银行贷款客户违约分析
2016-06-27白燕燕楚菲菲兰州财经大学统计学院甘肃兰州730000
白燕燕,楚菲菲(兰州财经大学统计学院,甘肃 兰州 730000)
银行贷款客户违约分析
白燕燕,楚菲菲
(兰州财经大学统计学院,甘肃兰州730000)
[摘要]随着互联网金融的迅速发展,商业银行更加重视贷款风险管理,判别出违约客户对风险管理异常重要。所以,基于C5.0算法的决策树模型应用而生,根据银行客户数据建立决策树模型,提出分类规则,对新出现申请贷款的客户是否会违约进行分类预测。通过交叉验证得到可靠稳定的决策树模型,并在决策树模型的基础上,加入成本矩阵,提高对违约客户判别的准确率,达到局部最优,从而提高商业银行对客户的风险管理和贷款控制。这既能满足个人融资的需求,又能降低商业银行的贷款风险。
[关键词]客户违约率;决策树;C5.0算法;成本矩阵;交叉验证
金融作为现代经济的核心,其发展程度对经济有着直接的影响。而银行贷款作为金融业的主要组成部分,对其风险的管理情况关系着贷款的资产质量,关系着金融业的发展。[1]因此,国家和企业必须重视对银行贷款风险的管理,及时发现银行贷款存在的风险,并采取多种有效的措施降低风险,不断提高银行贷款的资产质量,促进金融与经济的发展。
在互联网金融迅速发展的今天,贷款机构愈加重视对个人违约率的预测,从而降低客户违约带来的风险,以下是对算法和相关概念的介绍。
一、C5.0算法
决策树的实现算法有很多种,众所周知的是C5.0算法。这种算法是C4.5算法的改进,它们都基于ID3算法之上。C5.0算法已经变成了产生决策树的标准算法,因为对于大多数问题,决策树都是直接可用的。与其它的机器学习算法相比,基于C5.0算法的决策树模型性能很好,而且容易理解。该算法的缺点相对较小,而且很容易避免。以下是它的优缺点:
(一)选择最优分裂法
决策树的首要问题是确定哪一个特征进行优先分类,如果分类结果只有一个类,那么被认为样本数据不含有信息量,对于分类标准,有不同的测量方法,而C5.0算法利用了信息熵的测量方法。借鉴了热力学的概念,把信息中排除了冗余后的平均信息量称为“信息熵”,一个样本数据的熵所表示的是类值的混乱程度;[2]熵的最小值为0,表示样本数据完全同类,当熵的值为1时,表示混乱程度达到最大,即每一类的概率相当。以下是信息熵的公式:
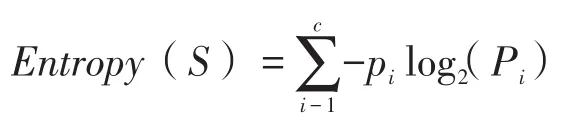
公式中S表示数据集,c表示类的个数,Pi表示数据落在第i个类中的概率。例如,假设我们有一个包含分两个类的数据集:分别为红色(60%)、白色(40%),则熵的计算如下(本文出现的代码都是R语言):
>-0.60 * log2(0.60)-0.40 * log2(0.40)
[1]0.9709506(上面代码输出结果)
我们研究以下数据只能分为两类的情况,如果知道其中一类的概率是x,则另一类的概率是1-x,用curve()函数画出在任何概率x情况下的熵。
>curve(-x*log2(x)-(1-x)*log2(1-x),col=2,xlab="x",ylab="Entropy",lwd=4)

优点对于大多数的问题都是通用的拥有高度自动化学习过程,能够处理数字特征、名义特征和缺失数据只提取最主要的特征没有数学背景也可以理解模型结果(决策树比较小时)比其它复杂模型更加高效缺点决策树模型往往有较大的分裂层很容易产生过拟合或不拟合模型依赖于平行轴分割的关系很难被建模训练数据集发生小的改变可能会导致决策逻辑发生大的变化大的决策树可能很难被解释,而且有可能做出违反实际情况的决策

图1 信息熵与类概率的关系
>-0.50 * log2(0.50)- 0.50 * log2(0.50)
[1]1
由此可知当x=0.5时,熵达到最大值1,即表示数据集的每一类的概率越接近,熵越大值越接近1,每一类的概率相差越大,熵越小值越接近0。
给定了纯度度量方法,C5.0算法还必须确定用哪一个特证进行分类,将可能的特征加入到系统分类中再次进行分类,对于不同的分类结果计算熵的变化,这就是信息增益。在信息增益中,衡量标准是分类特征能够为分类系统带来信息量的多少,带来的信息越多,该特征越重要。[3]对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量即熵的差值就是这个特征给系统带来的信息量。这个差值就是信息增益,对于特征F,信息增益是计算加入特征F前分类信息量S1与加入特征F后分类信息量S1的差值。公式如下:
InfoGain(F)=Entropy(S1)-Entropy(S2)
(二)修剪决策树
决策树根据分裂特性,可以无限期地增长,使得每个例子在训练数据上得到最好的分类。然而,如果形成的树过大,过于具体化,则容易在训练数据上形成过拟合模型,修剪决策树以减少它的大小,使其有更好的外推性。解决这个问题的方法有两种,一种方法是设置一个阈值,树增长的大小一旦达到这个阈值就停止其增长。[4]这被称为先剪枝,避免了不必要的工作。但其缺点是无法知道该决策树模型是否会错过微小的但很重要的决策节点。另一种方法是后剪枝,即当形成的决策树过大时,用基于在节点处的分类错误率的剪枝标准对其进行剪枝,使得决策树达到一个合适的水平。这种方法可以发现所有重要的数据结构,使模型具有更好的外推性。
二、相关概念
交叉验证(Cross Validation)是用来验证分类器性能的一种验证方法,基本思想是在某种意义下将原始数据进行分组,一部分作为训练集(train set),另一部分作为验证集(validation set)。首先用训练集对分类器进行训练,再利用验证集来测试模型,以此来评价分类器的性能。[5]常用的精度测试方法主要是交叉验证,例如10折交叉验证(10-fold cross validation),将数据分成十份,轮流将其中的九份做训练,一份做验证,10次结果的均值作为对算法精度的估计,交叉验证的目的是得到可靠稳定的模型。
测量指标。评估模型的指标有Precision,Recall,F-Measure(F1),TP Rate,FP Rate为了容易理解这些指标,以信息检索为例,在信息检索中这些指标的界定。信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),概念公式:
召回率(Recall)=系统检索到的相关文件/系统所有相关的文件总数
准确率(Precision)=系统检索到的相关文件/系统所有检索到的文件总数
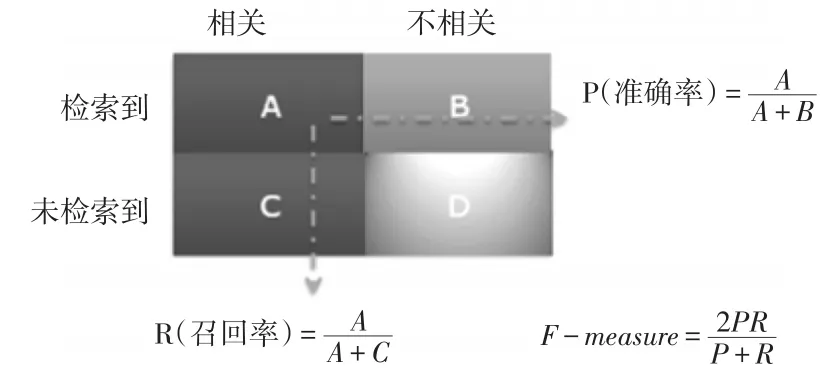
图2 准确率和召回率
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那就是什么地方出问题了。如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。所以,在两者都要求高的情况下,可以用F1来衡量,F1公式如下:
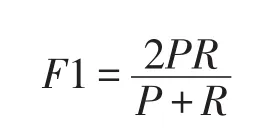
TPR是True Positive Rate的缩写,TPR代表能将正例分对的概率,FPR是False Positive Rate的缩写,FPR代表将负例错分为正例的概率,如下图和公式:
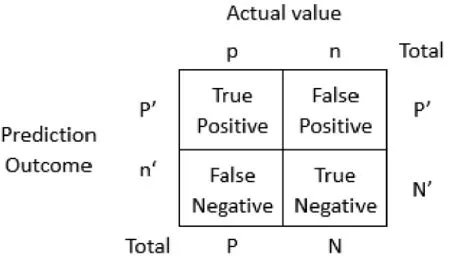
图3 TPR与FPR关系图

三、实证研究
在2007—2008年的全球金融危机中,已经凸显出银行业务透明度和精度的重要性。银行客户信用级别的有效性非常有限,越来越多的银行收紧了信贷系统,转向机器学习来更准确地识别高风险贷款。
(一)使用C5.0算法识别银行贷款风险
由于决策树是以简洁的语言来制定高精度统计模型,所以这种方法在银行业中被广泛使用。在许多国家,政府机构严格监控贷款操作流程,要求管理人员必须解释为什么某个申请人贷款被拒绝而其他人被批准,这些信息对于那些信用等级偏低的人来说非常有用,有利于他们提高自己的信用等级。
自动化信用评分模型用于即刻批准电话和网络申请信贷。我们采用C5.0决策树模型,开发一个简单的信贷审批调整模型,能减少错误所导致的金融机构的损失。[2]
(二)数据说明
我们的信用模型背后的理念是导致申请人更高的违约风险的确定因素。因此,我们需要获得大量的过去银行贷款和贷款是否违约的数据以及关于申请人的信息。这里所用的数据集包含了1 000个申请贷款人的信息。这些信息包括支票账户结余、储蓄账户结余、贷款时间、信用级别、贷款目的、贷款金额等17个变量(金额以万为单位)。这些信息说明了贷款特征和贷款申请人的特征,贷款是否违约作为一个类变量,我们需要做的是利用数据挖掘算法,预测申请人贷款违约情况。部分数据结构如下:
>str(credit)
'data.frame':1000 obs. of 17 variables:
$ checking_balance : Factor w/ 4 levels "<0 RMB",">2 RMB",…
$ saving_balance : Factor w/ 4 levels "<1RMB",">10 RMB",…
$ months_loan_duration: int 6 48 12 ...
$ credit_history : Factor w/ 5 levels "critical","good",...$ purpose : factor w/ 6 levels "business","car",... $ amount : int 11.69 59.51 20.96 ...
$ default: Factor w/ 2 levels "yes","no",......
贷款金额amount范围在2.5万元-184.20万元,贷款时间最短4个月,最长72个月。default变量有两个类,yes表示违约,no表示不违约。银行为了降低贷款损失的比例,希望客户违约率越低越好,所以我们根据历史贷款客户信息建立模型,找出未来更可能违约的客户,从而降低金融机构的损失。
1.决策树模型
将现有的1000条数据分成两个部分:用训练数据集构建决策树模型,用测试数据集评估模型性能。将90%的数据作为训练数据,10%的数据作为测试数据。数据的选取遵循随机原则,在R软件中实现,形成决策树模型如下:

括号里的数字是判别结果,如第一行(358/44)表示358个客户被归类为no,其中有44个申请人被错误的归类为no,有314个归类正确,也就是说,决策树模型将314个客户归类正确,预测结果与实际相同。44个客户归类错误,与实际结果相反。
2.模型评估
用已经形成的决策树模型对训练数据做预测,创建一个类向量值,作为100条测试数据中default的预测值,将实际的default值与预测的default作对比,形成混淆矩阵,结果如下:

图4 R软件的预测结果
由混淆矩阵可知,100个测试贷款申请的记录,模型预测的准确率为73%,其中57%是不违约,16%是违约;错误率为27%,将11%的不违约客户误归类为违约,16%的违约客户归类为不违约。同时更要注意的是,该模型在32个违约客户中,只找出了50%的违约客户,这样的错误将会使贷款机构付出很高的代价。为了减少贷款机构的损失,需要进一步改善模型。
(三)改善模型的性能
上面模型的错误率可能因过高而无法应用于实时信用评分。事实上,我们不构建模型,直接将100个测试数据归类为“no default”,正确率也能达到68%,总体上并不比构建的决策树模型差多少,而且简单易行,所以利用900个训练数据构建高效的模型是个具有挑战性的问题。
金融机构对于违约客户所持有的态度应该是“宁肯错杀,不肯放过”,所以构建模型更应该重视对违约人群归类的准确率的提高。通过一些方法来调整C5.0算法,有助于提高模型的性能,使其更有利于贷款机构。[6]
1.提高模型的精度
C5.0算法是在C4.5算法的基础上增强了自适应性,也就是在决策树模型形成的过程中,使得每个样本做最好的归类。每一种数据挖掘算法都存在其自身的优缺点,对于某个特定的问题,所谓“团结就是力量”,结合几种算法,弥补各自的优缺点,在很大程度上,可以提高分类器的精度。[2]
决策树模型中,树的规模过大容易过拟合,导致其外推性变差,所以对迭代次数加以限制,设置迭代上限为10(在R语言中设置C5.0函数的参数trial=10即可实现),控制树的规模,用新的决策树模型对测试数据进行预测,其结果如下:
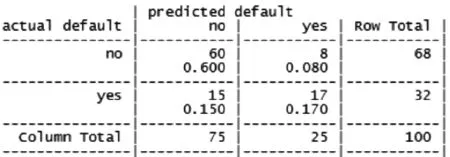
图5 改善模型后的预测结果
由此可知,模型的改进使得预测的总体误差从27%降到23%,但是对违约率的预测精度仍然未得到改善,将47%(15/32)的违约客户预测为不违约。为了提高对违约客户预测的准确率,我们需要对模型做进一步的改善。
2.违约客户分类精度的提高
给一个可能违约的贷款申请人贷款,需要付出高昂的代价,所以我们的目的是减少将违约客户错判为不违约的概率,降低银行贷款客户的违约率,这样才能使银行在高风险的贷款中获得的利益远远大于客户违约所带来的损失。在C5.0算法中加入成本矩阵,这里假设贷款违约的成本是错过一个不违约客户所带来的收益的4倍,创建一个两行两列的成本矩阵作为参数,在R中实现,新的预测结果如下:

图6 最终预测结果
由此可以看出,加入成本矩阵后,模型对违约客户判断的精确度大大提高,违约客户的错判率从47%降到19%(6/32)。结合两次改善模型的各自优点,从而增加不违约客户分类的准确性,降低银行贷款的风险。
结论
传统理念认为,“客户就是上帝”;而客户关系管理的理念认为,“客户并非都是上帝”。统计资料表明,有相当一部分客户是会让银行产生亏损的,如可能违约的客户。所以说,银行应集中精力抓住最有价值的客户,并且努力开拓这一客户群,满足已有高价值客户的需求,挖掘属于该客户群的新的销售机会。
稳定的目标客户群是任何一家商业银行生存和发展的基础。商业银行利用数据挖掘等现代信息技术建立预测模型完成对客户群的划分后,应针对不同产品或服务确定目标客户群,达到对客户信息集中收集、及时传达、迅速反馈,服务客户,使客户满意。商业银行积累了大量的数据信息,包括对客户的服务历史和销售记录、关于客户的人口统计学资料和生活方式的数据。商业银行应该充分有效的利用这些数据信息,将这些信息资源综合起来建立起一个完整的客户资料库,这有助于银行对客户的管理。
参考文献:
[1]王虹,方丹.商业银行贷款风险的探讨[J].时代金融旬刊,2015,(29):118-119.
[2]Brett Lantz.Machine Learning with R[M].PACKT,2013.8.
[3]朱爱群.客户关系管理与数据挖掘[M].北京:中国财政经济出版社,2001,(5):36-40.
[4]陈增圭.建立以客户关系管理为核心的新型商业银行[J].中国金融电脑,2003,(7):2-3.
[5]Tillett L ScoR.Banks Mine Customer Data.Intemet Week,2000,83l:45-46.
[6]Groth R.Data Mining:Building Competitive Advantages.Prentice-Hall Pit,1999.
[责任编辑:于明霞]
Bank Loan Customer Default Analysis
BAI Yan-yan,CHU Fei-fei
(Statistics Institute,Lanzhou University of Finance and Economics,Lanzhou 730000,China)
Abastract:With the rapid development of internet finance,commercial banks pay more attention to the loan risk management,so it is very important to identify the default customer. Meanwhile,the decision tree model based on C5.0 algorithm was presented. According to the bank customer data,decision tree model is established,and put forward the classification rules to predict whether the new loan customers will default to classify ones. Reliable and stable decision tree model is obtained by cross validation,and on the basis of the decision tree model,adding cost matrix,improve the accuracy of judgment for breach of contract customers,to achieve local optimization. So as to improve the management of commercial banks to the customer and the loan risk control. At the same time,it not only solve the problem of personal financing,but guarantee for individual entrepreneurs to provide funds,and reduce the loan risk of commercial banks.
Key words:customer default rate;decision tree;C5.0 algorithm;cost matrix;cross validation
[中图分类号]F832.33
[文献标识码]A
[收稿日期]2016-03-08
[文章编号]1671-6671(2016)03-0024-07
[作者简介]白燕燕(1991-),女,陕西延安人,兰州财经大学统计学院硕士研究生,研究方向:基于数据挖掘技术的客户关系管理。楚菲菲(1990-),女,陕西西安人,兰州财经大学统计学院硕士研究生,研究方向:国民经济统计。
