近红外光谱建模样本选择方法研究
2016-06-05靳召晰张秀娟罗付义赵盛毅严衍禄
靳召晰、张秀娟、罗付义、安 冬,3*、赵盛毅、冉 航、严衍禄
1. 中国农业大学信息与电气工程学院、北京 100083 2. 山东省德州市农业局、山东 德州 253016 3. 农业部农业信息获取技术重点实验室、北京 100083
近红外光谱建模样本选择方法研究
靳召晰1、张秀娟2、罗付义2、安 冬1,3*、赵盛毅1、冉 航1、严衍禄1
1. 中国农业大学信息与电气工程学院、北京 100083 2. 山东省德州市农业局、山东 德州 253016 3. 农业部农业信息获取技术重点实验室、北京 100083
针对小麦品种多分类问题、使用近红外光谱进行定性分析。建模样本增加能够使模型包含信息增多、但同时也会导致信息冗余、增加建模时间和存储空间、所以需要通过样本选择降低数据量。如果盲目选择必然会使信息丢失、模型效果将大打折扣、因此、在传统选择方法基础上、提出k近邻-密度样本选择方法。使用多天采集的小麦种子近红外漫反射光谱、在对其原始光谱进行预处理和特征提取后、分别使用随机抽样、k近邻和k近邻-密度三种方法进行建模样本选择、然后建立仿生模式识别模型和改进的仿生模式识别模型。实验结果显示、在建立的仿生模式识别模型中、使用k近邻-密度样本选择方法的模型识别效果优于另两种方法、且建模样本量大大降低; 而在改进的仿生模式识别模型中、使用k近邻-密度样本选择方法识别效果明显优于随机抽样、略好于k近邻方法、但使用k近邻-密度方法所选择的样本数量远少于k近邻方法。结果证明k近邻-密度样本选择方法不仅能够大大降低建模样本量、而且保证了模型质量、对解决小麦品种多分类问题有明显效果。
小麦; 近红外光谱; 定性分析; 样本选择
引 言
近红外光谱分析是利用近红外谱区包含的物质信息、对有机物质进行定性和定量分析的一种分析技术、兼备了可见光区光谱分析信号容易获取和红外区光谱分析信息量丰富的两方面优势。现代近红外光谱分析是从农业分析开始的、由于近红外光谱几乎可以分析所有与含氢基团有关样品的物理性质和化学性质、被称为“具有解决全球农业分析的潜力”[1]。随着光学技术、计算机技术和电子技术等现代科技的进步、现代近红外光谱分析技术逐渐发展并呈现出被广泛运用的趋势。
近红外光谱分析的关键是建立预测效果优秀的数学模型、而数学模型对样品的预测效果取决于建立模型时所用的数据[1]。随着信息科技时代的来临、我们需要处理的是海量高维的数据、当数据的数量及所包含的信息日益增多时、如何从中提取有效信息加以利用是我们面对的问题。近红外光谱的数学模型并不是使用的样本数越多越好、随着建模样本数的增加、模型中所引入的干扰因素及异常误差就会增多、过多的干扰信息会掩盖有用信息、降低模型性能[2]; 同时、大量相似、冗余的数据会大大增加建模运算量、进而增加建模时间和储存空间。本工作所使用的小麦种子每个品种都有来自不同产地的多份样品、信号复杂。所以、需要在保证模型性能的前提下、从大量可用的数据中选取具有代表性的建模样本。
随着近红外光谱样本选择越来越受到重视、其相应的研究也逐年增加。张其可等基于主元分析(principle component analysis,PCA)残差、在同类就近取样的基础上引入异常光谱剔除技术进行训练样本的二次提取、建立偏最小二乘模型、用于近红外校正模型的训练样本选择、能够有效剔除异常光谱[3]; 高学金等提出一种样本相似度度量方法、将亲和度引入到加权欧氏距离中并转化成相似度度量函数、应用到相似样本选择中、该方法有效增强了模型的泛化能力、并缩短预测时间[4]; 祝诗平等提出“二审”算法、采用“回收”算子将错判的异常样本保留、通过增加样本量使模型更具代表性和稳定性[5]。针对本实验室实验需求、及实验获取样本的大量复杂等特点、我们提出k近邻-密度样本选择方法、有效选择建模样本。下面对不同算法进行具体介绍。
1 相关方法
1.1 基于统计抽样的方法
抽样是统计学中一种常用的调查方法、从全体调查对象中按照一定的方法抽取一部分进行调查、然后根据样本数据对总体目标进行评估。抽样调查是一种从所有研究对象中抽取一部分进行调查并对全体研究对象做出估计和推断的非全面调查方法[6]。它按照随机原则抽取样本、每一部分样本都有被抽取的概率。它具有降低成本、节约时间、正确性高及适用范围广等优势。随着大规模数据采集应用的普遍、抽样思想被引入到模式分类、聚类分析和数据挖掘中、以达到高效分析处理数据的目的[7]。
1.2 基于最近邻的方法
这类方法始于上世纪六七十年代、在最近邻分类器被提出后陆续出现了一些基于最近邻编辑规则(nearest neighbor editing rules)的样本选择方法。这些方法大都参考了样本分布“同类相聚、异类相离”的假定。基于最近邻规则的样本选择方法注重于对噪声的剔除及分类边界的取舍、优化了样本分类能力。
1.3 基于密度的方法
基于密度的方法主要是以d1为半径计算每个样本的密度并进行排序、然后根据需求进行样本删除、密度函数和d1的选取是经验值[8]、需要在不同场合适当进行调整改进。
2 k近邻-密度样本选择方法
参考前人的研究和几种经典方法、提出k近邻-密度样本选择方法、该方法分为基于k近邻样本选择和按密度进行选择两个步骤(图1)、具体实现过程如下。
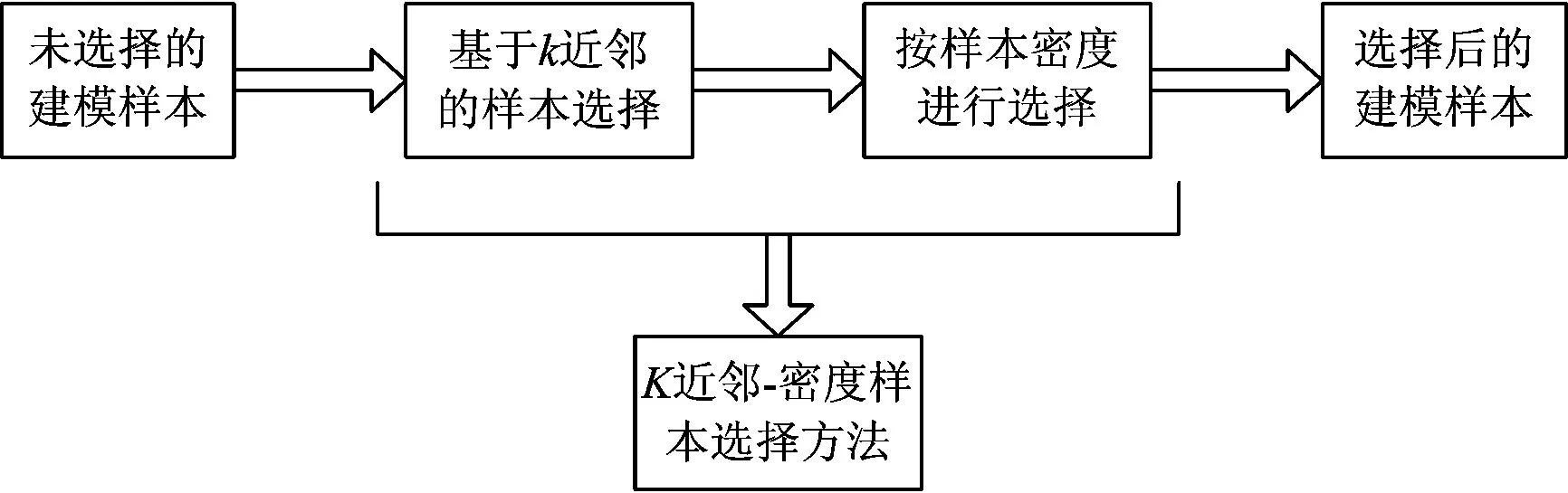
图1 建模样本选择步骤
1)基于k近邻的样本选择
在这一过程中、首先将建模样本进行k-means聚类、以聚类中心作为新的建模样本、根据Prim(普利姆)算法[10]构建最小生成树、作为模型构网点、然后根据k近邻法则循环剔除样本。步骤如图2所示。
2)按样本密度进行选择
第1)步能够有效剔除离群点、但对于质量良好的样本数据并不能有效较少数据量、所以根据密度筛选原则对建模样本进行二次选择。
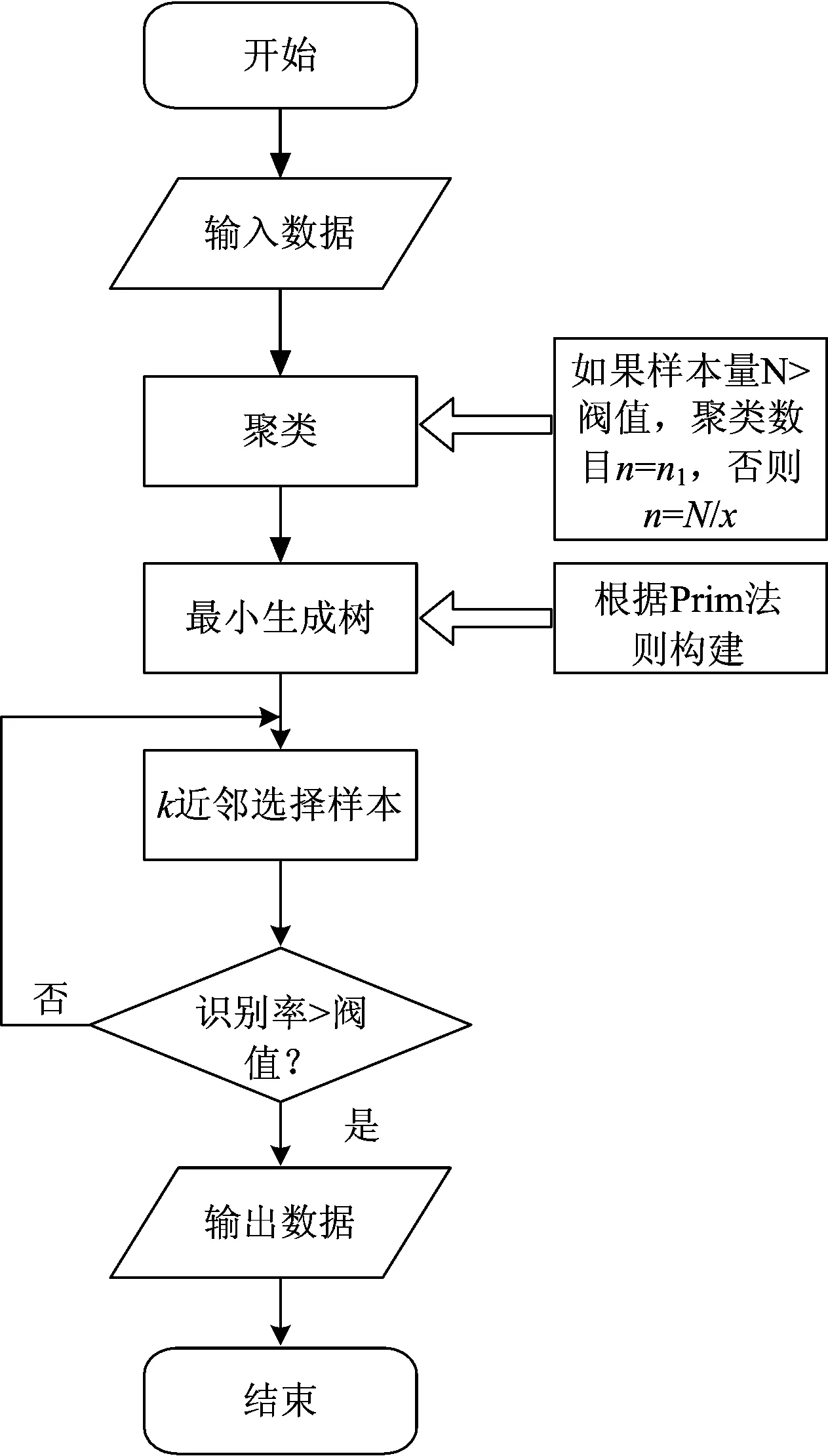
图2 基于k近邻的样本选择流程图
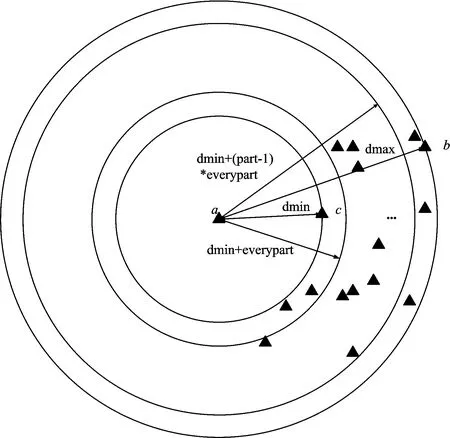
图3 按密度进行样本选择二维示意图
(1)计算相关距离
计算每两个样本点之间的相关距离、并找出最大距离dmax(假设为样本a和样本b之间的距离)和最小距离dmin(假设为样本a和样本c之间的距离)。
(2)密度筛选
将dmax与dmin的差值part等分、即
everypart=(dmax-dmin)/part
(1)
然后以样本a或样本b为球心、以dmin为基础半径、everypart为增量等间隔增加做球、即半径
rn=dmin+everypart×n
(2)
其中、n为从0到part的自然数。
最后按梯度选择每两个相邻球之间的样本。
3 实验部分
3.1 仪器与样品
实验所用光谱均使用聚光科技有限公司的SupNir-2720漫反射式谷物分析仪采集、谱区范围:1 000~1 799 nm、实验分析软件使用Matlab R2014a。
实验样品使用山东良星种业有限公司提供的3个品种不同产地的共13份小麦样品、具体信息如表1所示。光谱测量时、将小麦种子装进样品池、并使表面均匀以避免差异、每次每个品种采集10条光谱、所采集到的光谱质量良好。部分近红外漫反射原始光谱如图4所示。
3.2 光谱预处理和特征提取
小麦种子真实性鉴定模型系统框架如图5所示。
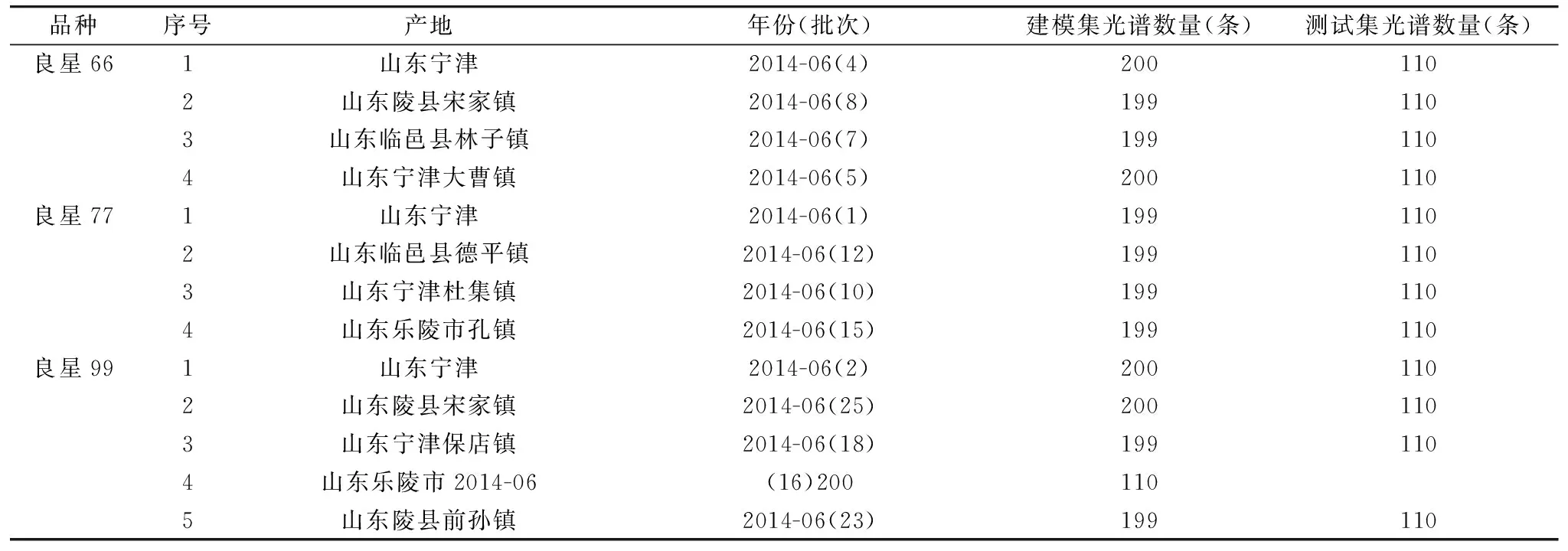
表1 小麦样品信息表
注:建模集使用光谱为20次采集得到、测试集光谱为与建模集间隔40天后分11次采集所得
Note:The spectra of the modeling set is collected in 20 times,the spectra of the test set 1 s collected in 11 times,and the collect time interval
光谱预处理使用平均窗口平滑(smoothing,SM)、一阶差分求导(first derivative,FD)和均值中心化(mean center,MC)处理方法、以达到去除噪声和背景干扰、提高光谱分辨率及消除多重共线性等目的。光谱的特征提取使用偏最小二乘(partial least squares,PLS)和线性判别分析(linear discriminant analysis,LDA)。
3.3 建立识别模型
使用仿生模式识别和经过改进的仿生模式识别分别建立识别模型、验证样本选择的有效性。
3.3.1 仿生模式识别(biomimetic pattern recognition,BPR)
仿生模式识别理论是王守觉院士于2002年提出的一种新的模式识别理论、与传统模式识别不同的是、BPR是基于对每一类事物的的“认识”、而不是划分; 同时它引入了同类样本之间存在的某些普遍联系、利用这种规律性建立了“多维空间中非超球复杂几何形体覆盖”的识别原理。其理论分析数学工具正是点集拓扑学中对高维流形的研究问题、这与传统模式识别的数学工具也有根本的差别。因此、仿生模式识别也称为拓扑模式识别[9]。
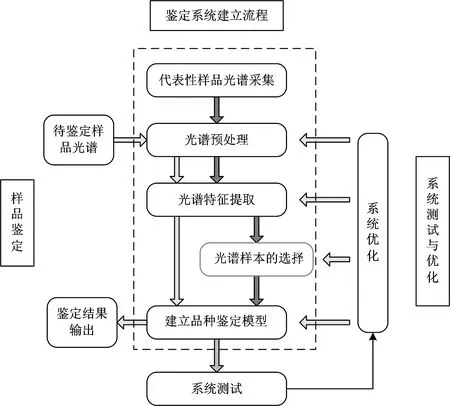
图5 小麦种子真实性鉴定模型系统框架
3.3.2 改进的仿生模式识别(biomimetic pattern recognition improved,BPRI)
基本的仿生模式识别算法会对每一个模型训练一个半径、然后根据半径判别测试样品归属。在此基础上、通过N近邻方式、找出N个与模型的最小距离、然后投票选出测试样本最终归属。这种方式不单单只依靠模型半径、改善了测试样本异常对结果的影响、增加了结果可靠性。
4 结果与讨论
4.1 数据和评价指标
实验中、建模样本使用20次采集到的13份样品各200条光谱数据、测试集样本使用时间间隔40天后采集到11次数据。使用正确识别率(correct acceptance rate,CAR)、正确拒识率(crrect rejection rate,CRR)和偏离度来对模型性能进行评价。

(3)

(4)

(5)
其中、类内距离为同一种类测试集平均光谱和建模集平均光谱之间的欧氏距离、类间距离为建模集不同品种平均光谱之间欧氏距离的平均值。
对系统性能而言、正确识别率和正确拒识率都是越高越好、而偏离度则是越小越好、其说明所选择的建模样本代表性越高、测试集和训练集数据的差别越小。实验中将三者均作为系统优化目标。
4.2 样本选择结果
在使用BPR和BPRI两种识别方法建立模型前、分别用随机抽样、k近邻样本选择和k近邻-密度样本选择三种方法对建模样本进行选择、然后对测试集进行测试、统计平均识别率、拒识率和偏离度、从而比较三种样本选择方法的有效性。实验结果如图6和图7所示。
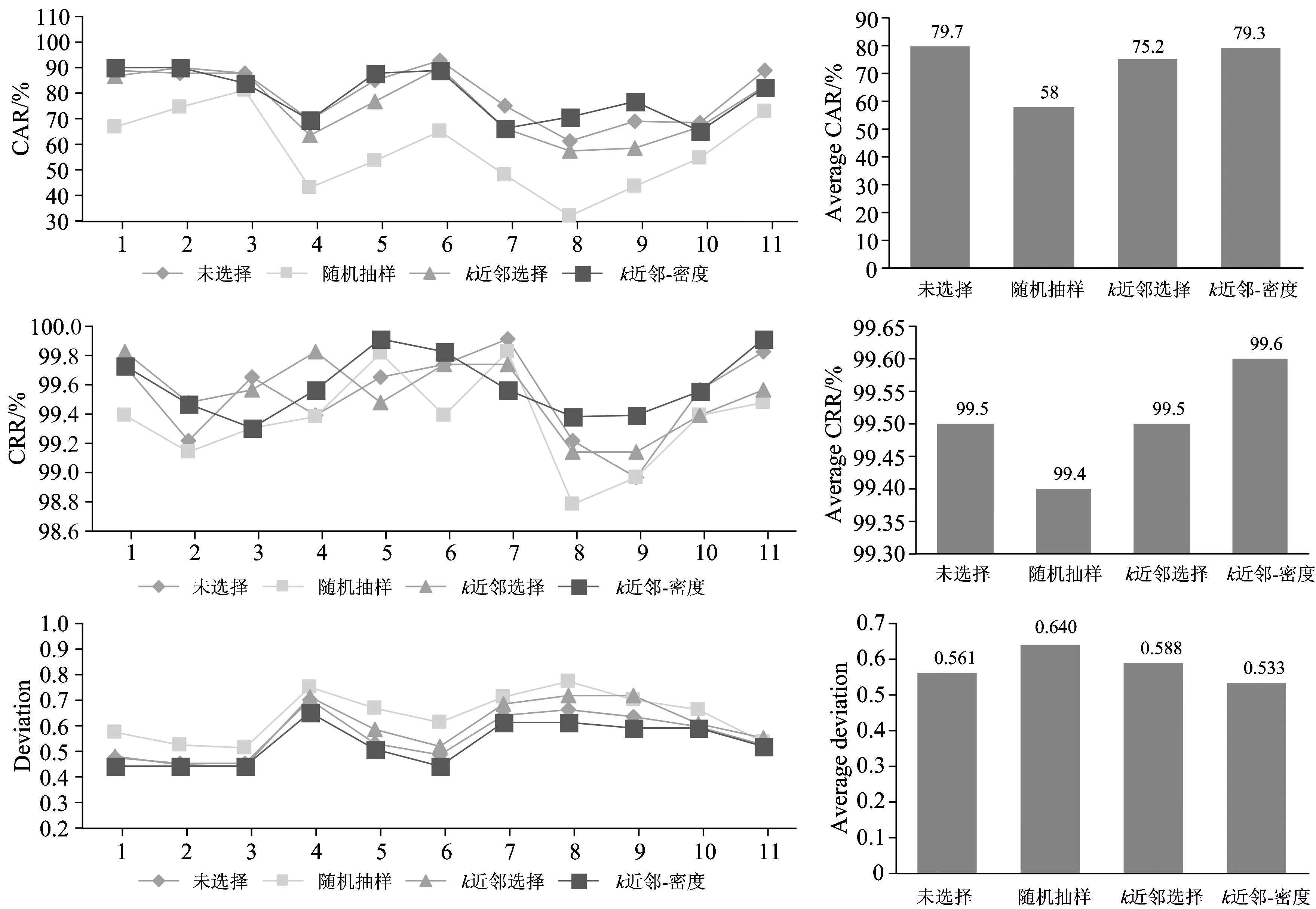
图6 BPR建模结果统计
从图6和图7可以看出、使用BPR作为识别方法时k近邻-密度样本选择后测试集的平均识别率和拒识率最高(除不进行样本选择外)、偏离度最小、即识别效果最好、优于k近邻样本选择、随机抽样效果最差; 以BPRI作为识别方法结果相同、而且以k近邻-密度方法进行样本选择后识别效果略好于不进行样本选择。同时从表1来看、虽然以k近邻作为样本选择方法的模型识别效果只是稍稍低于k近邻-密度样本选择方法、但后者使样本量大大降低、约为原始样本量的三分之一。
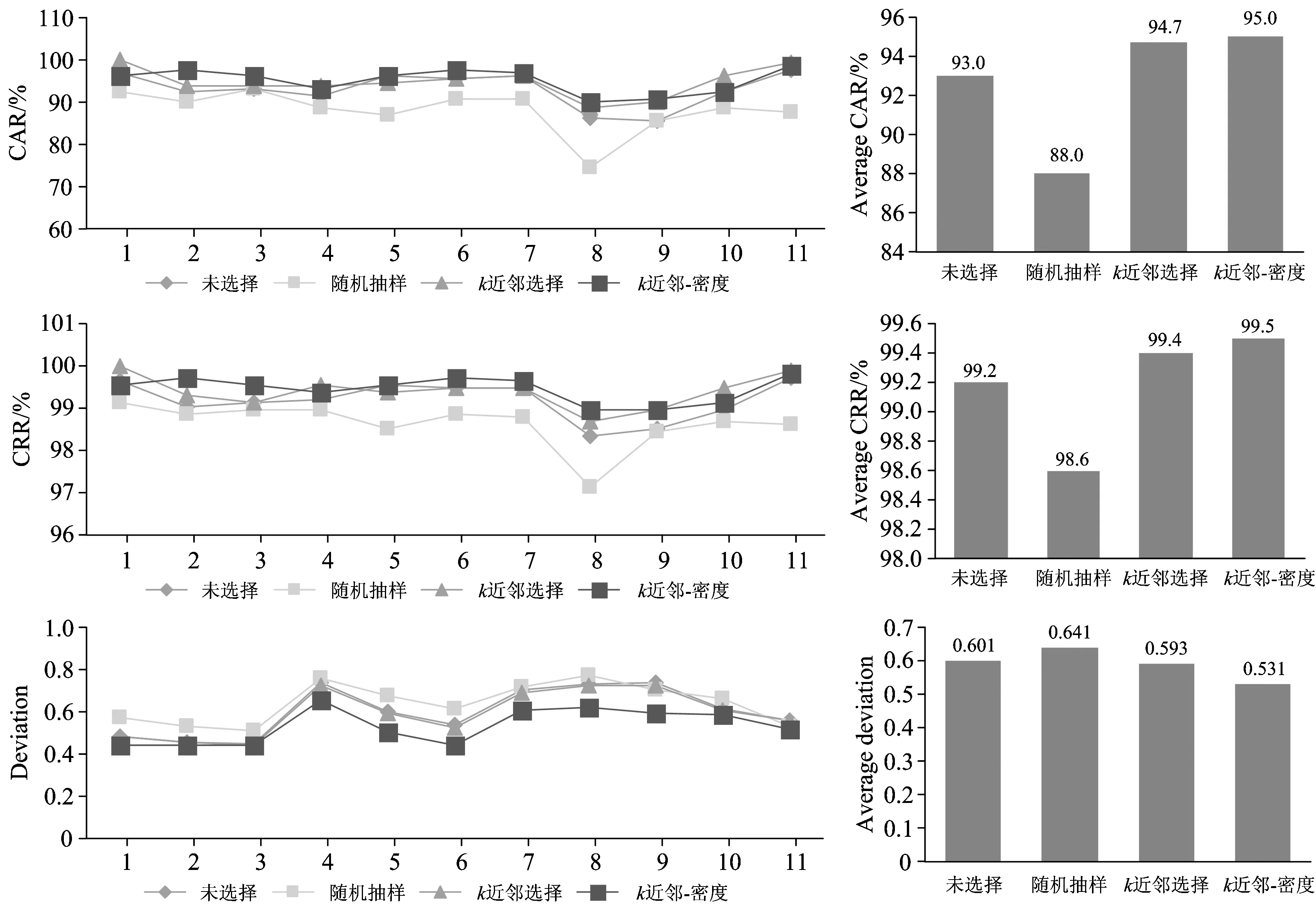
图7 BPRI建模结果统计

表2 不同样本选择方法选择后的样本数量
综合实验结果表明、以k近邻-密度作为样本选择方法所建立的模型识别效果明显优于随机抽样、略好于k近邻方法、但其建模样本量远少于k近邻所选择的样本。当建模样本品种较多时、该方法不仅能够有效光滑样本边缘而且能够在不影响样本覆盖的前提下删除冗余样本、从而保证了模型质量。
5 结 论
对于多品种的小麦种子漫反射近红外光谱、在对原始光谱进行平滑(SM)、一阶导(FD)、中心化(MC)预处理、偏最小二乘(PLS)和线性判别分析(LDA)特征提取后、分别以随机抽样、k近邻和k近邻-密度作为样本选择方法建立仿生模式识别和改进后的仿生模式识别两种模型、比较、模型平均识别率、平均拒识率和偏离度。实验结果表明、以k近邻-密度作为样本选择方法建立的仿生模式识别或改进后的仿生模式识别模型不仅能够大大降低建模数据量、而且保证模型质量不受损失、甚至略有提高、综合效果优于另外两种方法。
[1] YAN Yan-lu,ZHAO Long-lian,HAN Dong-hai,et al(严衍禄,赵龙莲,韩东海,等). Foundation and Application of Near-Infrared Spectroscopy Analysis(近红外光谱分析基础与应用). Beijing:China Light Industry Press(北京:中国轻工业出版社)、2005.
[2] LIU Xu-ping,HU Chang-qin,TIAN Ke-ren,et al(刘绪平,胡昌勤,田克仁,等). Chinese Journal of Pharmaceutical Analysis(药物分析杂志)、2010,30(7): 1340.
[3] ZHANG Qi-ke,DAI Lian-kui(张其可,戴连奎). Chinese Journal of Sensors and Actuators(传感技术学报),2006,19(4):1190.
[4] GAO Xue-jin,GENG Ling-xiao,XUE Pan-na,et al(高学金,耿凌霄,薛攀娜、等). Chinese Journal of Scientific Instrument(仪器仪表学报)、2015,36(2): 401.
[5] ZHU Shi-ping,WANG Yi-ming,ZHANG Xiao-chao,et al(祝诗平,王一鸣,张小超,等). Transactions of the Chinese Society for Agricultural Machinery(农业机械学报)、2004,35(4): 115.
[6] LIU Li,WANG Chun-zhi(刘 丽,王春枝). Software Guide(软件导刊),2008,7(7): 97.
[7] ZHANG Chun-yang,ZHOU Ji-en,QIAN Quan,et al(张春阳,周继恩,钱 权,等). Computer Science(计算机科学),2004,31(2): 127,141.
[8] ZHANG Li,GUO Jun(张 莉,郭 军). Journal of Beijing University of Posts and Telecommunications(北京邮电大学学报),2006,29(4): 77.
[9] WANG Shou-jue(王守觉). Acta Electronica Sinica(电子学报),2002,30(10): 1417.
[10] HU Zhi-qin(虎治勤). Computer Knowledge and Technology(电脑知识与技术),2011,7(27): 6711.
*Corresponding author
Study of Modeling Samples Selection Method Based on Near Infrared Spectrum
JIN Zhao-xi1,ZHANG Xiu-juan2,LUO Fu-yi2、AN Dong1,3*,ZHAO Sheng-yi1,RAN Hang1,YAN Yan-lu1
1. College of Information and Electrical Engineering,China Agricultural University,Beijing 100083,China 2. Dezhou Municipal Bureau of Agriculture,Dezhou 253016,China 3. Key Laboratory of Agricultural Information Acquisition Technology (Beijing),Ministry of Agriculture,Beijing 100083,China
For more wheat varieties classification problem,we use near infrared spectrumto do qualitative analysis. Increasing the size of modeling sample could increase information of the model,however,at the same time,it also makes information redundancy so that modeling time and storage space will increase,thus,we need to decrease the size of modeling sample though selecting them. Some information must be lost and the effects of the model must be worse if we select samples blindly. We put forward theknearest neighbor-density sample selection based on the traditional selection methods. Experiments use the near infrared diffuse reflection spectrum of wheat seed from lots of days. First,we use preprocessing and feature extraction to deal with the wheat original spectrum,then select modeling sample by three methods that are random sampling,knearest neighbor andknearest neighbor-density,finally,we establish the models of BPR(Biomimetic Pattern Recognition) and BPRI(Biomimetic Pattern Recognition Improved). The experimental results show that in the model of BPR we get the best results using the selection method ofknearest neighbor-density,especially it also decreases the size of modeling sample deeply,and in the model of BPRI the results using the selection method ofknearest neighbor-density are much better than random sampling and a little better thanknearest neighbor,but in the meanwhile the size of modeling sample using the selection method ofknearest neighbor-density are much smaller thanknearest neighbor. The experimental results prove that the sample selection method ofknearest neighbor-density can not only greatly reduce the modeling sample size,and ensure the quality of the model,it has obvious effect on varieties classification problem of wheat.
Wheat; Near infrared spectroscopy; Qualitative analysis; Modeling samples selection
Sep. 15,2015; accepted Jan. 23,2016)
2015-09-15、
2016-01-23
国家重大科学仪器设备开发专项 光栅型近红外分析仪及其共用模型开发和应用项目(2014YQ470377)、大北农青年学者研究计划项目(1081-2413001)、国家科技支撑计划项目(2014BAD23B00)和中央高校基本科研业务费专项资金项目(2015XD001)资助
靳召晰、女、1993年生、中国农业大学信息与电气工程学院硕士研究生 e-mail: jzx@cau.edu.cn *通讯联系人 e-mail: anclear@gmail.com; andong@semi.ac.cn
O657.33
A
10.3964/j.issn.1000-0593(2016)12-3920-06
