基于案例推理的矿井风机故障诊断系统的研究∗
2016-07-18李林琛张春芝杨德亮北京工业职业技术学院北京市石景山区100042
李林琛 张春芝 杨德亮(北京工业职业技术学院,北京市石景山区,100042)
★煤炭科技·机电与信息化★
基于案例推理的矿井风机故障诊断系统的研究∗
李林琛 张春芝 杨德亮
(北京工业职业技术学院,北京市石景山区,100042)
摘 要为了提高矿井风机故障诊断的准确率,结合案例推理研究设计了矿井风机故障诊断系统,该系统引入了群决策思想对多种相似度指标进行了综合,从而解决了因单一相似度指标对系统诊断结果带来的不确定性上的弊端,仿真试验表明,该系统能够有效地诊断出风机故障,能够高效地对风机的运行状态进行分析判断,为矿井安全提供了相应的保障。
关键词矿井风机 故障诊断 案例推理 群决策
矿井风机是煤矿企业生产的核心设备,其运行的安全性与可靠性直接决定着煤矿的安全生产能力。因此,对煤矿风机进行故障诊断十分必要,这样能对风机故障、隐患以及不良反应等做到早发现和早处理,保障设备安全、可靠、高效、经济地运行。而如何准确地判断风机的运行状态,及时发现故障征兆,并对出现的故障进行准确有效地分析和判断,已成为煤矿生产和故障诊断方面亟需解决的问题。
目前,常见的矿井风机故障诊断方法主要包含基于数据驱动的方法(如PCA、PLS等)和人工智能的方法(如神经网络、专家系统等),然而这些方法均存在相应的弊端,如为了保证神经网络的准确性,需要大量历史数据进行训练,这对于进行故障诊断的系统往往是无法实现的。因为故障具有突发性、不可逆性和破坏性,因此在实际中难以得到大量的训练样本,从而会影响到诊断的准确性与可靠性。此外,利用专家系统需要得到大量的规则,而此规则获取较为困难也限制了该方法的进一步发展,因此,急需确定新的方法对矿井风机进行诊断。
1 案例推理与问题分析
1.1 案例推理
案例推理(Case-Based Reasoning,CBR)崛起于20世纪80年代,其推理思想模拟了人类认知新事物的思想,即利用过往的知识经验来解决新问题,与专家系统不同的是案例推理的知识是某一领域以往处理过的,而经验案例,很大程度上避免了知识获取困难的问题,而且不用建立复杂的数学模型,适用于经验占主导或建模困难的领域。为了提高矿井风机故障诊断的准确率,保证风机的运行可靠性,本文针对案例推理的关键步骤案例检索环节进行了改进,通过引入群决策思想解决了因单一相似度指标带来的诊断不确定性,增强了诊断结果的可靠性,矿井风机的安全性得到进一步的保障。
案例推理是利用过往知识经验解决当前问题的方法,其推理过程包括案例检索(Retrieve)、案例重用(Reuse)、案例修正(Revise)和案例保存(Retrain),案例推理过程流程图如图1所示。

图1 案例推理过程流程图
利用CBR进行风机故障诊断的流程可描述为以下4个过程:
(1)构造风机案例库,将实际运行过程中积累的故障以及正常的案例表示为如下的二元组形式:
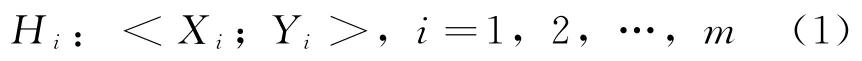
式中:Hi——历史案例;
m——故障源案例的总数;
Xi——第i个故障案例的特征属性,Xi可用特征值描述法表示;
Yi——第i个故障案例的诊断结果。
(2)记目标案例为T=(t1,t2,…,tj,…,tn),对应的分类结论为YT。为了得到YT的分类结论,需要评估案例库中每个故障源案例与目标案例T的相似度,一般采用K最近邻(K-Nearest Neighbor,KNN)检索策略去计算二者的相似度值:

式中:similarityi——Xi与T的相似度,similarityi∈[0,1];
dis1(T,Xi)——目标案例与历史案例的欧氏距离。
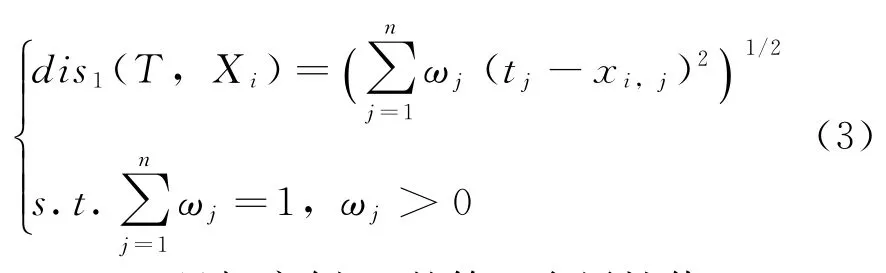
式中:tj——目标案例T的第j个属性值;
xij——第i个历史案例的第j个属性值;
ωj(j=1,2,…,n)表示第j个特征属性的权重,传统的做法是取均权重。
由式(2)可以得到m个相似度s1~sm,并将其按照降序排列,在此基础上得到前K个相似度所对应的源案例及其对应的诊断结果。
(3)在上述得到的K个相似度对应的故障源案例中,可采用最大相似度重用方式(K=1)或多数重用方式(K>1且为奇数)获得目标案例T的建议诊断结果。
(4)将目标案例T与分类结果YT表示为式(1)所述的二元组形式存储于案例库中,供后续的诊断案例使用。
1.2 问题分析
上述为利用案例推理进行风机故障诊断的一般流程,然而由于矿井风机的重要性,在利用CBR进行故障诊断时,需要保障诊断的准确率以及诊断的可靠性。
由上述介绍可知,案例检索在CBR中处于首位,对整个系统的运行效果起到了关键作用,检索质量的好坏直接影响着风机故障诊断的结果。传统的CBR系统通常采用KNN策略进行检索,而KNN是一种基于相似度的检索策略以距离的指标,通常采用单一的欧式距离指标进行计算。然而,由于风机系统较为复杂,采用单一的距离指标无法满足应用需要且可信度不高,会影响相似度的计算进而导致诊断准确率的下降。因此,为了提高检索的准确率和保障风机运行的可靠性,本文在案例检索阶段引入了群决策检索思想结合多种相似度评价指标,通过对多种距离指标进行了综合从而给出最终的检索结果。
2 基于案例推理的风机故障系统
通过案例推理与问题分析,结合矿井风机给出了改进的基于案例推理的矿井风机故障诊断系统,系统框架图如图2所示。

图2 基于案例推理的矿井风机诊断系统框架图
通过图2可以看出,该矿井风机的诊断系统运行过程为:首先构造矿井风机的故障案例库,将历史运行数据表示成运行特征与运行状态的向量组;当系统运行时,新产生的运行数据通过预处理后进入诊断环节,利用群决策改进的KNN检索策略得到与当前运行状态最相似的历史案例出来,并将最为相似案例的诊断结果进行重用,再经由案例修正环节将诊断结果输出以供操作用户及时作出后续处理,最终将此新的案例存储进案例库中,完成风机的故障诊断过程。
2.1 群决策案例检索
由图2可知,案例检索是故障诊断系统中的关键环节,其检索质量的好坏直接影响着故障诊断的准确率与系统运行的好坏,目前常用的检索策略为KNN策略,采用的是欧式距离来衡量相似度的大小。然而,单一的距离指标不能够满足风机的实际诊断需求,有可能会为检索带来不确定性进而影响诊断的准确率。
为了解决上述问题,保证诊断的准确性与风机运行的可靠性,本文在欧式距离的基础上采用了多种相似度的计算方式。在KNN检索中,除了欧式距离,常见的计算相似度的指标还包括曼哈顿距离和高斯变换等。在得到多个相似度指标后,为了得到最后综合的相似度值,引入了群决策思想,将3种指标以某种集结方法进行综合来得到最终的群决策结果,群决策结合的相似度计算如图3所示。

图3 群决策结合的相似度计算
群决策是集数学、政治学、经济学、社会心理学、行为科学、管理学和决策科学等多门学科研究于一体的交叉学科。从认知科学的角度看,群决策是对群体认知能力的综合利用。在群决策过程中,一般是先由决策者(也称为专家)对共同的决策问题给出自己的判断,然后按照某种商定的预设规则进行群意见的集结,根据群的偏好得到最终的决策。群决策用于改进案例检索策略时,首先将各个相似度指标视为专家,然后将不同专家得到的相似度值通过某种集结方式得到最终的决策结果。采用群决策中一种常用的集结方式来得到最后的相似度结果见式(4):

式中:Sim——所有专家进行群决策得到的最终的相似度值;
simk——用不同距离公式计算得到的相似度;
ω′k——不同专家的决策权重,权重越大表示该专家的权威性越强,对最终结果的影响越大。
由此可见,利用群决策思想进行相似度的计算能够避免单一指标带来的不确定性,但同时由式(4)可看出,专家的权重对相似度的计算起着重要作用,如何对这些专家合理的分配相应的权重值也是提高风机诊断准确率的一个重点。
2.2 遗传算法优化群权重
针对式(4)中专家权重的确定问题,采用遗传算法对群决策集结方式中的专家权重进行优化分配,具体过程如下:
(1)编码。针对群决策中专家权重的优化问题,选择最常用的二进制编码,分别采用5位二进制编码对应32个等级,表示相应权值的大小。
(2)适应度函数。在遗传算法过程中,个体的选择交叉都是以染色体的性能为依据的。在遗传算法寻优过程中,一个良好的适应度函数能够指导寻优的方向。因此,定义如下的适应度函数:

式中:N——测试案例集的案例数量,该适应度函数表示在某权重组合条件下,N个测试案例中能够正确诊断的案例个数;
Nj——在得到权重组合后,第j个测试案例是否在历史案例中检索出正确的结论,如果为Nj=1,则表示正确分类,反之则为0。显然,该函数可以保证找到具有分类准确率高的专家权重组合,即最优解。
(3)选择。本节采用轮盘赌法选择合适的个体,每个个体的选择概率和其适应度成比例。设种群大小为Ps,其中每个个体的适应度为fi,则个体i被选择的概率为:

(4)交叉。交叉是把两个父个体的部分基因相互交换而生成新个体的操作。本文采用单点交叉,具体操作为:在个体基因串中随机设定交叉点,当进行染色体交叉时,两个体交叉点前后的基因互换,并生成两个新个体。
(5)变异。变异运算是产生新个体的辅助方法,它能够改善遗传算法的局部搜索能力,并防止出现早熟现象。本文采用基本变异算子,对群体中染色体随机挑选一个或几个基因位置以概率进行变异,进行取反操作。
(6)停止条件。本文设置迭代次数作为算法停止条件,当达到预设的迭代次数,遗传算法结束,输出最优个体即为最优的专家权重组合结果。
3 试验研究
为了验证本文所提方法的有效性,在试验中模拟了现场中常见的电机叶片不平衡的故障,即分别在风机叶片中加上配重块来获取风机的运行状态特征以及振动信号,包括水平方向的振动以及垂直方向的振动两种。配重块是模拟异物黏附的故障,模拟出的电机叶片不平衡的故障与矿井内现场实际效果一致,本文共采集了777组数据,其中包括281组正常运行状态下的数据、215组加入1个配重块后风机的运行状态数据以及281组加入2个配重块后风机的运行数据,具体监测曲线如图4所示。(图4为实际搭建的煤矿通风机监测平台中实时显示的风机的振动曲线,图中3个阶段显示的依次为实际系统中正常运行状态、加入1个配重块以及加入两个配重快的振动曲线)。
为了诊断出风机叶片的不平衡故障,本试验主要采集了9个风机运行中的状态参数作为诊断的特征属性,具体为:A相绕组组温、B相绕组组温、C相绕组组温、轴前温、轴后温、静压、风量、垂直振动值、水平振动值和诊断结果。为了减小试验产生的误差,采用了十折交叉验证方法对实际数据进行试验,设计实验方案如下:
(1)方案1传统CBR。考察在利用单一相似度计算指标条件下,利用KNN检索策略得到的诊断性能,其中检索时的属性权重为均权重,K=7。
(2)方案2群决策改进的CBR。考察利用群决策改进并利用遗传算法对群权重进行寻优的检索策略对诊断性能的影响,并增加了与其他常见诊断模型的性能对比(RBFNN,CART,Logistic,Naive Bayes)。
(3)方案3不同样本量。为考察不同样本量条件下对系统诊断性能的对比,分别选取原案例库样本量的10%、20%和50%条件下,考察本文方法对诊断性能的对比情况。依据上述试验方案,对采集到的风机运行数据进行诊断,首先将数据平均分为10份,选择其中9份构建历史案例库,剩余作为目标案例库;其次采用本文所提方法,分别采用不同的相似度计算方法并结合群决策思想得出最后的结果,其中群专家的决策权值由遗传算法进行优化搜索;最后将得到的诊断准确率与其他方法RBFNN、CART、Logistic和Naive Bayes进行诊断性能对比,得到的对比结果图5所示。
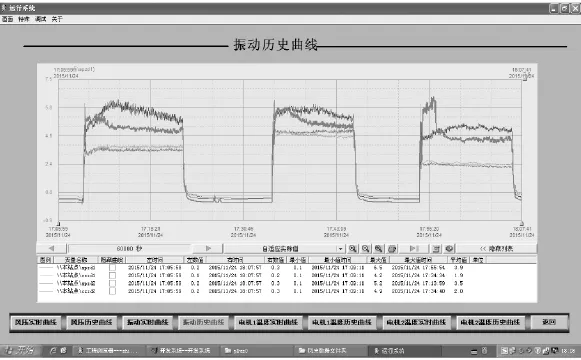
图4 实际系统中风机的震动曲线

图5 多种诊断策略对比
在试验中,涉及到一些参数需要进行设定,其中利用GA进行群决策专家权重的优化搜索中设定种群数量为20,交叉概率为0.3,变异概率为0.4,迭代次数30。由图5可看出,在5种诊断方法中,本文所提GCBR方法得到了最好的诊断准确率,与其他方法的诊断对比顺序为:GCBR>Logistic>RBFNN>Naive Bayes>CART。试验验证了本文利用群决策结合多种相似度计算方法的可行性,也表明了本文方法在风机故障诊断中的优越性。
为了考察在不同样本量条件下本文方法的诊断性能问题,实验分别选取原样本量的10%,20% 和50%作为训练集与历史案例库,此时上述5中诊断方法的诊断准确率对比结果见表3。
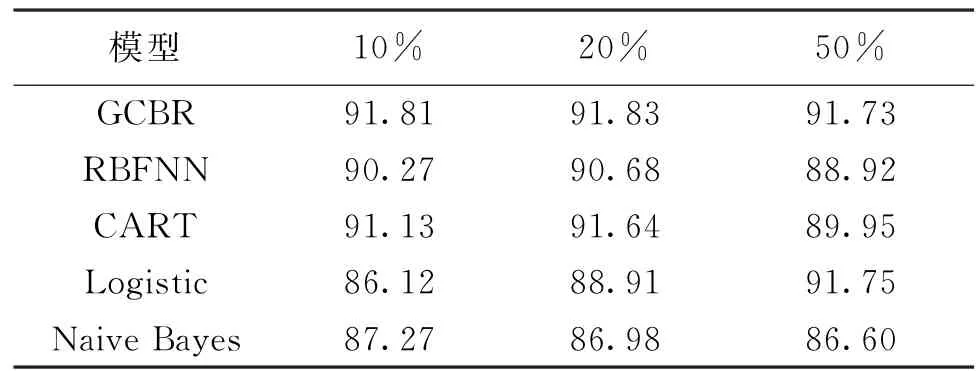
表3 不同样本量条件下本文方法的诊断性能
由表3可以看出,在不同的样本量条件下,5种策略均有不同的诊断准确率,其中本文方法与其他方法相比,样本量的变化对结果的影响要更小一些,表明在不同样本量的条件下,本文方法均能得到较好的诊断结果,这是由于案例推理包含案例存储的过程,初始的案例库规模对系统最后性能的影响要小。
4 结语
针对矿井风机的故障诊断问题,本文对基于案例推理的风机故障诊断系统进行了研究,为了保障该系统的故障诊断准确率,系统结合了群决策思想对案例检索阶段进行了改进,将多种相似度的计算指标视为专家,利用群决策集结方式得到合理的检索结果,并采用遗传算法对群专家的权重进行优化搜索。通过试验表明,与其他常见的诊断方法相比,本文所提方法得到了最优的诊断结果,且在不同的样本量条件对该方法的影响较小,表明了该方法的优越性,也验证了基于案例推理的风机故障诊断系统能够有效地提高矿井风机的故障诊断准确率,对于保障矿井的安全起到了良好的保障效果。
参考文献:
[1] 任宇.煤矿机电设备状态监测与诊断技术研究[J].煤矿现代化,2013(3)
[2] 李晶,刘国华.基于人工智能的煤矿风机故障诊断方法[J].煤矿机械,2013(12)
[3] 李蒙,刘保罗.混合推理实现矿井风机故障诊断系统设计[J].煤矿机械,2010(9)
[4] 陈雪峰,李继猛,程航等.风力发电机状态监测和故障诊断技术的研究与进展[J].机械工程学报,2011(9)
[5] 张红梅,赵建虎,代克杰.基于信息融合的风机喘振智能诊断方法研究[J].仪器仪表学报,2009(1)[6] 荆双喜,牛振华,华伟等.矿井通风机故障诊断专家系统的研究[J].煤矿机电,2007(1)
[7] 史忠植.高级人工智能[M].北京:科学出版社,2006
[8] 李伟,程晓涵,徐国贤.矿用主扇风机远程健康诊断系统的监测子站研究[J].中国煤炭,2014(7)
(责任编辑 路 强)
Research on fault diagnosis system for mine fan based on case-based reasoning
Li Linchen,Zhang Chunzhi,Yang Deliang
(Beijing Pollytechnic College,Shijingshan,Beijing 100042,China)
AbstractTo improve the accuracy rate of fault diagnosis for mine fan,a fault diagnosis system for mine fan based on case-based reasoning was researched and designed,the system,group decision was introduced to synthesize multiple similarity indexes,which solve the uncertain system diagnosis brought by single similarity index.The simulation experiment results showed that the system could effectively diagnose the faults and efficiently analyze the operating status of fan,so it could guarantee the mine safety.
Key wordsmine fan,fault diagnosis,case-based reasoning,group decision
中图分类号TD441
文献标识码A
基金项目:∗北京市属高等学校创新团队建设提升计划,北京工业职业技术学院科研项目(bgzykyz201402)
作者简介:李林琛(1982-),男,河南沁阳人,讲师,硕士,现任职于北京工业职业技术学院,主要研究方向为自动控制、传感与监测。
