人脸识别服务云计算化技术方案分析
2016-05-28刘晓玲陈云海林立宇张萍铁兵
[刘晓玲 陈云海 林立宇 张萍 铁兵]
人脸识别服务云计算化技术方案分析
[刘晓玲 陈云海 林立宇 张萍 铁兵]
摘要随着云计算技术的发展与普及,人脸识别技术及其应用也必然朝着云计算技术方向演进。文章从人脸识别技术与云计算分布式技术结合的角度出发,探讨人脸识别技术进行分布式存储与计算的可行性;主要介绍人脸识别的主要流程及相关技术,对相关技术进行分布式计算可行性分析,并最终提出一个基于Hadoop的人脸识别服务的云计算技术方案。
关键词:人脸识别 云计算 分布式计算
刘晓玲
女,2007年硕士毕业于中山大学,现就职于中国电信股份有限公司广东研究院,研究方向:视频编解码算法、视频云转码,云计算。
陈云海
男,本科,中国电信股份有限公司广东研究院,工程师,研究院产品委员会委员,已发表论文十余篇,主要研究方向:视频编解码算法、互联网应用、虚拟化、云计算、自然语言处理、知识管理及应用。
林立宇
男,2005年硕士毕业于中山大学,现就职于中国电信股份有限公司广东研究院云计算研究所,主要从事云计算、互联网应用、移动互联网应用、视频转码等方面的研究工作。
张萍
女,硕士,中国电信股份有限公司广东研究院,工程师,研究方向:视频编解码算法、互联网应用、云计算。
铁兵
男,本科,现就职于中国电信股份有限公司广东研究院,经济师,主要研究方向为企业竞争战略、移动互联网、电子商务、行业信息化。
随着云计算技术的发展与普及,互联网应用朝着云计算的方向发展是一个必然趋势。越来越多的人工智能技术也在朝着云计算化方向演进。本文从人脸识别技术与云计算分布式技术结合的角度出发,探讨人脸识别技术进行分布式存储与计算的可行性,实现人脸识别服务的云计算化。云计算分布式技术可以简单分为分布式存储和分布式计算两个方面。在分布式存储方面,人脸识别应用涉及到海量的数据,包括在模型训练所需的样本数据、识别阶段用到的数据等等,都可直接采取分布式存储技术进行存储。而在分布式计算方面,由于云计算分布式计算框架对计算有一定的要求,在人脸识别技术中采用分布式计算,则相比分布式存储要复杂得多。
云计算分布式计算框架对计算具有一定的要求[2]:可用于分布式处理的计算必须满足计算与计算之间的无相关性。人脸识别采用的许多机器学习的方法,往往比较复杂,常常会涉及到递进式的计算、或计算与计算之间的层层迭代。因此,将人脸识别技术应用于云计算的分布式计算框架,关键在于如何提取出人脸识别技术中的非相关的计算部分,用于云计算化的分布式处理。下文将进行人脸识别的主要流程介绍,并对相关技术进行分布式计算可行性分析,并最终提出一个基于Hadoop的人脸识别服务的云计算技术方案。
1 人脸识别流程及相关技术
人脸识别流程一般包括分类器等模型的训练过程和识别过程。在训练和识别过程,均需对数据进行预处理和特征提取。对数据样本的预处理包括图像大小、图像灰度化与图像的灰度均衡化等处理。对数据样本的预处理过程都是数据样本之间不相关的,可以直接交给云计算分布式平台处理。
在训练阶段,主要工作是基于已提取的特征进行分析和挖掘,以构造分类器或其它的数学模型。在识别阶段,基于分类器的人脸识别,只需提取待识别的样本特征,再通过分类器进行识别即可。基于其它数学模型,其识别过程与模型的形式相关,常通过计算矢量距离等距离度量方法来进行识别。基于矢量距离计算方法的识别过程,须计算待识别图像的特征向量与样本库的特征向量之间的欧式距离,从中选择最小距离作为匹配对象。
特征提取、分类器等模型训练及识别是人脸识别技术的最重要环节,涉及到多种不同方法,其适用于分布式计算的程度也各不相同。下文将从这三个环节进一步探讨其云计算化的可行性。
2 特征提取的云计算化
特征提取是人脸识别的重要环节。如何提取稳定、可靠的特征,使得其尽可能少受到光照、角度、遮挡物的影响,直接关系到分类及识别的质量。目前,人脸识别的特征提取算法可以分为基于全局特征和基于局部特征的两大类[2]:
基于全局特征的常用特征提取算法包括:PCA(主成分分析),LDA(线性判别鉴定)。
基于局部特征的常用特征提取算法包括:LBP(局部二值模式)、Gabor小波、HOG(梯度直方图)等。
主成分分析(Principal Component Analysis,PCA)或者主元分析。主成份分析是在基于统计学上对事物特征的统计,通过降维的方式,把多指标转换成少数综合指标。为了尽可能地保持数据的原始属性,因此PCA降维时须使得降低维度的数据间的方差最小。PCA的计算过程包括求样本均值,求解协方差矩阵,求协方差矩阵的特征向量和特征值,降维。其中,求样本均值、求解协方差矩阵都是数据块之间的无相关的计算,可以容易地移植到分布式框架map reduce中实现。在最近推出的云计算框架SPARK[5]中,已明确指出在其MLlib API中已经提供PCA方法。
Linear Discriminant Analysis(线性判别分析),它的基本思想是将高位的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,它所要确保的是投影后的模式样本在新的子空间上有最大的类间距离和最小的类内距离,从而在可分类性上达到最佳的效果。在具体的实现过程中,为保证最大类间距离和最小类内距离,同样需要矩阵的特征值和特征值向量的计算。对称矩阵的特征值、特征向量的计算,虽然也存在并发的解决方案(例如基于MPI计算模型的方法),但是由于该算法中用到的矩阵是涉及所有训练样本得到的大矩阵,基于分布式架构处理可能带来数据吞吐量方面的限制,因此需要进一步权衡。
基于全局特征的算法,在特征提取过程中是整个训练集的一起进行的,因此只能通过对其计算内部的一些环节,例如求样本均值、求解协方差矩阵等进行分布式处理。
基于局部特征的算法,样本与样本之间的特征提取是不相关的,因此基于局部特征的算法,包括LBP特征、Gabor小波、HOG(梯度直方图),都是可以直接基于样本维度在云计算分布式架构中进行并发处理。
3 分类器训练的云计算化
在特征提取的基础上,对数据进一步分析挖掘,通过多次训练构造分类器等数学模型。在分类器等模型设计上,主要存在以下几种常用的方法:Adaboost、HMM(隐马科夫模型)、神经网络、SVM等[2][3]。
Adaboost是一种迭代分类器,通过多个弱分类器级联成一个强分类器。每一次迭代获得一个弱分类器后,会根据当前的分类结果调整样本的权值,使得下一个分类器更加重视那些分类错误的样本,同时更加轻视那些分类正确的样本。多次迭代,直到分类效果满足要求为止。显然,这样的迭代过程具有计算相关性,无法直接进行分布式计算方式改造。但是,在每次迭代的内部,弱分类器的获取是建立在对特征的选择上,而每个特征评价方法是特征之间不相关的,因此特征评价的计算部分也可适用于云计算化。
HMM是马尔科夫链的一种,是状态不可直接观察的双重随机过程。该模型的训练过程是一种迭代训练的过程,以满足某个条件作为训练的结束条件。其训练过程一般迭代次数较少,单次迭代的计算量较大,所以对单次迭代的训练可以考虑使其并行化。但是由于在HNM方法中,状态也是一种递推的过程,算法比较复杂,其并行化的难度较大。
神经网络的特点是构造权值矩阵来模仿信号在传递过程中强弱的变化,制定多种传递的规则。在训练过程大多都采用一种反向传递的机制,通过对比理想结果与实际计算结果的差距,对权值矩阵进行修改,以此改变传递过程的信号强弱变化,进而改善分类器的分类效果。大多数反馈机制都是以迭代来修正权值矩阵,而不是一次性解决;因此也是一个串行训练的过程。因此,其并行化处理,只能是对其中单次迭代内部涉及大量的矩阵运算的优化。
SVM(Support Vector Machine)即是支持向量机,在解决小样本、非线性及高维模式识别具有许多特有优势。其原始形式是用来解决二分类问题,基于多个二分类器,可以构建N分类器。N 类中任意两个类都对应一个二类分类器,每个二类分类器都为一个特征向量的分类结果在两个类上进行打分,最后得分最多的类作为最后结果。每个二类分类器的构造过程可以采用分布式处理。
由于训练过程往往涉及到多次迭代,每次迭代都会根据上次迭代结果,进行调整参数再计算。迭代之间具有相关性,无法直接进行用于分布式框架处理的。因此,对训练过程进行云计算化,只能是在每次迭代的内部进行,从中分析其可分布式处理的环节。
4 识别过程的云计算化
基于分类器的人脸识别过程,是基于多级2分类器或N分类器的迭代检查过程,计算量相对较小。但是为达到最佳效率,在分类器分类过程中,也存在分布式处理以缩短计算时间的可能。以Adaboost为例,级联的弱分类器的个数众多,可以通过分布式的处理,将各个弱分类器平均分配到各个服务器上,每个服务器负载一部分弱分类器的分类,最后汇总得到最后结果。
基于欧式距离等向量距离计算方式的人脸识别过程,在提取特征之后,需要进行特征之间的距离计算及排序,计算量较大。由于需要将带检测对象的特征与原有的特征库进行逐一的距离计算,特征库的特征之间在计算时是不相关的,因此可以进行分布式处理,将计算分配到云计算平台中,最后再把计算后的各个结果,进行排序汇总。
5 基于Hadoop的人脸识别云计算技术方案
Hadoop[4]是一个业界广泛认可的云计算的分布式系统架构,其核心设计是HDFS和MapReduce。基于Hadoop构建人脸识别云服务,可采用HDFS存储海量的人脸识别样本数据,并采用MapRduce处理人脸识别中的可分布式处理环节,包括图像预处理、局部特征值提取、分类器训练与识别过程中的可分布式处理环节。
下面以LBP特征提取环节为例,介绍MapReduce的处理流程。通过定义LBP特征提取环节的Map和Reduce函数,实现分布式处理。
LBP特征提取过程的函数Map():
输入:
输出:
功能: i.从标准灰度图value提取LBP特征信息value’
ii.输出
LBP特征提取过程的函数Reduce():
输入:
输出:
功能:汇总所有LBP特征,形成LBP特征矩阵输出。
在Hadoop平台上,Map/Reduce的处理流程如图1。在Hadoop平台上,基于key值在Reduce环节进行分组处理,最终输出特征值矩阵。
6 展望
云计算技术的快速发展,给传统的人工智能技术带来新的发展推动力。从HADOOP和 MAP REDUCE 到SPARK,云计算分布式框架的性能一直在持续不断得到提升,并且SPARK框架已开始直接提供一些机器学习API。今年5月,百度在github上开源了其深度机器学习平台,也大幅降低开发和部署分布式机器学习系统及相关应用的门槛。而早在2011年开展基于云计算的模式识别研究的腾讯研究院,也于今年8月推出基于人类识别的身份验证服务。随着人工智能技术与云计算技术的结合,将人脸识别服务云计算化,势必推动人脸识别服务获得更广泛的应用。
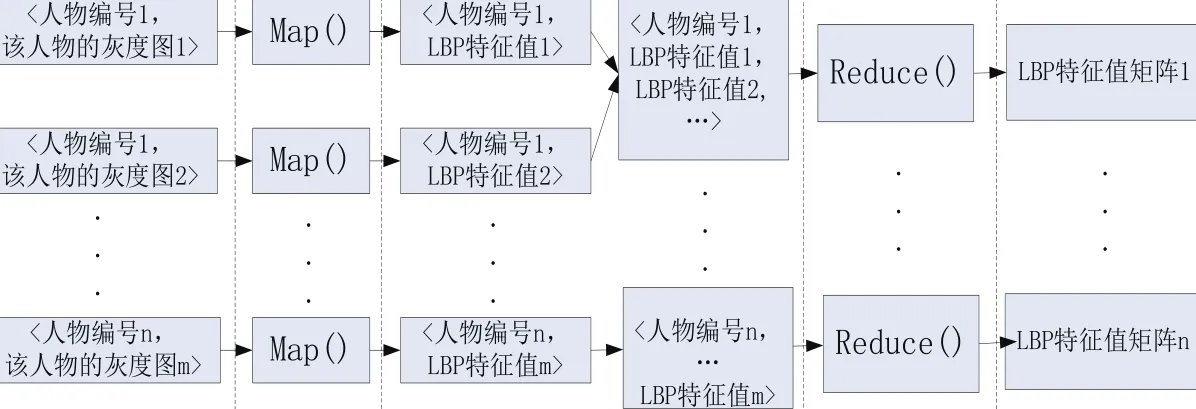
图1 LBP特征值的MapReduce处理流程
参考文献
1李仕钊. 基于云计算的人脸识别系统研究与实现.华南理工大学硕士学位论文, 2013: 5
2苏煜,山世光,陈熙霖,高文. 基于全局和局部特征集成的人脸识别. 软件学报,2010:8
3祝秀萍 吴学毅 刘文峰. 人脸识别综述与展望. 计算机与信息技术, 2008:4
4Hadoop百度百科 http://baike.baidu.com/view/908354.htm
5SPARK百度百科 http://baike.baidu.com/ subview/123524/123524.htm
DOI:10.3969/j.issn.1006-6403.2016.01.004
收稿日期:(2015-11-25)
