数据挖掘技术识别可疑洗钱交易行为模式研究
2016-06-30郝建军翟岁兵刘冬付向艳
郝建军+翟岁兵++刘冬+付向艳
摘要:洗钱就是通过犯罪手段实现金钱合法化。而且洗钱犯罪还维系了其他的犯罪行为,也是维持犯罪之生命线。洗钱活动对正常经济与金融秩序造成扰乱,危害社会安全,尤其通过洗钱还助长了腐败风气蔓延。而数据挖掘技术能够快速处理大量的金融数据,识别可疑洗钱行为,让反洗钱过程的结构更加简单、更具有效率。该文阐述数据挖掘技术的流程,以聚类算法与具备孤立点的挖掘算法构建了CBLOF算法,在此基础上形成识别可疑洗钱行为模式方法,为防范洗钱交易提供参考依据。
关键词:数据挖掘技术;洗钱交易;模式
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)14-0204-02
1 前言
如今,我国对于反洗钱主要是金融机构依据相关管理办法上报可疑交易数据,对洗钱犯罪进行识别和调查。这种方法存在标准模糊、高误报率、海量数据以及缺乏自适应性等问题,对上报可疑交易数据的有效性与可靠性造成影响。在这种形势下,本文就提出了采用数据挖掘技术识别可疑洗钱数据,这种研究具有实用价值。
2 数据挖掘技术的流
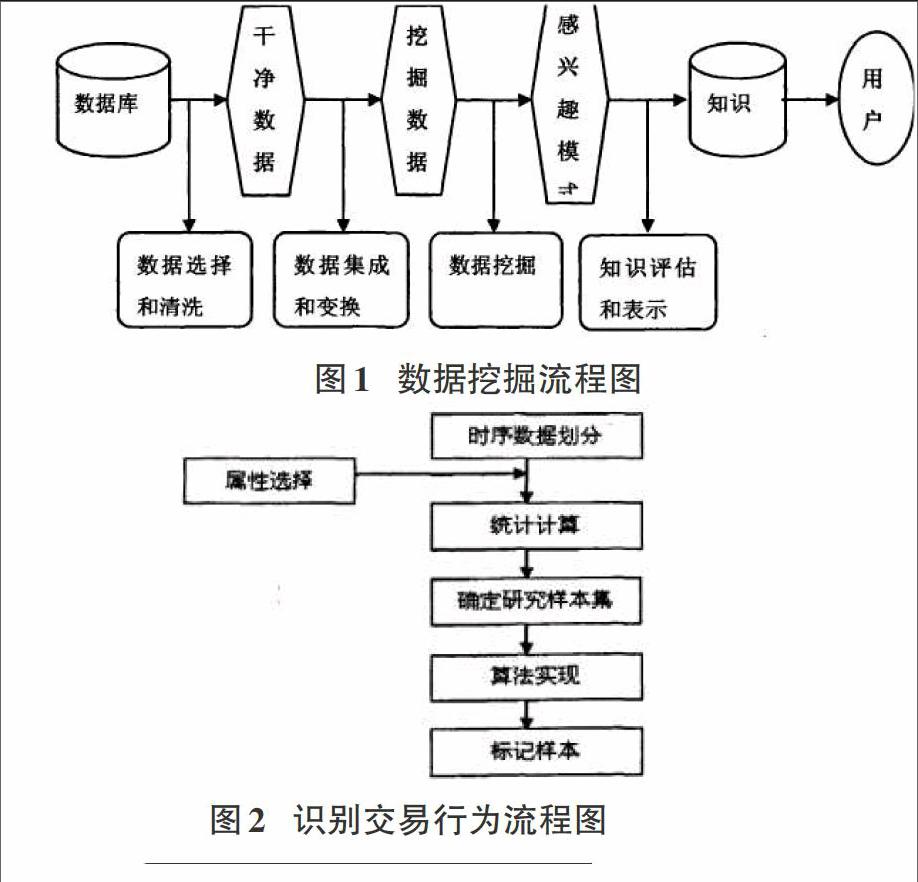
数据挖掘也称之为数据库知识发现。如今数据挖掘技术被应用到各个领域中,比如生物医学、金融、零售业以及工程和科学等各个领域中。数据挖掘技术能够快速处理大量的金融数据,识别洗钱行为,让反洗钱过程简单化、效率化。数据挖掘技术基本步骤如下图所示:
从上图来看,数据挖掘技术过程大致分成四个阶段:
(1)选择与清洗数据;当确定好数据挖掘对象时,就需要搜索所有和对象相关的外部与内部数据,就需要从中挖掘应用数据。但是现实中的数据都含有噪音的、不完全的、不一致数据,所以必须要清洗数据过程填充空缺值,消除噪声、识别孤立点,纠正数据中不一致。
(2)集成与转换数据;数据分析中常常要涉及数据集成,数据集成就是把多个数据源中数据共同存放到一个数据存储中。在合并多个数据源时,就必须要考虑到识别实体问题,就必须要将实体名称不同的合并在一起。有一些属性具有冗余性,可通过其他属性计算所得。数据转换就是要满足挖掘所需。
(3)挖掘数据;数据经过清洗,集成以及转化后,就进入到了挖掘数据阶段。挖掘数据就是选择适当的数据挖掘技术,比如聚类、神经网络、模式识别以及孤立点挖掘等等,然后依据所选数据挖掘技术确定具体算法,之后选定算法查找感兴趣模式。
(4)评估与表示知识;评估知识,如今主要是采用了兴趣度衡量真正感兴趣的知识。依据一定兴趣度的度量,评估数据挖掘结果,对有用部分进行筛选与评估,查找能够接受的结果。对于表示知识,如今较为流行的即为可视化技术,可视化即将数据、知识与信息转化成可视表示形式过程。
3 数据挖掘技术识别可疑洗钱交易
3.1 识别流程分析
识别可疑洗钱行为属于反洗钱数据调查,主要就是通过单笔账户的历史交易时序数据中各子序列比较分析,从中发掘值得怀疑交易数据。识别的基本思路如下图所示:
(1)时序数据划分:属于一个异常的检验体系中,即为一个单一数据点是不可能提供多少信息。真正需要是从数据中挖掘一些偏离正常数据数据模式。识别可疑洗钱行为,就需要将账户历史交易记录成一个个若干相邻单笔交易形成的交易子序列,从中挖掘可疑的行为模式,最后形成可疑交易数据。
(2)属性选择:识别可疑洗钱行为就是建立到清醒认识可疑交易特征属性上。只有选择属性较为科学、全面以及真实的描述偶然行为模式特征,选择方法识别这种行为的相关数据。
(3)统计计算:对于所选偶然可疑的洗钱行为的相关属性,计算出各个子序列属性值。子序列对应桌各行为模式就构成了属性特征的向量。
(4)确定样本集:每一个行为模式特征向量视为一个研究样本,账户上所有行为模式特征向量形成了样本集。
(5)算法实现:事实上,每一个账户中大多数交易行为均属正常化,或合法化,仅仅极少数交易行为存在可疑性。孤立点就是数据集中和大部分数据相偏离,出现偏离原有并非随机因素,主要是因为完全不同的生产数据机制。
(6)标记样本:依据样本的专家知识以及孤立因子值,标记出孤立最大因子值的N个样本,挖掘偶然可疑的洗钱行为模式。
本文对交易金额的属性分析、离散系数的属性分析作为重点说明。
(1)交易金额的属性分析:Tai(交易金额)即为每一个交易的子序列交易金额总和。假如某个账户第i个子序列中共有ni笔交易,每一笔交易金额[taij]依照时序排列是:[tai1、tai2...taint],那么账户的第i子序列交易金融是[Tai=j=1nitaij],由此可见,可以求出账户交易的所有n个子序列内交易金额:[Ta1、Ta2...Tan]。每一个子序列交易金额[Ta1、Ta2……Tan]以行业的规模特征向量中一个维度,经过比较分析,就能计算出偏离成都为总偏离程度中一部分。
本文选择交易金额为研究属性,就是从大额交易角度进行考虑。在识别可疑洗钱交易的研究过程中,因账户设定成偶尔的洗钱活动,绝大多数账户是没有进行洗钱活动,所洗钱分析就会选择短平快的洗钱模式,自然交易金额增大也就更加突出。即使交易金额能够用单一属性选择数理统计进分析,但是账户交易金额是极难符合某一种标准的分布,所以就要引入其他的属性。
(2)离散系数的属性分析:Tadi(交易金额的离散系数),即为交易金额的方差[Tsi2]和均值[Tai]的商。因交易金额的异常增大了,即便可疑洗钱行为具有重要表征,但也无法判别复杂洗钱行为。而犯罪时常利用多家银行或者其他的金融机构服务开展洗钱犯罪活动,在处理每一个账户时仅仅是针对小金额的非法收入,就能够规避监管大额交易的报告制度,也就增大了反洗钱的调查工作难度。选择交易金额的离散系统为研究属性,质量交易金额平均程度就是应对洗钱行为结构化的规避行为。离散系数越小,则表明交易的金额较为平均,反之交易金额具有较大波动。以出账金额作为案例,假如某一个账户第i个子序列中共有nj笔支出交易,那么按照每一笔的出账金额taij进行排列即为:[tai1、tai2...taint];该账户的第i子序列交易的平均金额即为:[Tai=1nj=1nitaij];账户上第i子序列支出交易金额方差即为:
[Tsi2=1ni-1j=1ni(taij-Tai)2]
就可以得出账户第i子序列支出金额的离散系数是:
所以就能够求解A账户第n个子序列中交易金额的离散系统为:[Tad1、Tad2、...Tadn]。本文就是将计算出来的离散系数,作为了可疑洗钱行为的一个特征属性,和其他属性值共同形成了子序列代表的行为模式所具的特征向量。
3.2 识别方法分析
在识别可疑洗钱行为模式上,本文就是借鉴了CBLOF算法同时,并适当改进了该算法中聚类分析过程,在此基础上形成了识别方法模式。
(1)算法设计
本文数据挖掘技术的涉及过程为:
其一从任意点开始,构建一个聚类簇,设初始簇为C1;
其二对其他某点q,计算和已有聚类簇点C的距离及最小值[distance(q,cmin)];假如[distance(q,cmin)]的距离小于或者等于阀值[ε],而且q未不属于任何一簇中,可 将它加入[Cmin],假如q距离多个已有簇小于或者等于[ε],那么合并这些簇。
其三对所生成聚类依照元素数目排序;
其四重复第2、3步,对下一点实施聚类,一直到所有点均被聚类为止。
(2)挖掘局部孤立点
经过上面分析形成了若干互不包含簇,同时簇是按照包含样本数目排列,选用CBLOF算法计算每一个点LOF值。之后依据LOF值大小进行排序。值越大孤立程度越高,值越小孤立程度就越低。金融机构就能够依据资源情况与公正所需确定出报送对象。
就是将聚类簇划分成大小类,按照样本数据点所属规模及数据点和最近簇的距离,由此确定出每一个数据点LOF值。这种方式下,挖掘局部孤立点就分成了两个步骤,就是按照大小类及确定出LOF值。
首先划分大小类;假设C={C1,C2,...Ck}为数据集合D聚类结果,其中[c1?c2...?ck],确定两个参数是a与β,根据下面公式有:
[c1+c2...+ck≥D*a];[cb/cb+1≥β];其中大类是c={[cii≤b]},用LC表死,即为LC={[cii≤b]};而小类是SC={[cjj>b]}。
其次计算LOF可疑度;假如数据集合中任何数据点是P,那么点P局部偏离值(即为LOF值)是:[CBLOF(p)=cj*distance(p,ci)],该式中[t∈ci,ci∈SC,cj∈LC];因此只要确定了每一个数据点LOF值,就能够确定出账户交易行为可疑的程度。使用信息者就能够依据所需,选出LOF值最大n个对象深入进行分析与研究。
4 结束语
识别可疑洗钱的交易行为,就可以依据账户自身交易模式变化进行识别。而偶尔洗钱行为无论属于那种手段,都能通过交易金额和交易时间两维度上存在异常表现出来,交易金额表现异常增大及平均程度异常,自然也就会增大交易频率异常。这种挖掘技术对识别洗钱行为具有作用。
参考文献:
[1]李果仁.反洗钱的现状与对策研究[J].广东经济管理学院学报,2014(1).
[2]谭德彬,陈藻.基于数据挖掘技术的银行反洗钱系统[J].国金融电脑,2013(7).
[3]汤俊.基于客户行为模式识别的反洗钱数据监测与分析体系[J].中南财经政法大学学报,2015(4).
[4]胡秋灵,姚文辉,宋晓萌.聚类分析方法在反洗钱应用中的优先序研究[J].华南金融电脑, 2015(11).
[5]黎金玲.基层金融部门反洗钱工作存在的问题与对策[J].武汉金融,2016(3).
