反蓄意模仿说话人识别系统中特征参数提取的研究*
2016-08-01唐宗渤王茂蓉刘继锦
唐宗渤, 周 萍,王茂蓉,刘继锦
(1.桂林电子科技大学 信息科技学院,广西 桂林 541004; 2.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004)
反蓄意模仿说话人识别系统中特征参数提取的研究*
唐宗渤1, 周萍2,王茂蓉2,刘继锦2
(1.桂林电子科技大学 信息科技学院,广西 桂林 541004; 2.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004)
摘要:当模仿者蓄意模仿说话人的语音且相似度极高时,说话人识别系统就有可能被欺骗。特征参数的提取是说话人识别的关键环节,直接影响了系统的识别性能。MFCC是语音识别中最热门的特征参数之一,但由于其只反映了语音的静态特性,为了提取更具个人语音特性的特征参数,引入加权MFCC,同时结合离散小波变换得到DWTWC,根据增减分量法,提出了DWI-MFCC。实验表明,DWI-MFCC倒谱系数比MFCC能更有效地区分语音的相似度。
关键词:特征参数; MFCC; 蓄意模仿; 增减分量法
引用格式:唐宗渤, 周萍,王茂蓉,等. 反蓄意模仿说话人识别系统中特征参数提取的研究[J].微型机与应用,2016,35(12):18-20.
0引言
生物认证技术[1]作为一种身份鉴别技术,它具有安全、方便等优点。但与其他生物特性相比,声音更容易被模仿,特别在蓄意模仿与目标说话人的语音相似度极高时,就给识别系统的鲁棒性带来严峻考验。有效的声学特征,可大大提高识别性能。常用的特征参数有基因频率、线性预测参数LPC、Mel频率倒谱系数[2]MFCC等。其中MFCC能充分模拟人耳的听觉感知特性,应用较多。但其只能体现语音的静态特征,为了提取更具个人特性的参数,本文对MFCC作加权处理,结合离散小波变换引进DWTWC,根据增减分量法,提出DWI-MFCC。实验表明,DWI-MFCC比传统MFCC更能区分语音的相似度,提高识别系统的鲁棒性。
1特征参数的提取
1.1Mel频率倒谱系数
MFCC[2]作为模拟人耳特殊感知能力的参数得到研究者的推崇。其实际频率f与Mel频率fMel之间的转换关系如式(1)所示,其中fMel的单位为Mel,f的单位为Hz。MFCC的提取过程如图1所示,其参数分布示例图如图2所示。
(1)

图1 MFCC参数提取流程图

图2 MFCC的参数分布示例图
由图2可知,随着维数的升高,MFCC变化幅度变小,升高到一定程度后,系统识别性不仅没有提高,反而增加了运算量。
1.2加权Mel频率倒谱系数
为了得到更具区分性的加权特征参数,本文采用升半正弦函数[3]进行加权,如式(2)所示:
r=0.5+0.5*sin(π*(i-1)/n)
(2)
其中i=1,2,…,n为维数,本文n=24,0.5是静态分量。为了更准确地体现不同说话人的个性特征差异[4],本文提出另一种加权函数如式(3)所示,得到改进的加权特征参数IWMFCC。
(3)
1.3DWTWC语音特征参数提取
在提取特征参数时,用离散小波变换代替傅里叶变换,用中频区域分布密集的Mid-Mel滤波器组[5-6]代替原来的滤波器, DWTWC参数的提取步骤如下:首先对语音信号进行预加重、分帧加窗等;接着用离散小波变换[7]对预处理后的信号进行处理,选择适当的小波基和分解层数对其分解,并计算小波系数;然后利用频谱的拼接把系数组成一组参数,求其能量;最后取对数,再经过DCT可得到相应的DWTWC。其提取过程如图3所示。

图3 DWTWC的提取流程图
与MFCC提取流程不同的是其前端处理采用离散小波变换[8],Mel滤波器换成了Mid-Mel滤波器组,有效补充了中频区域的语音信息。
2DWI-MFCC混合特征参数
为了提高识别率,需对MFCC、WMFCC、IMFCC和DWTWC进行融合,用增减分量法[9]对维度进行筛选,将对识别率贡献最大的n阶分量进行组合,得到新的混合特征参数,如式(4)所示:

(4)
其中,n为阶数,p(i,j)为从第i到第j阶的识别率,R(i)为第i阶分量平均贡献值,若其大于0,则对识别有贡献,反之则使识别率下降。文中仅顺序摒弃或增添特征分量[10]。由式(4)计算出各参数中对识别率贡献最大的特征分量,对其组合得到新的特征参数,即 DWI-MFCC。
3实验结果与分析
3.1不同特征参数欧氏距离排名对比
本文从专业配音网站提取语音库,采样频率为8 kHz,量化精度为16 bit。提取16阶MFCC,计算被模仿者与模仿者语音的MFCC和DWI-MFCC的欧氏距离,然后对其从小到大排序得到表1。

表1 MFCC和DWI-MFCC的欧氏距离排名
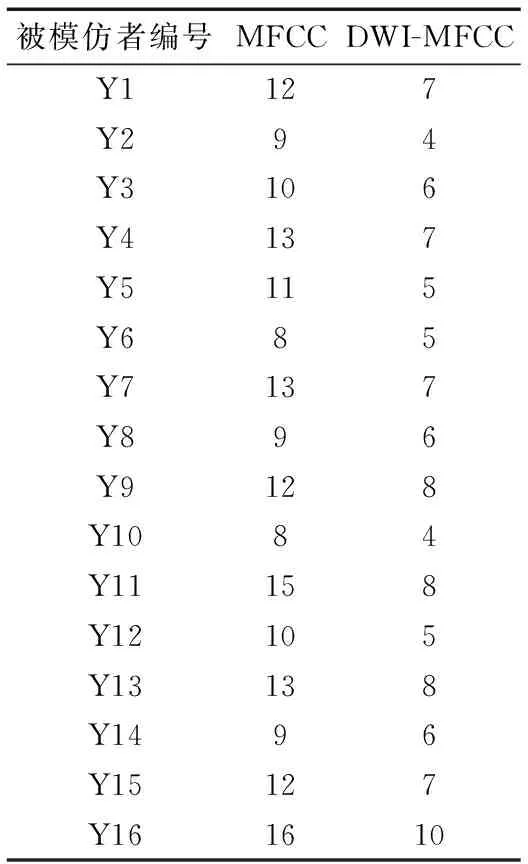
表2 不同的特征参数的错误
由表1可得,采用DWI-MFCC的原语音和模仿语音的排名一致性高达87.5%,证明 DWI-MFCC不但有效补充了MFCC在中频区域的语音信息,而且很好地体现了语音个性特征;而采用MFCC时,排名一致性只有43.75%,这是因为MFCC中只包含了语音的静态特性。综上,本文提出的DWI-MFCC对语音模仿的区分能力更强,能更有效区分出原语音和被模仿语音。
3.2不同特征参数实验结果的对比
为验证特征参数的语音模仿区分性能,建立基于SVM的蓄意模仿识别系统,首先选取80人模仿语音库中16位名人的声音。训练阶段,先提取目标说话人与待测试说话人的特征参数,将其分别记为“+1”类和“-1”类并用以训练出目标说话人的SVM模型。测试阶段,将待测试语音与目标说话人的模型进行匹配,再和预先设定的阈值进行比较。本文选取径向基函数作为SVM的核函数,惩罚系数为3,核函数参数为0.6。实验采用16阶的MFCC和DWI-MFCC分别作为样本建立SVM模型,对数据进行[0,1]归一化,计算出每个被模仿者使用不同特征参数时的错误接受率(FA),如表2所示,图4给出了两者的错误接受率的对比图。
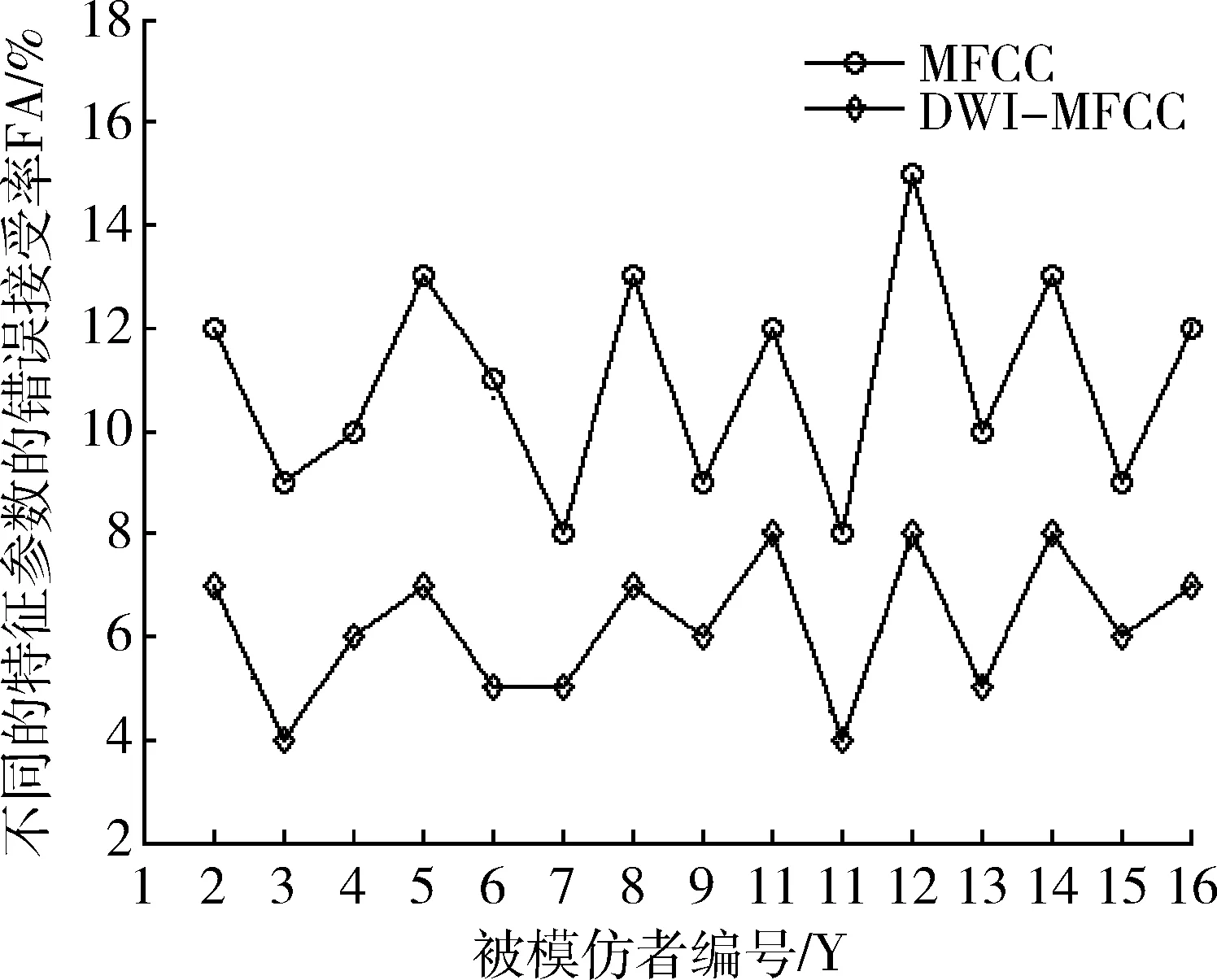
图4 采用不同特征参数的错误接受率(FA%)对比
从图4可知,MFCC的错误接受率曲线处于DWI-MFCC的曲线上方,即DWI-MFCC参数的错误接受率比MFCC参数的低,从而更有力地说明DWI-MFCC的区分性能比MFCC的要好。
4结论
本文通过对MFCC特征参数的分布分析,提出了加权MFCC,同时结合离散小波变换引入了DWTWC,根据增减分量法,提出了DWI-MFCC。从理论和实验两个方面对特征参数的有效性进行了分析,同时采用SVM对反蓄意模仿系统进行匹配分析。实验表明,本文提出的DWI-MFCC相比于传统的MFCC,对语音模仿的区分能力更强,有更好的识别性能。
参考文献
[1] 李建文,张晋平.基于改进语音特征提取方法的语音识别[J].微电子学与计算机,2009,26(7):230-233.
[2] 柯晶晶,周萍,景新幸,等.差分和加权Mel倒谱混合参数应用于说话人识别[J].微电子学与计算机,2014,31(9):89-91.
[3] 吴迪,曹洁,王进花.基于自适应高斯混合模型与静动态听觉特征融合的说话人识别[J].光学精密工程,2013,21(6):1598-1604.
[4] 陈明义,余伶俐,朱晗,等.基于特征参数融合的语音情感识别方法[J].微电子学与计算机,2006,23(12):168-171.
[5] 田永红. 一种优化的语音特征参数提取方法仿真[J]. 计算机仿真,2013,30(12):162-165.
[6] 吴丽芳. 语音转换系统中特征参数的研究[D].南京:南京邮电大学,2013.
[7] 杨阳,毛永毅,郑敏,等.基于小波变换的AOA定位算法[J].微型机与应用,2014,33(3):47-49,54.
[8] 胡沁春,何怡刚,何静,等.高斯类小波变换的开关电流频域法实现[J].电子技术应用,2014,40(1):44-46.
[9] 曹孝玉. 说话人识别中的特征参数提取研究[D].长沙:湖南大学,2012.
[10] 张璇. 基于Fisher准则的说话人识别特征参数提取研究[D].长沙:湖南大学,2013.
*基金项目:国家自然科学基金资助项目(61363005);国家自然科学基金资助项目(61462017);广西研究生教育创新计划资助项目(YCSZ2015152)
中图分类号:TP391.42
文献标识码:A
DOI:10.19358/j.issn.1674- 7720.2016.12.007
(收稿日期:2016-02-29)
作者简介:
唐宗渤(1986-),男,助理工程师,主要研究方向:语音信号处理与智能控制。
周萍(1961-),女,硕士,教授,主要研究方向:语音识别与智能控制研究。
王茂蓉(1990-),女,硕士研究生,主要研究方向:语音识别与反蓄意模仿。
Research of characteristic parameters extraction in speaker recognition system of anti-deliberate imitation
Tang Zongbo1, Zhou Ping2, Wang Maorong2, Liu Jijin2
(1.Department of Information Science and Technology, Guilin University of Electronic Technology, Guilin 541004, China;2.Department of Electric Engineering and Automation, Guilin University of Electronic Technology, Guilin 541004, China)
Abstract:When imitators deliberately imitate the speaker’s voice, and they have high similarity, speaker recognition system may be deceived. The extraction of feature parameters is key in speaker recognition, which directly affects the recognition performance. MFCC is one of the most popular feature parameters, but due to it only reflects static characteristics of voice, we introduce weighted MFCC to extract parameters of more individual voice. In combination with discrete wavelet transform, we introduce the DWTWC. According to increase or decrease in weight method, DWI-MFCC is proposed. The experimental result shows that the DWTWC is better than MFCC in distinguishing speech similarity.
Key words:feature parameter; MFCC; deliberate imitation; method of increasing or decreasing the component
