基于YARN集群的计算加速部件扩展支持
2016-07-19朱延超钱德沛
李 钦 朱延超 刘 轶 钱德沛
(北京航空航天大学计算机学院 北京 100191) (网络技术北京市重点实验室(北京航空航天大学) 北京 100191) (liqin0728@gmail.com)
基于YARN集群的计算加速部件扩展支持
李钦朱延超刘轶钱德沛
(北京航空航天大学计算机学院北京100191) (网络技术北京市重点实验室(北京航空航天大学)北京100191) (liqin0728@gmail.com)
摘要以GPU和Intel MIC为代表的计算加速部件已在科学计算、图形图像处理等领域得到了广泛的应用,其在基于云平台的高性能计算及大数据处理等方向也具有广泛的应用前景.YARN是新一代Hadoop分布式计算框架,其对计算资源的分配调度主要针对CPU,缺少对计算加速部件的支持.在YARN中添加计算加速部件需要解决多个难点,分别是计算加速部件资源如何调度以及异构节点间如何共享问题、多个任务同时调用计算加速部件而引起的资源争用问题和集群中对计算加速部件的状态监控与管理问题.为了解决这些问题,提出了动态节点捆绑策略、流水线式的计算加速部件任务调度等,实现了YARN对计算加速部件的支持,并通过实验验证了其有效性.
关键词分布式系统;YARN;计算加速部件;混合异构节点;图形图像处理器;节点捆绑;任务调度
2013年,Apache推出了其Hadoop分布式计算框架的第2代,命名为yet another resource negotiator (YARN)[1],其采用新的计算框架,使用专门的Resource Manager对整个集群资源进行管理,单个节点的资源被划分成多个Container(Ct),由Node Manager对其进行管理,而具体的集群应用则通过Application Master完成所有的调度和管理.这使得它以后将不仅仅支持MapReduce计算模型[2],更可以拓展至对内存计算(例如Spark[3])、实时计算(例如Storm[4])等的支持,并使得多种计算模型可以同时使用在同一个集群中.
近些年,如何在包括Hadoop等分布式平台下添加对于计算加速部件的支持成为分布式集群系统的一个研究方向.该主要研究方向有3个:1)将对于如GPU这样的计算加速部件的支持加入到MapReduce分布式计算模型中,通过对MapReduce模型的某个模块或者逻辑的创新型改进,实现包括Hadoop分布式系统在内的所有支持MapReduce模型的分布式集群系统对于计算加速部件的支持[5-10];2)在参考Hadoop调度系统的基础上,改进其调度策略或者设计一个新的分布式集群系统,使其原生态地支持计算加速部件资源,其中多以计算加速部件作为加速模块或者加速节点使用[11-16];3)不对Hadoop的架构和任务调度方法进行修改,而是在某一种或者某几种的特定应用上进行针对性的优化,以达到提高集群性能的目的[17-18].
本文提出并实现了基于YARN架构的计算加速部件(包括GPU和Intel MIC)扩展支持.通过使用动态节点捆绑以及流水线式计算加速部件任务调度策略,对YARN架构进行了扩展,使得在全部或部分节点配置计算加速部件的分布式系统中,上层应用可以使用计算加速部件.
1YARN基本架构
YARN是Hadoop2.0的资源管理系统,其基本的设计思想是将MRv1中的JobTracker拆分成2个独立的服务:一个全局的资源管理器(resource manager, RM)和每个应用程序独有的应用控制器(application master, AM).其中,RM负责整个系统的资源管理和分配,而AM负责单个应用程序的管理[19].
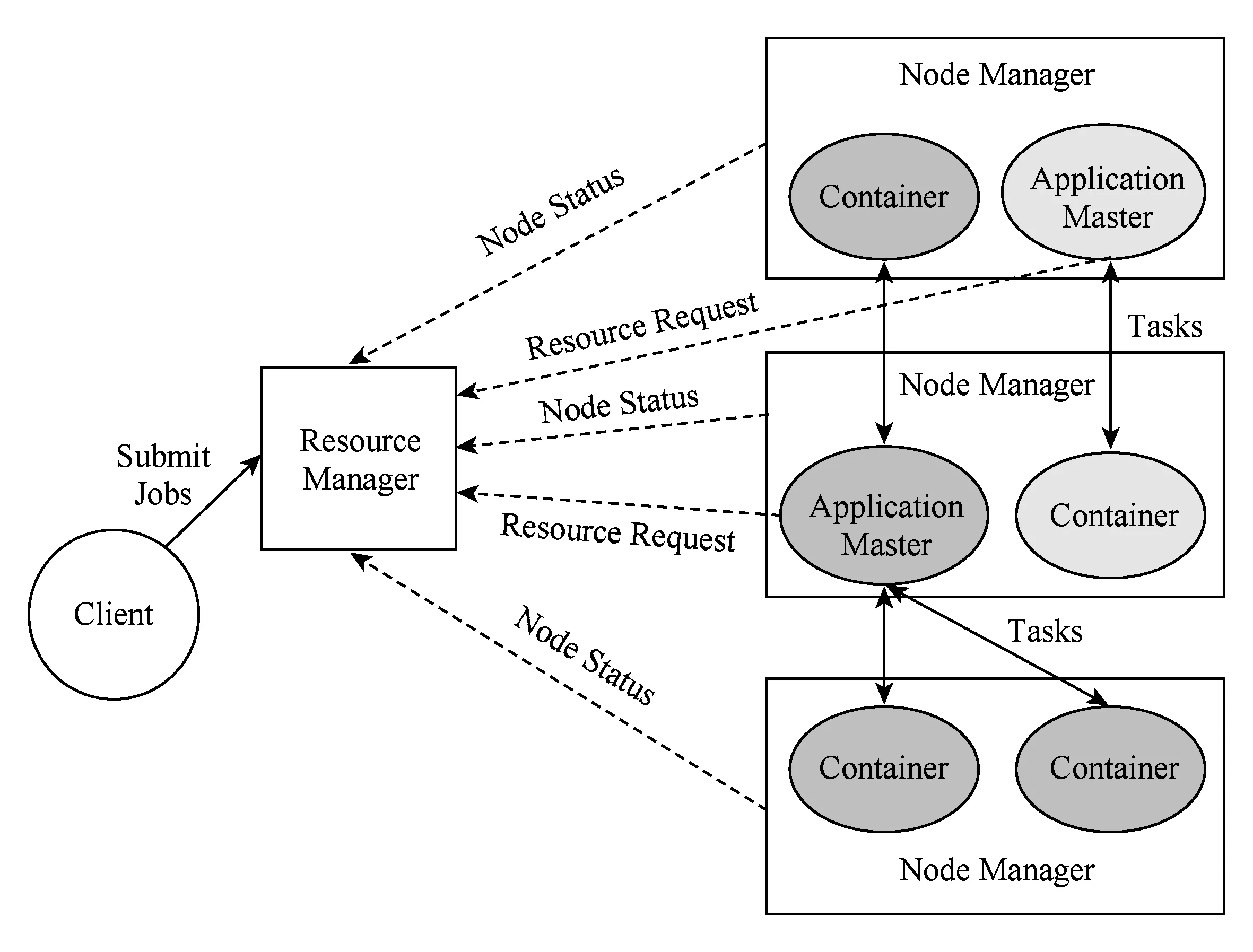
Fig. 1 YARN architecture.图1 YARN架构示意图
1) RM
RM是一个全局的资源管理器,负责整个系统的资源管理和分配.它由调度器(scheduler)和应用程序管理器(applications manager)这2个组件构成.调度器根据容量、队列等限制条件将系统中的资源分配给各个正在运行的应用程序.它不从事任何与具体应用程序有关的工作,而是根据各个应用程序的资源需求进行分配.应用程序管理器负责管理整个系统中的所有应用程序,包括应用程序的提交、与调度器协商已启动AM、监控AM的运行状态并在失败时重新启动它等.
2) AM
用户提交的每个应用程序都包含一个AM,它将与RM调度器协商获取资源,再将得到的资源进一步分配给内部的任务,与NM通信以启动或停止任务,监控任务的运行状态,并在任务运行失败时重新申请资源再次启动任务.
3) NM
NM是每个节点上的资源和任务管理器,它会定时向RM汇报本节点的使用情况和各个Ct的运行状态,以及接受并处理来自AM的Ct启动或停止等请求.
4) Ct
Ct是YARN中的资源抽象,它封装了某个节点的资源,主要包括CPU和内存.当AM向RM申请资源时,RM为AM返回的资源就是使用Ct表示.YARN会为每一个任务分配一个Ct,且该任务只能使用该Ct中的资源.
2计算加速部件的支持扩展
2.1设计思路
在现有的YARN框架中添加例如GPU或者Intel MIC这样的计算加速部件,并使之能够满足上层用户对资源的需求,为此需要解决3个问题:
1) 集群中对计算加速部件的状态监控与管理问题.现有的YARN中不支持除CPU之外的计算资源,因此需要新添加对计算加速部件的管理.本文采用由NM负责获取当前节点的计算加速部件的硬件信息,并在RM与NM之间增加实时计算加速部件的状态反馈,使RM获知计算加速部件的资源状态,整个集群的计算加速部件状态由RM进行监控与管理.
2) 计算加速部件资源如何调度以及异构节点间如何共享问题.现有YARN框架将每个节点CPU计算资源分割成相同粒度的容器Ct,然后根据一定的调度策略对任务进行调度,其中各个Ct中的计算资源都是相互独立的,不存在Ct到Ct之间的资源共享机制.但是与传统的CPU资源不同,计算加速部件并不一定存在于每个节点上,并且在实际的应用场景中也不能要求每个节点都拥有计算加速部件.因此,计算加速部件的资源调度重点在于如何解决将集群中的计算加速部件资源让每个节点都能够获取的问题.本文将集群中无计算加速部件的节点(NNode)与有计算加速部件的节点(ANode)建立动态捆绑关系,NNode中的需要计算加速部件执行的任务将会提交给对应的ANode上,并异步等待计算结果的返回.详细的节点捆绑策略将在2.3节中进行讲述.
3) 多个任务同时调用计算加速部件而引起的资源争用问题.单机环境下,多个进程如果同时使用例如GPU这样的计算加速部件时,会造成计算、通信等资源的争用,严重影响性能.在集群环境下同样有这样的问题.本文采用在ANode上建立一个特殊的Ct,称为AcCt (accelerator container),用来管理和调度获取到的计算加速部件任务.详细的AcCt任务调度策略将在2.4节讲述.
2.2系统结构
在分布式集群系统YARN上支持带有计算加速部件节点的设计方案的系统架构图如图2所示:
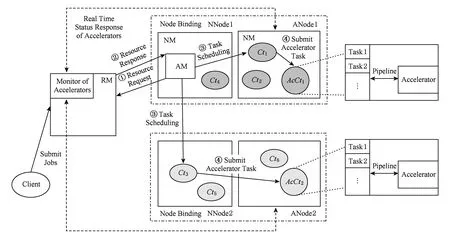
Fig. 2 Extended architecture of YARN.图2 扩展后YARN架构示意图
根据图2的架构图,应用调度流程总结如下:
1) 集群启动时,运行在各个节点的NM会向RM提交当前节点资源信息,这其中包括计算加速部件的资源信息,RM会根据计算加速部件的资源信息按照节点捆绑策略建立NNode映射到ANode的捆绑列表,并返回给各个NM,这时,ANode就会将本地的AcCt启动起来,并进行监听.
2) 用户向RM提交作业后,会产生一个新的AM,这时,AM会向RM申请作业所需的资源(包括计算加速部件任务的资源).RM会按照之前建立好的捆绑映射列表返回给AM所需的Ct信息,但具体的捆绑映射列表对AM透明,不需AM获知.
3) 作为Master的AM就会向分配给它的Ct发送任务并调度,若Ct遇到的是需求计算加速部件计算资源的任务,则会异步地向对应的ANode发送任务信息,这时,接收到任务的AcCt会按照流水线调度策略对任务进行处理,并在处理完成后将结果返回.
2.3节点捆绑策略
节点捆绑策略的基本原则是节点间距离最近原则,即同一机架内视为距离最近可捆绑,机架间节点相互隔离、不可捆绑.策略的核心是在实现动态捆绑的前提下尽量使用“平衡且代价小”的调度算法,具体来讲就是在动态变换时尽量保持原有NNode与ANode之间的对应关系.
RM会在各个NM启动时接收到当前节点的计算加速部件信息,同时NM与RM之间的心跳线也会时刻传递当前节点的辅助存储器信息.RM会根据这些接收到的资源信息进行NNode与ANode之间的捆绑.RM会为每个ANode建立1个以IP地址为键的栈结构,用来存储其捆绑的NNode.同时,RM会为每个机架建立1个对应的排序队列,用来放置之前建立的各个栈,排序队列以栈的存储节点个数为序.
1) 节点添加机制
① 接收NNode并添加时,将当前机架的排序队列中最小的栈取出,将当前NNode放入,再将栈插入回队列;
② 接收ANode并添加时,首先为其建立栈结构,然后判断所在机架的排序队列是否平衡(当前栈大小是否与队列中最小的栈大小相同),若已经平衡,则将当前栈加入到排序队列,就完成了策略;若不平衡,则从队列中取出最大栈,从栈头取出一个NNode放入到当前栈中,再将取出的栈插入回队列中.这时,再次判断是否平衡,如不平衡则再次进行以上操作直到队列平衡,如图3所示.
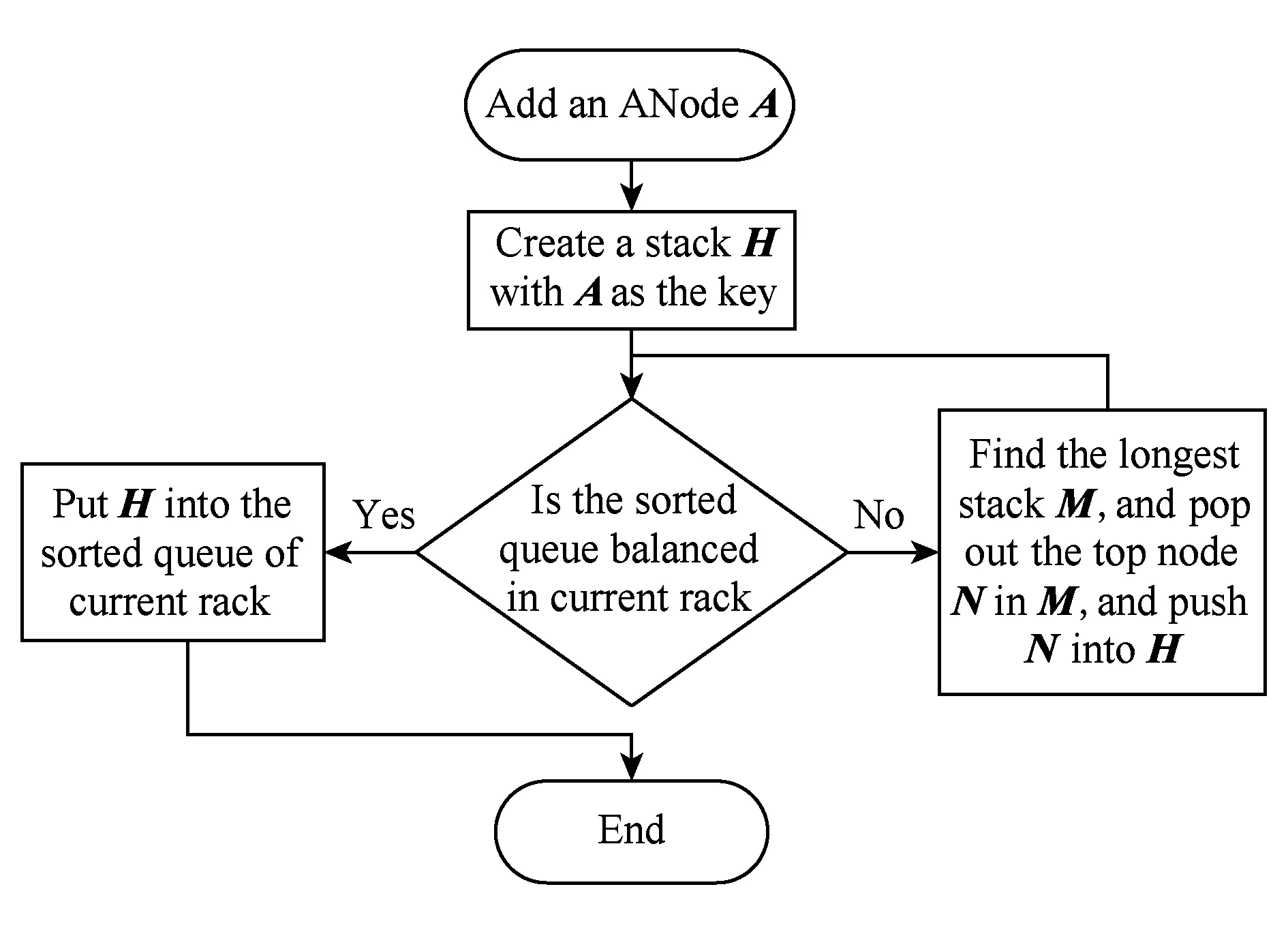
Fig. 3 Strategy of adding ANode.图3 添加ANode节点策略
2) 死亡退出机制
① NNode节点超时断开时,将其从对应的栈中删除,再对排序队列进行刷新;
② ANode节点断开时,将其从排序队列取出,在栈中的各个NNode都取出来,最后按照NNode的节点添加机制进行再次添加.
2.4计算加速部件任务调度策略
在ANode节点上,当NM开始运行时会同时启动AcCt来完成对所在节点计算加速部件资源的管理和任务调度.它使用远程读、处理、远程写的3级流水方式,将计算加速部件的计算资源高效地利用.具体的实现方式如图4所示:
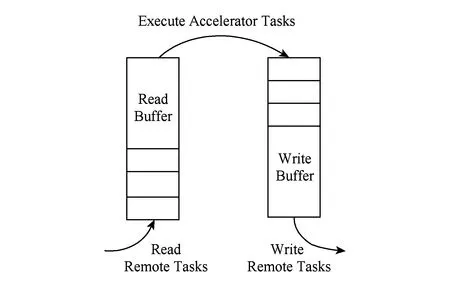
Fig. 4 Accelerator task scheduling in single node.图4 单节点内计算加速部件任务流水线调度策略
任务调度由3个独立线程和2个阻塞队列构成.远程读线程不断监听其他节点的连接,在获取连接后将远程需要处理的数据信息写入到本地的处理缓冲区中;处理缓冲区的数据结构是阻塞队列,处理线程会不断地从中取出需要处理的数据并执行;当处理线程完成处理操作后,会将处理好的结果写入到写缓冲区中;写缓冲区也由1个阻塞队列构成,它为远程写线程提供数据;远程写线程将从写缓冲区中的数据远程写入到与之建立连接的节点上.这样就完成了3级流水线的调度策略.
3实验环境及结果
3.1实验环境
本文的实验部署在以4台服务器建立起来的集群中,以GPU作为计算加速部件进行测试.详细的软硬件参数如表1所示:

Table 1 Test Environment
3.2实验测试用例
MAGMA(matrix algebra on GPU and multicore architectures)是由田纳西大学ICL实验室创建并维护的一组GPU加速的线性代数(LA)集,它为基于GPU的异构体系结构提供了基于GPU的LA测试包,以及例如LAPACK和BLAS这样的LA依赖包来进行CPU测试[20].
本文选取了MAGMA矩阵计算中最为常用的LU分解、Cholesky分解和QR分解算法作为集群中单次任务的基准程序,矩阵大小为10 000×10 000.表2给出了在本文实验环境下单个节点使用GPU计算和CPU计算的时间和它们之间的加速比.
Table 2CPUGPU Execution Time and Speedup of MAGMA Benchmark in Single Node
表2单机环境下MAGMA基准程序的CPUGPU执行时间和加速比
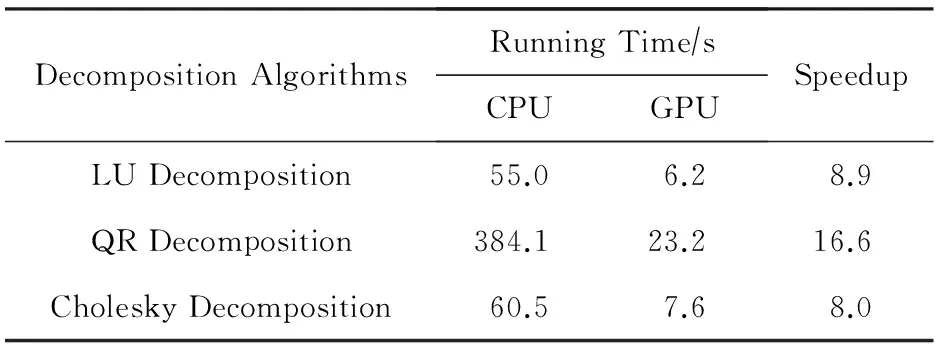
DecompositionAlgorithmsRunningTime∕sCPUGPUSpeedupLUDecomposition55.06.28.9QRDecomposition384.123.216.6CholeskyDecomposition60.57.68.0
每个测试应用中有100个相互独立的任务组成,其中单个任务分别是LU分解、Cholesky分解和QR分解的基准程序.通过改变单次任务的强度(1,2,4,8倍强度)和运行任务时进行的数据传输大小(1 MB,5 MB,10 MB,20 MB,50 MB)来探索本文的适用范围和性能.选择最高8倍的单次任务强度系数,是因为其所对应的时间已接近集群的单任务时间上限,高时间消费的单次任务在集群容错机制下,性能会下降得更加严重.选择最大50 MB的数据传输大小是因为在实际的应用中单次的任务数据量一般不会超过50 MB.而对于超过的任务,应该首先考虑是否应该将任务分拆成多个进行.

Fig. 5 Test results of benchmark programs of LU, QR, Cholesky algorithms in different clusters.图5 LU,QR,Cholesky算法基准程序在不同集群环境下的实验结果
本文还选取了一个对5万张图片进行多种特征提取和聚类索引的MapReduce 操作的应用实例.该应用使用了GPU加速的图片颜色和纹理LBP特征提取的Map操作,并在Reduce操作使用K-means算法对图片特征进行聚类[21].
由于实验环境的限制,本文使用了Cluster4-2(4个节点中2个节点拥有GPU),Cluster4-3(4个节点中3个节点拥有GPU)和Cluster4-4(4个节点中4个节点拥有GPU)这3种集群环境进行测试,并与没有使用本文方法(Cluster4-0,即4个节点都是用CPU进行计算)的环境进行对比.
3.3实验数据及分析
图5给出了由MAGMA矩阵计算中LU分解、Cholesky分解和QR分解算法Benchmark集群应用在使用不同的单次任务强度(1,2,4,8倍强度)和任务数据传输大小(1 MB,5 MB,10 MB,20 MB,50 MB)条件下,在Cluster4-4,Cluster4-3,Cluster4-2环境运行的时间与未使用本文方案的Cluster4-0环境运行时间的加速比折线图.
从不同的集群环境上看,Cluster4-2和Cluster4-4都出现了与GPU个数相匹配的加速比,并且LU和Cholesky算法在单次任务强度增大到8倍时出现了高于单机环境下的加速比情况.这主要是因为随着任务强度的增大,CPU算法耗费的时间过长,会更多地触发集群容错中的机制保证集群的正常运转,例如推测式执行等.但是本文方案中的任务异步执行和GPU加速的方法防止了这样的情况发生.
Cluster4-3也出现了一定的加速比,但是因为其在进行动态节点捆绑策略时,无法均匀地将有GPU节点和没有GPU节点绑定,造成了2个节点各独立使用1个GPU而另外2个节点共用1个GPU的不平衡.同时,Cluster4-2在节点绑定后,出现2个节点共用1个GPU、另2个节点也共用1个GPU的拓扑结构,与Cluster4-3不平衡的拓扑同构,因而其加速比曲线与Cluster4-2基本重合.这种GPU分配不均匀的问题,在集群节点个数增多的情况下会有一定程度的改善.
从单次任务强度变化上看,LU,Cholesky,QR这3个算法在不同集群环境下,加速比除了在强度为1的情况外,都会随着单次任务强度的升高而变大,单次任务强度与加速比成正相关.而强度为1时出现的个别数据不符合正相关曲线情况,是因为整个集群启动时间在运行时间较短的应用中影响更大.
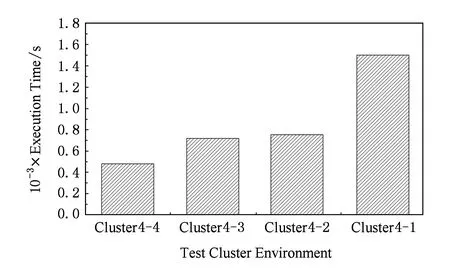
Fig. 6 Test result of the application for pictureextraction and clustering.图6 图片特征提取聚类应用程序的实验结果
从数据传输大小变化上看,LU,Cholesky,QR这3个算法在不同集群环境下,其加速比都没有表现出与数据传输大小之间的正反相关性,因此可以认为单次任务的数据传输大小在对整个应用的运行时间并没有明确的正反相关性.
图6给出了5万张图片进行特征提取和聚类的MapReduce操作的应用实例在不同集群环境下的运行时间柱状图.从实验数据可以看出,应用实例的运行时间基本能够随着集群节点中增加GPU计算资源而显著地减少运行时间.虽然在Cluster4-3环境下出现了与Benchmark应用程序相同的情况导致与Cluster4-2运行时间相同,但这种情况在集群节点个数增多时能够得到改善.
4结论
本文方案使用了集群计算加速部件统一管理、动态节点捆绑和流水线式计算加速部件任务调度策略,对原有的YARN架构进行了改进,增加了对包括GPU和Intel MIC在内的计算加速部件资源的调度和管理,使得在全部或部分节点配置计算加速部件的分布式系统中,能够较好地对集群中的计算加速部件进行利用.本文通过在4台节点组成的带有GPU计算加速部件的集群环境中,使用LU,QR,Cholesky分解算法以及5万张图片特征提取及聚类索引的应用实例,对本文方案进行了实验测试,实验结果验证了本文方案的有效性.
5未来工作展望
针对实验结果中Cluster4-3出现的性能问题,可以将现有方案中对节点的捆绑更加细化为基于Container的绑定,即在RM中维护的不再是节点间的捆绑关系,而是每个节点上的Container之间的捆绑关系.这样,就会更为细粒度地对集群资源进行分配和共享.但是也会遇到一些困难,例如Container并非真正的物理模块,而是由YARN对节点内资源进行隔离产生的逻辑模块,它的产生和销毁会更加灵活和频繁,这对整个管理模块的调度策略和性能是个挑战.
再者,可以对计算加速部件的性能建立权值表,并按照节点的权值信息优化动态捆绑策略.因为在本文当前的版本中,节点上的计算加速部件只是无与有之分,但是在实际环境中,不同型号和性能的计算加速部件可能同时存在于一个集群中.因此,如果建立一个性能的权值表,动态生成或者让用户自己修改和维护这个表格,并根据权值信息优化动态捆绑策略,这样就可以更好地利用不同的计算加速部件,从而实现效率的提升.
参考文献
[1]Vinod V, Arun M, Chris D. Apache Hadoop YARN: Yet another resource negotiator[C] //Proc of SoCC’13. New York: ACM, 2013: 5
[2]Jeffrey D, Sanjay G. MapReduce: Simplified data processing on large clusters[C] //Proc of OSDI’04. Berkeley, CA:USENIX Association, 2004: 135-150
[3]Apache Spark: Lightning-fast cluster computing[EB/OL]. [2014-07-31]. https://spark.apache.org
[4]Apache Storm: Distributed and fault-tolerant realtime computation[EB/OL]. 2014 [2015-07-31]. https://storm.apache.org
[5]Jeff S, John O. Multi-GPU MapReduce on GPU clusters[C] //Proc of IPDPS’2011. Piscataway, NJ: IEEE, 2011: 1068-1079
[6]Liu Mingliang, Jin Ye, Zhai Jidong. ACIC: Automatic cloud I/O configurator for HPC applications[C] //Proc of SC’13. Piscataway, NJ: IEEE, 2013: 1-12
[7]Li Xiaobing, Wang Yandong, Jiao Yizheng, et al. CooMR: Cross-task coordination for efficient data management in MapReduce programs[C] //Proc of SC’13. Piscataway, NJ: IEEE, 2013: 1-11
[8]Max G, Mauricio B, Vivek S. HadoopCL: MapReduce on distributed heterogeneous platforms through seamless integration of Hadoop and OpenCL[C] //Proc of IPDPSW’13. Piscataway, NJ: IEEE, 2013: 1918-1927
[9]Gunho L, Byung-Gon C, Randy H. Heterogeneity-aware resource allocation and scheduling in the cloud[C/OL] //Proc of HotCloud’11. Berkeley, CA: USENIX Association, 2011 [2014-07-31]. http://static.usenix.org/event/hotcloud11/tech
[10]Faraz A, Srimat C, Anand R, et al. Tarazu: Optimizing MapReduce on heterogeneous clusters[C] //Proc of ASPLOS’12. New York: ACM, 2011: 61-74
[11]Fengguang S, Jack D. A scalable framework for heterogeneous GPU-based clusters[C] //Proc of SPAA’12. New York: ACM, 2012: 91-100
[12]Kuen T, Wayne L. Axel: A heterogeneous cluster with FPGAs and GPUs[C] //Proc of FPGA’10. New York: ACM, 2010: 115-124
[13]George B, Aurelien B, Anthony D, et al. DAGuE: A generic distributed DAG engine for high performance computing[J]. Parallel Computing, 2012, 38(1): 37-51
[14]Cédric A, Jérme C, Samuel T, et al. Data-aware task scheduling on multi-accelerator based platforms[C] //Proc of the 16th IEEE Int Conf on Parallel and Distributed Systems. Piscataway, NJ: IEEE, 2010: 291-298
[15]Vignesh T R, Michela B, Gagan A, et al. ValuePack: Value-based scheduling framework for CPU-GPU clusters[C] //Proc of SC’12. Piscataway, NJ: IEEE, 2012: 1-12
[16]Jungwon K, Sangmin S, Jun L, et al. SnuCL: An OpenCL framework for heterogeneous CPU/GPU clusters[C] //Proc of ICS’12. New York: ACM, 2012: 341-352
[17]Wittek P, Darányi S. Accelerating text mining workloads in a MapReduce-based distributed GPU environment[J]. Journal of Parallel and Distributed Computing, 2013, 73(2): 198-206
[18]Zhai Yanlong, Luo Zhuang, Yang Kai, et al. High performance massive data computing framework based on Hadoop cluster[J]. Computer Science, 2013, 40(3): 100-103 (in Chinese)(翟岩龙, 罗壮, 杨凯, 等. 基于Hadoop的高性能海量数据处理平台研究[J]. 计算机科学, 2013, 40(3): 100-103)
[19]Apache Hadoop. Apache Hadoop: Apache Hadoop nextgen MapReduce[EB/OL]. [2014-07-31]. http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
[20]Innovative Computing Laboratory (ICL) of University of Tennessee. MAGMA: Matrix algebra on GPU and multicore architectures[EB/OL]. [2014-07-31]. http://icl.cs.utk.edu/magma/news/index.html
[21]Wang Xiangrong, Gao Fei, Li Qin, et al. GPU-based acceleration of local binary pattern algorithm for Internet applications[J]. Computer Engineering and Science, 2013, 35(11): 153-159 (in Chinese)(王香荣, 高飞, 李钦, 等. 面向互联网应用的图像LBP算法GPU并行加速[J]. 计算机工程与科学, 2013, 35(11): 153-159)

Li Qin, born in 1989. Master. His main research interests include distributed system and high performance computing.

Zhu Yanchao, born in 1989. PhD candidate. His research interests include high performance computer architecture and distributed systems (zyc0627cool@163.com).

Liu Yi, born in 1968. Professor of Beihang University since 2006, and associate professor of Xi’an Jiaotong University from 2001 to 2006. Received his PhD degree in computer science from Xi’an Jiaotong University. His main research interests include high performance computing and computer architecture (yi.liu@jsi.buaa.edu.cn).

Qian Depei, born in 1952. Master in computer science, professor of Beihang University, director of the Sino-German Joint Software Institute. Fellow member of China Computer Federation. His current research interests include high performance computer architecture and implementation technologies, multicoremany-core programming, distributed systems, overlay networks, and network measurement (depeiq@buaa.edu.cn).
Accelerator Support in YARN Cluster
Li Qin, Zhu Yanchao, Liu Yi, and Qian Depei
(SchoolofComputerScienceandEngineering,BeihangUniversity,Beijing100191) (BeijingKeyLaboratoryofNetworkTechnology(BeihangUniversity),Beijing100191)
AbstractAccelerators, such as GPU and Intel MIC, are widely used in scientific computing and image processing, and have strong potentials in big data processing and HPC based on cloud platform. YARN is a new generation of Hadoop distributed computing framework. Its adoption of computing resources is only limited to CPU, lacking of support for accelerators. This paper adds the support to nodes with accelerators to YARN to solve the problem. By analyzing the problem of supporting heterogeneous node, there are three identified difficulties which should be solved to introduce hybrid�heterogeneous to YARN. The first one is how to manage and schedule the added accelerator resources in the cluster; the second one is how to collect the status of accelerators to the master node for management; the third one is how to address the contention issue among multiple accelerator tasks concurrently running on the same node. In order to solve the above problems, the following design tasks have been carried out. Resource encapsulation which bundles neighbor nodes into one resource encapsulation is designed to solve the first problem. Management functions which collect the real-time accelerators status from working nodes are designed on the master node to solve the second problem. Accelerator task pipeline which splits accelerator tasks into three parts and executes them in parallel is designed on the nodes with accelerators to solve the third problem. Our scheme is verified with a cluster consisting of 4 nodes with GPU, and the workload testing the cluster includes LU, QR and Cholesky decomposition from the third party benchmark MAGMA, and the program performes feature extraction and clustering upon 50000 images. The results prove the effectiveness of the scheme presented.
Key wordsdistributed system; yet another resource negotiator (YARN); accelerator; heterogeneous nodes; graphics processing unit (GPU); node binding; task scheduling
收稿日期:2014-12-10;修回日期:2015-09-22
基金项目:国家“八六三”高技术研究发展计划基金项目(2012AA01A302);北京市科学研究与研究生培养共建项目
中图法分类号TP316.4
This work was supported by the National High Technology Research and Development Program of China (863 Program) (2012AA01A302) and the Scientific Research and Graduate Student Education Project of Beijing.
