OpenSPARC T1处理器Cache的优化研究
2016-07-18侯泽君张多利贾鼎成卢方全
侯泽君,张多利,贾鼎成,卢方全,施 莹
(合肥工业大学 电子科学与应用物理学院,安徽 合肥 230009)
OpenSPARC T1处理器Cache的优化研究
侯泽君,张多利,贾鼎成,卢方全,施莹
(合肥工业大学 电子科学与应用物理学院,安徽 合肥230009)
摘要:文章以OpenSPARC T1处理器为例,分析了片上多线程结构(chip multi-threading,CMT)处理器由于Cache抖动引发的缓存冲突等问题,通过引入空间锁环机制,减少程序中循环体被替换出Cache的概率,降低Cache冲突,从而提高多线程处理器性能。结果表明,使用空间锁环机制有效降低了缓存延迟和Cache的失效率。
关键词:OpenSPARC T1处理器;Cache抖动;空间锁环
近年来,UltraSPARC系列处理器已成为处理器新的发展方向。片上多线程结构(chip multi-threading,CMT)处理器指具有支持多个硬件线程能力的一种处理器结构,且其处理器的内核能够维护各线程独立的处理状态并迅速切换线程,从而避免了把时间浪费在等待线程的响应上。实际上CMT是一种将单芯片多处理结构(chip multi-processing,CMP)和同步多线程结构(simultaneous multi-theading,SMT)相结合的新兴技术,即用SMT处理器置换CMP中的各个单线程处理器内核,使得多线程处理器构造对称多处理结构(symmetric multi-processing,SMP)方式运作的线程级并行(thread-level parallslism,TLP)系统[1]。显然CMT具有功耗低、控制逻辑单元简单、扩展性能好且易于实现等优点,除此之外还具有片内高带宽通讯等特点。
在CMT处理器中,Cache作为重要的单元模块,组成结构分为存储体、地址转换设备和替换设备3个部分[2]。存储体用来保存内存数据的映射,地址转换设备用目录表实现Cache地址和内存地址的相互转换,替换设备在Cache空间不足时根据预置的算法规则来替换数据块,为即将到来的数据块腾出空间,并且修改地址转换设备中对应的目录表。TLP系统中多核处理器的并行线程运行,会导致各线程之间的竞争和核心对共享资源Cache的竞争[3]。
本文采用的OpenSPARC T1处理器是UltraSPARC系列的开源版,其8个处理器核心所支持的大量线程将会导致Cache竞争愈发激烈。本文分析结果表明,片内高速Cache的优化机制对处理器的整体性能提升有着不可替代的作用。
1OpenSPARC T1处理器简介
基于64位SPARC V9体系架构的OpenSPARC T1处理器是Sun公司的第一款单芯片多线程处理器。该处理器主要应用于高数据吞吐领域,例如个人用户或商业数据库方面等。
OpenSPARC T1处理器包含有8个SPARC V9 处理器核。每个核在硬件上支持4个线程,并含有一级指令缓存(L1-I-Cache)、一级数据缓存(L1-D-Cache)、1个全相联指令和数据快表(translation lookaside buffer,TLB)。每个在SPARC核中的L1-Cache,都采用了4路组相联结构,其中L1-I-Cache和L1-D-Cache的容量分别为16 kB 和8 kB,块大小为32 B。通过高速交叉开关(cpu-cache cross bar,CCX),8个核与片上L2-Cache及其他功能单元相连,其中L2-Cache采用12路组相联结构,以共享结构相互联系。
4个片内的动态随机存取存储器(dynamic random access memory,DRAM)直接和双倍数据速率异步DRAM (DDR2 SDRAM)进行相互连接。此外,片内还有1个J-Bus控制器可以提供OpenSPARC T1处理器与I/O子系统之间相互连接。
2Cache抖动现象
对于多线程的OpenSPARC T1处理器,尤其是应用于延时要求严苛的情况下,如果其他线程与主线程频繁地竞争Cache,将导致系统总体的性能下降,使得延时大幅增加,最终无法完成实时任务。Cache抖动指多个线程不停重复地访问共享Cache资源,从而会造成处理器性能大幅降低。Cache抖动如图1所示。
在多线程共享的L1-I-Cache中,第K块被线程T1的指令I1占用,当线程T2需要将指令I2调入该块时,即使L1-I-Cache此时仍有未被占用的空闲块,也会将第K块中线程T1的指令作废并换出;而当线程T1又需要指令I1时,就必须用指令I1替换掉指令I2,将其重新调入第K块;然后线程T2又会重复上一操作,这就产生了Cache抖动问题。特别是当这种情况发生在线程的循环处时,其危害更明显。在最差的情况下,单独运行1个线程的性能都要高于2个线程同时运行的性能,线程并行越多,危害则越大[4]。
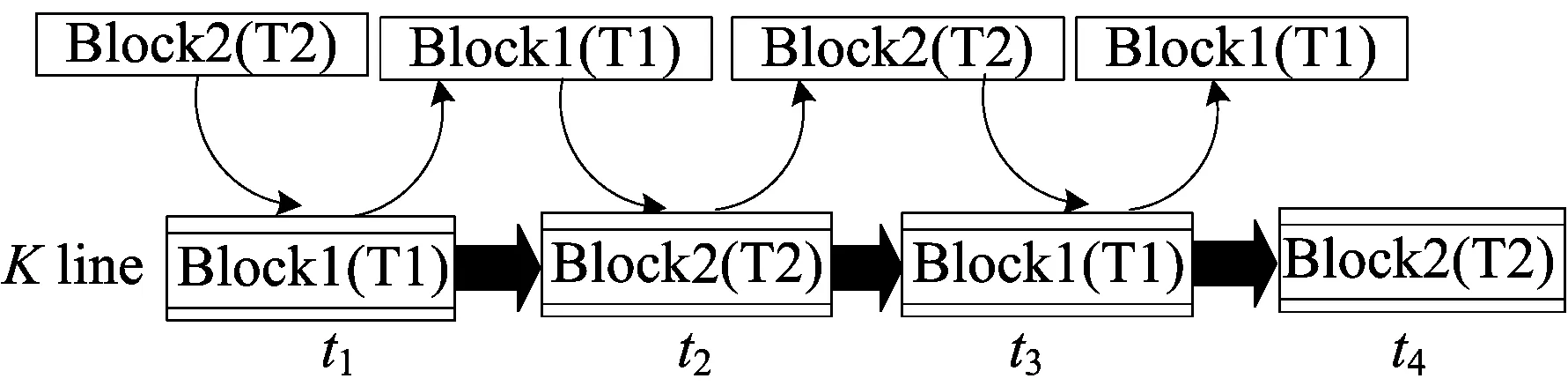
图1 Cache的抖动
程序设计中有一条“二八”法则[5],即20%的程序会占用80%的执行时间。该法则在数字信号处理中尤其显著,由于数字信号处理(digital signal processing,DSP)应用程序的核心通常都是循环体,很多情况下10%的核心循环程序就可能占用了80%以上的执行时间,同时运行多个程序将导致严重的Cache抖动现象,这使得一个线程的执行时间大大延长。如果Cache抖动发生在实时系统中,可能会因为无法满足实时性要求而导致严重的后果。因此在OpenSPARC T1等CMT处理器中,应该尽量保证高优先级线程的循环体得到优先执行。
另外,与单线程处理器相比,CMT处理器资源消耗多、控制复杂。因此,在CMT处理器中优化线程,在增加很少硬件的情况下,以低硬件成本换取高性能,尽可能地保证高优先级线程得到优先执行[6]。
3处理器的一级Cache优化
针对Cache抖动现象,本文提出了一种L1-Cache的优化思路,即循环竞争的空间锁(简称“空间锁环”)。在增加很少硬件资源的条件下,最大程度地减少循环体替换的方法。通过在OpenSPARC T1 处理器的SPARC核中设置几个寄存器,组成空间锁环,使之能够锁定L1-Cache中的某几块不被替换,但仍然可以被读和写。当线程运行循环代码时,会竞争空间锁环,竞争到空间锁环后将这段循环代码锁定在Cache中,从而避免了将该线程循环代码替换出Cache,有效减少了Cache冲突。以OpenSPARC T1处理器的I-Cache为例,空间锁环的2种状态如图2所示。
图2中,空间锁环由2个索引寄存器Ind-B、Ind-E和1个1位的锁定寄存器Lock组成。若Cache的容量为L,则索引寄存器Ind-B和Ind-E的容量W为:
W=lb L
(1)
为了实现空间锁环,传统的做法是再设置3个寄存器来控制循环代码的开始、结束和锁定状态,但同时增加了额外的硬件开销。
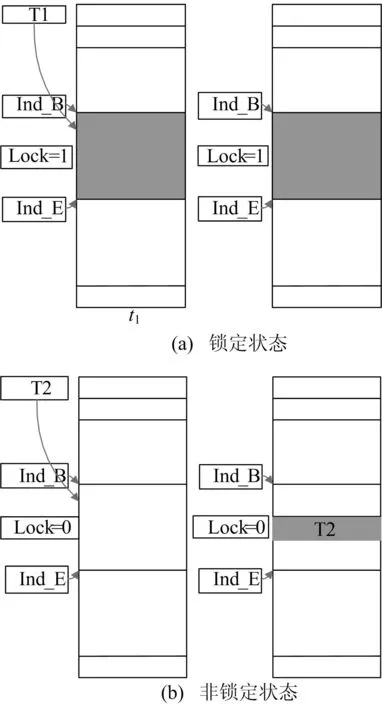
图2 空间锁环的锁定状态和非锁定状态
本文采用软硬件结合的优化思路,在编译器中添加loopb、loope、loopf 3条指令,用来实现3个寄存器的功能。使用编译器进行编译时,若检测出线程中的循环代码,则在其初始位置插入loopb、结束位置插入loope、出口位置插入loopf即可。
空间锁环在工作时,工作流程可划分为竞争、锁定、循环3个阶段,具体如图3所示。
(1)竞争。线程T1在运行时,若检测到loopb指令,表示将有一段循环代码开始运行,线程T1将与其他线程竞争空间锁环。竞争成功则进入锁定阶段,竞争失败则被挂起,待空间锁环空出后重新参与竞争。
(2)锁定。若线程T1竞争到空间锁环,则根据指令寄存器PC的索引值立即修改索引寄存器Ind-B,同时将锁定寄存器Lock置为1,标志空间锁环开始锁定。在继续运行过程中,索引寄存器Ind-E随着指令寄存器PC的变化而修正,不断锁定“自由”的Cache空间,直到检测出loope指令。此时,线程T1的循环代码就被锁定在由寄存器Ind-B和寄存器Ind-E标识出的空间锁环中,其他线程的指令将不能替换空间锁环中的Cache块。
(3)循环。线程T1的循环代码在空间锁环中不断循环,直到检测出loopf指令,表示循环已结束,锁定寄存器Lock被置为0,线程T1离开空间锁环,其他等待中的线程可以继续参与空间锁环的竞争。
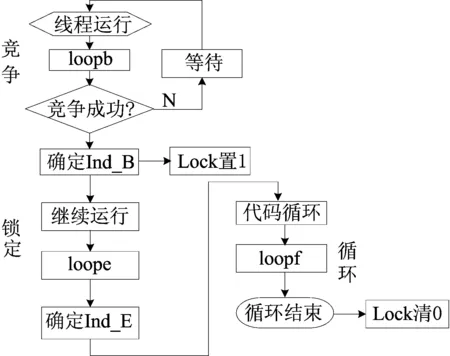
图3 空间锁环工作流程
从空间锁环的工作机制可以看出,空间锁环通过增加硬件代价较小的3个锁存器,成功地对Cache抖动进行了优化。本文以OpenSPARC T1处理器的L1-I-Cache为例,对空间锁环的收益进行分析。
假设OpenSPARC T1处理器有2个线程同时运行,L1-I-Cache每个块内有NC条指令,最多可接受K条指令,当发生缺失时,L1-I-Cache需要TM个时钟周期从L2-Cache中调入数据,线程T1中的循环代码指令数为NT1,程序的循环次数为C,线程T1的循环代码运行时,线程T2顺序执行。
根据以上条件,L1-I-Cache每发生1次替换操作,延迟为:
(2)
循环代码在L1-I-Cache中所占行数为:
(3)
假设线程T1、T2执行速度相同,则使用空间锁环优化前发生替换的次数为:
(4)
若Dloop为线程T1的整个循环代码部分从L2-Cache调入L1-I-Cache的延时,则使用空间锁环后,延时减少了Dall,具体公式为:
(5)
4实际优化结果
为了验证空间锁环的实际效果,现利用OpenSPARC T1处理器对T1线程及T2线程的表现进行评析。
在OpenSPARC T1中,L1-Cache分为L1-I-Cache和L1-D-Cache,可寻址的空间为4 GB,L1-I-Cache的大小为 16 kB,块大小为32 B,宽度为 256位宽(32字节),共 512个块[7]。
因为L1-I-Cache的容量为512行,根据(1)式,索引寄存器Ind-B和Ind-E的容量都是9位。当L1-I-Cache发生缺失时,一个块的替换操作延时是22个时钟周期。取L1-I-Cache每个块内有8条指令,线程T1执行一段循环长度为256条的指令,连续执行100次;同时线程T2按顺序执行,在发生竞争时启用空间锁环,按优先级的顺序,而对于同一优先级的线程,则按先入先出(first input first output,FIFO)策略。根据(5)式,可得空间锁环节省的延时为4 400。
5结束语
在OpenSPARC T1处理器中由于多线程并行竞争Cache等资源引发Cache抖动,使得每个线程的延时上升,效率降低,导致不能满足即时性要求。如果Cache抖动现象过于严重,多线程处理器的性能甚至不如单核单线程处理器表现良好。本文采用空间锁环降低Cache的冲突,可以尽量避免线程中的循环体被替换出Cache。分析结果表明,启用空间锁环不仅使得Cache冲突减小,Cache的失效率降低,而且主线程的性能也得到了较大程度的提升。采用软硬技术相结合的空间锁环,仅增加了几个寄存器和移位器,大大减少了优化花销,对高性能多核处理器设计中的Cache设计具有一定的借鉴意义。
[参考文献]
[1]方娟,张红波.多核处理器预取策略的研究[J].微电子学与计算机,2010,27(8):74-76.
[2]黄鹏.CMT:处理器吞吐量倍增的秘诀[J].程序员,2006(5):122-124.
[3]王晶,张盛兵,张萌,等.CMT结构资源共享问题及争用缓解机制研究 [J].微电子学与计算机,2007,24(6):1-4.
[4]贺荣华.一种超长指令字同时多线程处理器的设计与分析[D].长沙:国防科学技术大学,2005.
[5]马鹏勇.CMT处理器高速缓存的优化技术[D].长沙: 国防科学技术大学,2007.
[6]唐轶轩.面向多线程应用的Cache优化策略及并行模拟研究[D].合肥:中国科学技术大学,2012.
[7]胡小龙,杨蕊.OpenSPARCT1处理器Cache机制研究及优化[J].微计算机信息,2009,25(1/2):267-268,271.
(责任编辑闫杏丽)
Optimization of the Cache in OpenSPARC T1 processor
HOU Ze-jun,ZHANG Duo-li,JIA Ding-cheng,LU Fang-quan,SHI Ying
(School of Electronic Science and Applied Physics,Hefei University of Technology,Hefei 230009,China)
Abstract:Taking OpenSPARC T1 processor as an example,the Cache conflicts caused by the Cache thrashing in the chip multi-threading(CMT)processors are discussed. On this basis,the circular locking mechanism of space is introduced to reduce the probability of being replaced from the Cache and avoid Cache conflicts in the loop body,so as to improve the performance of multi-threading processor. The result shows that the cache latency and the failure rate of the Cache are reduced by using the circular locking mechanism.
Key words:OpenSPARC T1 processor;Cache thrashing;circular locking mechanism of space
收稿日期:2015-03-10;修回日期:2015-04-13
基金项目:国家自然科学基金资助项目(61106020);合肥工业大学大学生创新性实验计划资助项目(201510359038)
作者简介:侯泽君(1988-),男,陕西宝鸡人,合肥工业大学助教; 张多利(1976-),男,黑龙江齐齐哈尔人,博士,合肥工业大学研究员,硕士生导师.
doi:10.3969/j.issn.1003-5060.2016.06.014
中图分类号:TP302.7
文献标识码:A
文章编号:1003-5060(2016)06-0786-04
