副版本优先级可提升的全局容错调度算法
2016-07-31韩江洪魏振春
彭 浩 韩江洪 魏振春 卫 星
(合肥工业大学计算机与信息学院 合肥 230009)(hanjh@hfut.edu.cn)
副版本优先级可提升的全局容错调度算法
彭 浩 韩江洪 魏振春 卫 星
(合肥工业大学计算机与信息学院 合肥 230009)(hanjh@hfut.edu.cn)
在主副版本机制的全局容错调度中,副版本运行窗口短,采用优先级继承策略的副版本响应时间长,容易错失截止期.针对副版本实时性差的问题,提出基于优先级提升策略的全局容错调度算法(fault tolerant global scheduling with backup priority promotion,FTGS-BPP),通过赋予副版本比主版本高的优先级,减少副版本在运行过程中受到的干扰,缩短了副版本的响应时间,改善了副版本的实时性,从而减少了实现容错所需的额外处理器资源.仿真结果表明,和采用优先级继承策略的全局容错调度算法相比,FTGS-BPP在调度相同的任务集时明显降低了处理器资源需求.
为了满足对计算能力不断增长的需求,多处理器芯片被越来越多的嵌入式硬实时系统采用,例如航空电子系统[1]、汽车电子系统[2]、工业控制系统[3]等.硬实时系统同时具有实时性和可靠性要求.实时性是指系统中的每个任务都必须能够在某个固定时限内完成设计的功能,这个时限被称为截止期;可靠性是指系统可以无故障执行设计功能的能力.有效的硬实时容错调度算法是满足系统实时性和可靠性要求的关键[4-6].
主副版本机制是实现容错调度最主要的方法[7].在该方法中,系统中的每个任务有一个主版本以及一个或多个副版本,任务开始运行时只有主版本作业就绪,副版本作业都处于挂起状态,如果主版本出错,则会有一个副版本作业进入就绪状态并被调度运行,该副版本作业出错则继续调度下一个副版本作业,直至该任务任意一个版本的作业正确响应,副版本作业的启动顺序由设计人员预先确定.
和多处理器实时调度算法相同,容错调度算法也分为分组容错调度算法和全局容错调度算法.前者将任务分组,并保证将同一个任务的主副版本分到不同的组中,每组单独占用一个固定的处理器,并使用单处理器实时调度算法调度每个组中的任务[5,89];后者不固定任务的运行位置,任务可以在处理器间迁移,调度器总是调度优先级高的主版本或者副版本在功能完好的处理器上运行,这样不会出现有处理器空闲而任务在其他处理器上等待却不能使用空闲处理器运行的情况.和分组容错调度相比,全局容错调度的研究还很少,文献[10]提出了基于概率模型的动态优先级全局容错调度算法EDFk,并建立了基于使用率的可调度测试.文献[11]研究了基于优先级继承策略的固定优先级全局容错调度算法FTGS.优先级继承策略的问题是会造成副版本实时性差,在主副版本机制的容错调度中主版本和副版本的截止期是相同的,而副版本作业只有在主版本作业出现故障之后才会进入就绪状态被调度运行,因此可供副版本作业运行的时间窗口较短,容易错失截止期,为了保证副版本能够在短时间内响应,需要增加大量额外的处理器资源.
优先级提升策略是解决副版本实时性差的有效方法,该策略通过赋予副版本比较高的优先级,使副版本作业可以在较短时间内响应,从而满足实时性要求.本文基于优先级提升策略,针对固定优先级偶发实时任务集,提出副版本优先级可提升的全局容错调度算法(fault tolerant global scheduling with backup priority promotion,FTGS-BPP),解决主副版本机制的全局容错调度中副版本实时性差的问题.
本文的研究建立在以下假设的基础上:
1)任务之间相互独立,任务中没有并行运行的代码,即一个任务同一时刻只能占用一个处理器;
2)在一次作业的生命周期内只会出现一次故障,这一假设在容错调度领域被广泛采用[5,9-10,12];
3)故障持续时间很短,即是瞬态故障[13-14];
4)系统的硬件平台为同构多处理器平台,处理器速度相同,并共享存储器.
1 任务模型和相关定义
多处理器硬实时系统包含1个由n个实时任务组成的偶发任务集和1个由m个同构处理器组成的硬件平台.任务τi(i=1,2,…,n)包含1个主版本和1个副版本,用6元组τi=?CPi,CBi,Di,Ti,PPi,PBi?表示.其中,CPi和CBi分别表示主、副版本的最坏情况运行时间;Di表示相对截止期,即任务一次运行的释放时刻和完成时限之间的时间长度;Ti表示任务相邻2次释放作业的最小时间间隔;PPi和PBi分别表示主、副版本的优先级,在这里规定数值越小代表越高的优先级,即最高优先级为1,最低优先级为n.在后面的章节中,不需要特别指明作业的序数时,用JPi和JBi分别表示任务τi主、副版本的一次作业,ri表示JPi和JBi的释放时刻,di表示作业的绝对截止期,即di=ri+Di,分别用RPi和RBi表示τi主、副版本的最大响应时间,用RNFi表示系统中无故障时τi主版本的最大响应时间.
任务的主、副版本在某一时刻(时间触发或事件触发)同时分别释放1次作业,主版本释放的作业立刻进入就绪状态,副版本释放的作业进入挂起状态,只有在对应主版本作业发生故障时才会进入就绪状态,主版本作业正确响应时,取消对应的副版本作业.就绪作业进入1个全局就绪作业队列,调度器按照优先级顺序调度前n个(n是处理器数量)就绪作业在功能完好的处理器上运行,作业和处理器之间没有绑定的关系,即作业可以在任意1个处理器上运行.在FTGS-BPP中,抢占是始终允许的,任意时刻就绪的高优先级作业会抢占低优先级作业,如果有多个低优先级作业则抢占其中优先级最低的,同时作业迁移也是始终允许的,即被抢占作业可以在另一个处理器上恢复运行.
在后面章节的讨论中,需要用到下面这些定义:
定义1.任务τi在时间区间A内的负载是指在该时间区间内τi作业的累积运行时间长度.
定义2.高优先级任务τi在时间区间A内对作业Jk产生的干扰负载是指τi释放的作业处于运行状态而Jk处于就绪状态但不能运行的累积时间长度.
定义3.在时间区间A内作业Jk受到的累积干扰负载是指在该区间内所有高优先级任务产生的干扰负载的总和.
定义4.在时间区间A内作业Jk受到的干扰是指在区间内Jk处于就绪状态但得不到运行的累积时间长度.
定义5.如果作业的释放时间在时间区间之前,截止期在该区间开始时刻之后,则称该作业为带入作业,如图1中的J1.分别用CI(carry-in)和NC(no carry-in)表示一个任务是否有带入作业的情况.

Fig.1 Definitions of carry-in and carry-out job.图1 带入作业和带出作业的定义
定义6.如果作业的释放时间在区间结束时间之前、截止期在区间结束时间之后,则称该作业为带出作业,如图1中的J4.
2 可调度性测试
可调度性测试是硬实时调度算法的重要组成部分,在系统设计阶段,必须通过可调度性测试证明系统中运行的实时任务集是可调度的,即在运行过程中没有作业会错失截止期.不同的硬实时调度算法安排任务运行次序、位置的策略不同,这二者决定了可调度性测试的形式,因此需要给每种调度算法建立专属的可调度性测试.
由于多处理器实时系统的临界时刻(critical instant)还是未知的,目前的可调度性判定条件都是任务集可调度的充分而非必要条件[15].文献[16-17]分别基于响应时间分析法(response time analysis,RTA)和截止期分析法(deadline analysis,DA)建立了多处理器实时系统的可调度性判定条件RTALC和DA-LC.基于响应时间分析的可调度性判定准确性更高,因此FTGS-BPP算法的可调度性测试采用这种方法,按照优先级从高到低的顺序依次判定任务集中每个任务的可调度性,如果所有任务都是可调度的,则任务集是可调度的.
2.1 可调度性分析
假设被测试任务为τk.τk可调度要求:1)τk无故障时可以在截止期前正确响应;2)τk发生故障时可以在截止期前正确响应.其中前者又包含其他任务发生故障和没有任务发生故障2种情况.
假设τk的主、副版本在时刻rk各释放一次作业JPk和JBk,τk可能遇到的故障模式有3种:1)系统中没有故障发生,τk使用主版本作业JPk的计算结果,JPk的最大响应时间RNFk就是无故障时τk的最大响应时间;2)其他任务发生故障,τk依然使用主版本作业JPk的计算结果,JPk的最大响应时间RPk就是τk的最大响应时间;3)τk发生故障,即τk的主版本作业发生故障,τk使用副版本作业JBk的计算结果,JBk的最大响应时间RBk就是τk发生故障时的最大响应时间.
只有τk在3种故障模式下的最大响应时间都不大于其截止期,即式(1)成立,τk才是可调度的.2.2~2.4节将详细讨论如何计算3种故障模式下的最大响应时间.

2.2 系统中无故障
当系统中没有故障发生时,所有副版本作业都不会进入就绪状态,只有主版本作业运行,因此调度情况和不考虑容错能力的调度算法类似,使用RTA-LC[16]中的方法可以计算JPk的最大响应时间RNFk.为了便于理解,这里根据本文使用的任务模型改写该计算方法中使用的公式,并简要叙述计算过程,这些在后面讨论其他故障模式时也需要使用.
首先要计算高优先级任务τi(PPi<PPk)在从rk开始长度为L的时间窗口(后面简称为L)内产生的最大负载.图2是任务τi在L内有带入作业(CI)和没有带入作业(NC)时产生最大负载的释放模式,区分这2种不同情况是为了使用限制带入作业(limited carry-in)技术[16,18],以提高测试准确性.

Fig.2 Release pattern for calculating the upper bound of workload.图2 产生最大负载的作业释放模式
分别用WCIi(L)和WNCi(L)表示τi在有带入作业(CI)和没有带入作业(NC)情况下的最大负载,使用式(2)和式(3)计算:
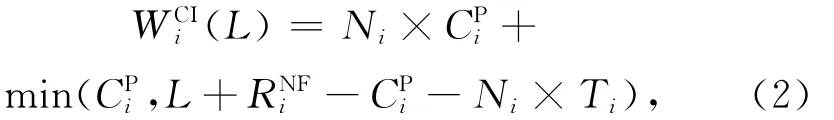
其中Ni表示可以在L内完整运行作业的数量,min(CPi,L+RNFi-CPi-Ni×Ti)表示带出作业产生的最大负载;
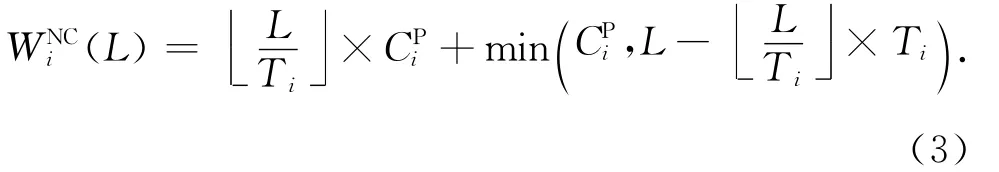
任务τi在L内有带入作业(CI)和没有带入作业(NC)时产生的最大干扰负载ICIi(L)和INCi(L)分别使用式(4)和式(5)计算:

限制τi的最大干扰负载不超过L-CPk+1的原因在于:如果τi的最大干扰负载到达L-CPk+1,τi释放的作业在L内占用一个处理器的时间已经导致JPk无法在该处理器上被调度(运行高优先级负载不超过L-CPk的处理器才有足够的资源运行JPk);而继续增加τi的最大干扰负载会导致在计算最大干扰时,超过L-CPk+1的部分被错误地分配到每个处理器上,影响最终计算结果.
用Fi(L)表示τi在有带入作业(CI)和没有带入作业(NC)情况下最大干扰负载的差值:
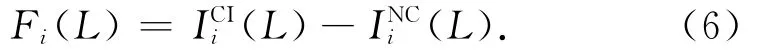
至此,通过式(7)可以计算得到所有高优先级主版本在L内产生的最大累积干扰负载Sk(L).式(7)使用限制带入作业(limited carry-in)技术,只允许Fi(L)项前m-1(m是处理器个数)大的任务有带入作业,该技术的具体讨论请见文献[16,18].
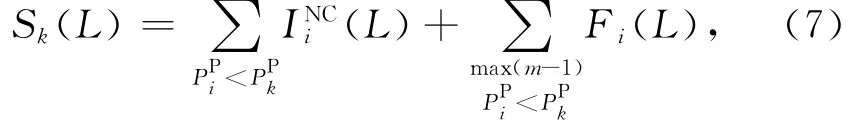
在L内,JPk受到的最大干扰Ik(L)通过式(8)计算.式(8)等号的右边表示所有高优先级主版本产生的最大累积干扰负载在L内能够同时占用所有处理器的最密集排列,这种排列导致JPk就绪但无法运行的时间最长.

从RNFk(0)=CPk开始,迭代计算式(9),直至RNFk(n+1)=RNFk(n),RNFk(n)即为JPk在系统中无故障情况下的最大响应时间RNFk.
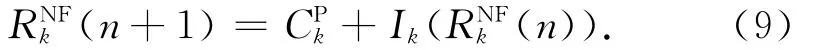
2.3 其他任务发生故障
假设故障任务为τf,JPk除了受到高优先级任务主版本的干扰,还受到τf一次副版本作业JBf的干扰.高优先级主版本的最大负载和最大干扰负载使用式(2)~(6)计算,但由于考虑了有故障发生的情况,在式(2)中应使用考虑故障的主版本最大响应时间RPi代替RNFi.
τf可能在任意时刻出错,即JBf可能在任意时刻就绪,这里对其做出最坏情况假设,即JBf在rk时刻就绪.考虑到只有优先级高于JPk时JBf才对其产生干扰,JBf产生的最大干扰负载If(L)使用式(10)计算:

JPk受到的最大干扰Ik(L)通过式(8)计算.
从RPk,f(0)=CPk开始,迭代计算式(12)直至RPk,f(n+1)=RPk,f(n),RPk,f(n)即为τf故障时JPk的最大响应时间RPk,f.

JPk在任意一个任务(除τk之外)故障时的最大响应时间RPk是所有RPk,f中的最大值,即:
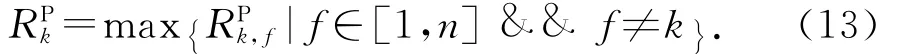
2.4 自身发生故障
假设JBk在时刻t0就绪,即对应主版本作业JPk在时刻t0发生故障.时刻t0越迟,JBk的响应时间也就越迟,而JPk发生故障的最迟时间不可能晚于系统无故障情况下其最大响应时间RNFk,因此假设t0=RNFk,这对于任务τk来说是最坏情况.
将τk的主副版本作业JPk和JBk结合为一个虚拟作业J′k,J′k分成2个部分:前一部分优先级为PPk,长度为CPk;后一部分优先级为PBk,长度为CBk.J′k的运行过程和τk的主版本作业JPk在RNFk时刻出现故障之后JBk就绪并完成运行的过程相同,因此J′k的最大响应时间R′k就是JBk的最大响应时间.此时,求JBk最大响应时间RBk的问题就转化为求J′k的最大响应时间R′k的问题.
由于J′k在运行过程中有1次优先级变化,使得变化前后对其产生干扰的任务集合不同.优先级高于PPk、低于PBk的主版本(假设序号为i)在[rk,RNFk]内对J′k产生干扰,优先级高于PBk的主版本(假设序号为j)在[rk,R′k]内对J′k产生干扰,它们的最大负载和最大干扰负载分别通过式(2)~(6)可以得到.
J′k在时间区间L内受到的最大累积干扰负载S′k(L)通过式(14)计算.由于R′k≥RNFk+CBk,在计算过程中L的最小取值为RNFk+CBk,因此在式(14)中不考虑L<RNFk的可能,以简化公式方便理解.
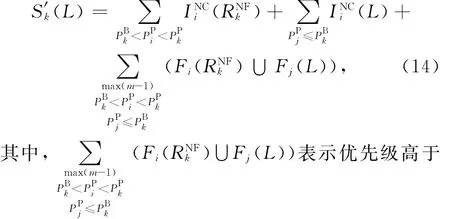
PPk的所有任务的Fi(L)项中,前m-1大的项的数量和.
J′k受到的最大干扰I′k(L)通过式(8)计算.
从R′k(0)=RNFk+CBk开始,迭代计算式(15)直至R′k(n+1)=R′k(n),R′k(n)即为虚拟作业J′k的最大响应时间,也就是主版本作业发生故障的情况下JBk的最大响应时间RBk.
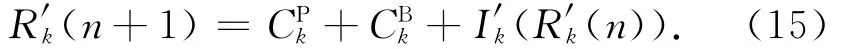
3 副版本优先级分配
在FTGS-BPP中,副版本的优先级会影响整个实时任务集可调度性.高优先级副版本可以在短时间内响应,实时性好,但是副版本优先级过高会给其他高优先级主版本带来额外的干扰负载,而高优先级主版本通常能承受的干扰相对较小,增加额外干扰负载有可能造成主版本不可调度.
本节建立一种启发式的副版本优先级分配算法.假设一个实时任务集的主版本已采用某种优先级分配算法分配优先级,例如DM(deadline monotonic),DkC等,并已按照优先级顺序排序,即PP1=1,PP2=2,…,PPn=n.在初始状态下,将副版本的优先级都设置为对应主版本的优先级,并判定整个任务集的可调度性,从最高优先级任务开始,依次检测每个任务副版本的可调度性,对于不可调度的副版本,将其副版本提升一个优先级,并更新再次判定该副版本和所有主版本的可调度性,不需要测试其他副版本的可调度性是因为从第2节的讨论中可以看出,副版本的可调度性只取决于高优先级主版本,改变副版本的优先级对其他任务的副版本没有影响.重复这个提升—测试过程直至副版本可调度,如果赋予副版本最高优先级仍不可调度,或者在这个过程中有主版本被判定为不可调度,则优先级分配失败,不能找到能够容错调度该任务集的副版本优先级分配方案.
副版本优先级分配算法的伪代码描述如算法1所示,其中primaryi和backupi分别表示任务τi的主、副版本,假设任务集已按照主版本优先级顺序排序,因此任务及其主版本的下标就等于优先级.


4 仿 真
仿真实验采用调度大量随机生成任务集的方法,以处理器需求(m)和任务集使用率(U)的比值(m?U)为评价指标,比较FTGS-BPP和采用优先级继承策略的全局容错调度算法(FTGS-1)实现容错调度所需的处理器资源.这一方法在硬实时调度研究领域被广泛采用[5,8-9,16-17].m?U比值反映了调度算法对处理器资源的需求,数值越小表示该调度算法的调度性能越好.FTGS-1是文献[12]中提出的容错调度算法只考虑一次故障的形式.同时,实验中也计算了不考虑容错的全局调度算法(GS)的m?U比值,从而可以比较2种容错调度算法为实现容错需要的额外处理器资源.
生成随机任务集的方法如下:首先设置任务集中单个任务的使用率(C?T)上限a和任务数量n,最小释放间隔T取[1,500]内的随机值,并假定任务以T为周期释放作业,最坏情况运行时间C取[1,aT]中的随机值,截止期D=T,任务的副版本简单地规定为主版本的复制.
a分别取0.2,0.3,0.4,0.5,分别使用DkC和DM算法给随机任务集的主版本分配优先级,在之间从低到高搜索使任务集可调度的m值(处理器个数),对每个m取值运行一次副版本优先级分配算法,如果成功分配优先级则说明在该m取值下任务集是可调度的,对每组参数(a和n)重复30次实验,取平均值作为有效结果.实验结果如图3~6所示.
从图3~6中可以看出,不论使用DkC或DM算法分配优先级,FTGS-BPP算法容错调度随机任务集所需的处理器资源都明显少于FTGS-1.和FTGS-1相比,使用DkC算法分配优先级时,FTGS-BPP最多减少处理器需求17.7%(a=0.4,n=40),平均减少11.4%;使用DM算法分配优先级时,FTGS-BPP最多减少处理器需求21.7%(a=0.3,n=30),平均减少12.1%.实验结果说明FTGS-BPP通过提升副版本优先级,改善了副版本的实时性,从而减少了为保证副版本不错失截止期而需要的额外处理器资源.
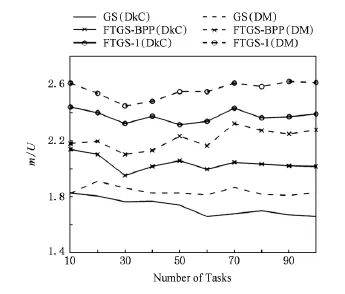
Fig.3 m?Uratio when a=0.2.图3 a=0.2时的m?U比值
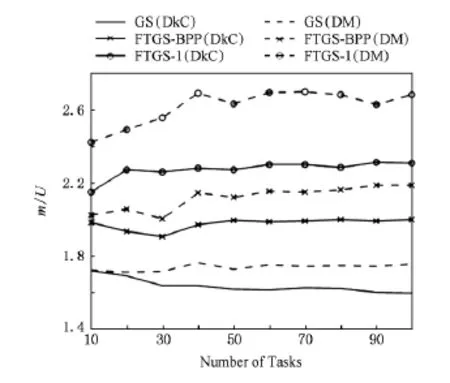
Fig.4 m?Uratio when a=0.3.图4 a=0.3时的m?U比值

Fig.5 m?Uratio when a=0.4.图5 a=0.4时的m?U比值
Fig.6 m?Uratio when a=0.5.图6 a=0.5时的m?U比值
5 总 结
本文基于优先级提升策略,提出副版本优先级可提升的全局容错调度算法FTGS-BPP,改善了副版本的实时性,使副版本可以在较短的运行时间窗口内依然不会违反截止期约束.通过生成大量随机任务集仿真的方法,对比了FTGS-BPP和基于优先级继承策略的全局容错调度算法的调度性能,仿真结果表明,采用不同的优先级分配算法时,FTGS-BPP都能够有效减少容错带来的额外处理器资源需求.
[1]Gaska T,Werner B,Flagg D.Applying virtualization to avionics systems—The integration challenges[C]??Proc of the 29th Digital Avionics Systems Conf.Piscataway,NJ:IEEE,2010:5.E.1-1 5.E.1-19
[2]Di Natale M,Sangiovanni-Vincentelli A L.Moving from federated to integrated architectures in automotive:The role of standards,methods and tools[J].Proceedings of the IEEE,2010,98(4):603 620
[3]Adyanthaya S,Geilen M,Basten T,et al.Fast multiprocessor scheduling with fixed task binding of large scale industrial cyber physical systems[C]??Proc of 2013 Euromicro Conf on Digital System Design.Piscataway,NJ:IEEE,2013:979 988
[4]Ding Wanfu,Guo Ruifeng,Qin Chengang,et al.A faulttolerant scheduling algorthm with software fault tolerance in hard real-time systems[J].Journal of Computer Research and Development,2011,48(4):691 698(in Chinese)(丁万夫,郭锐锋,秦承刚,等.硬实时系统中基于软件容错模型的容错调度算法[J].计算机研究与发展,2011,48(4):691 698)
[5]Zhu Ping,Yang Fuming,Tu Gang,et al.Feasible faulttolerant scheduling algorithm for distributed hard-real-time system[J].Journal of Software,2012,23(4):1010 1021(in Chinese)(朱萍,阳富民,涂刚,等.一种可行的分布式硬实时容错调度算法[J].软件学报,2012,23(4):1010 1021)
[6]Xie Guoqi,Li Renfa,Liu Lin,et al.DAG reliability model and fault-tolerant algorithm for heterogeneous distributed systems[J].Chinese Journal of Computers,2013,36(10):2019 2032(in Chinese)(谢国琪,李仁发,刘琳,等.异构分布式系统DAG可靠性模型与容错算法[J].计算机学报,2013,36(10):2019 2032)
[7]Krishna C M.Fault-tolerant scheduling in homogeneous realtime systems[J].ACM Computing Surveys,2014,46(4):48:1 48:34
[8]Bertossi A A,Mancini L V,Menapace A.Scheduling hardreal-time tasks with backup phasing delay[C]??Proc of the 10th IEEE Int Symp on Distributed Simulation and Real-Time Applications.Piscataway,NJ:IEEE,2006:107 118
[9]Chen H M,Luo W,Wang W,et al.A novel real-time faulttolerant scheduling algorithm based on distributed control systems[C]??Proc of 2011Int Conf on Computer Science and Service System.Piscataway,NJ:IEEE,2011:80 83
[10]Berten V,Goossens J,Jeannot E.A probabilistic approach for fault tolerant multiprocessor real-time scheduling[C]?? Proc of the 20th Int Parallel and Distributed Processing Symp.Piscataway,NJ:IEEE,2006:1 10
[11]Pathan R M,Jonsson J.FTGS:Fault-tolerant fixed-priority scheduling on multiprocessors[C]??Proc of the 10th IEEE Int Conf on Trust,Security and Privacy in Computing and Communications.Piscataway,NJ:IEEE,2011:1164 1175
[12]Samala A K,Mallb R.Fault tolerant scheduling of hard realtime tasks on multiprocessor system using a hybrid genetic algorithm[J].Swarm and Evolutionary Computation,2014,14(1):92 105
[13]Baumann R.Soft errors in advanced computer systems[J].IEEE Design &Test of Computers,2005,22(3):258 266
[14]Koren I,Krishna C M.Fault-Tolerant Systems[M].San Francisco,CA:Morgan Kaufmann,2007
[15]Guan N,Wang Y.Fixed-priority multiprocessor scheduling:Critical instant,response time and utilization bound[C]?? Proc of the 26th Parallel and Distributed Processing Symp Workshops &PhD Forum.Piscataway,NJ:IEEE,2012:2470 2473
[16]Guan N,Stigge M,Yi W,et al.New response time bounds for fixed priority multiprocessor scheduling[C]??Proc of the 30th IEEE Real-Time Systems Symp.Piscataway,NJ:IEEE,2009:387 397
[17]Davis R I,Burns A.Improved priority assignment for global fixed priority pre-emptive scheduling in multiprocessor realtime systems[J].Real-Time Systems,2011,47(1):1 40
[18]Lee J,Shin I.Limited carry-in technique for real-time multicore scheduling[J].Journal of Systems Architecture,2013,59(7):372 375

Peng Hao,born in 1984.PhD candidate in Hefei University of Technology.His main research interests include real-time system scheduling and embedded systems(superbinnitu@aliyun.com).

Han Jianghong,born in 1954.Professor and PhD supervisor in Hefei University of Technology.His main research interests include safety-critical industrial systems and embedded systems.

Wei Zhenchun,born in 1978.Associate professor in Hefei University of Technology.His main research interests include internet of things,wireless sensor networks,embedded system and distributed system.

Wei Xing,born in 1980.Associate professor in Hefei University of Technology.His main research interests include internet of things engineering and discrete event dynamic system.
Fault Tolerant Global Scheduling with Backup Priority Promotion
Peng Hao,Han Jianghong,Wei Zhenchun,and Wei Xing
(School of Computer and Information,Hefei University of Technology,Hefei 230009)
Fault tolerance is of great importance in hard real-time systems due to the impossibility of eliminating faults.In such a system the fault tolerant scheduling algorithm plays a critical role for achieving fault tolerance capability.In primary-backup scheme based fault tolerant global scheduling algorithms,the execution window of backup is relatively small.When priority inheritance strategy is adopted,the response time of the backup is likely too long to guarantee deadline requirement.For improving the real time property of the backup,we propose a fault tolerant global scheduling algorithm based on backup priority promotion strategy—FTGS-BPP.In FTGS-BPP,the backup has a higher priority than its corresponding primary so that during the execution the backup suffers less interference.Consequently the response time of the backup is reduced which means better real time performance.FTGS-BPP can achieve fault tolerance with less processors than the algorithms which follow priority inheritance strategy.A backup priority searching algorithm is also proposed.The simulation result shows that,compared with the fault tolerant global scheduling algorithm based on priority inheritance strategy,FTGS-BPP is able to reduce processor requirement significantly when scheduling the same task set.
multiprocessor;fault-tolerant scheduling;global scheduling;hard real-time systems;priority promotion
TP316.2
2014-12-17;
2015-06-09
国家自然科学基金项目(61370088);国家国际科技合作专项项目(2014DFB10060);国家科技支撑计划项目(2013BAH51F01,2013BAH51F02)
This work was supported by he National Natural Science Foundation of China(61370088),the International S&T Cooperation Program of China(2014DFB10060),and the National Key Technology R&D Program of the Ministry of Science and Technology(2013BAH51F01,2013BAH51F02).
魏振春(weizc@hfut.edu.cn)
关键词 多处理器;容错调度;全局调度;硬实时系统;优先级提升
