大数据应用部署研究
2016-08-01北京电信规划设计院有限公司工程师杨春丽北京电信规划设计院有限公司工程师马媛媛北京电信规划设计院有限公司工程师
张 亮 北京电信规划设计院有限公司工程师杨春丽 北京电信规划设计院有限公司工程师马媛媛 北京电信规划设计院有限公司工程师
大数据应用部署研究
张亮北京电信规划设计院有限公司工程师
杨春丽北京电信规划设计院有限公司工程师
马媛媛北京电信规划设计院有限公司工程师
摘要:分析在海量数据情况下,Hadoop各组件及其生态圈(如Impala、Spark)技术特点及应用场景;结合大数据平台通用架构,提出在数据采集、储算、应用等方面的功能架构及技术架构。
关键词:大数据;Spark;Impala;Hadoop
1 引言
本文主要研究以Hadoop2.0为基础大数据平台应用体系架构,根据数据特性,从功能架构、技术架构不同纬度来探讨如何搭建大数据平台,实现对海量数据的挖掘、分析及处理。
2 业务需求
面对海量数据的增加,传统数据仓库无法有效存储日益增长的业务数据,海量的数据导致了业务系统数据存储和处理的压力,而数据仓库无法线性扩容,将导致信息系统出现管理难度加大、成本高、扩容压力大、效率下降等问题。
(1)行业的发展趋势
微信、微博等OTT应用的广泛使用,互联网+的广泛应用,传统产业日益管道化,导致逐渐失去对用户和生态链的控制能力。
(2)技术发展趋势
现有技术瓶颈:现有数据库技术处理大数据存在瓶颈,无法对非结构化的数据进行处理,数据库无法进行横向扩展。
海量数据的分布式处理技术日趋成熟:随着海量数据的分布式处理技术的不断应用,使其稳定性、易用性不断提高,具备了大规模商用的条件。
(3)业务发展的需要
●市场发展:一方面满足精准营销的需要,一方面满足企业对数据分析的需要。
●管理分析:用户流失分析等。
●内部管理:投诉数据分析及其他相关数据分析。
3 大数据应用体系架构
大数据平台主要实现大数据平台数据的采集处理、存储及计算、数据分析挖掘模型的建立、大数据平台数据的对外服务的功能。以下分别从功能、技术架构等方面具体阐述。
3.1功能架构
大数据平台可以分为数据接口层、数据核心处理层、数据服务层及运营、运维管理,具体功能架构如图1所示。
3.1.1数据接口层
数据接口层用于提供平台的数据采集和处理能力。数据采集范围包括但不仅限于用户资料采集、网页内容采集、合作伙伴数据等。
(1)用户资料采集:用户基础信息、终端信息、投诉信息等采集。
(2)网页内容采集:互联网网站信息采集。
(3)合作伙伴数据:第三方合作伙伴信息采集。
数据处理包括ETL处理、预处理和数据加密及脱敏。
(1)ETL处理:实现数据抽取、数据校验、数据处理、数据装载等功能。
(2)预处理:提供数据排重、分拣、格式转换等功能。
(3)数据加密及脱敏:去除数据中的敏感信息,数据脱敏可以是数据加密、关键信息抹除等方式。
3.1.2数据核心处理层
数据核心处理层:用于提供海量数据的存储和计算能力。
(1)即时处理:提供本地SQL查询引擎,提供原始HDFS数据和HBase数据库的简单查询访问搜索引擎,实现全文索引和搜寻。
(2)批量数据处理:基于不同的业务场景提供数据的定时批量处理能力和实时批量处理能力。
(3)数据核查:自动实现数据清洗、数据稽核、生成数据质量报告;实现数据全生命周期的数据监控与数据稽核;配合完成各数据处理环节数据质量信息的采集并提供结果,实现端到端的透明化管理等。主要提供核查规则配置管理、核查规则调度、核查规则执行、数据质量问题处理、数据质量评估分析等功能。
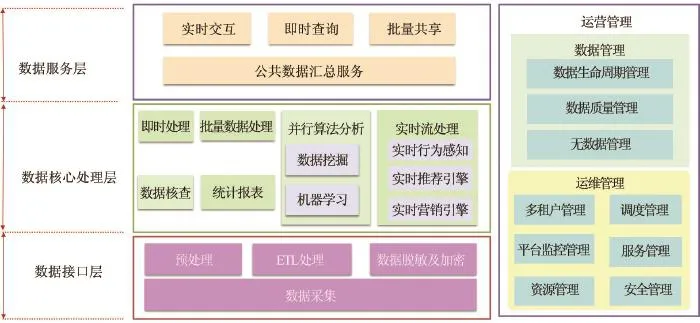
图1 总体功能架构图
(4)统计报表:根据报表目录和报表的配置要素,在统一的配置调度管理下,根据报表作业的相互关系,按时生成各类报表。主要提供报表生成配置、报表生成执行、报表生成监控等功能。
(5)并行算法分析
●数据挖掘:数据挖掘的能力主要包含了数据访问与准备、数据探索、建模分析算法、图形展现以及模型评估、模型发布等多项功能。
●机器学习:实现数据模型挖掘建立,数据分析算法探索,最终用于支撑上层应用。主要算法有贝叶斯、决策树、聚类等。
(6)实时流处理
●实时行为感知:基于客户偏好及行为习惯形成客户标签,同时通过收集捕获各种实时交互信息分析客户行为的价值所在,以客户的这些行为作为触点进行营销规则的制定和营销活动的策划。
●实时推荐引擎:主动发现用户当前或潜在的需求,为用户推荐其喜欢的商品或内容并主动推送信息给用户。
●实时营销引擎:主要负责包含数据的采集、营销矩阵数据生成、触发规则管理以及结合规则引擎对数据的处理。
3.1.3数据服务层
(1)公共数据汇总服务
负责对数据进行统一加工,生成汇聚层数据;对互联网数据进行处理,获取特定专题信息数据等。
(2)实时交互
提供实时单笔访问大数据中心的数据功能,主要包括查询、写入、更新、搜索等功能。
(3)即时查询
提供将数据以消息的方式实时推送的服务方式,主要包括单信息推送和信息流推送等。
(4)批量共享
提供实时/准实时/定时批量传输数据,主要包括批量数据抽取和批量数据导出功能。
3.1.4运营管理
运营管理是面向应用对数据、任务、资源、安全等进行全面管理,主要实现:
(1)大数据平台的集中管理
统一管理大数据平台的各种软硬件资源,确保安全、可靠、高效的运行。
(2)与应用的隔离
应用无需直接访问大数据平台底层的各项服务,即可实现应用的开发、测试、运行和维护
(3)多租户部署
实现应用的资源共享和逻辑隔离。
3.1.5数据管理
(1)数据生命周期管理:主要包括数据存储管理、数据处理流程管理、数据发布管理、数据归档管理等。
(2)数据质量管理:主要包括校验规则定义、数据质量验证及验证调度、数据质量问题处理等。
(3)元数据管理:通过获取大数据平台各环节的元数据信息,并进行集中的存储管理,为数据运维管理及使用人员提供统一的数据定义和标准,便于对数据的理解以及辅助数据管控和运维等。
3.1.6运维管理
(1)多租户管理:实现应用的资源共享和逻辑隔离。
(2)调度管理:调度管理提供定时、实时的作业触发功能,提供作业触发、服务触发功能,提供作业依赖检查机制,提供作业流程化调度能力;通过交互页面的方式提供人工触发的方式进行作业的调度。
(3)资源管理:提供相关资源配置信息管理、资源配置信息的展现、资源配置信息录入、资源配置信息变更、资源配置信息查询统计功能。对资源进行统一管理功能,通过数据配置的方式,对资源进行统一维护和管理。同时,在资源分配和使用上,能够通过多种方式对资源池中的资源进行灵活分配。
(4)平台监控管理:对各类资源系统、资源实例进行监控,记录监控信息供用户和管理员查看。
(5)服务管理:指服务管理员通过统一的、可视化的工具,将服务访问发布到大数据平台中,发布前需要提供指定平台的发布业务执行测试功能,测试通过后由服务管理员正式发布到运行平台。
(6)安全管理:通过IP控制、认证鉴权、服务安全处理等方式对服务访问过程中的安全进行统一管控。访问审计提供接入、访问、流程控制、优先级日志的记录及审计功能。
3.2技术架构
现有关系型数据库技术(如Oracle、Sybase等)无法对非结构化的数据进行处理,数据库无法进行横向扩展,只能依赖服务器性能增长进行纵向扩展,处理海量数据存在瓶颈。建议采用Hadoop2.0为核心及其生态圈技术来搭建处理海量数据的公共平台。
本文将根据Hadoop及其生态圈技术特性,分析其适用场景来搭建大数据公共平台。以下将从数据接口、数据核心处理、数据服务层来说明大数据公共平台的技术架构。
3.2.1数据接口层
数据接口层提供将数据采集到系统中和将数据提供给外部的能力,即首先数据能够进入系统,然后提供处理后数据。可以支持源头为关系数据库的全量、增量数据导入,支持源头为文件的数据导入,支持源头流数据的导入。可以将数据输出到关系数据库、文件或者流管道。
(1)结构化数据
针对源数据进行采集,可以选择使用Sqoop1或者DataX。Sqoop支持所有支持JDBC的数据库。DataX支持MySQL和Oracle的采集。
Sqoop是一个用来在关系型数据库和Hive、Hbase之间进行数据相互转移的工具,可以将一个关系型数据库中的数据导入到Hive、Hbase中,也可以将Hive、Hbase的数据导出到关系型数据库中。Sqoop、Datax也支持增量数据采集。
(2)非结构化数据
建议使用Flume来对文件数据进行采集。Flume是一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统。它可以定制各类数据发送方,用于收集数据。Flume可以将文件、流式数据复制到本系统的HDFS中进行保存。
3.2.2数据核心处理层
(1)HDFS
Hadoop实现了一个分布式文件系统(Hadoop DistributedFileSystem,HDFS)。HDFS是基于X86服务器和本地磁盘的分布式文件系统,它将大文件分割成大小为64MB的数据块在本地文件系统中进行存储。HDFS节点主要包括NameNode及DataNode。NameNode是整个文件系统的管理节点,维护文件系统的文件目录树、文件的元数据及数据块列表。DataNode提供文件数据的存储服务,对文件数据提供多副本服务,以保证系统的高容错性。
Hadoop具有高容错性、高吞吐量、大文件存储等特点,适用于非结构化数据大文件存储及流式数据访问,不适合大量小文件随机低延时读取。
(2)分布式计算MapReduce(M/R)
MapReduce用于大规模数据集(大于1TB)的并行运算,是典型的非实时并行计算模型。
MapReduce中作业(Job)是客户端执行的基本单位。MapReduce通过把作业分成若干个小任务(Task)来工作,主要包括两种类型的任务:Map和Reduce任务。
有两种类型的节点控制着作业执行的过程:Jobtracker和多个Tasktracker。Jobtracker通过调度任务在Tasktracker上运行来协调所有在系统上的作业。Tasktracker运行任务的同时,监视所在设备的资源情况及当前Task的运行状况,把进度报告传送到Jobtracker。Jobtracker记录着任务的整体进展情况,管理所有Job失败、重启等操作。如果其中一个任务失败,Jobtracker可以重新调度任务到另外一个Tasktracker。
M/R比较适合大规模数据集的并行计算,适用于海量非结构化数据的定时批量处理。但M/R的编程模型过于单一,导致开发效率低,限制了更多应用的产生。由于其数据处理流程是一系列M/R任务的串行执行,导致频繁的磁盘I/O操作,执行效率比较低。
(3)Yarn
Yarn是Hadoop0.23之后的新MapReduce框架,可为上层应用提供统一的资源管理和调度。Yarn包括ResourceManager、ApplicationMaster和 NodeManager三部分。ResourceManager控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager将各个资源部分(计算、内存、带宽等)安排给基础Node Manager(Yarn的节点代理)。每一个应用的ApplicationMaster负责相应的调度和协调。
(4)HBase
HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它利用了Hadoop所提供的分布式数据存储功能,适合于非结构化数据存储的数据库。
(5)Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。
Hive适用于大规模数据集的批处理作业,但在大规模数据集上的执行查询一般有分钟级的时间延迟。Hive本身也不支持联机事务处理(OLTP)操作。
(6)Impala
Impala是一个在Hadoop集群上运行的本地SQL查询引擎,提供原始HDFS数据和HBase数据库的简单查询访问。它移植了MPP引擎直接操作HDFS文件和Hbase表,采用Parquet列式存储格式,适合海量结构化数据的即时分析及查询,支持从s级到h级的各种查询。目前,Impala已经达到商用MPP数据库的性能。
(7)Spark
Spark是开源的类HadoopMapReduce的通用的并行计算框架。Spark基于M/R算法实现的分布式计算,中间输出和结果可以保存在内存中。Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。Spark适用场景有:迭代式算法、交互式数据分析、实时流处理。
由于RDD(弹性分布数据集)的特性,Spark不适用那种异步细粒度更新状态的应用,例如Web服务的存储或者是增量的Web爬虫和索引。
Spark由4部分组成:SparkSQL、MLlib、GraphX、SparkStreaming(见图2)。

图2 Spark架构图
●Spark SQL:Spark处理SQL和结构化数据工具,Spark引入了Schema RDD的数据抽象,使其能统一、高效地访问和查询各种不同的数据源。Spark SQLAPI能像查询RDD一样查询结构化的数据,并且Spark SQL还提供了JDBC/ODBC的服务端模式,以便建立JDBC/ODBC数据连接。
●MLlib(MachineLearning):Spark提供的机器学习库,包含了常见的机器学习算法。
●GraphX(Graph Processing):是Spark处理图(Graph)的框架,利用PregelAPI可以用RDD有效地转换(Transform)和连接(Join)图,实现图算法。
●Spark Streaming:Spark处理流应用的库,结合了批处理查询与交互式查询,方便重用批处理的代码和历史数据。
Spark可以利用已有的Hadoop组件在Hadoop集群中运行,可以访问HDFS文件系统,也可以通过Spark on Yarn配置参数使用Yarn来实现资源调度。
(8)Storm
Storm是个实时的、分布式以及具备高容错的计算系统。Storm作为实时流数据处理事实上的标准,已经集成到Hadoop的Yarn上。它主要有以下特性:
●编程模型简单化
继承了Pout和Bolt类编写事件处理逻辑,降低了编程的复杂性。
●服务化
提供服务框架,支持热部署,即时上线或下线应用。
●高容错性和可扩展性
管理工作进程和节点的故障,计算是在多个线程、进程和服务器之间并行进行的。
●可靠性Storm
保证每个消息至少能得到一次完整处理;任务失败时从消息源重试消息。
●快速
使用ZeroMQ作为其底层消息队列,保证消息能得到快速的处理。
(9)数据挖掘计算引擎
●Mahout
Mahout是基于Hadoop之上的机器学习和数据挖掘的一个分布式框架。Mahout用Map-reduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Mahout包括分类、聚类、关联规则挖掘、回归、降维/维约简、进化算法、推荐/协同过滤、向量相似度计算、非Map-Reduce算法等类型的算法,并具有很好的扩展性。
●Pagerank
PageRank是一种数据挖掘算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。
●Pregel
Pregel是Google提出的一个面向大规模图计算的通用编程模型,是一个用于分布式图计算的计算框架。许多实际应用中都涉及到大型的图算法,典型的如网页链接关系、社交关系、地理位置图、科研论文中的引用关系等,有的图规模可达数十亿的顶点和上万亿的边。Pregel主要用于图遍历(BFS)、最短路径(SSSP)、PageRank计算等。
(10)根据以上技术分析,Hadoop及其生态圈技术定位及应用场景如表1所示。
3.2.3数据服务层
数据服务层主要技术及应用场景说明如表2所示。
3.2.4总体架构
根据以上各层的技术分析,对大数据公共平台架构建议如下:
(1)数据接口层
建议采用Flume作为非结构化数据收集手段,结构化数据可以使用DataX/Sqoop等方式进行数据转出及导入。
(2)数据核心处理层
建议采用HDFS集群作为非结构化、半结构化数据存储,MPP关系型数据库集群作为结构化数据存储,Yarn作为实现统一资源管理调度。考虑到实时交互处理与批量处理同时并存的需要,采用Impala和Hbase数据实时查询及分析,M/R实现定期批量处理,Spark作为实时批量处理,Storm流数据计算引擎作为流数据处理引擎。
(3)数据服务层
采用SOA实现服务能力管理及调用,通过消息中间件完成应用之间的数据交换,数据集成平台提供批量数据服务。大数据总体技术架构如图3所示。

表1 Hadoop及其生态圈技术定位及应用场景

表2 数据服务层主要技术及应用场景
4 结束语
核心业务和数据是各电信运营商的生命之源、发展之本,数据步入海量级别,大数据平台将在数据统计分析、精准营销中发挥关键作用,具有广泛的应用前景。
参考文献
[1]陈虹君.基于Hadoop平台的Spark框架研究[J].电脑知识与技术,2014(35:8407-8408).
[2]黎文阳.大数据处理模型Apache Spark研究[J].现代计算机(专业版),2015(8):55-60.

图3 总体技术架构图
收稿日期:(2016-04-26)
Research on big data applications deployment technology
ZHANGLiang,YANGChunli,MAYuanyuan
Abstract:In the case of massive data analysis,Hadoop ecosystem and its various components(such as Impala,Spark)technical features and application scenarios proposed functional architecture and technical architecture in terms of data collection,data processing,data applications and the like.
Key words:big data;spark;impala;hadoop
