基于Lucene的站内搜索引擎开发研究
2016-07-21郭肇毅乐山师范学院计算机科学学院四川乐山614000
郭肇毅(乐山师范学院 计算机科学学院,四川 乐山 614000)
基于Lucene的站内搜索引擎开发研究
郭肇毅
(乐山师范学院计算机科学学院,四川乐山614000)
摘要:经典搜索引擎目前的性能已十分良好,但在对于某些特定网站内部信息的检索方面,若采取直接嵌入经典搜索引擎的方式,往往效果不佳。本文基于Lucene这一全文检索工具包,在对词条进行分析方面,将Lu⁃cene自带分析器与盘古分词工具相结合,开发了一款针对一个经典论坛的站内搜索引擎,经检测性能良好。
关键词:Lucene;站内搜索引擎;盘古分词
随着信息化进程的深入,政务公开等的需要,许多机关事业单位、企业等都建立了自己单位、部门的网站。但是,要在这些网站中快速地查找到自己所需要的信息是一件十分费时、费力的工作,特别是对于某些BBS论坛,要想查找相关主题的帖子也是十分困难的。目前,很多网站采用内嵌Google、百度等搜索引擎的形式来做相关的搜索工作。但是,由于网站本身的特点,采用内嵌大型搜索引擎的方式往往会造成效率低下。因此,开发一款针对网站本身特点的站内搜索引擎十分必要[1]。
本文通过仔细钻研搜索引擎的基本原理的前提下,基于一个著名的开源搜索引擎类库—Lucene,开发了一款针对某个论坛的站内搜索引擎,经检测搜索性能良好。
1 相关工作
1.1搜索引擎简介
所谓搜索引擎,就是按照一定的规则和方法,运用特定的计算机算法从网络上搜索信息,并对搜索到的信息进行相应处理后,将用户所要查找内容的相关信息展示给用户。常见的搜索引擎主要有全文索引搜索引擎、目录索引搜索引擎、元搜索引擎、垂直搜索引擎等。尽管搜索引擎如此多种多样,但它们的组成结构大体上是一样。一般搜索引擎包括5个组成部分:用户接口(一般是图形化接口)、网络爬虫、索引文件数据库、搜索工具和索引工具[2]。其示意图如图1所示。
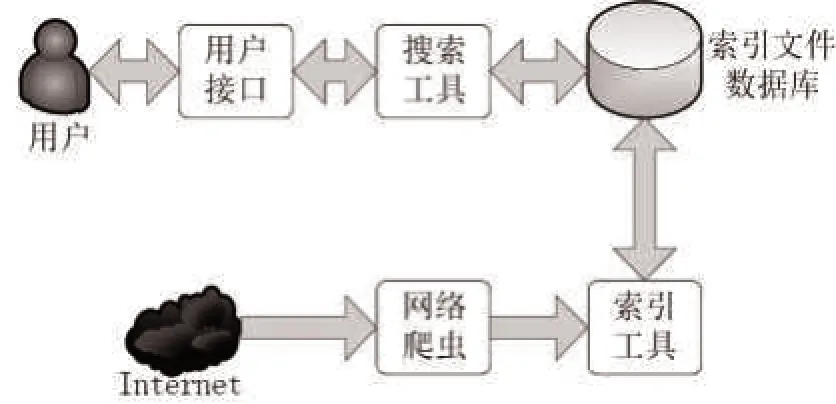
图1 搜索引擎结构示意图
搜索引擎的大致原理如下。
①通过网络爬虫抓取因特网上的信息。其具体流程为:根据信息是否有关,若是相关信息,则将相应的网页内容下载下来,以便之后建立索引等相关操作,同时查看该网页是否含有其他链接,若有,同样将其存储下来以便之后的搜索。网络爬虫搜索抓取信息主要采用深度优先搜索算法和广度优先搜索算法。
②索引工具是建立索引的工具,原理是将网页内容按照特定的算法处理后,建立相应的索引保存到索引文件数据库。建立索引的目的是为了之后查找的方便,类似于书本中的目录。书本有了目录,查找相应的内容就会方便很多。其中,倒排索引是一种常见的索引形式,而这是Lucene采用的索引形式。
③当用户想要查找某些信息的时候,用户通过相应的搜索引擎用户接口输入想要查找的内容,特定的搜索工具对用户输入的信息进行一些特定处理,然后在索引文件数据库中查找相关的内容,查找到后,将相关的信息通过用户接口反馈给用户。
1.2Lucene简介
Lucene是一个开源的全文检索工具包,原作者叫Doug Cutting。Lucene最初只有java版本,但因其强大的功能,逐渐有了很多其他语言的版本,比如C++、C#、Perl等,而且全球的爱好者在不断地对其进行完善。
使用Lucene从文档中检索关键字时,大体上可以分为以下步骤:①对要进行查找的文档进行预处理;②将大文档切分成多个小文档;③为相应的文档构建索引;④构建查询对象;⑤再在索引中查找相关内容。
在Lucene中,可以按关键词查询指定的列,根据相关度返回结果,也可以自定义搜索结果排序方式。
由于在建立索引时,写入索引并能够被用户检索的是一个个词条。因此,只有通过分词才可能让信息检索系统理解用户的检索,进而为其搜索相关内容。Lucene本身自带有分词工具,但其工具性能不很优秀,而市面上也存在大量的第三方分词工具,比如盘古分词就是其中的一种。
2 实验部分
实验采用的Lucene版本是v2.9.4的.net版本,所用到的盘古分词采用的是v2.3.1。实验采用ASP.NET进行用户界面的开发,借鉴了很多知名搜索引擎网站的风格特点,翻页采用的是缓存与不多的IO相结合的机制,减少了多用户同时访问时对服务器带来的压力。另外,构建的索引文件是对一个知名论坛内部数据进行分析所构建出来的。
本实验主要的创新点在如下。
①用盘古分词的分析器分析输入关键字的各个被切分出(盘古分词器切分的)的部分的权重,然后在索引中的Title域和Content域中查找这些权重不同的部分。
②用lucene自带的Ngram和StandardAnalyzer切分并分析输入关键字的权重,分析权重的具体操作如下:首先切出的词的最短长度是输入关键字的一半,然后如果输入关键字是三字词或以上,那么则赋予这个关键字所有切分出的部分以较高的权重,且被切出的部分字数越多权重越大;如果输入关键字是两字词或以下,那么赋予该两字词以较高的权重,切出的单字以较低的权重(因为用户输入的是两字词,说明这个两字词一定是一个很特殊且很重要的词,故可以赋予较高的权重),然后这部分是在Title这个域中去查询,加上前面建索引的时候将Title的权重用setBoost提高一点,通过这两种方式来提高标题命中所占的权重。
③用①和②中的东西进行BooleanQuery,如果关键字的长度大于4,则二者取或,否则,二者取与,这样可以既保证准确性,又保证搜到尽可能多的东西。
表1所示为搜索“果手”所显示的前10条记录。

表1 实验效果图
从表1中可以发现,站内搜索引擎性能基本能够达到市面上著名搜索引擎的效果。
3 结论
本文基于Lucene这一全文检索开发包,开发了一款适应于具体某个著名论坛的站内搜索引擎,通过整个开发过程,发现尽管Lucene已经非常优秀,但其也有相对薄弱的地方,比如自带的分析器还不够十分强大,而市面上分词工具虽然能够与之结合,取得不错的性能,但仍有提高的空间,在之后的研究中,可以考虑引入深度学习的思想,来改进现有的分词工具,使最后得到的搜索引擎效果更好。
参考文献:
[1]马志强,刘利民,苏依拉,等.基于Lucene的站内搜索引擎研究[J].内蒙古工业大学学报,2009,28(1):52-57.
[2]卫权岗,马建红,刘静.基于Lucene的WEB站内搜索引擎的研究与实现[J].信息通信,2011(5):97-98.
中图分类号:TP391.3
文献标识码:A
文章编号:1003-5168(2016)02-0021-02
收稿日期:2016-02-03
作者简介:郭肇毅(1987-),男,硕士,助教,研究方向:自然语言处理。
Research on the Development of the Search Engine Based on Lucene
Guo Zhaoyi
(Leshan Normal University,School of Computer Science,Leshan Sichuan 614000)
Abstract:The performance of the classic search engine is very well nowadays.However,on the search of some special websites’internal information,the result is not very good if adopting directly embed the clas⁃sic search engine.This paper developed a search engine inside the website for a classic bbs,by taking ad⁃vantage of lucene,which is afull-text searchtool kit.On the side of analyzing word term,we adopt the ana⁃lyzer which belongs to the Lucene itself and PanGu Analyzer.The performance of our search engine is quite good by detecting.
Keywords:Lucene;search engine inside the website;PanGu Analyzer
