基于任务迁移和需求控制的云计算成组调度性能及代价评估
2016-05-31陈斌东一舟毛明荣
陈斌 东一舟 毛明荣


摘 要:对成组调度技术在云计算中的应用效果展开了研究,该效果体现在其性能和耗费代价的综合指标上。文章对该模式的研究是通过虚拟化以分析基于任务迁移和需求控制的成组调度性能和综合代价为手段,以基于Amazon弹性云计算架构(EC2)为实验背景进行效率评估实验以获取支撑数据。结果显示,该调度策略可以有效地部署于云环境,并且该云平台可以被真实的高性能计算环境或其它高性能领域所应用,具有较高的性能代价比。
关键词:云计算;成组调度;高性能计算;虚拟机
中图分类号:TP39 文献标识码:A 文章编号:2095-1302(2016)05-00-05
0 引 言
云计算指的是计算资源作为公共事业的一种模型,就像水和电力一样,用户可以按照其所需而获取计算资源。基础设施即服务(IaaS)和网格计算这样的既有模型不同,它对于提供给用户的软件或服务的类型没有任何限制。事实上,云提供了有效的应用基于已有的或定制的任何软件的能力。
云计算的重要性在于为小公司或组织在没有先前投资的情况下提供接入计算基础设施的机会。因此,所需要的资金投入总额可以被缩减为最小化的投入代价并减小了运行风险。
云计算可以被运用到高性能计算上这一结论已被证实。小的机构和个体科研组织现在可以接入大型计算资源,不仅可以通过带有限制的网格,还可以通过提供了虚拟无限资源为基础平台的云集群,这些集群在维护上只需要原有的部分代价,并且通过使用即付费的模式来运作。
任何分布式系统的核心都在于它的任务调度器,其作用在于向服务器或者虚拟机分配任务。通常,调度器的调度策略目标是达到更快的响应时间和更低的故障率,这是通过最小化冗余延迟来实现的[1]。
在我们的模型中,调度器必须以趋于最小时间花费的虚拟机目标策略来获得最佳的代价效率比。该建模系统实现了一个称为成组调度的并行任务调度的特殊实例,该实例中的任务必须同时执行及被调度,以满足其持续互相通信的要求。这就需要在任务和虚拟机之间建立一张点对点映射图[2],并且要避免由来源于另一个非运行任务作为任务输入等待条件所可能带来的瓶颈问题及其引起的死锁。
在分布式和集群系统领域,近些年成组调度已经被广泛研究。Karatza在其文献中提到了对适应性先来先服务(AFCFS)以及最大优先级任务先服务(LJFS)的性能研究[3]。与此同时他还研究了成组调度在输入输出调度和处理器失败情况下的应用研究[4]。Papazachos和Karatza研究了该成组调度在两个不同集群系统中的应用情况。先前提到的公共应用成组调度都是设计于预先安排好服务器总数量及单机范围任务大小的静态系统。
使用虚拟计算机作为处理单元的网格模型系统的弹性被Nie和Xu等人研究[5]。其发表的研究聚焦于没有执行期限的非并行任务和目标与当维持最小化失败率时的最大化利用率。
云计算平台的调度策略在之前已经被研究。Assuncao等人对通过云完成的扩展私有集群进行了研究[6]。Sotomayor等人使用模糊虚拟机管理架构对在并行任务批量调度虚拟机利用率问题上进行了研究。在这些模式中,任务并不需要交互操作,并且可以被独立的调度执行[7]。
我们研究了在动态提供虚拟机的分布式云计算系统中应用成组调度策略的方法和效用。我们利用了两个任务调度算法即之前提到的AFCFS和LJFS,并且控制虚拟多样化工作和多重任务规模的范围。评估结果同时对性能和代价效率调度算法有效。然而,我们先前的工作没有考虑任务的迁移以提高响应时间和减小任务分离,同样没有考虑到高负荷工作的适应算法,应用可能引起很多等不到执行机会的任务。在该新研究中,我们的模型中整合了迁移机制和需求控制系统,并且比较了这些方法的有效性,这些方法有着较好的综合性能和代价效率。之前的研究并没有考虑到成组调度在基于云计算架构的复杂模型中的应用。
1 系统及工作模式
虚拟建模开发包括动态虚拟机集群及其虚拟机调度器(DVM)。当系统初始化时,无需进行虚拟机租约的确定,虚拟机数量可以动态增加和缩减。
在虚拟机调度器有能力进行分布式并行任务调度的情况下每一个虚拟机将实现其自己的等待队列。虚拟机调度器同样有一个任务队列,它们既不能按照虚拟机不均匀到达时间进行调度也不能按照系统负载来进行调度。出于简单的目的,虚拟机调度器本身并不包括在虚拟机总数中。同样,任务迁移和需求控制机制由虚拟机控制器进行管理。
虚拟机间通信可以认为是自由竞争关系,然而任何潜在的通信都包含了任务执行时间。所以,我们必须要考虑到当任务调度器队列存在任务调度延误的情况。
除此之外,虚拟机被考虑在包括相同EC2的实例类中,并且因此具有完全相同的特性。虽然虚拟机可能具有不同的处理性能,就像非虚拟系统一样,研究表明,除却输入输出可能产生的影响,虚拟机可以提供近似相同的性能[8]。由于在我们的研究中没有考虑到输入输出情况,假设任何包括任务执行时间在内的影响性能的临时原因都是隐含被屏蔽的。
成组调度需要任务并行运作[9],因此每一个任务需要一系列等价于为执行需要而并行化的空闲虚拟机。在我们的模型中,并行化的程度是随机的,其符合离散均匀分布并可以归纳为以下两类:
(1)低并行化任务:任务的数量以q为概率维持在1至16个之间。
(2)高并行化任务:任务的数量以1-q为概率维持在17至32个之间。
q是决定了任务总数的任务数量并发系数,该系数可以属于第一类或第二类。
因此平均任务数量(AJS)可以按照式(1)计算得出:
这里,E代表的是离散均匀分布等量范围值。任务同时到达时间的意思是以1/λ为平均值的指数分布并且平均服务时间是以1/μ为平均值的指数分布。服务时间和任务数量之间没有关系,因此,一个低并行度任务可以拥有一个较长的服务时间。最终研究显示,成组调度的上下文切换需要较高代价,故任务并不会常以抢占的方式执行完成[10]。该系统的控制模型如图1所示。
图1 系统模型
2 调度迁移和需求控制策略
2.1 任务分发
图1所示的系统入口点是虚拟机调度器。任务并行化程度小于或等于时可用立即分发虚拟机。对于虚拟机任务的分布,虚拟机调度器应用最短队列优先算法,该算法向虚拟机分发任务按照最短队列原则进行。
2.2 任务调度
模型应用了两个常用的成组调度算法。不管是AFCFS还是LJFS都在集群计算领域有着一定程度的研究。服务调度原则如下:
(1)适应性先来先服务:AFCFS试图调度那些在其各自队列之前的任务,当每一次虚拟机变为空闲时,如果没有这个任务的存在,AFCFS将试图以最快降低队列长度的方式来调度任务。因为这种AFCFS调度方式趋于针对较小任务,这些任务更易于调度但会增加最大任务的等待时间。
(2)最大优先级任务先服务: LJFS调度方式提供了针对大任务的更优先的调度策略。在每一个调度周期内,LJFS都将尝试调度分布于空闲虚拟机中的最大优先级任务。该方法通过授权方式在很大程度上增加了大任务的响应时间。同样,由于大任务在调度过程中经常将大量虚拟机资源空余出来,相对于AFCFS,较小的任务在等待时间上将被缩减。
2.3 任务迁移
成组调度中有一个共性问题,即通常当等待任务被调出队列的过程中处理器总会处于空闲状态[11]。为了避免出现这种时间碎片,迁移的实施是必须的。迁移的处理包括了从虚拟机队列中的繁忙虚拟机中向可用空闲虚拟机上迁移切换任务。虽然该处理方式解决了前面提到的碎片问题,但其本身也给系统带来了大量的开销[12]。
本文设计的系统在考虑了应用任务迁移安全性的前提下减少了系统开销。具体做法是:只有在系统不能通过正常途径进行任务调度的情况下才允许任务迁移。当这种情况发生时,迁移系统尝试查找是否在任务队列中有适合于在当前空闲虚拟机中运行的任务。如果存在这样的任务,系统将使用以下两种策略中的一种来对任务进行迁移,具体选择哪种依赖于虚拟机的配置。这两种策略如下:
(1)首位适应:在合适的任务队列中,直接选择排在首位的任务。该方法实现简单,带来的平均开销少。
(2)最佳适应:选择最适合的任务,该任务对于空闲的虚拟机来说,具有最高等级的并行化适应性。该方法由于需要执行最佳任务适应算法,从而将带来较多的额外开销。
为了高效达到该迁移任务的目的,我们还引入了一个迁移监控机制用于减少总的迁移次数,该监控可以确保任务调度只发生在适配任务数小于指定数量的情况下。
当迁移处理结束后,迁移的任务将被调度到执行状态,并立刻在下一个时钟周期被执行。该处理方式可防止对同一任务的多次重复迁移,避免对系统产生更多负载开销。
2.4 需求控制
我们的系统中还设计有一个包含了队列优先权的专用子系统,该子系统的实现目的在于进行需求控制。当该队列包含了“需求控制”任务时,常规的任务调度和迁移会被暂停。当系统的膨胀系数Xfactor达到了设置的需求门限,则该任务会自动触发。膨胀系数的计算方法见式(2):
这里,IWTj和ej是实例等待时间,该时间的长短取决于各个实际执行任务j本身的运行时间。
对膨胀系数的选择在整个任务控制处理中起到了非常重要的作用。另外,在我们的模型中有需求的任务可能会发生迁移,并没有被上面提及的监控系统所绑定,因此需求控制系统也可能导致在所设置的膨胀系数满足的情况下形成任务迁移潮。
3 虚拟机控制策略
云向用户提供了其对计算资源按照实际请求虚拟机数量进行增容或减容的能力。该过程包括了一个延迟,该延迟由虚拟机管理者创建和设置新的虚拟机所需时间而产生。在每次请求中该延迟通常小于十分钟。在我们的虚拟模型中,该延迟是按照均值为0.1而设计的,满足U(0,0.4)的持续均匀分布的随机数。
3.1 虚拟机供给机制
一个复杂的子系统被实现用于从系统中添加和去除虚拟机。遇到以下条件之一时将发生虚拟机租借的情况:
(1)虚拟机不足。当一个任务包含了多个子任务,其总数超过了可用虚拟机数目,将会发生这种情况。该任务被排列在虚拟机管理器中直到新的虚拟机可以供给。
(2)虚拟机过载。在每一次分发中,系统都会检查虚拟机等待队列的状态,计算平均负载因子的公式见式(3)。
这里,Jk是虚拟机k中的当前等待任务数,Pk是系统当前已租借虚拟机数。
(3)
ALF总体而言要优于之前定义的负载门限,系统提供了一个虚拟机控制器能力等价于达到任务数的新虚拟机,其任务队列将处于等待状态直到新虚拟机可用为止。
出现上述两种情况的任一种,系统都不会去尝试申请租借更多的虚拟机。同样,当每一个提供的租借虚拟机被暂停,在第十个周期到达后将会由系统为新的虚拟机进行填补。
3.2 虚拟机释放机制
在当前环境下,当系统不再需要使用某些虚拟机时,可能会进行虚拟机的释放。该操作由于会影响系统的整体开销,所以特别重要。如何评价一个虚拟机是否满足可释放条件取决于以下三点:
(1)虚拟机是空闲的并且其等待队列也是空的;
(2)虚拟机管理器队列中没有等待重新调度的任务;
(3)没有正处于计划迁移激活态的任务。
若以上三点标准同时满足,我们就认为该虚拟机处于可释放状态。
4 性能与代价评估
该研究既集中于系统性能的评估,也关注代价的评估。
4.1 性能评价指标
以下指标都在性能评价中使用:
(1)响应时间RTk:表示了任务k的请求在到达与反馈之间的间隔时间。它的平均值可以定义如下:
这里N代表任务的总数。
(2)响应迟缓比Sk:其定义为Sk=RTk/ek,该指标显示了一个任务相对于其服务时间ek的延误容忍比度。由于该指标可以很容易被作为分母的数值很小的服务时间所影响,所以我们使用下述限制指标:
我们的实验里λ被设置为10-3。
(3)迁移总数目migtot:由于上述原因,我们使用有明确影响的迁移总数量以对系统综合性能的虚拟化进行评估。
4.2 代价评估
由于云的运作是有代价关联的,所以系统必须在响应时间和所需代价之间维持一个较好的平衡。因此,我们需要整合代价性能效率的指标,即虚拟机完全租赁时间(LT)和平均响应时间(RT)。
CPE=DLT+DRT
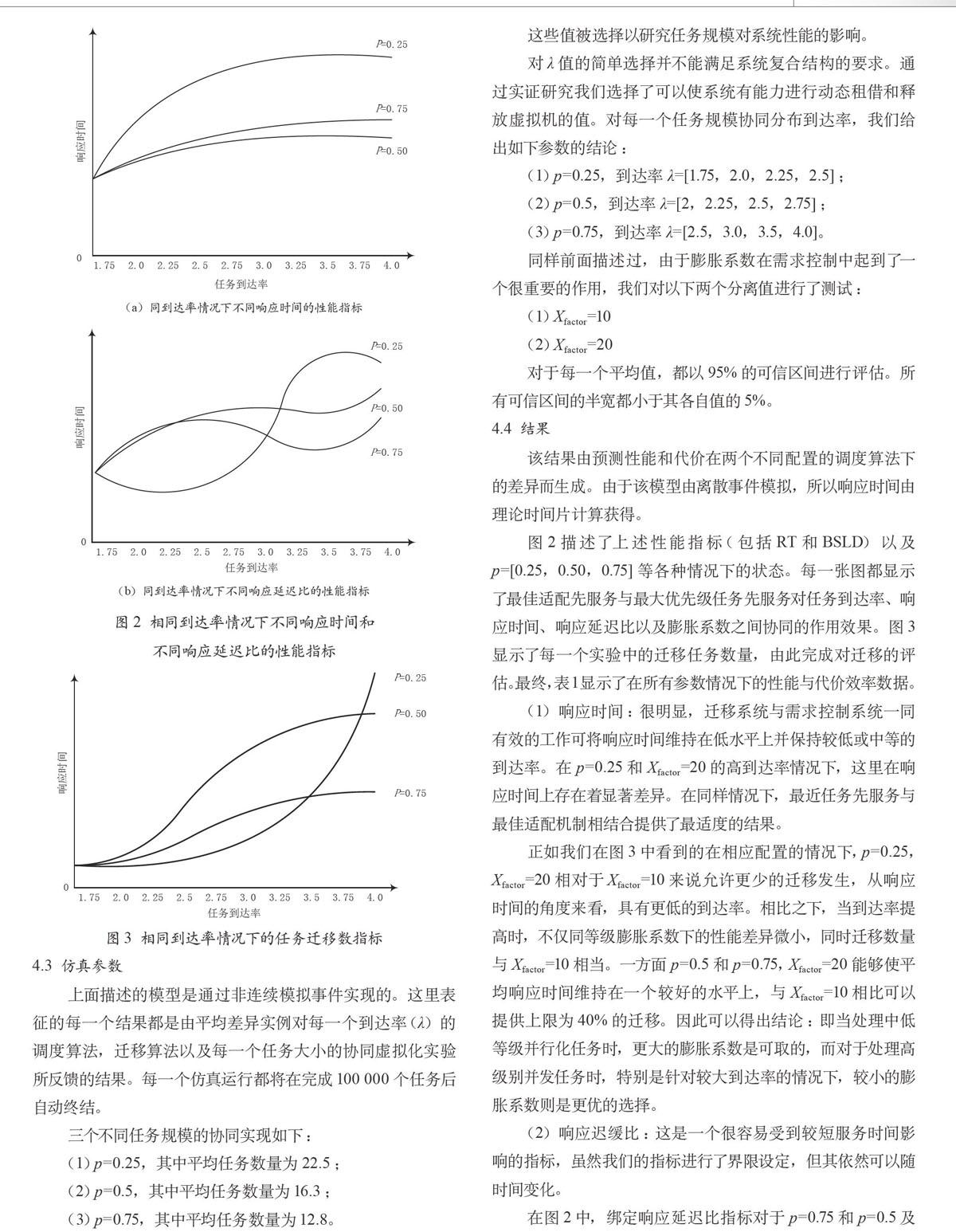
这里,DLT是LT和两个虚拟实验的相关差异,DRT是响应时间之间的相关差异。我们必须注意到,最佳适配先服务作为基础较最大任务先服务策略在CPE数据上具有负向效果,所以显示出最佳适配先服务作为基础较最大优先级任务先服务策略的优越性。图2所示是在相同到达率情况下不同响应时间和不同响应延迟比的性能指标图。图3所示是相同到达率情况下的任务迁移数指标。
(a)同到达率情况下不同响应时间的性能指标
(b) 同到达率情况下不同响应延迟比的性能指标
图2 相同到达率情况下不同响应时间和
不同响应延迟比的性能指标
图3 相同到达率情况下的任务迁移数指标
4.3 仿真参数
上面描述的模型是通过非连续模拟事件实现的。这里表征的每一个结果都是由平均差异实例对每一个到达率(λ)的调度算法,迁移算法以及每一个任务大小的协同虚拟化实验所反馈的结果。每一个仿真运行都将在完成100 000个任务后自动终结。
三个不同任务规模的协同实现如下:
(1)p=0.25,其中平均任务数量为22.5;
(2)p=0.5,其中平均任务数量为16.3;
(3)p=0.75,其中平均任务数量为12.8。
这些值被选择以研究任务规模对系统性能的影响。
对λ值的简单选择并不能满足系统复合结构的要求。通过实证研究我们选择了可以使系统有能力进行动态租借和释放虚拟机的值。对每一个任务规模协同分布到达率,我们给出如下参数的结论:
(1)p=0.25,到达率λ=[1.75,2.0,2.25,2.5];
(2)p=0.5,到达率λ=[2,2.25,2.5,2.75];
(3)p=0.75,到达率λ=[2.5,3.0,3.5,4.0]。
同样前面描述过,由于膨胀系数在需求控制中起到了一个很重要的作用,我们对以下两个分离值进行了测试:
(1)Xfactor=10
(2)Xfactor=20
对于每一个平均值,都以95%的可信区间进行评估。所有可信区间的半宽都小于其各自值的5%。
4.4 结果
该结果由预测性能和代价在两个不同配置的调度算法下的差异而生成。由于该模型由离散事件模拟,所以响应时间由理论时间片计算获得。
图2描述了上述性能指标(包括RT和BSLD)以及p=[0.25,0.50,0.75]等各种情况下的状态。每一张图都显示了最佳适配先服务与最大优先级任务先服务对任务到达率、响应时间、响应延迟比以及膨胀系数之间协同的作用效果。图3显示了每一个实验中的迁移任务数量,由此完成对迁移的评估。最终,表1显示了在所有参数情况下的性能与代价效率数据。
(1)响应时间:很明显,迁移系统与需求控制系统一同有效的工作可将响应时间维持在低水平上并保持较低或中等的到达率。在p=0.25和Xfactor=20的高到达率情况下,这里在响应时间上存在着显著差异。在同样情况下,最近任务先服务与最佳适配机制相结合提供了最适度的结果。
正如我们在图3中看到的在相应配置的情况下,p=0.25,Xfactor=20相对于Xfactor=10来说允许更少的迁移发生,从响应时间的角度来看,具有更低的到达率。相比之下,当到达率提高时,不仅同等级膨胀系数下的性能差异微小,同时迁移数量与Xfactor=10相当。一方面p=0.5和p=0.75,Xfactor=20能够使平均响应时间维持在一个较好的水平上,与Xfactor=10相比可以提供上限为40%的迁移。因此可以得出结论:即当处理中低等级并行化任务时,更大的膨胀系数是可取的,而对于处理高级别并发任务时,特别是针对较大到达率的情况下,较小的膨胀系数则是更优的选择。
(2)响应迟缓比:这是一个很容易受到较短服务时间影响的指标,虽然我们的指标进行了界限设定,但其依然可以随时间变化。
在图2中,绑定响应延迟比指标对于p=0.75和p=0.5及一些异常值的情况下显示了一个持续稳定的行为结果。这些结果显示,响应延迟发生在迁移算法和需求控制介于中低等级的并发任务规模的协同程度处于可控制水平的情况下。对于p=0.25,相对结果显示在响应延迟比上则会与预期结果有较大的不一致。这可以归于迁移和需求控制方法在时间上以短服务时间划分任务以至在等待队列里以相对于期望的立即影响的响应延迟比需要更长的周期。
(3)代价与性能效率:在我们之前的工作中,是没有包括迁移和需求控制的,因此得到的结论是对于所有任务在较高到达率情况下,最大优先级任务先服务与适应性先来先服务相比有着更高的代价效率。表1显示了这些在迁移和需求控制起作用的情况下基本消失的差异。不同的任务规模效应和扩展因素看起来有着较小的影响,同时,当使用负值对适应性先来先服务进行描述的话,差异实际可以忽略不计。
表1 代价和性能效率表
λ 先来先服务(10) 最佳适应先服务(10) 先来先服务(20) 最佳适应先服务(20)
p=0.25
1.75 -0.016 32 0.012 79 -0.058 01 -0.051 02
2.50 -0.056 49 -0.029 13 0.015 14 -0.029 27
3.25 -0.061 12 -0.033 13 -0.137 15 -0.203 18
4.00 -0.041 45 -0.042 13 -0.025 31 -0.051 99
p=0.50
1.75 -0.012 07 -0.002 80 0.004 13 -0.038 12
2.50 -0.041 32 0.008 77 -0.042 32 -0.045 41
3.25 -0.057 69 0.007 49 -0.018 32 -0.076 81
4.00 -0.061 42 -0.021 93 -0.121 47 -0.048 02
p=0.75
1.75 -0.031 58 -0.033 11 -0.006 91 -0.031 85
2.50 -0.048 15 -0.021 88 -0.051 01 -0.079 03
3.25 -0.021 10 -0.018 98 -0.066 13 -0.035 73
4.00 -0.027 41 -0.047 26 -0.088 01 -0.075 15
5 结 语
本研究将任务迁移和需求控制两个重要的概念整合入模型中。结果模型被通过多负载多任务规模的成组调度,迁移和需求控制集成的虚拟器进行测试。多种指标都被应用以对满配置情况下的性能和系统代价进行评估。
迁移和需求控制的应用对实验模型有很深刻的影响。虽然迁移平衡了响应时间的差异,它们的总数量在系统性能问题上扮演了一个非常重要的角色,同时它们提供了一个新的比较基准。另外膨胀系数的差异提供了更好的调整机制以在不同的环境下获得更好的结果。
在将来,我们希望对新的工作负载模型进行测试,以与云计算更好地进行适配。同样对该机制在系统中各式各样的应用,如果任何属于实时云系统的结论被提出,性能因素都应该进行深入的研究。
参考文献
[1] Z. C. Papazachos,H. D. Karatza.The impact of task service time variability on gang scheduling performance in a two-cluster system.Simul[J].Modell.Pract.Theory, 2009,17(7):1276-1289.
[2] Y. Zhang, H. Franke, J. Moreira,et al.An integrated approach to parallel scheduling using gang-scheduling, backfilling, and migration[J]. Dept. of Electr. & Comput. Eng.,State Univ.of New Jersey,Piscataway,NJ, USA.IEEE Transactions on Parallel and Distributed Systems,2003, 14(3):236-247.
[3] Y.Wiseman,D.G.Feitelson.Paired gang scheduling[J].IEEE Trans. Parallel Distrib. Syst.,2003,14(6):581-592.
[4] A. M. Law.Simulation Modeling and Analysis[Z].4th ed. McGraw-Hill Higher Education, 2007.
[5] D. G. Feitelson.Metrics for parallel job scheduling and their convergence[Z].in Revis. Pap. from the 7th Int. Worksh. on Job Sched. Strateg. for Parallel Process., ser. JSSPP 01. London, UK: Springer-Verlag, 2001:188-206.
[6] M. Guazzone, C. Anglano, M. Canonico.Energy-Efficient Resource Management for Cloud Computing Infrastructures[Z].presented at the Cloud Computing Technology and Science (CloudCom),IEEE 3rd Int. Conf., 2011:424-431.
[7] F.R.Dogar,P.Steenkiste,K.Papagiannaki.Catnap: Exploiting high bandwidth wireless interfaces to save energy for mobile devices[Z].in Proc.ACM MobiSys10,San Francisco, California, 2010:107-122.
[8] N. Vallina-Rodriguez,J.Crowcroft.ErdOS: achieving energy savings in mobile OS[Z].in Proceedings of the sixth international workshop on MobiArch, ser. MobiArch 11. New York, NY, USA: ACM, 2011:37-42.
[9] 刘亮,向碧群,桂晓菁.基于云计算的多污染区域综合检测系统设计[J].计算机测量与控制,2012,20(8):2089-2091.
[10] 张潇丹,李俊.一种基于云服务模式的网络测量与分析架构[J]. 计算机应用研究,2012,29(2):725-729.
[11] G. Wang,T.S.E. Ng.The Impact of Virtualization on Network Performance of Amazon EC2 Data Center[Z].Proceedings of IEEE INFOCOM, 2010:1-9.
[12] V. Chang, G. Wills, D. De Roure.A Review of Cloud Business Models and Sustainability[Z].IEEE 3rd International Conference on Cloud Computing, 2010: 43-50.
