基于工作流引擎的遗留系统流程重构设计与实现
2016-05-14武鹏李文倚刘小白
武鹏 李文倚 刘小白

摘要:基于工作流引擎工具,设计了遗留系统集成工作流引擎的嵌入式结构,实现了遗留系统与工作流引擎用户和权限数据的同步及工作流引擎节点配置的无缝集成,解决了遗留系统流程处理灵活性与可扩展性不强、难以实现用户级灵活定制和不能快速满足企业应用的问题,对于遗留系统流程重构具有一定的借鉴意义。
关键词:工作流;系统集成;遗留系统;流程重构
DOIDOI:10.11907/rjdk.161456
中图分类号:TP319
文献标识码:A 文章编号:1672-7800(2016)005-0097-02
0 引言
随着信息系统的深入应用,各企业和组织内部产生了大量作为业务支撑的遗留系统[1]。为了满足新的业务需求,对相关系统进行优化与重构不可避免。其中,随着管理提升和审核流程的变更,作为系统重要功能的各类审核流程管理功能暴露出了如下主要问题:①不少遗留系统独立开发的流程管理模块使用了伪流程方式,依赖于流程节点序列编码,缺乏灵活性与可扩展性;②在流程节点设计方面未能实现用户级灵活定制,需要开发人员操作后台数据库或硬编码进行人工干预。
一般的工作流产品或工具都能够可视化地进行流程建模,并灵活适应流程节点的变化需要[2]。但通常基于工作流的信息系统开发要针对具体的工作流产品进行架构、设计和实现,既定架构、设计和实现的遗留系统并不能很好地且轻量地使用工作流工具,以发挥工作流技术的优势。
针对上述问题,本文首先引入了工作流引擎工具,然后在原有系统架构、设计和实现的基础上完成了工作流引擎嵌入结构设计并加以实现,通过二次开发解决了工作流引擎在现有系统中动态嵌入的问题,最终以某遗留系统为例成功完成了审核流程的重构,提高了系统的可用性与灵活性,解决了实际应用问题。
1 具体问题分析
目前某应用系统的流程管理功能基于自行开发的流程管理模块,如表1所示。其流程管理机制是将每个流程活动状态用一组整数序列(1,2,10,50,100,150,200)来表示,每个整数值代表一个审核状态,让程序记录该状态以便知道操作顺序,以及当前处于什么状态。然而这种机制不支持灵活修改,如表1所示。假设 “录入完毕“和“经过了第一次审核”之间多一个活动,则意味着需要在1和2之间增加一个整数。若要满足需求,只能重新设计相应序列并修改相关实现。
一般的解决方案是引入工作流引擎代替现有流程处理模式,以实现流程用户级灵活自定制,提高可用性与灵活性。但面对架构、设计和实现已经成型的遗留系统,一个成熟的工作流引擎本身的可定制性有限,要实现工作流引擎与遗留系统的无缝集成,有如下问题需要解决:①遗留系统的业务数据与工作流引擎的流程实例建立关联;②遗留系统与工作流引擎管理器用户数据和权限数据的同步及流程节点配置的无缝集成。以下针对上述具体问题进行分析并提出解决方案。
2 设计思路与实现
2.1 遗留系统集成工作流引擎嵌入式结构
通常工作流的使用有以下几个典型步骤:①使用工作流中类似企业管理器的工具建立用户、组织结构和角色等基础元素;②针对业务流程完成数据库及数据库表、页面和表单设计;③使用工作流的可视化流程建模设计器完成流程建模;④在建好的流程中配置流程节点属性。这些都建立在工作流引擎之上,依托设计器等工具即可将使用设计器设计的表单与流程建模得到的流程节点关联起来。每张数据库表都有类似TaskID(任务ID)的字段,该字段标识一个流程任务,由工作流引擎自动维护[3]。
其中流程建模通常是由流程节点加上一定的条件节点,按照一定规则互相连接完成。流程流转的对象实际上是表单信息,而将表单与流程相关联的关键在于流程节点的设置。通过对流程节点属性的设置,以及表单对应的后台数据库表中的TaskID字段来关联信息系统中的基本业务单元、相应表单、所在流程以及对应节点。表单的提交将发起一个流程实例,表单的处理使流程实例顺着一个个节点流转,而“提交”等处理事件将在表单设计过程中固化到表单或表单的后台代码中[4]。
对于一个已经开发完成并运行多年的遗留系统而言,系统所有的Web页面、后台业务逻辑和数据库表结构设计都已完成,直接使用工作流相关工具进行设计和配置无法建立表单和流程实例之间的关联。因此,本文设计了遗留系统集成工作流引擎的嵌入式结构,解决了上述问题。
本文在现有遗留系统的架构、设计和实现基础上,设计中间表作为遗留系统和工作流引擎的适配器和桥接器,建立表单和流程实例之间对应关系。具体思路如下:针对应用系统中表单的构成(例如:在基本信息审核中是以油气田为单位,每个油气田下又有所属油气田的具体信息表,即存在两个基本单元:油气田代码和具体信息表代码,分别用于标识油气田和所属油气田的具体信息表),建立并记录工作流引擎中TaskID(流程实例对象)与油气田代码和具体信息表代码的关联。同时,如果节点和表单直接关联,工作流引擎中有一个ProcID(流程处理过程对象),每一步流转通过它来标识,如果一个节点一步一次处理一个表单信息到下一个节点,由于没有分支,则不需要知道此表单具体对应哪个ProcID;如果一个节点一步一次处理不止一个表单,待处理任务中会有不止一个ProcID,而每一个ProcID对应一个表单,则需要记录ProcID分别对应哪个表单,以区分处理。
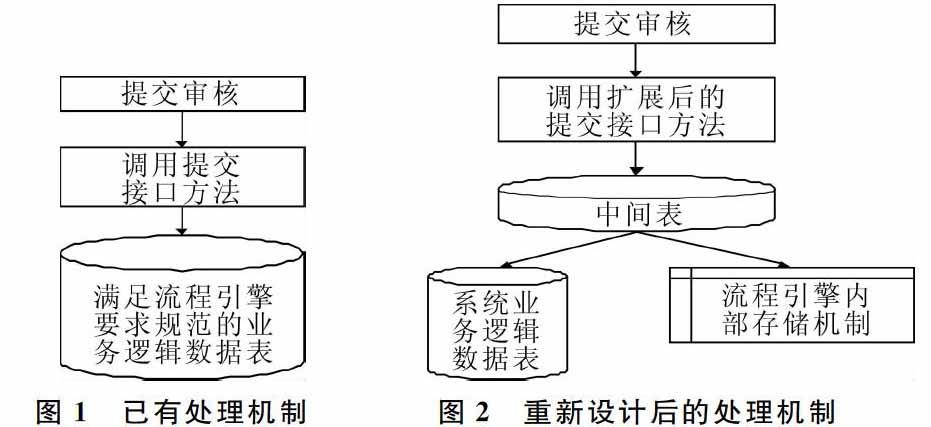
本文据此设计了一个类似(TaskID、ProcID、油气田代码、具体信息表代码)的关系将流程实例和具体的待处理信息关联起来,并提出了如下通用解决方案:依据具体的业务流程处理要求,在工作流的后台数据库或应用系统的数据库中添加一张中间表来记录TaskID、ProcID和具体业务的关联关系,如图1、图2所示。改变已有的处理机制,使用一张中间表作为桥接,在遗留系统的业务表单同后台工作流引擎的内部处理机制(流程流转、处理记录等)之间建立桥梁,形成遗留系统集成工作流引擎的嵌入式结构,并关联业务处理与流程实例,将遗留系统应用工作流的难度从技术层面转移到业务层面,从而使应用工作流技术进行遗留系统重构变得可行和简单。
本文以Liveflow工作流引擎为例,在启动一个流程时同时写中间表,借助工作流引擎内在提交方法Post(objBPCn, "提交", out o, 0, "", SetFields(fieldsName, fieldsValue), null, null)写入这种关系,其中SetFields(fieldsName, fieldsValue) 是表单数据集合参数。通过此方法把ProcID、油气田代码、具体信息表代码在启动时写入中间表。进行流程节点处理时,对同一油气田代码和具体信息表代码更新ProcID,使中间表永远存储最新处理完的ProcID。
通过该方式为遗留系统使用工作流的二次开发接口重写“提交”和“处理”建立了基础,也为单节点中多表单信息的批量处理提供了解决方案。要在工作流引擎中的单节点中处理多表单信息,只需在中间表中建立一对多关系,然后使用工作流的二次开发接口,重写“提交”和“处理”事件。当用户在审核处理界面操作时,相应的“提交”和“审核”事件将通过工作流引擎的内部处理机制与工作流引擎进行一系列交互,以保证每一次处理都知道处理内容以及下一个节点的接收内容,并由工作流引擎自动维护节点状态信息,以保证业务流程的处理过程在使用工作流设计器建模后形成的流程中作为一个个流程实例进行体现。
2.2 数据同步及工作流引擎节点配置无缝集成
本文直接从工作流引擎后台数据库中读取流程实例的各节点“状态”信息,通过LiveFlow建立在BPFC(Business Process Foundation Class)上的基于COM的二次开发接口BPO (Business Process Object)映射和同步工作流产品与遗留系统的用户信息数据库表,完成遗留系统与工作流引擎管理器用户数据和权限数据的同步。在遗留系统的系统管理模块集成流程节点的审核用户配置,将工作流引擎流程节点的配置与遗留系统进行无缝集成。工作流引擎维护的流程节点的配置,已经集成在遗留系统的系统管理模块中来完成。
3 结语
本文完成了遗留系统集成工作流引擎的嵌入式结构设计,同时以LiveFlow工作流引擎为例完成了遗留系统与工作流引擎管理器用户和权限数据的同步及流程节点配置的无缝集成,实现了遗留系统数据审核流程用户级灵活自定制,有效提高了系统的可用性与灵活性,对使用工作流技术重构遗留系统流程具有实际意义和一定的借鉴价值。
参考文献:
[1]张一川,汪德帅,刘莹,等.基于业务服务的企业遗留系统集成框架[J].计算机应用, 2008,28(B06):263-265.
[2]蔡孝武,韩永国,蓝科.一种轻量级工作流引擎的研究与设计[J].计算机工程, 2010,36(20):78-79.
[3]罗海滨,范玉顺,吴澄.工作流技术综述[J].软件学报,2000,11(7):899-907.
[4]王凯,张毅坤,杨凯峰,等.面向OA系统的工作流引擎研发[J].计算机工程与设计,2008,29(19):4967-4971.
(责任编辑:黄 健)
