基于手机LBS位置服务的社交网络分析
2016-05-30马强付艳茹
马强 付艳茹

摘 要: 基于手机LBS定位方法对以犯罪嫌疑人为对象的社交网络进行挖掘,通过提取手机数据和基站数据建立数据字典,提出了一个LBS位置服务数据挖掘算法,关联分析了社交行为、社交网络和犯罪线索的潜在关系,并以实例形式给出了基于Python机器学习功能的实现过程。
关键词: 手机; 定位; Python; 社交网络; 位置服务; 关联
中图分类号: TP 393.08 文献标志码: A 文章编号: 1671-2153(2016)04-0092-05
0 引 言
随着LBS(location based service)手机定位方法增值的位置服务,手机已不再局限于双方通讯的功能,而是由手机社交网络集合了多方的社交行为(如指示服务场所、访问网络、商务活动、电子支付等)。手机实名制及手机LBS定位功能有助于在社交网络中分析一般用户的社交行为和发现特定人为犯罪嫌疑人的线索,而不局限于以往单纯的用户一方手机话单数据的分析。如果基于LBS的位置服务对手机数据和基站数据进行关联分析,则可能从犯罪嫌疑人的社交行为中挖掘出社交网络,并可利用Python的机器学习功能进行演绎,形成多角度获取线索和证据的解决方案。
1 手机话单数据分析的不足
传统上获取犯罪嫌疑人犯罪线索的手段多从分析手机话单数据入手[1]-[3]。但手机话单数据分析存在一定不足:一是为得到更多的线索,往往需要由通话轨迹来分析犯罪嫌疑人的社交网络,试图通过关联的人脉关系发现新线索,但由合法手机用户转变为犯罪嫌疑人是相对渐进的过程,其中手机用户会基于不同的目的产生双方通讯,通话持续的时间也可能不尽相同,一般手机用户个体之间的通话持续时间少于1 min的占61%,通话持续时间超过15 min的占11%,平均的通话持续时间在1 min51s[4]。考查数据的关联性,这种通话时长只是以权重的方式反映通讯的频度而已,而在暴露社交网络方面则是不充分的。二是手机话单数据分析的前提是获取的手机号码与身份识别相一致,而现实之中因遗失、改号、盗用、借用等原因手机使用者身份丧失排他性。三是手机话单数据无关乎内容,线索跟踪只限于手机通话或短信行为的有无,而实际更多的是通信背后以手机上网数据相关联的碎片化社交信息。四是通话记录和短信记录可能被手机用户直接删除,甚至手机数据被全部清除,导致通话轨迹陡变而失去数据关联分析的意义。
2 改进手机数据分析的基本设想
改进前述不足的方法之一是将手机数据分析的范围从话单延展到手机社交网络,即从该网络节点及边的关系入手,分析移动状态下犯罪嫌疑人由手机完成的社交行为。虽然受手机数据涉及个人隐私的法律限制,还不能类似固定网络以IP地址确定使用者位置的普遍方法来定位任意用户和获取手机数据,但在侦办手机用户涉嫌犯罪的特定条件下,获取手机数据以及分析相应的社交行为具有强制性。分析的方法既可基于时间也可基于内容,前者可通过判断社交网络每个时间片是否存在变化点来确定社交行为的发生[5],而后者可通过手机定位中位置服务内容是否存在变化来确定社交行为的发生。本文即基于LBS定位的位置服务将手机数据延展到基站数据,即将手机话单数据和手机社交网络数据综合进行分析。
LBS定位用户手机的最大优势是在定位不受天气和位置影响的前提下而实现了基站与用户之间的数据交换,其增值的位置服务仅仅借助了至少3个移动通信基站的信号差异。基站是一种移动通信无线电台形式,其功能是在以无线电覆盖一定区域范围内,通过移动通信交换中心,与用户移动电话终端之间进行双向收与发的无线信息传递。当基站数量充足的时候,LBS定位精度50 m以内的概率可达到67%,定位精度150 m以内的概率可达到95%,响应速度可达到小于3 s,虽然这和至少需要4颗卫星提供经度和纬度坐标信号定位手机的GPS(global positioning system)技术指标不相上下,但在形成手机社交网络的位置服务方面更具应用优势。
一般嫌疑人在案前与案后的具体时间和空间位置上,通过手机完成的社交行为都必然会表现为不同的注意力投放,包括浏览于阅读、搜索、购物、交友、游戏、音乐、论坛、软件等网络栏目内容,当基站地理位置和浏览的网络内容具有一定的关联模式时,就可借助基站与手机之间的数据交换,由犯罪嫌疑人的社交网络分析其社交行为,再关联于潜在的犯罪线索。
3 系统设计方案
为了建立前述关联模式,设定手机社交网络是由有限的集合或集合中的元素及其相互关系组成,一般可用有向图G=(V, E)相应表示,其中V为节点集,E为边集,网络节点vi∈V表示某个人,边ej∈E表示不同网络节点间的相互关系。
考虑到在LBS位置服务中关注的是手机用户使用网络资源服务的内容,它需要在社交网络中由边集E来区分节点集V中节点间关系类型,以及需要表达两个相邻节点vi和vj之间的关系,故可相应提取手机数据和基站数据,将其写成对应的数据字典。
3.1 基站数据提取
以LBS位置服务来定位手机需要获取基站的服务小区和邻近服务小区的相关信息。基站数据主要包括了国家、运营商、位置区LAC、服务小区CELL、纬度、经度、纠偏纬度、纠偏经度、覆盖范围、URL访问地址等10类字段。它同移动电话终端的手机用户数据有所不同,后者包含了用户编码、网络制式、位置区、基站经度、基站纬度、业务名称、业务入口名称、开始时间、上行包数、下行包数、上行流量、下行流量、网站名称、网站频道、应用体系标识、分类体系标识、内容分类标识、URL访问地址等8类共计几十个字段,且以CSV格式存储。
手机平台的不同,调用手机协议栈函数也不同。以Android平台为例,位置服务信息应包含下列数据:标识基站服务小区的ID 号CELLID、识别手机客户所属移动网络的代码MNC、标识移动网络所属国家的代码MCC、标识不同位置区的代码LAC、接收手机信号强度的指示值RSSI。
3.2 建立数据字典
3.2.1 手机数据
对手机部分的数据建立以CSV格式存储的文本文件类型的数据字典。在不同的手机平台下,一个完整的CSV数据字典可以包含用户编码、网络制式、位置区、基站经度、基站纬度、业务名称、业务入口名称、开始时间、上行包数、下行包数、上行流量、下行流量、网站名称、网站频道、应用体系标识、分类体系标识、内容分类标识、URL访问地址等8类几十个字段,但考虑到由社交网络判定用户行为的实际应用,仅选取手机用户编码ID为Key项,对应的Values为时间、地理位置、业务类型等3个关键字段,即可经Python编程计算出节点的中心度,并生成标定数据流动的社交网络布局图。例如,假设ID为'49515218'的手机用户在一段时间内采用手机移动方式2次连接互联网和访问社交网站若干栏目,则保存在数据字典中的手机数据记录一部分的格式为
20151208114236,39.756781_116.626031,“社交”
20151208114253,39.756781_116.626031,“社交”
3.2.2 基站数据
对基站部分的数据可采集为基站服务小区ID 号CELLID、移动网络代码MNC、国家代码MCC、位置区代码LAC、信号强度指示值RSSI、服务分类标识、Sink端和Source端的流量标识等字段。考虑到由社交网络判定用户行为的实际应用,只需要手机用户编码ID对应的服务标识和相应的流量即可满足社交网络的定位要求。例如,对于ID为'49545217'的手机用户,可依LBS定位需要至少三个基站服务小区的信息,其基站服务小区的记录格式可依次表示为
5023,TD-SCDMA,15302,120.7364,28.8539,
10104,0
5716,TD-SCDMA,15671,120.7231,28.8514,
10088,0
49961,TD-SCDMA,19196,121.4153,28.62478,
10104,0
接下来再考虑位置服务的内容。假设ID为'49545217'的手机用户于同一地点2次连接互联网,而且访问了社交网站的浏览、视频2个栏目,使用了1次百度搜索,使用的流量分别是22481、25446、26276个kB,则当不考虑标识符时,基站数据记录格式可表示为
20151208114236,39.756781_116.626031,
22481,“浏览”
20151208114253,39.756781_116.626031,
25446,“视频”
20151208114253,39.756781_116.626031,
26276,“搜索”
3.3 LBS位置服务挖掘算法
在完成数据字典的基础上,建立如下LBS位置服务挖掘算法:
步骤1:编程调用手机协议栈函数,以网络节点vi∈V为信标节点,获取3组至6组所处基站的服务小区和邻近服务小区的CELLID,MNC,MCC,LAC,RSSI值;
步骤2:通过手机的 HTTP协议,将步骤1的vi∈V位置服务小区信息传输到Google Gelocation Server中,以获取vi相对应的服务小区经度与纬度;
步骤3:对于基站由信标节点vi测定出的手机接收信号强度RSSI值,计算vi对应的自由空间损耗LBF的数值。对于所有vi∈V测定的发射功率PT,接收天线增益GR,发射天线增益GT,电缆与电缆线头之间的衰耗LC,则由公式RSSI=PT+GR+GT-LC-LBF按信号强度计算自由空间的损耗LBF;
步骤4:采用LBF=32.5+20lgF+20lgD的无线电传播路径损耗公式,按一定的频率F,对所有vi∈V,将自由空间损耗LBF转化为计算相对应的距离D;
步骤5:在前述3~6组的基站服务小区和邻近服务小区的坐标信息和距离中,以至少选取的3个信标节点vi为圆心,信标节点vi到未知节点vj为半径作3个圆,经双精度转换处理后,再由联立方程求出内侧3个交点x,y,z及三角形质心Ox,y,z,以此定位手机的当前位置。
步骤6:由手机移动用户所处基站地理位置信息和服务的流入量生成该手机用户的CSV词典,由Python的Networkx软件包创建手机在不同时间和空间位置上的数据流动网络;
步骤7:由数据流动网络生成转移矩阵M,对手机用户在不同时间和空间位置的注意力投放介入人工解释,得到社交网络的数据展示。
4 结果与分析
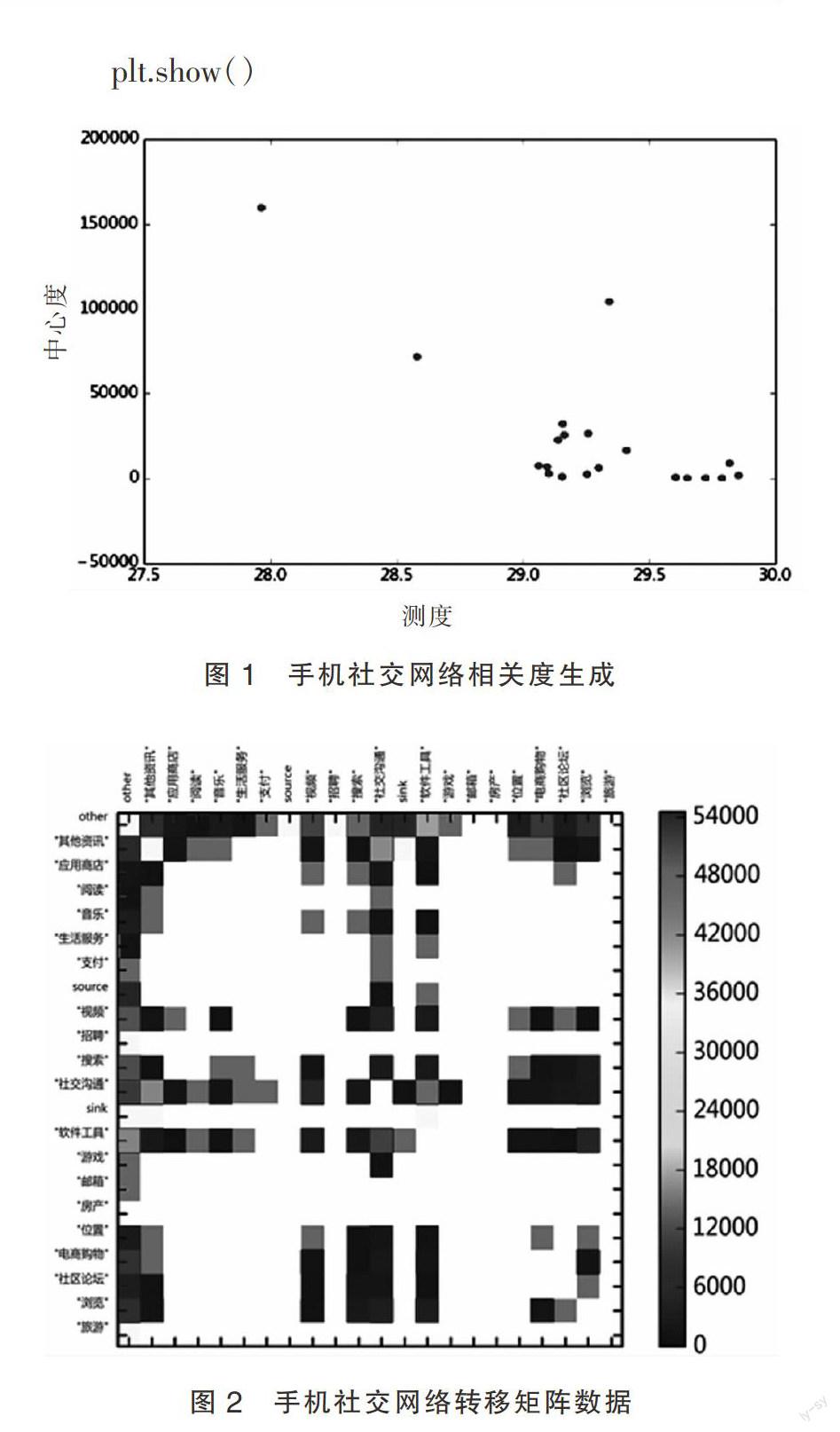
为验证位置服务挖掘算法的有效性,在手机社交网络G=(V,E)中,任意选取一个基站标定ID为'49515218'的手机用户,再在基站和手机两端建立数据字典my.txt,然后从基站数据的Source端和Sink端提取手机社交网络中指定的手机号码的位置服务数据流入量(如表1所示),继而由Python语言编程生成网络相关度和转移矩阵数据图,再分析手机社交网络特性。
为了编程预处理数据字典和数据流入量,先在Python语言中选取加载Networkx软件包[6]。由于Networkx软件包内置了数据图与复杂网络分析算法,便于仿真建模分析手机社交网络中的复杂网络,故可基于NetworkX软件包进行编程将手机社交的有向网络G=(V,E)转化为无向网络,将网络节点视为信标节点。计算信标节点测度与生成测度分布序列,包括一个信标节点vi到网络中所有的其他信标节点vj(i≠j)之间的距离、节点离心度、中心度以及手机社交网络G=(V,E)的密度分布,即社交网络G中实际存在的信标节点链接数量■ei和给定节点数量■vi与链接数量■ei之间比值,并由Python编程生成手机位置服务的可视化数据统计图。
下列是采用Python代码按上述LBS位置服务算法实现的部分可视化数据统计图,包括社交网络相关度生成图(图1)及转移矩阵M数据图(图2):
import networkx as nx
import matplotlib.pyplot as plt
G=nx.DiGraph()
with open('e://my.txt', 'r') as h:
for i in h:
x,y,w = i.strip().split(',')
G.add_edge(x.decode('utf-8'),y.decode('utf-8'),weight=int(w))
alpha = G.nodes()
alpha[0] = 'other'
A = nx.to_numpy_matrix(G)
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(A, interpolation='none')
ax.set_xticks(range(22))
ax.set_yticks(range(22))
ax.set_xticklabels(alpha,rotation=90, fontsize=8,verticalalignment='bottom')
ax.set_yticklabels(alpha,rotation=0, fontsize=8,verticalalignment='bottom')
fig.colorbar(cax)
plt.savefig('e://matrix.bmp', dpi =600)
plt.show()
在手机社交网络相关度生成的数据图(图1)中,横轴表示的是信标链接节点的测度(即服务流入量数据的距离);纵轴表示的是信标节点的中心度(即服务流入量数据的重要性)。可以发现,除去Source端和Sink端外,ID为'49515218'的手机用户在手机位置服务中表现的信标节点链接数量集中在测度为29.0到30.0之间的序列区间内,中心度主要相应集中在0~5000的范围内,除去3个较高中心度且分布稀疏的网络节点vi、vj、vk以外,其他相应的信标节点数量达到了17个,即vs(s=1,…,17且s≠i,j,k),只有很少的通话行为和上网行为分布在28.0~28.5的测度区间内。虽然这3个信标节点vi、vj、vk的中心度达到了55 000~155 000的较高值,但其网络密度分布不均衡,其信标节点在位置网络中的离心度较高,而信标节点的数量则偏少。
为进一步区分手机社交行为有位置服务网络中的流动情况,将上述二个数据图与数据字典my.txt和源自基站数据的Source端和Sink端及位置服务的数据流入量相结合,由生成的网络转移矩阵对手机用户的网络行为及潜在的社交网络进行解释。由图2可知,转移矩阵数据图基本上是对称的,元素的稀疏或密集代表了使用不同服务之间的注意力流动,以及不同社交行为的聚集。即相对偏少的3个信标节点vi、vj、vk说明ID为'49515218'的手机用户相应的通话联系或上网行为可能是偶发的,而在另外的17个信标节点vs(s=1,…,17且s≠i,j,k)中,手机位置服务中的产生“搜索”和“网上购物”二类数据流量的节点距离很近,“浏览”、“阅读”、“资讯”三类数据流量的需求比例较相近,“音乐”、“视频”二类数据流量的节点距离近,产生“游戏”、“旅游”、“房产”、“邮箱”、“支付”五类数据流量的需求比例较小,但信标节点间的位置距离较远。
依据数据分析结果,如果是对特定的犯罪嫌疑人,则可获得在使用手机LBS位置服务建立的手机社交网络G中,其社交行为的注意力流动倾向依次排序为:访问社交网站、网上购物、查阅社会资讯、网上娱乐等,由此可判定个人的日常喜好、社交行为方式、性格倾向等。为缩小目标范围,可在前述数据分析基础上,对手机社交网络G纵深挖掘,即对任意一条边ei∈E附加时间权重或语境内容权重的选项,再次进行深度数据分析。在此基础上,对以上手机社交行介入人工解释,依照手机社交网络G=(V,E)展现的符合阈值要求的网络关联度,将不同ID的手机用户按照LBS位置服务内容挖掘算法类似处理的结果进行串并,并结合上网行为与手机话单进行分析,再将手机社交行为与可疑号码的通话时间、通话次数、通话圈、通话频率等通话轨迹数据进行匹配,以获取与之关联的人脉关系,并发现可疑线索和关联证据。
5 结束语
LBS定位手机一个最大的低成本优势是在显示服务场所方面只与数据点的采集与更新有关,不涉及地图数据的采集与更新,这在包月流量计价渐入常态的今天,会驱动用户不自主地选择LBS定位方式。而“服务场所”恰恰是挖掘犯罪嫌疑人社交网络的核心与焦点,这将在执法领域有更为普遍的应用。
参考文献:
[1] 马李芬. 电话信息在案件侦查中的运用[J]. 社科纵横,2010,25(12):71-74.
[2] 斯进. 手机话单分析信息碰撞技战法的应用研究[J]. 信息网络安全,2011(7):63-68.
[3] 王彦学. 基于人、机到案层面的手机数据收集与研判[J]. 警察技术,2015(2):38-41.
[4] Lugano G. Mobile Social Networking in Theory and Practice[J]. First Monday,2008,13(11):15-20.
[5] 施伟,刘慧君,傅鹤岗,等. 基于手机数据的社交网络构建[J]. 计算机工程,2013,39(5):101-105.
[6] Aric A. Hagberg,Daniel A. Schult and Pieter J. Swart.Exploring network structure,dynamics,and function using NetworkX[C]//Proceedings of the 7th Python in Science Conference(SciPy2008),Pasadena,CA USA,2008:11-15.
Abstract: The approach concerns mainly a series of works: the analysis of data mining for the social networks to criminal suspects based on LBS, the establishing data dictionary by extracting phone data and base station data, the proposing of a data mining algorithm on LBS, the analysis of the prospective relationship between social behavior, social networks and crime clue. Finally, an example was given about implementation process of machine learning based on Python.
Keywords: phones; positioning; python; social networks; LBS; association
(责任编辑:徐兴华)
