基于Cookie的网盘资源在线溯源方法
2016-06-21林海伦李焱王伟平岳银亮林政
林海伦,李焱,王伟平,岳银亮,林政
(1.中国科学院信息工程研究所,北京 100093;2.国家计算机网络应急技术处理协调中心,北京 100029)
基于Cookie的网盘资源在线溯源方法
林海伦1,李焱2,王伟平1,岳银亮1,林政1
(1.中国科学院信息工程研究所,北京 100093;2.国家计算机网络应急技术处理协调中心,北京 100029)
网盘作为一种基于互联网的信息传播载体,其所分享的敏感资源已经在网络流量中占有越来越多的比例,因此,获取网盘资源的分享链接对于网络安全有着重要的意义。提出了一种高效可扩展的基于Cookie的网盘资源溯源方法—CookieTracing。该方法通过在海量的HTTP会话中建立Cookie与HTTP会话的索引表来实现网盘资源和下载网盘资源的跳转链的关联,同时通过累计散列算法加快溯源结果的验证。实验结果表明,所提方法具有较好的性能和可扩展性。
网盘资源;分享链接;URL跳转链;Cookie;HTTP会话
1 引言
随着互联网技术的飞速发展,网络作为一个开放式的平台,为用户提供了众多可以分享和下载资源的服务,如P2P注1:https://en.wikipedia.org/wiki/Peer-to-peer。:https://en.wikipedia.org/wiki/BitTorrent。、BitTorrent注2:https://en.wikipedia.org/wiki/Peer-to-peer。:https://en.wikipedia.org/wiki/BitTorrent。以及目前比较流行的网盘。由于网盘操作简单,用户无需安装软件就可以一键分享、下载资源;而且与BitTorrent等传统资源分享模式相比,下载速度快。网盘具备的这些特点导致P2P和BitTorrent使用量急剧下降[1~3]。目前,统计已有很多研究对网盘的使用情况,Maier等[1]对网盘的网络流量进行了统计分析,发现网盘流量占普通网络流量总数的17%。Gehlen等[2]对网盘的点击量进行了统计分析,发现网盘是排名前10的网络应用,并且占据5%的点击量。Allot等[3]则对网盘在移动终端上的网络流量进行了统计分析,发现网盘流量占据移动终端网络流量总数的19%。通过上述分析可以看出,网盘已成为重要的网络资源分享和下载的方式。
当用户利用网盘分享资源时,网盘会给该资源生成唯一与之对应的URL标识,用户将该链接分享至网络社交平台,其他用户即可点击该链接下载分享资源,这些用户点击分享链接后会弹出一个带有下载按钮的页面(本文将其定义为入口页面),该页面的URL即为资源的分享链接,页面会描述该下载资源的属性信息,如资源发布者、资源发布时间、资源下载次数等。
当用户单击入口页面中的下载按钮下载该资源时,用户使用的浏览器会自动向服务器发出一系列HTTP请求(本文将其定义为资源下载的URL跳转链),直至成功建立下载资源的HTTP会话。如何从海量的网络流量中获取网盘下载资源所对应的入口页面对于网络审查[4]、网络取证[5]、网络流量监控[6]等具有重要意义,本文将这一过程定义为网盘资源溯源。
众所周知,Referer是HTTP表头的一个字段,用来指定当前请求资源的来源地址。然而,在真实流量统计中,大约只有17%的HTTP会话存在Referer字段。因此,只依赖Referer字段无法获取绝大部分下载资源的入口页面。同时,网络地址转换(NAT,network address translation)[7]、多路多播技术[8]和HTTP代理[9]等技术的使用也导致公网路由节点捕获的HTTP会话的IP地址无法作为精确追溯其URL跳转链的依据。而Cookie中包含计算机和浏览器的信息,可以用来辨别用户身份、进行session跟踪。
为此,本文提出了一种高效可扩展的基于Cookie的网盘资源在线溯源方法——CookieTracing,该方法的创新之处有以下几点。
1) 提出了一种基于Cookie的网盘资源溯源方法,基于散列技术,通过建立location字段与HTTP会话以及Cookie与HTTP会话的散列表实现网盘资源溯源。
2) 通过缓存HTTP会话的Cookie、URL和location字段,采用累计散列算法加快溯源结果验证,从而适应在线流量的溯源。
2 相关工作
目前,针对网盘资源溯源,与之相关的研究工作主要有2类。
一类是针对网页木马、恶意网页识别[10]提出的针对URL跳转链的入口URL识别方法。由于网页木马以及恶意网页为了躲避检测,通常都会经过多次URL重定向将用户浏览器最终引向恶意代码网页[10]。这种URL多次跳转给网页木马和恶意网页的识别带来了很大的挑战。
为此,已有很多工作围绕网页木马、恶意网页等入口URL的识别展开研究,如Lee和Jenefa等[10,11]针对Twitter上存在的恶意URL识别提出了WarningBird方法,该方法通过收集同一恶意网页的多条URL跳转链获取入口URL,通过入口URL的特征识别恶意网页。Zhang等[12]针对网页木马识别提出了Arrow方法,该方法首先通过蜜罐技术收集同一恶意软件的不同URL跳转链;其次,对比URL跳转链各个节点的IP和域名获取恶意软件的入口URL;最后,针对该入口URL提取URL模式,根据URL模式识别网页木马。
通过分析可以发现,WarningBird和Arrow方法[10~12]都是通过收集恶意网页代码的URL跳转链,离线学习入口URL的特征,根据这些特征实现恶意网页代码及其入口URL(恶意网页、挂马网页)的识别。这种方法虽然可用于网盘资源的溯源,但是还存在一些不足。目前,众多的网盘对应的分享资源的URL跳转链特征并不一致,而且通过调研发现即使对于同一网盘的分享资源的不同下载,其特征也会变化,所以现有的方法难以直接适用于网盘的分享资源的溯源。
另一类是针对NAT和HTTP代理导致骨干网关上数据分组的IP地址无法标识用户而提出的在NAT主机进行识别的技术[13,14]。例如,Goldberg等[13]通过分析HTML网页内容,以及HTTP会话中的user-agent字段,实现了对不同用户发出的一系列HTTP请求的关联。Maier等[14]通过对用户浏览器的版本和配置等信息产生“浏览器指纹”的方法,识别出不同用户浏览器所发出的的HTTP会话。Neasbitt等[15]提出了一种基于网络流量跟踪的用户—浏览器交互重构方法。上述这些方法虽然能够识别不同用户的HTTP请求,但是存在以下缺陷:骨干网络大部分的HTTP会话中只包含user-agent,而没有其他的配置信息,如字体、插件、时间等,这将导致方法失效。不仅如此,这种方法需要缓存网页内容,针对骨干网络的巨大流量,这会极大地加剧空间开销。
通过对相关工作的分析可以看出,虽然目前已经出现了一些针对资源溯源的方法,但是这些方法无法有效处理网盘资源的溯源。特别地,随着网络大数据的爆炸性增长和网盘的流行,需要研究有效的网盘资源溯源方法,提高资源溯源的准确性。
3 CookieTracing方法的原理
本节将详细介绍CookieTracing方法的原理。为此,首先给出URL跳转链和CookieTracing方法的形式化定义,然后介绍CookieTracing识别网盘分享源下载入口页面的处理流程。
3.1 问题定义
定义1URL跳转链。给定一个网盘资源的分享链接,用户通过浏览器访问该链接发送下载资源的HTTP会话请求,到建立下载该资源的HTTP会话完成资源下载为止,这期间发出的一系列HTTP请求对应的所有URL,称为该资源下载对应的URL跳转链。
由于时间、地点、位置的不同,对于同一个网盘资源的分享链接,每一次下载该资源对应的URL跳转链中的各个URL节点可能都不相同。CookieTracing方法的目标就是基于不同用户下载该网盘资源产生的URL跳转链,查找URL跳转链中的公共节点,从而实现网盘资源入口页面的识别。下面通过一个例子来简单说明基于URL跳转链识别网盘资源入口页面的思想。
以用户A、B、C为例,他们利用同一网盘资源分享链接下载资源产生的URL跳转链如图1所示。
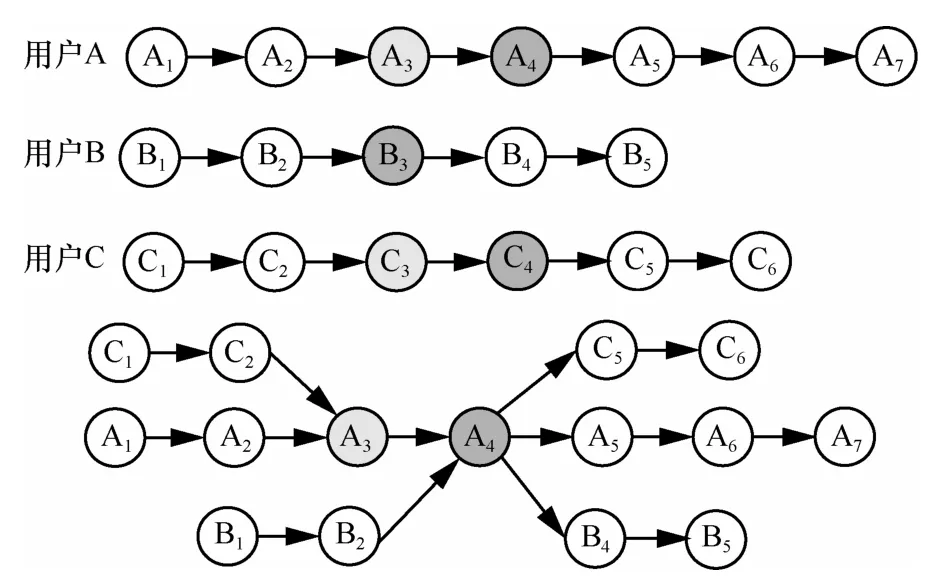
图1 网盘下载资源入口页面查找示例
在图1中,A4、B3、C4分别表示用户A、B、C下载资源时的入口页面,如果能获取A、B、C各自资源下载的URL跳转链,提取出这3条URL跳转链的公共节点,就可以找到该资源的入口点A4(即B3、C4)。
通过以上分析可以看出,网盘资源溯源需要经过以下几个步骤:首先,从网关流量中识别下载资源并计算资源的标识ID;然后,获取下载资源的URL跳转链;最后,合并具有相同资源标识ID的不同URL跳转链,获取唯一的公共URL节点,该节点即为该下载资源对应的入口页面。因此,本文提出的网盘溯源方法——CookieTracing,就是基于不同用户通过浏览器访问资源产生的Cookie信息,采用上述处理方式对网盘资源进行溯源。
3.2 CookieTracing方法流程
在本节,将详细介绍CookieTracing方法进行网盘资源溯源的处理流程。
3.2.1 下载资源的标识ID计算
通过分析发现,用于网盘资源传输的HTTP会话具有以下几个特点:1) 下载资源HTTP会话的content type的取值有几种,分别为video/mp4、application/stream等;2) 在真实流量统计中显示,93%的下载资源HTTP会话的content length都在50 MB以上。因此,可根据上述特点识别出所有包含网盘下载资源在内的下载资源。
由于下载资源在网络上是按分组传输的,在大流量环境中传统缓存整个下载资源数据计算资源MD5的方法无法适用于在线流量的计算,原因在于:一方面,这种方式极大地消耗了内存资源,另一方面,也增加了分享链接的获取时间。为此,CookieTracing采用了累计散列的方法计算下载资源的标识ID,该方法对于按分组到达的数据,对每个字节累计进行散列,将下载数据映射成一个64 bit的散列值,从而获得下载资源的标识ID。真实流量中,下载资源的部分数据即可以对资源进行区分,因此,CookieTracing方法只对下载资源的前20%~30%数据做累计散列,用来实现下载资源的标识ID的计算。
3.2.2 资源的URL跳转链提取
对于网盘分享资源下载生成的URL跳转链中,每个节点对应的HTTP会话的Cookie信息可能存在多个键—值(key-value)相同的项,本文将其定义为token。其中,某些token是网盘服务器用来追踪用户,标识用户的访问记录。为此,本文定义了token的区分度dif,计算公式如下
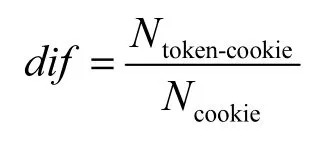
其中,Ntoken-cookie为包含该token的HTTP会话数;Ncookie为总的HTTP会话数。
为了提高URL跳转链计算的准确性,本文定义HTTP会话的关联度simtoken,计算公式如下
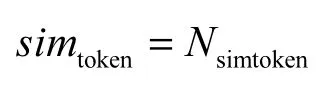
其中,Nsimtoken为2个HTTP会话的Cookie区分度高的token的个数。如果2个HTTP会话的关联度simtoken大于阈值sim0,则认为这2个HTTP会话属于同一条URL跳转链。因此,只要获取与下载资源HTTP会话有着高关联度的一系列HTTP话单就可获取URL跳转链。
根据HTTP重定向原理可知,下载资源HTTP会话的URL与重定向HTTP会话的location相同,而重定向的HTTP会话存在Cookie信息。因此,在计算网盘资源下载的URL跳转链时,首先通过下载资源HTTP会话的URL获取重定向HTTP会话;然后,通过重定向HTTP会话即可获取完整的URL跳转链。
3.2.3 资源的入口页面计算
根据网盘资源的标识ID,对网盘资源下载的URL跳转链进行分组,将具有相同标识ID对应的资源下载的URL跳转链进行合并,对合并之后的URL跳转链上的节点进行遍历,查找URL跳转链上的割点,若该割点是合并的URL跳转链上的唯一的公共URL节点,那么该节点即为该网盘资源的入口。
基于上述CookieTracing方法的原理和处理流程,下面将详细介绍CookieTracing方法的实现。
4 CookieTracing方法实现
在本节,首先介绍CookieTracing方法的整体框架,然后介绍各个模块的具体实现。
4.1 基本框架
CookieTracing方法主要包含4个部分:HTTP会话收集、HTTP会话索引、URL跳转链计算和资源入口计算,在进行网盘资源溯源时,该方法整体的处理框架如图2所示。

图2 CookieTracing 实现架构
1) HTTP会话收集模块负责对输入的网络流量进行解析,获取所需的HTTP会话,并缓存HTTP会话的头部信息,以便降低存储空间开销。
2) HTTP会话索引模块负责解析HTTP会话,对海量的HTTP会话建立Cookie字段与HTTP会话的关联。
3) 资源URL跳转链计算模块,负责根据下载资源HTTP会话获取重定向HTTP会话,并根据重定向HTTP会话的Cookie信息提取资源下载的URL跳转链。
4) 资源入口页面计算模块负责合并同一下载资源的多个URL跳转链,获取合并的URL跳转的唯一公共节点,并通过比较分享链接下载资源的标识ID与Load Runner[16]模拟访问收集的资源标识ID,验证所找到的资源入口页面的正确性。
4.2 模块实现
本节将详细介绍CookieTracing方法中每个模块的具体实现细节。
4.2.1 HTTP会话收集
该模块通过网络流量处理平台解析HTTP会话信息。首先,过滤出2类需要的HTTP会话。
1) 如果HTTP会话的content-type字段的值为text/html,且存在Cookie字段,则将这类HTTP会话信息的三元组:(URL,Cookie,TCP连接建立时间戳)缓存于HTTP会话队列。
2) 如果HTTP会话的content-type字段的值为video/x-ms-wmv、video/mp4等音视频MIME类型,且该HTTP会话的content-length大于某阈值,则该HTTP会话即为下载资源的HTTP会话。将这类HTTP会话的四元组:(URL,Cookie,TCP连接建立时间戳,下载资源标识ID)缓存于资源下载HTTP会话队列。
其次,计算下载资源HTTP会话的下载资源标识ID,本文采用了累计散列算法,计算一个64 bit的散列值作为下载资源的标识ID,具体的计算方法如算法1所示。
算法1资源标识ID计算
输入resourceSize,key,totalAccumulationLen
输出resourceID

从算法1中可以看出,资源标识ID的计算的时间复杂度与下载资源的大小有关,算法的复杂度为O(N)。
4.2.2 HTTP会话索引创建
该模块对HTTP会话队列中的HTTP会话建立索引,规则如下。
1) 如果HTTP会话中存在location字段,则以location字段指定的URL作为key,HTTP会话作为value,存入location索引表。为了降低空间开销,该索引对存储的HTTP会话只做一定时间缓存(本文选取的时间间隔为5 min)。记该索引表为location-HTTP索引表,结构如图3所示。
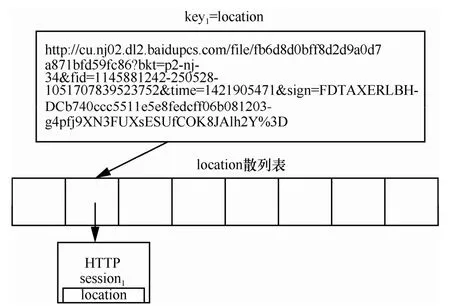
图3 location-HTTP会话索引表结构
2) 若HTTP会话包含Cookie,则将Cookie分割为token,以token作为key,包含此token的HTTP会话作为value,缓存于token索引表,记为token-HTTP索引表。其中,每个token关联的HTTP会话链表按照数据分组的捕获时间进行排序。token-HTTP索引表的结构如图4所示。
为了降低算法的时间开销和空间开销,在建立token索引表时会去除区分度dif不高的token,如去除存在于大多数HTTP会话的token。
空间开销分析:考虑到互联网访问服务通常是由IIS或Apache服务器提供的,IIS或Apache默认的HTTP会话的大小为1 MB,如前所述本文选取缓存5 min时间间隔内的HTTP会话,通过对实际的骨干网络某个节点的流量分析发现,流量中每秒包含约10个网盘资源访问HTTP会话。因此,5 min内可能的网盘资源访问HTTP会话数量约为3 000个,所需的空间开销共计约为3 GB。
对于location-HTTP索引表,其所需的空间开销主要由URL和HTTP会话的编号ID所需的空间开销组成:URL的平均长度不超过1 024 byte;HTTP会话的编号ID的长度为8 byte。因此,5 byte时间间隔内索引表所需的空间开销约为3 MB。
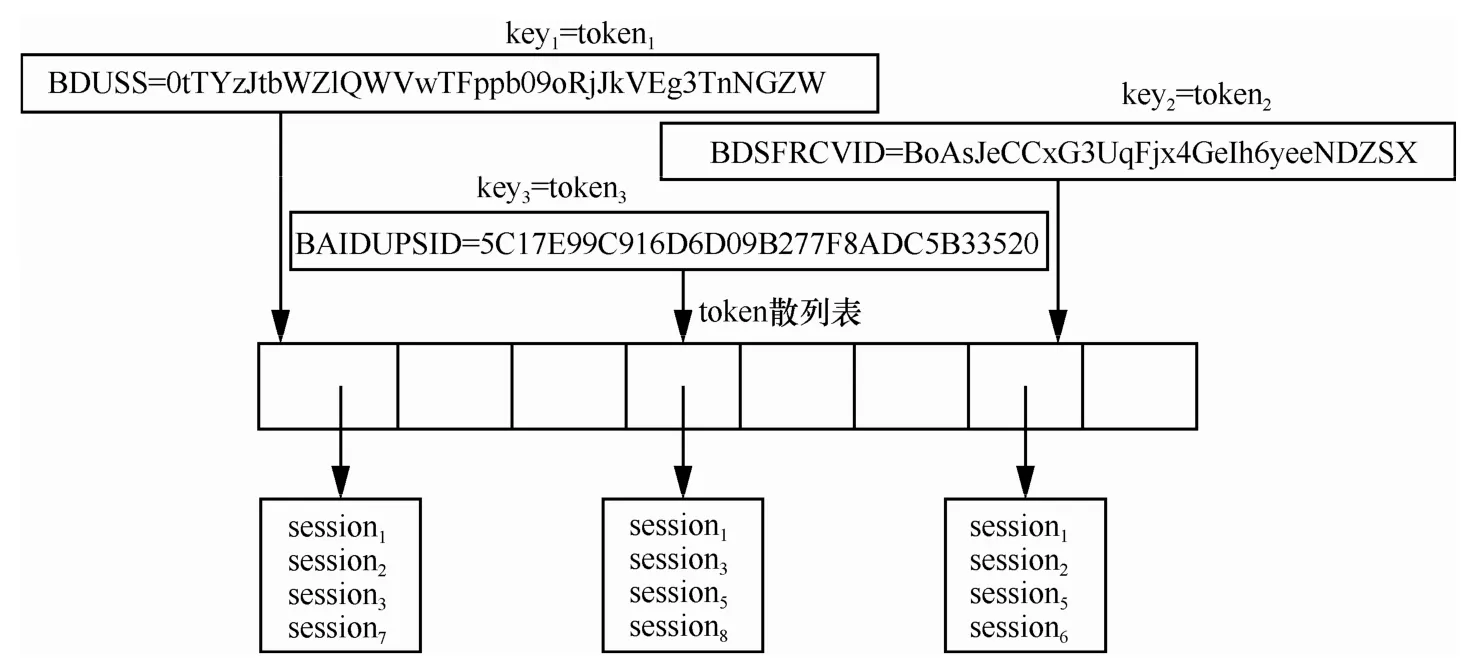
图4 token-HTTP索引表结构
对于token-HTTP索引表,其所需的空间开销也是主要由token和HTTP会话的编号ID所需的空间开销组成:每一个token不超过8 byte;HTTP会话的编号ID的长度为8 byte。一个HTTP会话的Cookie中的token(属性)的平均选取数量不超过5个,因此,5 min时间间隔内索引表所需的空间开销约为0.24 MB。
通过分析可以看出,在CookieTracing方法中,HTTP会话索引总的空间开销不超过4 GB。
4.2.3 URL跳转链计算
该模块的处理过程包括以下几步。
1) 将从下载资源的HTTP会话队列中出队的HTTP会话的URL作为key,查找location-HTTP索引表,获取重定向HTTP会话。
2) 将重定向HTTP会话的Cookie分割成token,以token为key,查找token-HTTP索引表,获取所有包含这些token的HTTP会话,本文将这些HTTP会话链定义为疑似HTTP会话链。
3) 遍历疑似HTTP会话链,统计HTTP会话在疑似HTTP会话链中出现的频率。如果其频率大于指定关联度阈值,即认为其属于下载资源的URL跳转链。
下面通过一个例子来说明,下载资源URL跳转链的计算。给定一个下载资源,其对应的重定向HTTP会话包含的Cookie可分为4个token,分别记为token1、token2、token3和token4,以这些token为key,查找cookie-HTTP索引表,获取4个token分别对应的HTTP会话链,如图5所示。
在图5所示的例子中,规定每一个HTTP会话若其出现在HTTP会话链中的频率大于1,则该HTTP会话属于URL跳转链。因此,比较token1、token2、token3和token4关联的4条HTTP链,发现编号为1、2、4、8的HTTP会话在4条HTTP会话链中出现的频率都大于1,所以它们属于下载资源的URL跳转链。根据token-HTTP索引表中,HTTP 会话链按照数据分组获取的时间排序,因此,该下载资源的URL跳转链即为1→2→4→8。
4.2.4 资源入口页面计算
与从疑似HTTP会话中获取URL跳转链的方法类似,CookieTracing方法基于统计的方式,从下载资源的URL跳转链中获取资源的入口页面,主要包含以下几个步骤。
1) 将具有相同下载资源标识ID的URL跳转链进行合并。
2) 遍历合并的URL跳转链,寻找割点,若该割点在该下载资源对应的所有的URL跳转链中出现的频率最高,则该节点即为该下载资源真正的入口页面。
3) 通过Load Runner[16]模拟用户访问网盘资源的分享链接,重新下载该资源,然后通过累计散列计算该资源的标识ID值并与CookieTracing计算出的标识ID做对比,如果二者相同,则该网盘资源的入口页面被确定。
5 实验与分析
为了验证本文提出的基于Cookie的网盘资溯源(CookieTracing)方法的性能,本节将对CookieTracing的有效性进行实验分析,首先测试CookieTracing方法进行网盘资源溯源的查准率和查全率;然后测试CookieTracing方法的运行效率。
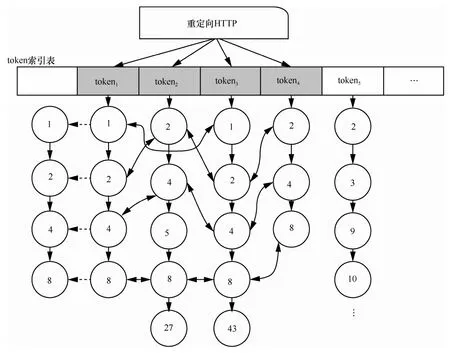
图5 URL跳转链获取过程
5.1 实验设置
1) 评价指标
在实验中,针对有效性测试,使用查准率和查全率进行评价。其中,查准率指查找到的正确资源入口点占查找到的网盘资源入口点的比例;查全率指查找到的正确资源入口点占所有网盘资源入口点的比例。在运行效率测试中,使用获取时间进行评价(指获取入口点的时间)。
2) 基准方法
为了验证CookieTracing方法对网盘资源溯源的性能,采用最新的方法WarningBird[10,11]作为基准方法(详见第2节)。
3) HTTP会话索引存储
在实验中,本文采用基于内存的key-value数据库Redis注3:http://redis.io/。存储HTTP会话索引。
在实验中,首先,通过百度网盘搜索引擎获取视频资源的分享链接。然后,利用Load Runner模拟用户请求这些分享资源链接,收集各自对应的URL跳转链。最后,在网关上统计随着下载资源增多,CookieTracing方法和WarningBird方法进行网盘资源溯源的查准率、查全率,以及它们的运行时间。下面分别介绍CookieTracing方法对应的有效性、运行效率实验结果。
5.2 实验结果
1) 有效性测试
CookieTracing方法与WarningBird方法查准率的实验结果如图6所示。
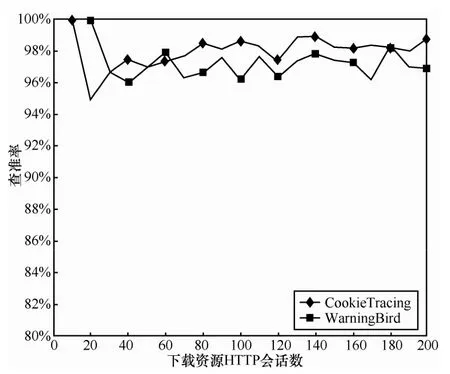
图6 查准率实验结果
从图6中可以看出,CookieTracing方法和WarningBird方法的查准率基本一致,平均查准率分别是98.67%、97.76%,导致这一现象的原因在于:这2种方法在网盘资源的入口点查找时采用的算法基本一致,都是通过合并资源的URL跳转链,计算跳转链中的公共节点获得资源的入口点。值得注意的是,在网关上由于流量捕分组采集不稳定因素,导致网盘资源溯源的查准率在一定范围内呈现波动现象,但整体上呈稳定趋势。
CookieTracing方法与WarningBird方法查全率的实验结果如图7所示。从图7可以看出,与WarningBird方法相比,在对网盘资源进行溯源时,CookieTracing的查全率远远高于WarningBird方法。其中,CookieTracing方法的平均查全率为98.86%,而WarningBird方法的平均查全率为16.67%。主要原因在于:WarningBird方法采用基于HTTP Referer字段的方法,在真实流量统计中,HTTP会话存在Referer字段的比例很少,只依赖Referer字段难以获取绝大部分下载资源的入口页面。而Cookie在资源请求访问中是普遍存在的,基于Cookie进行网盘资源溯源将是一种非常有力的方式。
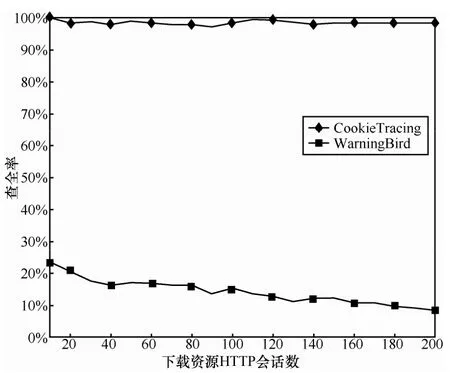
图7 查全率实验结果
由此可见,虽然WarningBird方法具有和CookieTracing方法几乎相当的查准率,但是在查全率方面,WarningBird方法仅是CookieTracing方法的,这进一步验证了基于Cookie方式的CookieTracing方法对网盘资源溯源的有效性。
2) 运行效率测试
本节将评估CookieTracing方法与基准方法WarningBird在网盘资源入口识别上的运行效率,实验结果如图8所示。
从图8中可以看出,随下载资源的增加,CookieTracing方法资源入口的查找时间明显快于WarningBird方法,并且随着下载资源HTTP会话的增加,CookieTracing方法的查找时间基本保持线性增长,而WarningBird方法呈指数增长,这说明在实时性方面CookieTracing方法明显优于WarningBird方法。主要原因在于CookieTracing方法采用累计散列算法计算资源ID标识,能够加快资源ID的计算。
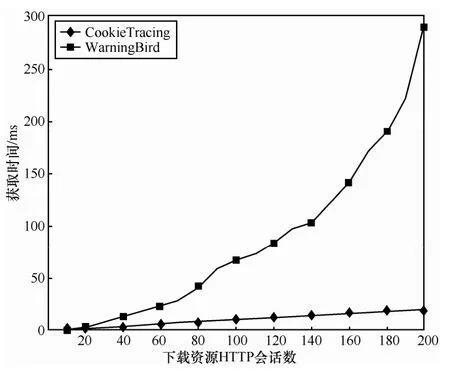
图8 运行效率实验结果
基于以上实验分析可以看出,与基准方法相比,CookieTracing方法在进行网盘资源溯源时,不仅可以获得更高的准确率,而且在实时性方面也能获得更好的效果,这些都表明CookieTracing方法的有效性,这也说明在网盘资源溯源中,采用Cookie是一项非常有用的技术。
6 结束语
如何从骨干网络节点上的海量流量中识别出网盘资源下载的HTTP会话的入口页面对于网络审查、网络取证、网络审计等具有重要意义。为此,本文提出一种基于Cookie的网盘资源在线溯源方法——CookieTracing。CookieTracing方法首先获取下载资源的URL跳转链,然后通过对比同一下载资源对应的不同URL跳转链获取唯一公共URL节点,认为该URL即为下载资源对应的入口页面。最后通过Load Runner模拟用户访问该URL,验证溯源的正确性。实验结果表明CookieTracing方法具有很好的性能。
[1]MAIER G,FELDMANN A,PAXSON V,et al.On dominant charac-teristics of residential broadband Internet traffic[C]//9th ACM SIGCOMM Conference on Internet Measurement.ACM,2009:90-102.
[2]GEHLEN V,FINAMORE A,MELLIA M,et al.Uncovering the big players of the Web[M].Springer Berlin Heidelberg,2012.
[3]MOBILE TRENDS A.Global mobile broadband traffic report[R/OL].Allot Communications,Technical Report,http://www.allot.com/MobileTrends Report,2010.
[4]BERGHEL H.The discipline of Internet forensics[J].Communications of the ACM,2003,46(8):15-20.
[5]WATTS S,NEWBY J M,MEWTON L,et al.A clinical audit of changes in suicide ideas with internet treatment for depression[J].BMJ open,2012,2(5):e001558.
[6]PANAH A,PANAH A,PANAH O,et al.Challenges of security issues in cloud computing layers[J].Rep Opin,2012,4(10):25-29.
[7]GOKCEN Y,FOROUSHANI V A,HEYWOOD A.Can we identify NAT behavior by analyzing traffic flows[C]//IEEE Security and Privacy Workshops (SPW).2014:132-139.
[8]LIU T T,YANG W,XU C L,et al.A SNR-based multi-channel multicast scheme for popular video in wireless networks[J].Journal of Networks,2013,8(3):628-635.
[9]HAYTON S J,JONES D R,LOBO A R,et al.Using entity tags (etags) in a hierarchical HTTP proxy cache to reduce network traffic:U.S.Patent Application 13/360,891[P].2012-1-30.
[10]LEE S,KIM J.Warningbird:a near real-time detection system for suspicious URLs in twitter stream[J].IEEE Transactions on Dependable and Secure Computing,2013 (3):183-195.
[11]JENEFA A,RAVI R.Classifier:a real-time detection system for suspicious URLs in Twitter stream[J].International Journal,2014,2(2).
[12]ZHANG J,SEIFERT C,STOKES J W,et al.Arrow:generating signatures to detect drive-by downloads[C]//20th International Conference on World Wide Web.ACM,2011:187-196.
[13]GOLDBERG J,WESTERLUND M,ZENG T.A network address translator (NAT) traversal mechanism for media controlled by real-time streaming protocol (RTSP)[J/OL].http://tools.ietf.ory/html/ draft-ietf-mmusic-rtsp-nat-03.
[14]MAIER G,SCHNEIDER F,FELDMANN A.NAT usage in residential broadband networks[M].Passive and Active Measurement.Springer Berlin Heidelberg,2011.
[15]NEASBITT C,PERDISCI R,LI K,et al.Clickminer:towards forensic reconstruction of user-browser interactions from network traces[C]// The 2014 ACM SIGSAC Conference on Computer and Communications Security,2014:1244-1255.
[16]JINYUAN C.The application of load runner in software performance test[J].Computer Development &Applications,2012,5:014.

林海伦(1987-),女,山东临沂人,博士,中国科学院信息工程研究所助理研究员,主要研究方向为数据挖掘、知识图谱。

李焱(1984-),男,湖北随州人,国家计算机网络应急技术协调中心工程师,主要研究方向为分布式系统和云计算。

王伟平(1975-),男,吉林舒兰人,博士,中国科学院信息工程研究所研究员、博士生导师,主要研究方向为大数据存储与处理。

岳银亮(1982-),男,河南许昌人,博士,中国科学院信息工程研究所副研究员,主要研究方向为大数据存储与智能化处理。

林政(1984-),女,山东青岛人,博士,中国科学院信息工程研究所助理研究员,主要研究方向为自然语言处理、情感分析。
Cookie based online tracing method for cyberlockers resource
LIN Hai-lun1,LI Yan2,WANG Wei-ping1,YUE Yin-liang1,LIN Zheng1
(1.Institute of Information Engineering,Chinese Academy of Sciences,Beijing 100093,China;2.National Computer Network Emergency Response and Coordination Center,Beijing 100029,China)
Cyberlockers have recently become an Internet-based agent of information dissemination.In light of the non-negligible fraction accounted by the traffic flows originating from cyberlocks,it is necessary to trace them for network security.An efficient and scalable cookie based online cyberlockers resource tracing method was proposed,called CookieTracing.It can achieve an efficient association between cyberlockers resource and its download redirect chain by construction of index table between cookie and HTTP sessions in massive HTTP sessions.Meanwhile,through cumulative hash algorithm,it can speed up the validation of tracing results.Experimental results show that this method performs good efficiency and scalability.
cyberlockers resource,shared links,URL chain,Cookie,HTTP session
s:The National Science and Technology Major Project of Hegaoji (No.2013ZX01039-002-001-001),The National Natural Science Foundation of China(No.61303056,No.61402464,No.61402473,No.61502478,No.61602467)
TP319
A
10.11959/j.issn.1000-436x.2016274
2015-10-25;
2016-06-30
“核高基”国家科技重大专项基金资助项目(No.2013ZX01039-002-001-001);国家自然科学基金资助项目(No.61303056,No.61402464,No.61402473,No.61502478,No.61602467)
