基于数据质量诊断的数据整合技术
2016-08-01叶健辉白静洁
叶健辉 白静洁 刘 琪 王 刚 王 梓 武 江
基于数据质量诊断的数据整合技术
叶健辉1白静洁2刘琪2王刚2王梓3武江2
1.国网湖南省电力公司;2.南瑞集团北京科东公司;3.国网天津市电力公司
行业曲线
本文针对目前电网运行数据存在的跳变、不刷新等数据质量问题,提出了一种基于数据质量诊断的数据整合技术,通过该技术实现了电网运行数据的规范性和统一性,提高了数据的可靠性和完整性,为电网运行分析提供了可靠的数据支撑。
当前电力调度中心存储了大量电网运行、生产管理等方面的数据。电网运行数据有跳变、不刷新等异常错误,这些数据的存储方式和分散性,很难让用户直接发现原因。电网生产运行和管理对数据准确性要求很高,调度数据必须是可靠和完整的,才能准确反映电网运行情况。在电网运行中存储海量历史数据,对于这些海量历史数据准确性会影响很多应用,如负荷预测、省间数据交互、可视化展示分析及调度数据上报等。因此,对数据质量研究分析的同时,提高调度数据质量具有十分重要的现实意义。
结合智能电网调度技术支持系统数据模型规范性和统一性,对电网运行数据查询或存储如何保证数据准确性,主要通过数据模板整合工具来提高调度数据质量。
本文首先通过介绍数据整合技术架构,提出了一种基于数据质量诊断的数据整合技术。其次,通过利用五项关键技术整体实现电网运行数据的规范性和统一性,从而解决了提高了数据的准确性,为电网运行分析提供了可靠的数据支撑。
技术架构
本文针对现有的电网运行数据存在的问题,经过分析数据特征与存储分布情况,结合现有的数据质量诊断方法,设计出了适用于电网调度运行数据质量诊断的数据整合技术架构,从可视化流程构建技术、多源异构数据抽取技术、数据质量诊断技术、基于血缘追踪的数据转换技术到内存数据转发服务,全方位的解决了数据所存在的所有问题。技术架构如图1所示。
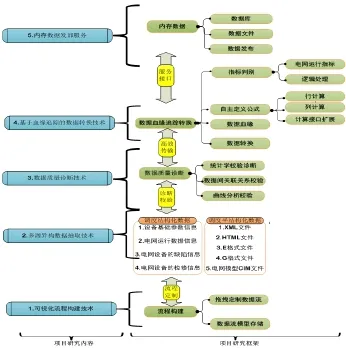
图1 数据整合技术架构
关键技术
可视化数据流构建技术
视化数据流为数据整合提供操作方便可拖拽、灵活定义节点方式进行数据整合。依据XML标准模型保存数据流模型数据,为数据整合提供了可视化定制流程手段,同时具备高度的可移植性。如图2所示。
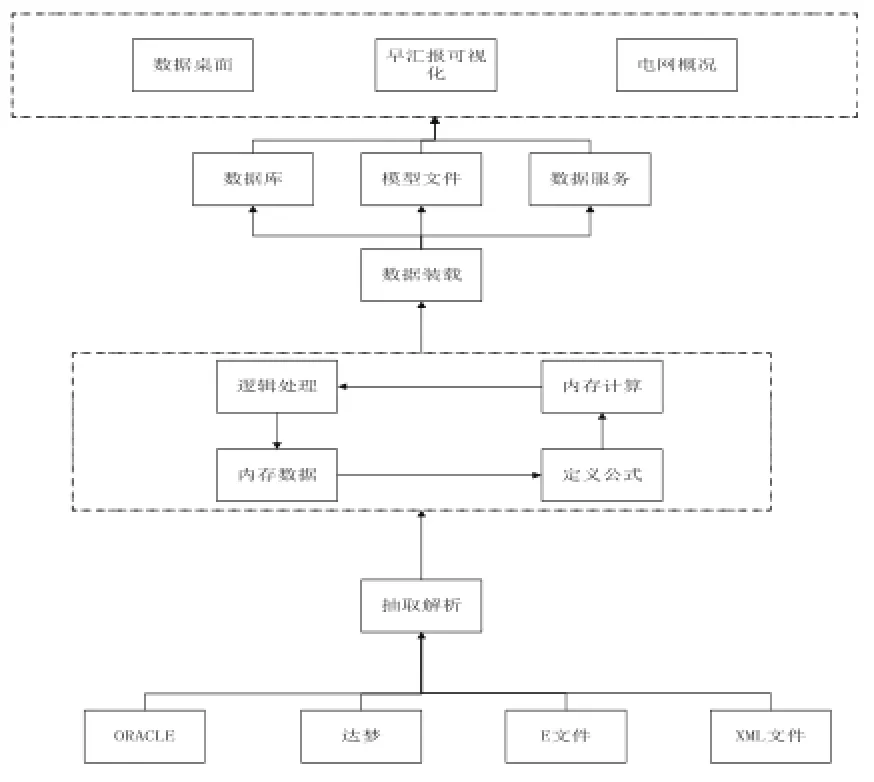
图2 可视化数据流构建技术

图3 基于XML标准模型文件描述应用程序界面
1)灵活拖拽定制
用flex页面元组件定义数据操作节点,选择不同节点进行拖拽到数据操作区域,动态调整节点坐标和摆放位置;通过监听鼠标事件和键盘事件对其操作记录节点位置,定义界面全局变量临时缓存,待操作完成后统一保存到模型文件。
2)流程化模型存储
基于XML标准模型文件描述应用程序界面,使原本需要由代码开发的程序界面转而可以使用此规范进行描述。在定义中包含组件类型、位置定义、大小定义、样式定义及其他组件属性。如图3所示。
多源异构数据抽取技术
目前整合工具在使用过程中抽取源有国产数据库、商业数据库和电力模型文件,数据库抽取技术采用配置不同连接驱动动态反射调用连接库实例,即可达到同时抽取多个库实例。电力模型文件通过FTP服务多线程抽取,采用模板解析技术将数据文件放入内存处理。
1)多源异构数据技术
封装构建异构数据源的查新模块,转换底层数据对象为统一的全局数据。实现数据的统一访问以及数据源的集成和共享。构建异构数据技术架构见图4。
2)全量抽取技术
数据源端进行全部装载时需要进行全量抽取,全量抽取就是将数据从数据库中抽取出来,通过转换和加载操作迁移到其他地方。技术实现通过选择不同库实例定义SQL语句抽取全量和JAVA读文件IO流操作数据文件。
3)增量抽取技术
增量抽取只抽取自上次抽取以来数据库中要抽取的表中新增或修改的数据。在整合使 用过程中,捕获变化的数据是增量抽取的关键。将业务系统中的变化数据按一定的频率准确地捕获。增量数据抽取中常用的捕获变化数据的实现用动态时间戳去定义SQL语句和文件名,时间戳标签[YYYY][MM][DD][HH24][MM][SS],通过JAVA正则处理替换达到数据动态更新抽取。
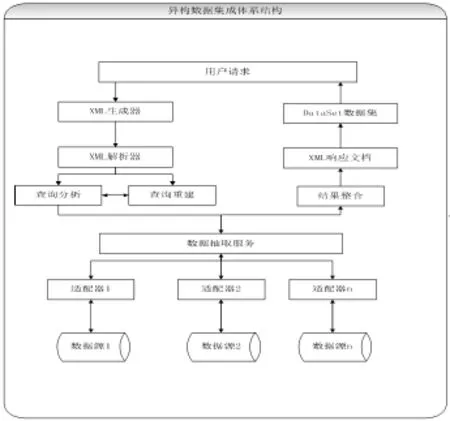
图4 异构数据集成体系结构
数据质量诊断技术
数据整合通过对数据抽取后,要对抽取数据结果进行数据质量诊断校验。一般的数据信息都符合统计学正态分布的规律,若一些占比小的数据存在异常,则通过与其它数量少的数据比较做出判断。电网运行类数据质量诊断技术主要采用曲线分析校验,具体如下:
将最近5个点进行大小排序,显示值取排序中值。使用中值滤波法可以排除局部极值的干扰。若是有一个异常数据经过,则由于在该异常数据段前后2个点附近为极大值(极小值),该点将被中值滤波法所抛弃。使用加权平均法,即将某点前后5个值进行权值平均,加权平均法虽然增加了曲线的平滑度,却依然受到误差的权值因素影响,而且某点的误差影响到前后5个点共计9个点的影响范围。使用中值滤波法可能会丢失一个峰值信息,但是用电控制以趋势控制为主,峰值控制较少,因此最终采用了中值滤波法来排除异常数据。给出了加权平均法和中值滤波法去除异常点的分析比较。如图5所示。
基于血缘追踪的数据转换技术
经过数据抽取对数据质量诊断判别后,需要对内存数据根据不同电力业务进行模型转换。在数据转换技术中采用数据血缘和流程追踪进行处理,数据血缘分为数据建模和查询重写。血缘追踪采用二叉树递归遍历节点内存数据转换计算处理,整合过程中速度快、数据关系透明化和逻辑操作方便等。

图5 曲线分析校验

图6 模板技术
1) 数据转换
数据转换服务将根据数据整合任务配置,在数据抽取服务完成后自动启动。它读取该任务的转换配置模板文件,并根据转换模板文件的具体要求:实现源端和目地端用户名不同的转换;源端和目地端表名不同的转换;源端和目地端字段名不同的转换;支持对一个表的字段增加,删除、修该源字段类型;对NUMBER类型数据作的+, -, *, /的转换。支持给一个列设置默认值,当该列为空时自动替换为设置的默认值。
2)模板技术
通过定义数据标签模板对数据模型格式转换,IMPUTIOSTREAM文件流对其模板和数据文件合并。解析标签对内存数据格式找到相应标签填充实数据,返回二维数据结构。在模板中改变变量几乎在任何地方都可以使用复杂表达式来指定值命名的宏,可以具有位置参数和嵌套内容名字空间有助于建立和维护可重用的宏库,在嵌套模板片段生成输出时,转换数据文件模型输出。如图6所示。
3)数据血缘
数据建模。主要是建立数据库概念结构的模型,先定义数据库全局概念结构模型,然后逐层细分,产生不同粒度的概念结构模型,知道原子概念结构模型;定义每个原子概念结构模型整合起来构成数据库全局结构模型;通过核心数据属性进行部分属性关联,逐步扩张得到数据标准模型;对表数据还可以采用视图关联。这样在实体之间的联系分为一对一、一对多和多对多三类。
流程化血缘追踪采用二叉树递归遍历算法,递归是设计和描述算法的一种有力的工具,它在复杂算法的描述中被经常采用
4)自主定义公式
在电网运行中地区负荷总加、全网最大、负荷率等需要自主定义公式计算。定义计算函数,通过下列方式可以实现自主计算的自优化:用函数来表示定义公式策略;依据当前的数据模型,通过业务数据定义函数公式,得到期望的数据状态和相应取值情况。针对内存中二维数据在电力业务需求中采用行与行和列与列之间公式定义计算,公式定义满足常规运算和统计函数运算,常规运算包括加、减、乘、除和操作符优先级等,统计函数包括SUM、SQRT、AVG、TAN、COS和逻辑与或运算等。
定义行计算公式。通过数据唯一标识定义公式,葛大江总机组出=G#1+G#2+G#3,通过遍历二维数据找到数据标识操作计算。
定义列计算公式。根据数据列名定义公式,当日全网负荷最大值=MAX(H1,H2,H3…),根据列名找到度量计算。
扩展计算函数。通过JAVA运行态反射调用技术,加载自定义函数类注入,丰富自主计算功能和业务数据逻辑处理。
5)指标判别技术
在电网运行中需要很多数据指标应用去支撑运行分析,数据指标分析也是电网运行中重要一部分。选择相关区域、设备及量测类型编码进行定位。根据统一编码,设备和量测关系进行匹配。搜索设备和量测类型对象编码匹配得出葛大江有功总加公式和分量进行判别。
基于内存的数据发布服务技术
在数据整合后需要对内存数据提供服务和发布,根据不同应用业务数据需要,可以将内存数据装载多个库实例和生成多个电力标准模型文件。当前电网调度的信息应用系统不断增加,并且多为异构系统,其应用需求也在不断变化,需要面向对象设计对其它系统提供数据服务调用。
数据库装载
把内存数据交换到目的节点,选择库实例,通过利用JDBC组件,支持国产数据库、SYBASE、SQLSERVER、DB2、MYSQL等多种满足SQL标准的数据库进行数据装载。
数据文件发布
从哈希列表中获取数据并将模板转义匹配,数据流中内存数据进行定义模板生成数据文件,生成数据文件通过FTP服务进行发布存储。
结语
本文提出的基于数据质量诊断的数据整合技术,从数据抽取、数据转发、数据发布、数据诊断等多个环节对数据进行了规范和统一,从整体上实现电网运行数据的规范性和统一性。而且在此基础上,使用数据质量诊断技术极大的提高了数据的准确性,为电网运行分析提供了可靠的数据支撑。
DOI:10.3969/j.issn.1001- 8972.2016.13.042
