基于模糊聚类的PM2.5拟合组分选择模型的研究
2016-06-07徐恒鹏史国良轩淑艳南开大学计算机与控制工程学院天津00071南开大学软件学院天津00071南开大学环境科学与工程学院国家环境保护城市空气颗粒物污染防治重点实验室天津00071河北省唐山市玉田县环境保护局河北唐山06199
徐恒鹏,李 岳,史国良,王 玮*,轩淑艳(1.南开大学计算机与控制工程学院,天津 00071;2.南开大学软件学院,天津 00071;.南开大学环境科学与工程学院,国家环境保护城市空气颗粒物污染防治重点实验室,天津 00071;.河北省唐山市玉田县环境保护局,河北 唐山 06199)
基于模糊聚类的PM2.5拟合组分选择模型的研究
徐恒鹏1,2,李 岳1,2,史国良3,王 玮1,2*,轩淑艳4(1.南开大学计算机与控制工程学院,天津 300071;2.南开大学软件学院,天津 300071;3.南开大学环境科学与工程学院,国家环境保护城市空气颗粒物污染防治重点实验室,天津 300071;4.河北省唐山市玉田县环境保护局,河北 唐山 064199)
摘要:提出了一种新的P M2.5源成分谱拟合组分选择模型,在充分考虑拟合过程的物理意义的基础上,采用聚类正确率作为组分选择的依据.实验验证,该模型能够准确获取较好的拟合主组分, 相比与经验选或者手动盲选所得拟合结果,我们提出的模型将成功拟合(误差范围在0~0.05之间)的比例由40%提升到83%.
关键词:PM2.5源成分谱;组分选择;CMB受体模型;源解析;模糊聚类
* 责任作者, 副教授, kevinwangwei@nankai.edu.cn
近年来,多地频发的雾霾天气,让PM2.5成为时下最为热门的词汇之一,国家出台了《国十条》以指导当前大气污染防治[1].在进行大气污染治理之前,必须明确各种大气污染源类的分担率.大气颗粒物源解析的方法主要分为两大类:扩散模型和受体模型,其中发展最为迅速和成熟的是受体模型.自20世纪70年代以来,提出了化学质量平衡法(CMB)、因子分析法(FA)等受体模型,其中化学质量平衡(CMB)模型由于其物理意义明确且能定量计算各个源类贡献度而成为发展最迅速、应用最广泛的源解析技术[2],被我国环保部和美国EPA列为推荐模型,在中国得到了广泛的发展和应用[3].胡珊等[4]利用CMB模型对珠江三角洲PM2.5进行致癌风险及源解析、冯银厂等[5]采用CMB模型对乌鲁木齐环境空气中TSP和 PM10源解析、邹长武等[6]采用CMB模型提出了一种混合尘溯解析新方法.
虽然CMB模型在我国的颗粒物防治工作中发挥了重要作用,但是在利用CMB进行拟合时,如何选取拟合组分仍没有得到很好的解决.靠人工或经验挑选拟合组分,不仅工作量大且可能漏掉更优结果,很多研究人员提出了不同的解决思路,如2001冯银厂等[7]提出“穷举法”方法,即通过增加一些诊断方法以期获取“最优”的拟合结果[7].
本文针对PM2.5源成分谱在CMB模型拟合过程中存在的人工或经验选取组分时工作量大且较难获取“最优”拟合结果的问题,提出了一种基于模糊聚类的PM2.5源成分谱拟合组分选择模型,旨在为PM2.5源成分谱在CMB模型拟合过程中的组分选择问题提供一种新的解决思路,并对本文提出的组分选择方法进行了可行性研究.
1 基于模糊聚类的PM2.5源成分谱参与拟合组分的选择模型描述
PM2.5源成分谱数据是典型的小样本、高维度数据,且不同维度含量的数量级有时相差极大,出现维数灾难[8],即随着维数的增加,计算量呈指数倍增长.有鉴于此,可将PM2.5源成分谱拟合组分问题转换为机器学习中的特征选择问题.通过特征选择方法,对源成分谱数据进行处理,将得到的相应 “主组分”当作参与拟合的组分.本文采用模糊聚类方法对源成分谱数据进行聚类,将聚类正确率作为PM2.5源成分谱拟合组分选择依据或标准.

图1 算法整体流程Fig.1 The flow chart of algorithm
本文提出的基于模糊聚类的PM2.5源成分谱的参与拟合组分选择模型的实验流程如图1所示.输入为PM2.5源成分谱数据,首先设定组分变异、组分含量横向对比以及组分含量纵向对比这3组参数的取值,进而生成候选组分集集合,对所有组分候选集进行聚类中心初始化,再用FSC聚类算法进行模糊聚类,最后计算聚类正确率,将聚类正确率最高的参数对应的候选组分集作为参与拟合的最佳组分集.在进行聚类中心初始化时采用协方差矩阵进行样本筛选及聚类中心初始化操作,在后面章节2.1、2.2、2.3、2.4将详细介绍.
1.1 组分候选集生成方法
PM2.5源成分谱中,样本数目少,组分数目较多,根据组分的物理意义,设定3组参数来生成拟合组分候选集.
组分变异参数:对于每种源类,其中某组分变异系数越小,说明该组分离散度越小.将该组分纳入CMB等主流源解析模型中,拟合结果更准确.组分变异系数其中,cvi,l表示对于源类i中组分l的变异系数,σi,l表示源类i中组分l的标准差,ui,l表示源类i中组分l的均值.
组分含量横向对比参数:即组分含量大小.对于每种源类,组分含量较大的若干个组分,一般均为该源类的必选组分,需纳入CMB等主流源解析模型,也可称为组分含量横向对比系数.
组分含量纵向对比参数:对于某种源类,有一些标识性组分是其他源类所不具有的,组分含量纵向对比系数用来找出该种源类的标识性组分.对于源类i,假设组分l是其标识性组分,那么para_veri,l值就为1(测量精确的情况).对比系数如下:

式中,para_veri,l表示源类i中组分l的组分纵向对比系数;ui,l表示源类i中组分l的均值;n表示源类个数.
设定上述3个参数取值范围,组合生成不同的候选组分集η.例如,可以将求出的变异系数划分为10个取值空间,即10个候选集.对于组分含量横向对比及纵向对比参数也可以通过设定范围来生成各自的候选组分集.最终,将上述生成的三类组分候选集进行简单组合去重后,生成最终的候选组分集η.
1.2 FSC模糊加权软子空间聚类算法
过去几十年里,针对已有的传统聚类方法,出现了很多基于特征加权或特征选择的数据挖掘方法,其中子空间聚类是目前高维数据聚类分析中一个非常重要的研究领域[9-10].根据聚类方法的不同,主要分为两种聚类形式[12-13]:硬子空间聚类、软子空间聚类.
软子空间聚类算法具有更好的适应性与灵活性,可以分为模糊加权子空间聚类方法及熵加权子空间聚类算法.模糊加权子空间聚类算法包括FWKM、FSC[11]、AWA,该类方法对每一类的各组分进行模糊加权,对于每一个组分,样本分布越紧凑,则组分获得权值越大,与CMB拟合算法思想一致.此外,组分方差越小,所占权重越大,同时为权重赋予一个模糊指数,使该聚类算法更具有适应性.
在FSC算法中,一个源类在某个组分或特征上的密度越大,该组分或特征对于该源类的贡献度或权值越大.对于给定的源成分谱样本数据集,本文利用软子空间聚类算法得到k个源类中心值,即每个源类的信息:.定义uji表示第i个样本xi属于第j个聚类中心zj的模糊隶属度,定义U表示整个源类的模糊隶属度矩阵,.
此外,以期更好发现各个数据簇相应的子空间结构,软子空间聚类算法在聚类过程中对每个数据簇的全部特征赋予一个特征加权系数.因此,定义wjh表示第h个特征对于第j个数据簇的重要性或贡献度,则W表示整个源分谱样本数据集的特征加权系数矩阵,.
FSC模糊聚类的目标函数如下[11]:

文献[11]给出了上述公式的详细算法步骤及W、Z和U的迭代公式.
在初始化聚类中心时Z时,采用了基于协方差矩阵的样本筛选方法[14].
1.3 基于模糊聚类的PM2.5源成分谱组分选择模型描述
本文采用聚类正确率作为组分选择衡量标准.聚类正确率是指被正确划分样本占总体样本的比率,定义为:

其中,numl表示源类l被正确划分的样本数,N表示所有源成分谱样本数目.
对于组分候选集中每一个组分集合ηt,利用文献[11]样本筛选方法进行聚类中心初始化,然后根据算法FSC进行模糊聚类,最后计算该ηt下的聚类正确率CAt.最后选取CA数组中最大的值对应的组分候选集作为输出.
测绘新技术在建筑工程测量中的地位越来越重要,尤其是随着建筑工程行业的规模不断壮大其重要性越来越突出。但与此同时,传统的测绘技术因为效率、准确性和可靠性的问题很难再满足建筑工程发展的需要。在这种状况下,越来越多的新的测绘技术不断涌现对推动测绘事业的发展以及提高建筑工程测量的准确度和可靠性起到了重要作用。
算法描述如下:
算法.Dim_Sel algorithm
输入:PM2.5源成分谱数据集,源类个数k,组分候选集η,模糊加权系数α,一个无穷小参数ε.
输出:输出最佳参与拟合组分
第1步:从候选集η选取一个组分集ηt;
第2步:按照文献[14]样本筛选算法进行聚类中心初始化;
第3步:按照文献[11]模糊聚类算法聚类; 第4步:依据公式(3)计算聚类正确率CA ;
第5步:计算出每个阈值对应的CA,找到CA最大值对应的组分候选集输出.
2 方法验证与评估
2.1 受体生成方法
为了保证实验结果的准确性、有效性,实验所用的PM2.5源成分谱数据是来自于实际监测数据,该数据集中,每个样本包括101个属性,含有3个源类:SOIL类、COAL类、VEHICLE类,即在进行模糊聚类时源类个数k设定为3.实验所用源解析工具是美国环保EPA-CMB8.2[15]受体模型软件.受体生成方法参考相关文献,从PM2.5源成分谱3种源类中随机选取3个样本,再按照随机设定的贡献度生成一条受体.实验时,随机生成30条受体数据,对所有组分候选集进行验证,进而证明本文提出的组分选择的方法可行性.
2.2 拟合结果衡量方法
CMB软件拟合得出的各个源类的贡献度需与真实贡献度进行比较,本文采用相似度系数及平均绝对误差AAE[16]进行衡量.相似度系数包括夹角余弦和相关系数.
夹角余弦函数忽略两数据点(向量)之间的绝对长度而考虑其在方向上的相互关系,拟合贡献度与真实贡献度越相近,其值越大.
相关系数是关于向量标准差的夹角余弦,它表示两个向量线性相关的程度,若两个向量越相近,其值越大.

通过计算拟合贡献值和真实贡献度的平均绝对误差(AAE)来表示拟合值和真实值的平均差异,若AAE的值较低,表明拟合值和真实值较接近.本文通过上述3种衡量标准,对算法Dim_sel验证.
2.3 聚类正确率与组分选择的关系验证
图2为阈值集η与聚类正确率CA关系,其中,横坐标表示阈值集η,纵坐标表示聚类正确率.从图2可知第11组组分候选集相对应的聚类正确率最高,约为84%.

图2 聚类正确率变化Fig.2 Variation of CA
图3、图4、图5中分别为采用相似系数、夹角余弦及平均绝对误差对拟合结果进行评估的折线图,横坐标代表组分候选集η,纵坐标分别为30条受体拟合结果与真实贡献度的相似系数、夹角余弦及平均绝对误差的平均值大小.图3与图4的走势和图2的走势近乎一致,图5的走势和图2的走势几乎相反,表明选择聚类正确率较高的点对应的组分候选集进行CMB拟合,其拟合正确率较高,说明了将聚类正确率作为拟合组分选择标准的有效性.

图3 相似系数衡量拟合结果变化Fig.3 Evaluation of fitting results by similarity factor
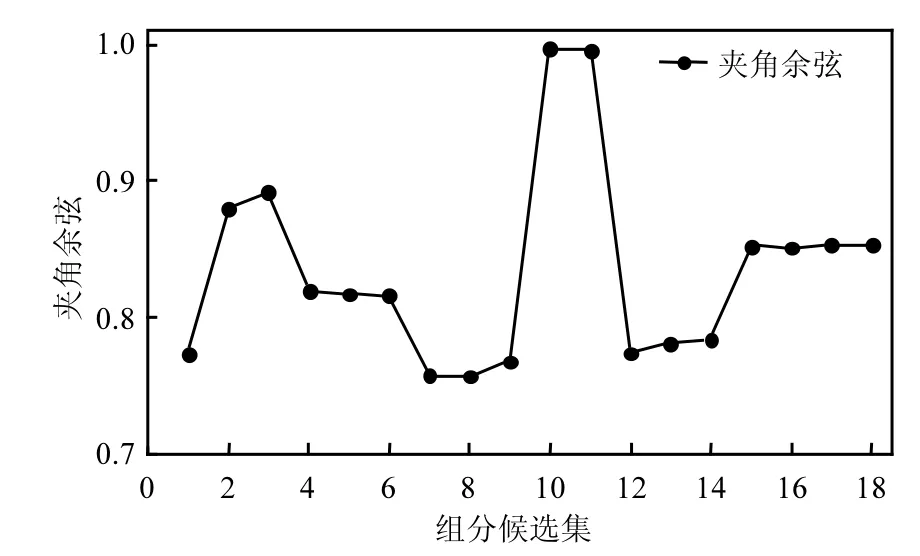
图4 夹角余弦衡量拟合拟合结果变化Fig.4 Evaluation of fitting results by angle cosine

图5 平均绝对误差衡量拟合结果变化Fig.5 Evaluation of fitting results by AAE
2.4 参与拟合最佳组分与盲选法对比试验
图6为候选集组分个数与聚类正确率对应关系图,从图中可知聚类正确率最高点对应的参与拟合组分是16个,其中包含了Al、Si、OC、EC等3种源类的标识性组分,也是拟合过程中人工经验筛选的必选组分,也包含了Ca、K、Cr、Fe等主要组分[2,5,7].
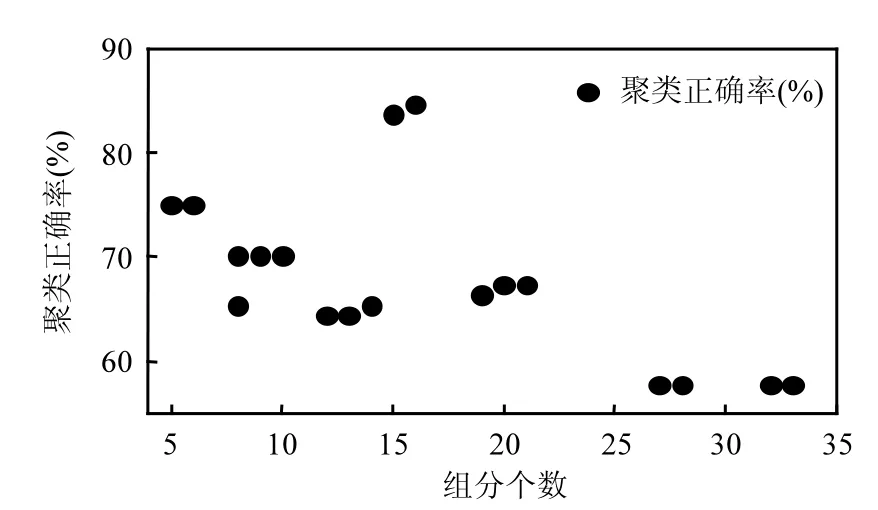
图6 候选集组分个数与聚类正确率Fig.6 The number of components corresponding to CA
本文设计了两组实验进行对比:对于实验随机生成的30条受体,一组选取聚类正确率最高点对应的16个组分进行拟合;另一组采用k折交叉验证思想,对20次手动盲选选取组分进行拟合,其中选取组分中均含三种源类常用的拟合组分Al,Si,OC,EC等.手动盲选实验中即包含随机选取组分,又包含三种源类的常用组分,使对比实验结果更加客观与稳定.
图7为利用AAE对20次手动盲选实验的拟合结果进行衡量,横坐标表示受体ID,纵坐标表示AAE.三条线分别对应20次手动盲选实验中每个受体拟合结果的AAE的平均值,最大值及最小值.从图7可知:最大值线和最小值线之间的浮动较大,说明采用手动盲选组分选择方法得到的拟合结果较为随机且常出现无法得到拟合结果的情况;平均值线与最小值线浮动较小,说明平均值线可较好体现手动盲选实验的拟合结果.
图8为利用AAE对盲选及算法选组分拟合所得到的结果进行衡量对比折线图.横坐标代表受体ID,纵坐标是AAE,即30条受体拟合结果与真实贡献度之间的平均绝对误差,其值越小表示拟合结果越精确.采用聚类正确率最高的16个组分所得拟合结果的AAE均远低于20次手动盲选拟合结果AAE的平均值,再次表明采用本文算法模型选取的组分所得拟合结果较大程度上优于随机选取组分所得拟合结果,并且一定程度上减少了拟合实验的次数,同时减少了PM2.5源解析过程中的工作量.
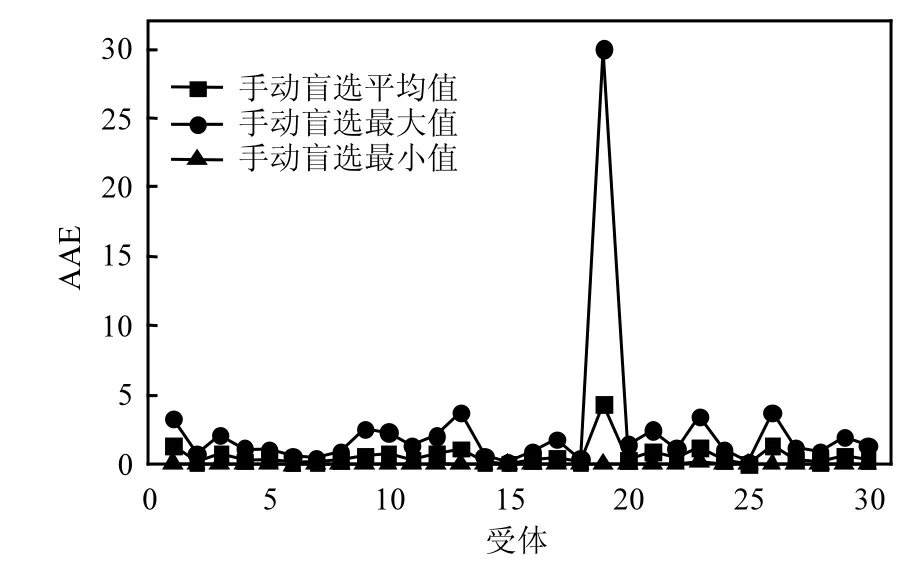
图7 AEE衡量盲选拟合结果Fig.7 Evaluation of Random selection fitting results by AEE

图8 AEE衡量拟合结果对比Fig.8 Fitting results contrast based on the AEE

图9 COAL源拟合结果对比Fig.9 The comparison diagram of COAL fitting results
图9、图10、图11分别表示源类COAL、SOIL、VEHICLE的算法选及随机手选的拟合结果与真实贡献度的比较.横坐标表示受体ID,纵坐标表示拟合结果减去真实贡献度的差值的绝对值.观察得知,手动盲选对应的86%以上的受体的拟合结果与真实贡献度的误差绝对值均远高于算法选所对应的误差绝对值,即采用随机手选的组分较难得到精确度较高的CMB拟合结果.

图10 SOIL源拟合误差对比图Fig.10 The comparison diagram of SOIL fitting results

图11 VEHICLE源拟合结果Fig.11 The comparison diagram of VEHICLE fitting results
采用算法选组分进行CMB拟合,所得3种源类的拟合结果绝对误差值范围在(0~0.05)之内的比例达到83%,但采用手动盲选组分进行拟合的比例仅为40%,即采用本文提出的组分选择模型筛选的组分参与的拟合效果与真实贡献度的误差较小,而手动盲选的拟合结果则和真实贡献度曲线误差较大,进一步表明了算法模型的有效性.
3 结论
本文提出了一种基于模糊聚类的PM2.5拟合组分选择模型,通过选取聚类正确率较高的值所对应的组分来进行CMB拟合.实验结果表明,采用本文提出的PM2.5拟合组分选择方法,有86%的受体所得拟合结果优于手动盲选所得拟合结果,其误差范围在0~0.05之间的比例由40%提升到83%,在一定程度上提高了PM2.5源成分谱CMB拟合结果的精确度.
参考文献:
[1] 大气污染防治行动计划 [J].中国环保产业, 2013,(10):4-9.
[2] Shi G L, Tian Y Z, Zhang Y F, et al.Estimation of the concentrations of primary and secondary organic carbon in ambient particulate matter: Application of the CMB-Iteration method [J].Atmospheric Environment, 2011,45(32):5692-5698.
[3] 朱 坦,吴 琳,毕晓辉,等.大气颗粒物源解析受体模型优化技术研究 [J].中国环境科学, 2010,30(7):865-870.
[4] 胡 珊,张远航,魏永杰.珠江三角洲大气细颗粒物的致癌风险及源解析 [J].中国环境科学, 2010,30(11):1202-1208.
[5] 冯银厂,彭 林,吴建会,等.乌鲁木齐市环境空气中TSP和P M10来源解析 [J].中国环境科学, 2005,25(S1):30-33.
[6] 邹长武,印红玲,刘盛余,等.大气颗粒物混合尘溯源解析新方法[J].中国环境科学, 2011,31(6):881-885.
[7] 冯银厂.关于化学质量平衡(CMB)受体模型应用中若干技术问题的研究 [D].天津:南开大学, 2002.
[8] Scott D W.Multivariate density estimation: theory, practice, and visualization [M].Wiley.com, 2009.
[9] Müller E, Günnemann S, Assent I, et al.Evaluating clustering in subspace projections of high dimensional data [J].Proceedings of the VLDB Endowment, 2009,2(1):1270-1281.
[10] Parsons L, Haque E, Liu H.Subspace clustering for high dimensional data: a review [J].ACM SIGKDD Explorations Newsletter, 2004,6(1):90-105.
[11] Gan G, Wu J.A convergence theorem for the fuzzy subspace clustering (FSC) algorithm [J].Pattern Recognition, 2008,41(6): 1939–1947.
[12] Deng Z, Choi K S, Chung F L, et al.Enhanced soft subspace clustering integrating within-cluster and between-cluster information [J].Pattern Recognition, 2010,43(3):767–781.
[13] Jing L, Ng M K, Huang J Z.An Entropy Weighting k-Means Algorithm for Subspace Clustering of High-Dimensional Sparse Data [J].IEEE Transactions on Knowledge & Data Engineering, 2007,19(8):1026-1041.
[14] 徐恒鹏.基于智能信息处理的PM2.5源解析问题的研究 [D].天津:南开大学, 2014.
[15] Habre R, Coull B, Koutrakis P.Impact of source collinearity in simulated PM2.5data on the PMF receptor model solution [J].Atmospheric Environment, 2011,45(38):6938-6946.
[16] Christensen W F, Gunst R F.Measurement error models in chemical mass balance analysis of air quality data [J].Atmospheric Environment, 2004,38(5):733–744.
The fitting component selection model of PM2.5based on fuzzy clustering.
XU Heng-peng1,2, LI Yue1,2, SHI Guo-liang3, WANG Wei1,2*, XUAN Shu-yan4(1.College of Computer and Control Engineering, NanKai University, Tianjin 300071, China;2.College of Software, NanKai University, Tianjin 300071, China;3.State Environmental Protection Key Laboratory of Urban Ambient Air Particulate Matter Pollution Prevention and Control, College of Environmental Science and Engineering, NanKai University, Tianjin 300071, China;4.Yutian Environmental Protection Agency, Tangshan 064199, China).China Environmental Science, 2016,36(1):12~17
Abstract:In current research, there is a lack of uniform standards for components selection in PM2.5source profile apportionment.Researchers tend to choose the component manually and empirically, leading to a subsequent poor fitting result, or even failures.Concerning on this problem, this paper has proposed an innovative component selection model of PM2.5source profiles apportionment.On the basis of the physical representative of each component, the proposed model calculates the accuracy of fuzzy clustering as the standard score for selection.The experiments prove that our model outperforms the traditional empirical models.The successful rate for fitting, measured by the fitting errors in 0 to 0.05, grows to 83% by implementing our model, in contrast to rate of 40% from the traditional selection model.
Key words:PM2.5source profile;components selection;CMB receptor model;source apportionment;fuzzy clustering
中图分类号:X513
文献标识码:A
文章编号:1000-6923(2016)01-0012-06
收稿日期:2015-06-01
作者简介:徐恒鹏(1988-),男,山东临沂人,在读博士,主要从事PM2.5源成分谱拟合模型研究.发表论文1篇.
