一种多路实时视频拼接系统的设计与实现*
2016-06-30陈张新熊庭刚
陈张新 熊庭刚
(武汉数字工程研究所 武汉 430205)
一种多路实时视频拼接系统的设计与实现*
陈张新熊庭刚
(武汉数字工程研究所武汉430205)
摘要针对当前多路视频拼接系统实时性差、拼接效果不理想的问题,提出一种DSP+PC构架的视频拼接系统。该视频拼接系统由普通的PC机和硬件加速卡组成,硬件加速卡实现视频采集和视频拼接融合功能,PC端主要负责视频显示和人机交互,它们两者之间通过PCIe高速协议进行数据传输。此外,论文通过改进基于SURF的特征点提取算法,提高了数据处理速度和配准精度。该设计实现了8路标清视频的实时拼接与显示,并显著提升了视频拼接效果。
关键词全景视频拼接; 图像融合; SURF算法; DM8168
Class NumberTP391
1引言
为了解决单个摄像头在获取场景时存在的视野宽度不够的问题,视频拼接技术应用而生。这种技术可以将目标物体四周的场景进行无盲区显示,进而填补特定场所大范围、无盲区监控的市场空缺,可以预见,全景视频拼接系统在车(舰)载监控、公共场所安全监控、智能交通、全景地图绘制等军用和民用领域必将有着广泛的应用前景。例如,在军事领域,全景视频拼接系统能够很好地把各个战场获得的画面拼接起来,实时了解战场的情况,进而根据画面显示的信息做出与之对应的决定,很大程度上杜绝了因为指挥不当而造成的损失。又例如,在医学领域,如今的内科常规检查都采用了医学摄像诊断,而对于较大尺寸的目标,一个摄像头不能照射到整个画面,而两个的话,不进行任何处理则会对医生的诊断带来一定的误差和难度。而视频拼接的引入能很好地解决这方面的难题。
目前,对于视频拼接技术的研究,基本上都局限在功能实现的层面上,而且仍未出现一种能够达到实时效果的拼接算法。随着视频拼接系统研究的不断深入,对于一些比较基本的问题都得到了很好的解决,但实时性一直都是困扰着这套系统能够取得突破的一个关键性问题。所以本文将着重对实时性这一问题进行分析和解决,同时,提出使用一种高效的构架。这种构架的结构是主控单元+硬件加速卡模式,它能够最大限度的调用各个处理器的资源,加上算法方面的优化,进一步提升视频数据的处理能力,从而达到实时性的效果。本系统在算法方面除了解决实时性的问题外,将对视频显示的效果也做进一步的优化,比如图像配准精度问题等。
2系统设计与实现
本系统的组成主要由摄像机组、视频拼接控制器、客户终端等三个部分构成,其中视频拼接控制器对来自摄像机组的多路视频图像进行实时采集、校正、拼接、融合,最终生成全景视频图像并予以实时显示、压缩、存储和传输,从而实现对场景任意角度的无盲区监控。
2.1硬件整体构架
在硬件实现方面,本系统采用硬件加速卡的方式来提高系统的实时性和可扩展性。如图1所示为全景拼接系统硬件组成框图,采用主控单元+多个硬件插卡(视频采集与硬件加速卡)的方案。其中,主控单元主要负责人机交互和资源调度,而采用硬件插卡的形式可以根据具体需求对系统功能进行扩展,例如:目前设计的系统采用两块卡完成对8路PAL视频图像的拼接,若需增加/减少视频通道数、提高/减低系统分辨率可简单通过增加/减少硬件插卡的形式实现。硬件插卡通过高速数据交换总线与主控单元相连,其主要功能如下。
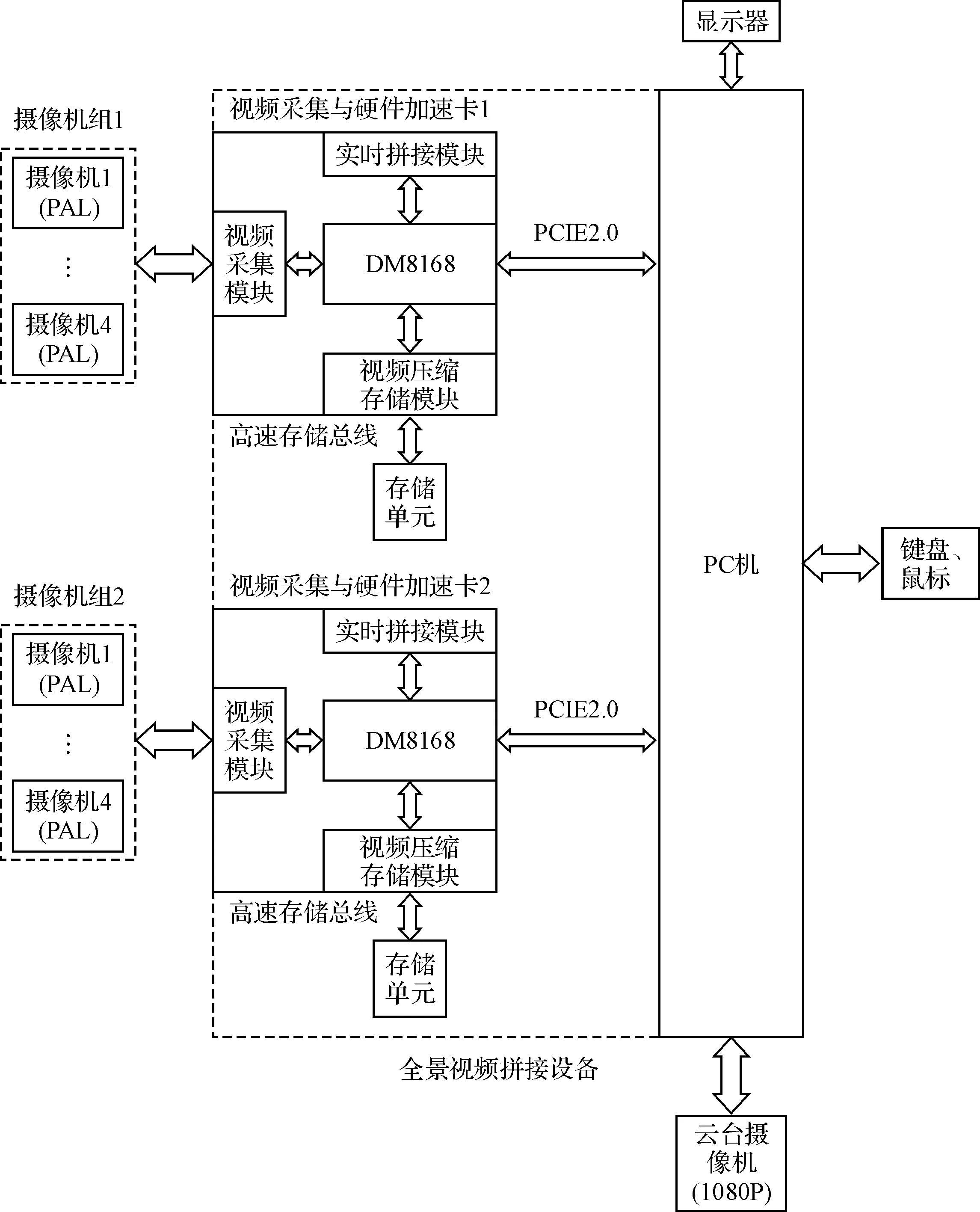
图1 全景拼接系统硬件组成框架
1) 对来自摄像机组的4路PAL模拟视频进行实时采集;
2) 利用拼接参数完成4路视频图像的实时拼接,并将拼接好的图像通过高速数据交换总线实时传递给主控单元;
3) 根据主控单元发来的指令,接收来自主控单元的拼接参数或将采集到的4路原始视频图像通过高速数据交换总线传递给主控单元;
4) 对采集到的四路原始视频进行压缩,并通过高速存储总线存储到本地存储单元。
主控单元的主要功能包括:
1) 人机交互;
2) 对硬件插卡进行控制和调度;
3) 在全景拼接系统启动阶段计算拼接参数并通过高速数据交换总线传递给硬件插卡;
4) 在全景拼接系统稳定运行阶段,每隔一段时间通过高速数据交换总线从硬件插卡接收原始视频图像,重新计算拼接参数,并将新的拼接参数通过高速数据交换总线传递给硬件插卡;
5) 实时接收来自硬件插卡的拼接图像,并实时将来自各硬件插卡的拼接图像拼接起来形成全景图像;
6) 控制云台摄像机,跟踪目标或对局部区域进行放大。
2.2系统实现
本文所设计的硬件加速卡主要由DM8168及一些外设组成,TMS320DM8168是TI最新推出的一款高性能DMSoC,其中包含一个C674x DSP 主频为1GHz,1 个Cotex-A8 主频为1.2GHz,三个HDVICP 频率为600MHz。CPU 具有强大的数据处理能力并包含大量的外设资源。其采用ARM+DSP的达芬奇构架,可以广泛应用于视频编解码、视频会议、媒体服务器、视频监控等领域。评估板内部所包含的模块以及外设主要包括以下几点:
· 基于Cortex-A8的ARM微处理器;
· 基于C674x的定/浮点DSP;
· 一个高清视频处理子系统(HDVPSS);
· 三个高清视频图像协处理器(HDVICP);
· 3D图形引擎;
· 丰富的外设接口,主要包括UART接口、SATA接口、视频接口(4片视频采集芯片TVP5158)、音频接口、以太网接口等。
根据以上设计的硬件框架,本文搭建了一个主控单元 + 硬件加速卡的实验架构。DM8168的工作是多核之间协同作用,共同完成的,之所以能够最大限度利用各个芯片之间的资源,主要得益于ARM中运行了一个Linux操作系统来协调各个微处理器之间的工作。
DM8168是DSP和ARM双架构的SOC芯片。对芯片与外界的交互通过ARM端的Linux操作系统和相关的应用程序来管理,DSP端只处理相关的算法。DSP和ARM之间的通信和交互式通过引擎(Engine)和服务器(Server)来完成的[5]。
在ARM 端,对视频类程序来说,应用程序首先把采集到的原始图像信号,通过VISA 接口调用相关的Codec 存根函数,由存根函数调用相关的Engine API函数,也就是SPI (service provider interface)接口,但由于实际的Codec算法在远端(DSP端),所以必须由引擎把信号进行封装,通过OS抽象层与DSP Link 通讯把打包后的数据发送出去。这种数据处理方式有效地利用了各个环节的分工,提升了整个系统的开发效率。对于双核的达芬奇构架,两核之间的资源分配很大程度上决定了系统能否最大限度地各尽其能。ARM独享(DSP不可用)的外设有:UART/0/1/2,I2C,看门狗时器,PWM/0/1/2,ARM 中断控制器,USB2.0,ATA/CF,SPI,GPIO,VPSS,EMAC/MDIO,EMIF A CONTROL,VLYNQ,MMC/SD。DSP独享(ARM不可用)的外设有:DSP 中断控制器,VICP。ARM和DSP 共享的外设有:EDMA,Timer/0/1,Power & Sleep Controller,ASP 和EMIFA Data。也就是说,DM8168首次给DSP分配了内存管理单元(MMU),其可以将内存访问的权限授予DSP,使得DSP与ARM拥有平等访问内存的权利。DSP通过指向内存单元的指针寻址就可获取数据,无需对数据进行拷贝。这种多核之间数据共享的机制大大提高了ARM和DSP协同工作的效率。
将上面已经优化过得算法移植到DSP上之后,可以在PC端发送视频采集命令,通过PCIe传送到硬件加速卡,进行视频采集。硬件加速卡端将采集到的视频进行一系列预处理后,进行拼接融合,将视频数据传输到PC端进行实时显示。其具体软件实现流程图如下所示。
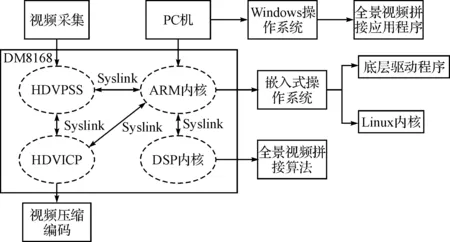
图2 系统构架
2.3软件算法优化
在算法设计方面,经过长期的研究发现,在视频图像拼接过程中,拼接参数计算阶段耗时最长,但拼接参数的计算仅需在系统启动时计算一次,而后续拼接过程中可以每隔几分钟甚至更长时间计算一次,不需要实时计算;另外,由软件算法得到的拼接参数与实际情况存在一定误差,如果每一帧视频图像都重新计算拼接参数,反而会影响场景的视觉一致性,这也是静止图像拼接算法不能直接用于视频拼接的一个主要原因[1]。经上述分析后,本文将视频拼接算法模块划分为两个子模块,即拼接参数计算模块和图像拼接模块,来进一步提高算法的实时性。
拼接参数计算模块主要完成曝光系数、拼接掩膜、后相映射图等拼接参数的计算。如图2所示为拼接参数计算模块的工作流程。首先利用SURF(Speeded Up Robust Feature)算法提取图像特征,并完成特征匹配对的搜索,然后根据特征匹配对估计相机焦距和相机运动参数。为了消除相邻图像间的亮度差异还需要进行曝光系数的计算。最后,为了进一步分担图像拼接模块的负担,此模块还需完成后相映射图(用以图像弯曲)的计算以及权重图(用以图像融合)的计算。
图像拼接模块从拼接参数计算模块得到相关参数,并完成视频图像的拼接,此过程需要实时处理。如图3所示为图像拼接模块的工作流程,该模块需要利用拼接参数计算模块输出的后相映射图、曝光系数、权重图等依次完成图像弯曲、曝光补偿和图像融合。
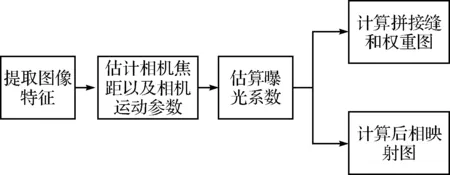
图3 拼接参数计算工作流程
关于图像配准的算法有很多种,比如说比较经典的基于尺度不变特征(SIFT)的图像拼接技术,该算法完全自动完成,而且采用了多分辨率对图像进行融合,具有尺度不变性和旋转不变性,是目前视频拼接领域最为流行的算法。但是,当待匹配图像含有大量的相似结构或者有高速运动的物体时,由于SIFT特征描述符仅仅利用了特征点的局部领域信息,因此对散落在这些相似区域中的点极易发生错误匹配。此次,利用了SURF特征[2]和RANSAC(Random Sample Consensus)[3]方法来实现多路视频图像精确配准。配准流程图[4]如图4所示,这种配准算法主要分为两大步骤:第一步是特征提取——提取待匹配的两幅图像的SURF特征,并对每个特征点生成一个多维的描述子,所有特征点的描述子构成每一幅图像的特征集;第二步是特征点匹配——以特征点集为考察对象,选择一组特征集为参考集,另一组为目标集,在目标特征集中找出与参考特征集中一个特征描述子最相近的一个,对应特征点组成匹配对,再对匹配对进行提纯,剔除错误匹配结果。

图4图像拼接模块工作流程
SURF算子是一种具有局部特性的算子,该算子只对图像中某一局部的极值点进行提取[5],这种局部特性很稳定,它不会因为图像存在尺度缩放、旋转、光照强度不同等情况而出现较大的变化,因此SUEF特征是一种局部不变形特征[6]。SUEF特征提取算法流程图5所示。
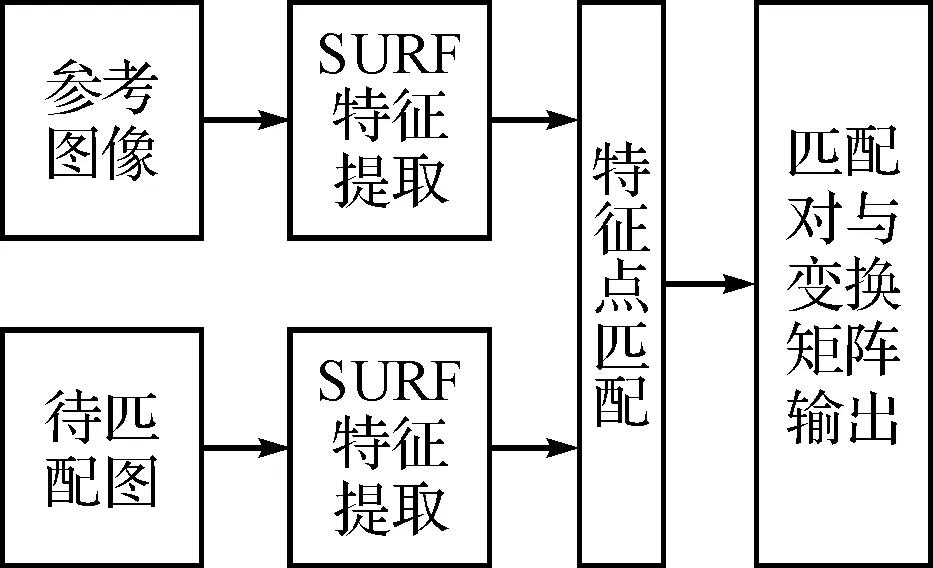
图5 配准流程图

图6 SURF特征提取流程图
一般而言,同一个场景的不同视角的图像之间具有一定的对应关系[6],在齐次坐标系下,图像之间一般满足式(1)所示的透视关系,其中M为图像变换矩阵[7]。
(1)
对于较为丰富的图像,得到的匹配对数往往数以百计,而图像间变换关系只需四个匹配对便可完成[8]。如果只选择其中四个匹配对计算出来的变换矩阵难免具有片面性,这就需要找出大部分匹配对都满足的变换矩阵,至于那些不满足的匹配对就作为错误匹配对而被剔除掉[9]。本项目拟采用RANSAC算法实来提纯匹配对并估计变换参数。在实际操作中,具体实现形式可按照下列步骤进行[10]:
1)每次随机取出四个匹配对,并以此计算出变换矩阵中的八个参数。
2)将匹配对中的其中一个点坐标经过计算出来的变换矩阵变换成一个新的坐标值,并计算这个坐标值与匹配对中的另一个点的坐标的距离。
3)考察上一步计算出来的距离,如果它小于某一个阈值,则将它作为一个内点,否则作为外点。
4)对所有的匹配对都按照第三步的做法,并记录在上述变换矩阵下的内点数。然后从第一步开始重复进行上述步骤,直到找到拥有最多内点的变换模型,最大重复次数为N。对于N的确定,先令ω为数据是真实数据模型内点的概率,n为确定模型参数的最小点数,取4。这样一来,一次估计所有n个点都为内点的概率就为ωn。如果要保证经过N次至少有一次估计中的所有点都是内点的概率为p,那么N应该满足以下关系式:
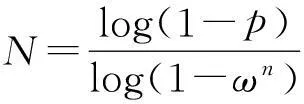
(2)
3实验结果与分析
相对于全景视频的拼接,本文选取了三路视频拼接作为实验的结果进行分析。这样做的理由是三路视频的拼接与八路的原理是一致的,但取景相对来说会方便很多,而实际达到的效果却一样。
实验采用本文所介绍的拼接算法,在搭建完开发环境和硬件系统后,把算法移植到DSP上运行,最后显示出来的视频图像如图7所示。经过与实时的视频进行对比发现,我们所拼接显示后的图像的延时可以严格控制在15ms以内,这个参数已经可以满足现如今大部分的监控需求。而且拼接后的视频流的帧率平均可达25f/s。

图7 全景视频帧截图
4结语
通过对视频拼接系统硬件方面和软件方面长期的研究,本文提出一种优化的硬件构架,并辅以改进的视频拼接算法,很大程度上改善了视频拼接实时性差、拼接效果不理想等瓶颈。本系统的主要设计思路是通过DM8168的8个视频采集口对8个摄像头的视频数据进行采集,利用ARM调度板间资源,通过DSP上已经移植的视频拼接算法处理同步的帧视频信号,处理后的数据通过PCIe协议传输到上位机进行显示。实验结果表明,本系统能将8路D1视频源的拼接延时控制在15ms以内,基本满足了实时性要求,而且通过对配准算法的优化,很好地改善了拼接效果。
参 考 文 献
[1] W Pan, K Qin, Y Chen. An Adaptable Multilayer Fractional FourierTransform Approach for Image Registration[J]. IEEETrans. on PAMI (S0162-8828),2009,31(3):400-414.
[2] Ishibuchi H,Tsukamoto N,Nojima Y.Diversity Improvementby Non—geometric Binary Crossover in EvolutionaryMultiobjective Optimization[J]. IEEE Transactions onEvolutionary Computation,2010,14(6):985-998.
[3] 杜威,李华.一种用于动态场景的全景表示方法[J].计算机学报,2014,26(6):968-956.
[4] 陈虎.基于特征点匹配的图像拼接算法研究[J].海军工程大学学报,2007,19(4):94-97.
[5] 陈玲,李昊然,谷源涛,等.基于DM8168的视频会议服务器的设计与实现[J].计算机仿真,2013(11):206-208.
[6] Tuytlaars T. and Van Gool L., Matching widely separated views based on affine invariant region. International Journal of Computer Vision,2004,59(1):61-85.
[7] 方贤勇.图像拼接技术研究[D].杭州:浙江大学,2005.
[8] M. Brown. D. Glowe. Recognising Panoramas[C]//Proceedings of the 9th International Conference on Computer Vision (ICCV2003),2003:1218-1225.
[9] R. Szeliski and H.-Y.Shum.Creating full view panoramic image mosaics and texture-mapped models[C]//Computer Graphics (SIGGRAPH'97) Proceedings,1997:251-258.
[10] Giorda.F, Racciu.A. Bandwidth Reduction of Video Signals via Shift Vector Transmission [J]. IEEE Transactions on Communications,1975,23(9):1002-1004.
Design and Implementation of A Multi-channel Fast Video Stiching System Based on DM8168
CHEN ZhangxinXIONG Tinggang
(Wuhan Digital Engineering Institute, Wuhan430205)
AbstractIn order to deal with the problem that multichannel video mosaicing system has worse real-time performance and unsatisfactory stitching effect, a video mosaics system of DSP + PC architecture is presented. The video mosaicing system is composed of ordinary PC and the hardware acceleration card.The hardware acceleration card is really to realize the function of video capture and video fusion splicing, and PC is responsible for video display and human-computer interaction. The data transmission between PC and hardware acceleration card relies on the PCIe high-speed protocols. In addition, through improving the feature points extraction algorithm based on SURF (Speeded Up Robust Feature), the data processing speed and matching accuracy is improved. The design has realized the 8 sign clear video stitching and display in real time, and significantly increased the video stitching effect.
Key Wordspanoramic video stitching, video fusion, SURF algorithm, DM8168
*收稿日期:2015年12月17日,修回日期:2016年1月23日
作者简介:陈张新,男,硕士研究生,研究方向:视频信息处理、DSP驱动开发等。熊庭刚,男,博士,研究员,研究方向:计算机体系结构。
中图分类号TP391
DOI:10.3969/j.issn.1672-9730.2016.06.022
