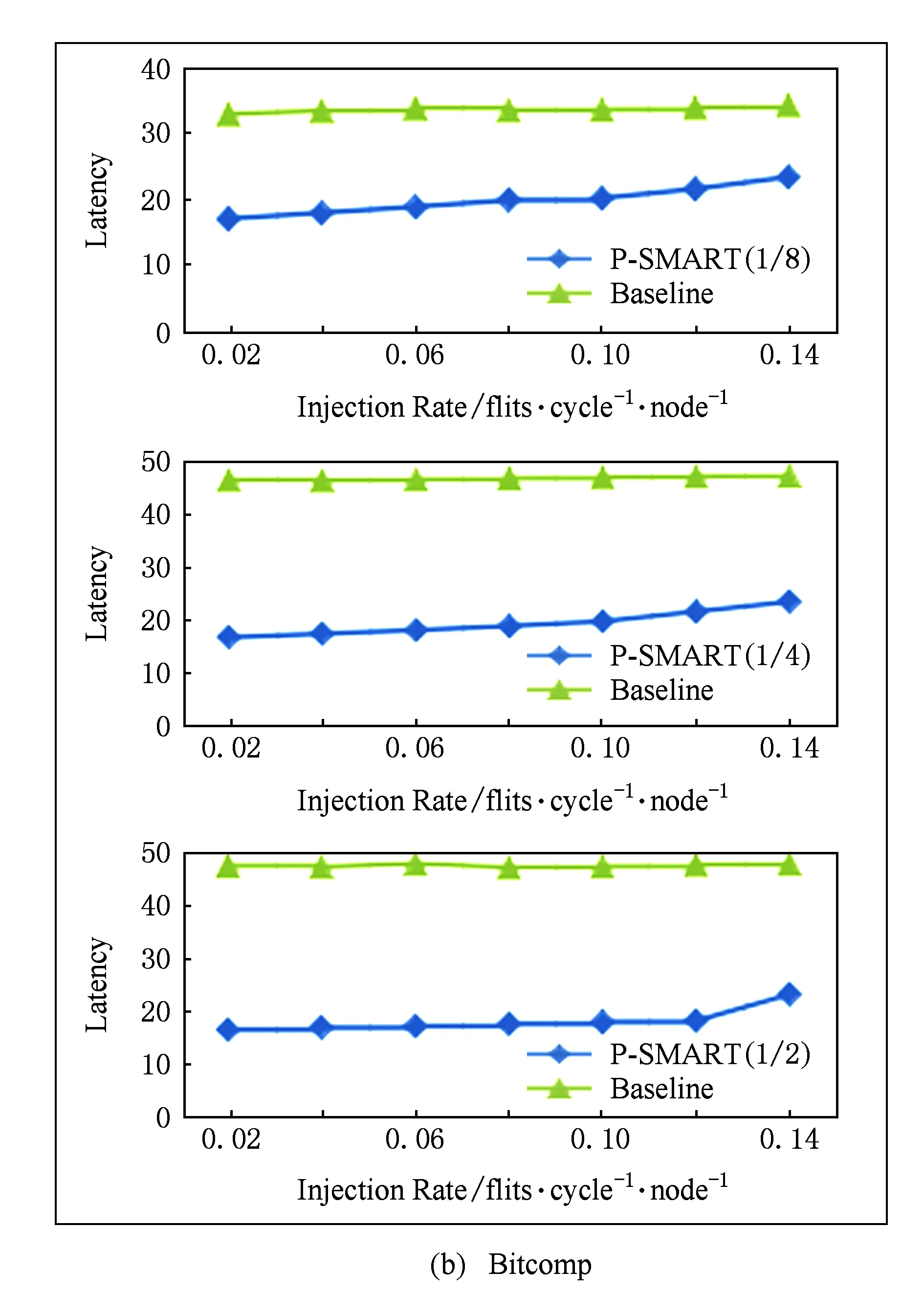
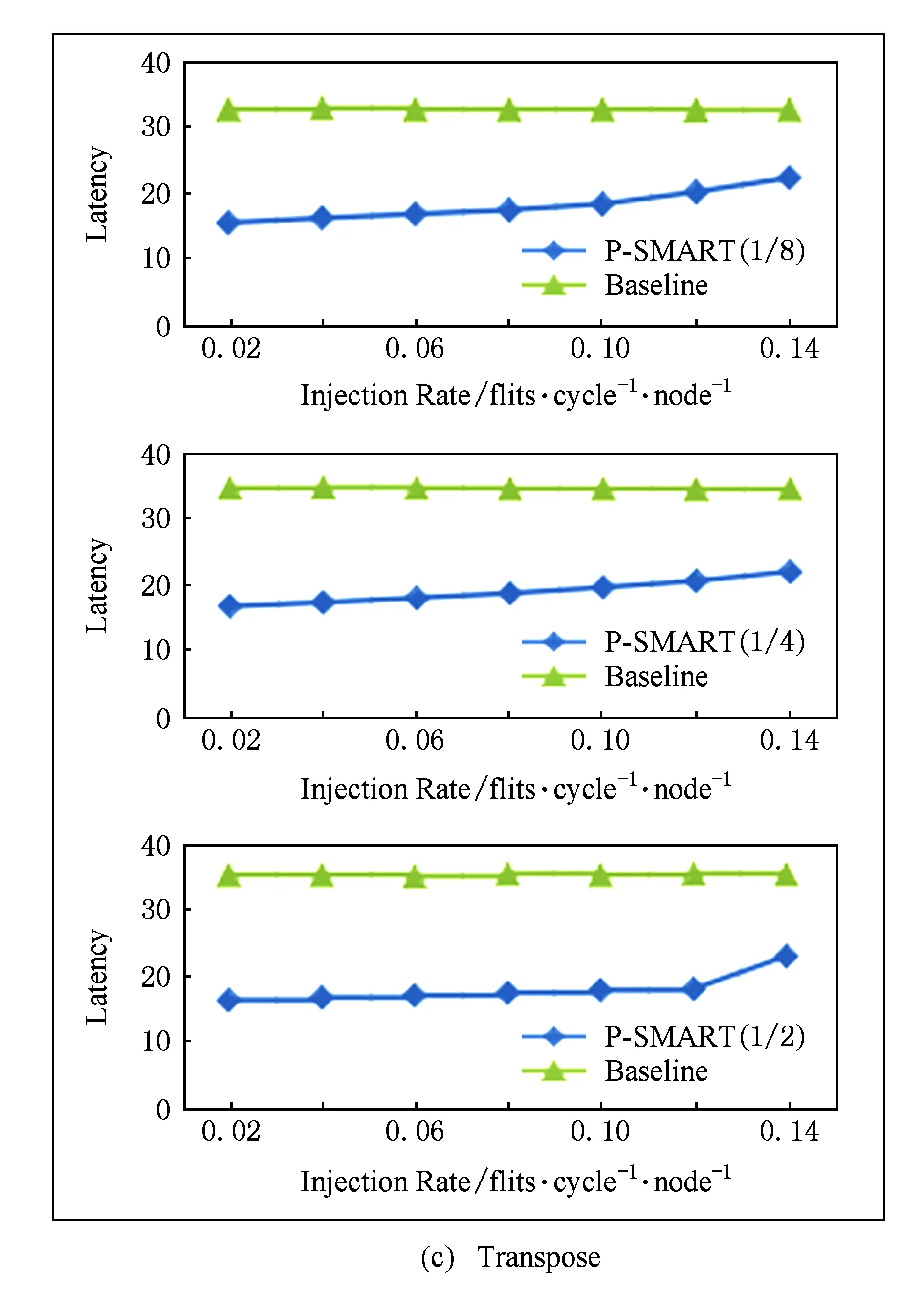
Fig. 6 Performance evaluation results under synthetic loads.图6 合成负载下性能评测结果
我们用Dsent对合成负载的网络功耗进行评测.只对P-SMART和SMART进行比较.图7显示的是在不同的核休眠比例下,动态功耗以及总功耗随着注入率增加的变化情况,流量模式为uniform.在注入率低于0.12时,核休眠的比例为18,14,12,总功耗分别降低8.7%,13.4%,28.2%.
4总结
本文提出在单周期多跳旁路片上网络中,关闭与休眠核连接的路由器中部分输入虚通道,减少路由器中缓存功耗.我们分析得出,在旁路片上网络中,当部分路由器连接的核被置为休眠状态时,它们的输入虚通道使用率会比普通的路由器低许多.而在片上网络路由器中,缓存消耗的能量占整个路由器消耗能量的比例比较大.我们将这部分路由器中的部分输入缓存关闭,减小路由器消耗的功耗,对网络性能的影响不大.本文主要研究片上网络低功耗,片上网络中基于合成负载的模拟实验是一般性的研究方法,我们用不同流量模式的综合负载进行实验评测.实验结果表明:休眠核比例分别为18,14,12,在注入率低于0.12时,3种不同的流量模式下关闭虚通道增加的网络延迟基本都低于2%,片上网络总功耗分别降低8.7%,13.4%,28.2%.对于缓存消耗功耗比例较大的片上网络路由器,能够得到可观的能效收益,相对来说网络性能的降低并不明显.
参考文献
[1]Intel Corporation. Teraflops Research Chip[EBOL]. 2007 [2016-03-01]. https:www.intel.com
[2]Kim J S, Taylor M B, Miller J, et al. Energy characterization of a tiled architecture processor with on-chip networks[C]Proc of the ISLPED’03. New York: ACM, 2003: 424-427
[3]IDC. Future of Virtualization[EBOL]. 2007 [2016-03-01]. http:www.vmware.comfilespdfanalystsFuture-of-virtuali-zationIDC.pdf
[4]Gowan M K, Biro L, Jackson D. Power considerations in the design of the Alpha 21264 microprocessor[C]Proc of the 35th Design Automation Conf (DAC). New York: ACM, 2003: 726-731
[5]Samih A, Ren W, Krishna A, et al. Energy-efficient interconnect via router parking[C]Proc of the 19th Int Symp on High Performance Computer Architecture (HPCA). Los Alamitos, CA: IEEE Computer Society, 2013: 8-19
[6]Gómez C, Gómez M E, López P, et al. Reducing packet dropping in a bufferless NoC[C]Proc of the 14th Int Euro-Par Conf on Parallel Processing. Berlin: Springer, 2008: 899-909
[7]Moscibroda T, Mutlu O. A case for bufferless routing in on-chip networks[C]Proc of the 36th Annual Int Symp on Computer Architecture. New York: ACM, 2003: 424-427
[8]Jiang N, Becker D U, Michelogiannakis G, et al. A detailed and flexible cycle-accurate network-on-chip simulator[C]Proc of Performance Analysis of Systems and Software. New York: ACM, 2013: 86-96
[9]Dally W, Towles B. Principles and Practices of Inter-connection Networks[M]. San Francisco: Morgan Kaufmann, 2003
[10]Shang L, Peh L, Jha N K. Dynamic voltage scaling with links for power optimization of interconnection networks[C]Proc of the 9th Int Symp on High Performance Computer-Architecture (HPCA). Los Alamitos, CA: IEEE Computer Society, 2003: 91-102
[11]Borkar S. Thousand core chips: A technology perspective[C]Proc of the 44th Design Automation Conf (DAC). New York: ACM, 2007: 746-749
[12]Soteriou V, Peh L S. Exploring the design space of selfregulating power-aware onoff interconnection networks[J]. IEEE Trans on Parallel and Distributed Systems, 2007,18(3): 393-408
[13]Kim G, Kim J, Yoo S. Flexibuffer: Reducing leakage power in on-chip network routers[C]Proc of the 48th Design Automation Conf (DAC). New York: ACM, 2011: 936-941
[14]Moscibroda T, Mutlu O. A case for bufferless routing in on-chip networks[C]Proc of ISCA’09. New York: ACM, 2009: 8-19
[15]Matsutani H, Koibuchi M, Wang D, et al. Adding slowsilent virtual channels for low-power on-chip networks[C]Proc of NOC’09. New York: ACM, 2009: 23-32
[16]Krishna T, Chen C-H O, Kwon W C, et al. Breaking the on-chip latency barrier using SMART[C]Proc of the 19th Int Symp on High Performance Computer Architecture (HPCA). Los Alamitos, CA: IEEE Computer Society, 2013: 378-389

Li Bin, born in 1990. MS candidate. His main research interests include high performance interconnection network.

Dong Dezun, born in 1980. PhD, associate professor. Senior member of China Computer Federation. His main reseach interests include high performance inter-connection network.

Wu Ji, born in 1988. PhD candidate. His main reseach interests include high performance interconnection network.

Xia Jun, born in 1976. PhD, associate professor. Senior member of China Computer Federation. His main reseach interests include high parallel and distributed computing,and high performance computer systems.
收稿日期:2016-03-11;修回日期:2016-05-16
基金项目:国家自然科学基金项目(61272482);全国百篇优秀博士论文基金项目(201450);教育部高等学校博士学科点专项科研基金项目(20124307120026)
通信作者:董德尊(dong@nudt.edu.cn)
中图法分类号TP393
P-SMART: An Energy-Efficient NoC Router Based on SMART
Li Bin, Dong Dezun, Wu Ji, and Xia Jun
(CollegeofComputer,NationalUniversityofDefenseTechnology,Changsha410073)
AbstractAs the number of on-chip cores in chip multiprocessors (CMPs) increase, size of network-on-chips (NoCs) and network latency increase. NoCs consume an increasing fraction of the chip power as technology and voltage continue to scale down, and static power consumes a larger fraction of the total power. Currently, processor designers strive to send under-utilized cores into deep sleep states in order to improve overall energy efficiency. However, even in state-of-the-art CMP designs, when a core going to sleep the router attached to it remains active in order to continue packet forwarding. The router attached to a sleeping core has low traffic load, due to no packets to or from sleeping core. An on-chip network called SMART (single-cycle multi-hop asynchronous repeated traversal) that aims to present a single-cycle data-path all the way from the source to the destination. This paper, we propose reducing the VC(virtual channel) of router that is attached to sleeping core, based on SMART NoC, reducing power consumption and bringing little performance penalty. We evaluate our network using synthetic traffics. Our evaluation results show that VC power gating increases network latency less than 2% when the workload is low, and compared with no bypass path network, the power is reduced about 13.4%.
Key wordsnetwork-on-chip (NoC); power consumption; bypass path; latency; virtual channel
This work was supported by the National Natural Science Foundation of China (61272482), the Foundation for the Author of National Excellent Doctoral Dissertation of China (201450), and the Specialized Research Fund for the Doctoral Program of Higher Education of China (20124307120026).
