基于神经网络的医保欺诈主动发现模型
2016-05-14王超韩可欣黄登一
王超 韩可欣 黄登一
摘要:本文阐述了运用自组织竞争型神经网络(SOM)与BP神经网络相结合,建立医保欺诈主动发现模型的原理和过程。主要介绍医疗数据的特征,海量数据初步分类和精选样本对BP神经网络进行训练的方法,最后采用遗传算法对BP神经网络的权值和阈值进行优化。研究成果较好地实现了对医保欺诈行为的主动识别。
关键词:SOM神经网络 BP神经网络 医保欺诈 识别模型
中图分类号:TP399 文献标识码:A 文章编号:1007-9416(2016)05-0000-00
Abstract:In order to build a model for detection of fraud in medical services, the paper proposes a new algorithm by combining self-organized map neural network(SOM) with back-propagation artificial neural network(BP).The authors firstly introduce the characteristic of medical data, and then investigate approach based on SOM to select samples for the training of BP neural network. At last, the paper applies genetic algorithm into the model, so as to optimize initial weights and biases. It turns out that the model is highly effective in intelligent recognition of fraud.
Key Word: SOM neural network; BP neural network; Fraud in medical; Model for detection
1引言
随着我国医疗保险普及率的提高,医保基金的安全问题日渐引人关注。自城镇职工医疗保险和新型农村合作医疗制度实施以来,骗取医保基金的案件不断发生[1]。据不完全统计,在许多国家医保欺诈和滥用每年造成的损失都达数亿美元甚至更多,严重妨碍了各国医保政策的顺利实施[2][3]。因此,构建一个相对准确的医保欺诈主动发现和预警机制,对保障参保人员权益、提高医保基金使用效率都具有重大意义。
目前,反医保欺诈的研究是一个世界性的课题。由于医疗数据的海量信息和欺诈行为的隐蔽性,有效识别欺诈行为是反欺诈研究的重点和难点。国外学者的研究中,美国的Fen-May Lion对Logistic回归模型、神经网络和决策数等三种方法用于医疗数据挖掘,的方法和效果情况分析比较[4];美国的Kweku-Muata和Osei-Bryson分析了目前数据挖掘中存在影响因子过多的问题,并提出VFT和GQM的解决方法[5]。国内针对医保欺诈的研究,目前多数停留在社会和法律层面的分析;关于医保欺诈行为识别方法,主要有杨超等提出的统计回归和神经网络相结合的方法[6],研究的深度和广度都有待进一步拓展。
本研究采用自组织竞争型神经网络,对海量医疗数据按疑似欺诈数据和非欺诈数据两类进行初步筛选;在此基础上,人工精选一些分类后的数据作为BP神经网络的训练样本,并用遗传算法对BP神经网络进行优化。经验证,优化后的BP神经网络对医保欺诈具有良好的识别效果。
2 医保欺诈的概念及数据特点
2.1医保欺诈定义和类型
医疗保险欺诈一般是指医疗保险制度的相关利益主体以骗取医疗保险基金或医疗保险待遇为目的,采取各种形式隐瞒自己的真实身份或实际诊疗情况,从而骗取相关利益的行为。本研究所指的医保欺诈采用广义的定义,即任何因不符合正常就医规律的行为而导致的对医保基金的滥用或骗取都被视为医保欺诈。
根据严重程度的不同,医保欺诈可分为两类:一类是对医保基金的滥用,如小病住院,开高价药,过度检查等造成的医保资源的浪费;另一类则带有明显的欺诈故意,如非投保人使用投保人的证件,医院开具虚假的住院证明、药品清单或就诊发票等。
2.2医疗数据特征
本研究所用数据来源于深圳市南口区南山、西丽、蛇口三家大型医院2014年一月份的病人数据和就诊记录,共计约35万条数据。每条医疗数据有100多个字段,包含病人资料、就诊明细、住院信息、药品信息等海量数据,具有明显的大数据特征。这些数据中既没有明确标记为骗保行为的记录,也没有一套用来界定异常数据的完整规则,而且其中不乏错误的、残缺的和无效的数据。因此,研究前期利用SAS和SPSS等工具对数据进行清洗和提取,构建了有效信息数据库。
3 相关算法简介
3.1 自组织神经网络
自组织神经网络(SOM)属于层次结构网络,有多种类型,其共同特点是都具有竞争层。最基础的网络仅有一个输入层和竞争层。假定输入层由N个神经元,竞争层有M个神经元。网络的连接权值为且满足约束条件:所有连接权值之和为1。在竞争层中,神经元之间互相竞争,最终只有一个神经元获胜,以和当前的输入样本相适应。在这种竞争机制中,竞争层中具有最大加权值的神经元赢得竞争胜利。竞争胜利的神经元可以代表当前输入样本的分类模式。竞争后各层神经元之间的权值还要按照一定规则进行修正。通过不断调整网络中与各神经元相关的权值和阈值,网络得出当前样本下误差最小的最佳分类模式。
自组织神经网络最大的优势是具有自主学习能力,可以通过分析事物的内在规律和本质属性建立相应规则,进而对具有不同特征的事物进行分类。其事先无需已明确分类的样本进行训练,能满足对海量医保数据进行初步筛选的要求。据此,我们采用的自组织神经网络对原始数据进行一次筛选,初步分离具有骗保行为特征的数据和没有骗保行为的数据作为BP神经网络的训练样本。
3.2 BP神经网络算法
BP网络[7](Back Propagation),是一种按误差逆传播方法训练的多层前馈网络,是目前应用最广泛、研究最充分的神经网络模型之一。BP网络无需事前揭示描述事物之间映射关系的数学方程,它通过学习和存贮大量的输入-输出模式映射关系,采用最速下降法的学习规则,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
BP网络的缺陷是学习收敛速度过慢、无法保证收敛到全局最小点,网络结构难以确定。另外,网络结构、初始神经元之间连接的权值和阈值的选择对网络训练的影响很大,而且需要不断的测试和调整才能获取。不过一旦找到合适的参数,BP网络将具有很高的精确度。针对这些特点,我们采用遗传算法对神经网络BP算法的参数,即连接权值和阈值进行优化,选择出最佳的网络模式,大大减小了人工选择参数带来的误差。
3.2 遗传优化算法
遗传算法借鉴于生物进化论,它将要解决的问题模拟成一个生物进化的过程:初始种群通过复制、交叉、突变等操作产生下一代的解,种群中适应度较高的个体被保留下来,适应度函数值低的个体被自然淘汰。这样进化多代后就很有可能会进化出适应度函数值很高的个体。在对医保欺诈数据挖掘实例中,我们利用遗传算法对BP神经网络进行优化,把预测数据与期望数据之间的误差作为适应度函数,这样当进行数代的进化,变异,选择之后,得到最优的初始权值和阈值。利用得到的最优初始权值和阈值建立BP神经网络,此时建立的即是判别误差最小的网络模式。这样,当有新的数据输入神经网络,便可以较准确的实现对它的分类,即判断是否属于医保欺诈数据。
4 主动发现模型的搭建
4.1 样本和变量
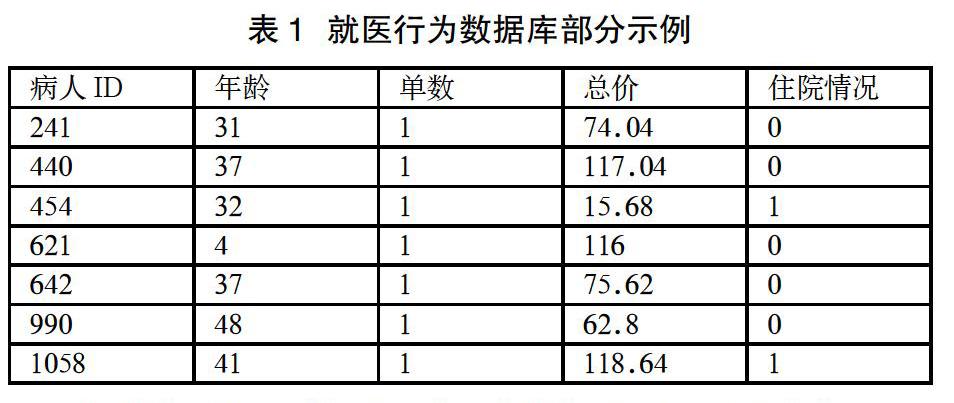
对比所给数据和医保欺诈种类,前述医保欺诈的行为反映在数据上主要有以下几种表现:单张处方药费极高、同一医保号短时间内反复多次大量拿药、病人ID和医保号不符、小病长时间住院等。提取数据与医保欺诈行为识别相关的特征,包括“患者年龄”“住院情况”“就诊总金额”“就诊次数”,构建就医行为数据库,最终得到10050个样本。部分示例下表1所示。
通过自组织神经网络算法的计算,找出了欺诈患者在就诊总金额、就诊次数和住院人数比例上与非欺诈患者有明显的区别:欺诈患者的就诊平均总金额达到1254.63元、平均就诊次数为3次、住院人数比为32%,而非欺诈患者就诊平均总金额为289.49元、平均就诊次数1.58次、住院人数比为19.5%。欺诈患者的三项指标明显高于非欺诈患者。
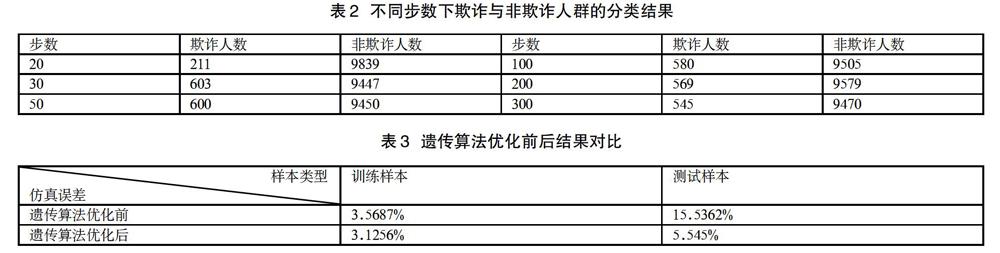
改变训练的步数,得到不同步数下欺诈人群的人数如下表2所示。
从表中可以看出,随着训练步数的增加,自组织神经网络分类出的欺诈人数呈现先增加后减少的趋势。在20步的时候,欺诈人数远远小于30步的人数,这是神经网络学习不完全的结果。当训练步数增加到300时,欺诈人数较之前有一定下降,这可能与神经网络过度学习有关,使得数据的泛化能力下降。30步以后,神经网络分类结果基本稳定,欺诈人数的波动率仅为0.35%。综合考虑网络的学习效果和分类所需时间,我们最终选定训练步数为200,即将欺诈人数为569人作为初步分类结果。
通过查阅参考资料,应用经验判断法对分类后的欺诈数据进行人工核查。考虑到老年人容易患病住院和患严重疾病的患者医药费极高的特殊情况,从569位疑似欺诈患者中排除89人,从9481个非欺诈患者中新确定出35位可能欺诈的患者。最终确定疑似欺诈人数为471,非欺诈人数9579,自组织神经网络的误判率仅为0.98%。
由于分类结果的波动率和误判率都很低,可以认为该分类有效,能够作为BP神经网络的训练样本。
4.2 BP神经网络创建
对于一般的模式识别问题,三层网络即可很好地解决问题。在三层网络中,隐含层神经网络个数和输入层神经元个数之间有近似关系[9]:
在建立的模型中,由于样本有4个输入参数,2个输出参数,所以这里取值为31,设置的神经网络结构为4-9-2,及输入层有4个节点,隐含层有9个节点,输出层有3个节点,共有49+92=54个权值,9+2=11个阈值。
遗传算法对BP神经网络的优化如下:首先计算适应度并对神经网络的权值和阈值编码,从而得到初始种群;通过解码得到权值和阈值并并利用其建立新的BP网络;使用训练样本和测试样本来训练和测试网络,得到相应的测试误差;利用遗传算法对适应度高的染色体进行复制、交叉、变异,得到新群体,然后循环上述过程。最后得到测试误差最小的那一组权值和阈值,作为用来医保欺诈数据主动发现模型网络结构中的最佳参数。
为了确保模型的有效性,我们从初步分类的欺诈数据和非欺诈数据中分别选取271条和400条数据,共计671条数据作为训练样本来训练BP网络。然后将确定为欺诈的剩余200人和非欺诈人群中再次选出的200人作为测试样本,来验证网络的识别效果。将样本的测试误差的范数作为衡量网络的一个泛化能力(网络的优劣)的指标,优化前后仿真误差的结果对比如下表3所示。
由上表可见,优化初始权值和阈值后的测试样本误差由15.536%减小到5.545%,训练样本的误差由3.5687%减小到3.1256%,即测试样本正确率最高可达到1-5.545%=94.094%。表明优化后BP神经网络的训练和测试效果都得到了较大改善,遗传算法的优化具有良好的效果。
5结语
本研究创新性地将单层竞争型神经网络与BP神经网络结合使用:采用单层竞争型神经网络对海量数据的初步分类,得到的结果经检验具有较好的稳定性和一定的准确性;利用BP神经网络需要用部分已知分类的样本进行训练的特性,将单层竞争型神经网络的分类结果作为BP神经网络的输入,从而使两种神经网络相结合、优势互补,对于建立一种医保欺诈行为主动发现的模型具有较大的参考价值。本研究的不足之处在于:无法获知准确的欺诈数据或者判别标准,当数据量增加时会更难以判断自组织神经网络初步分类的精准度,对BP网络学习的准确度造成一定影响。因此,本研究成果适合开发成一款医保欺诈预警系统,由系统直接从海量数据中筛选出疑似欺诈数据,并对疑似数据进行实时监测和报警,这样可以大大缩小人工核查的范围,为医保欺诈的调查和最终判别提供极大的便利。
参考文献
[1]牛晓辉.新农合住院费用的分析及异常值筛检方法研究[D].华中科技大学,2012.
[2]Pflaum B B,Rivers J S. Employer strategies to combat health care plan fraud.[J].Benefits quarterly,1990,71:.
[3]Leonardo, J. A. "Health care fraud: a critical challenge."Managed care quarterly?4.1 (1995): 67-79.
[4]Liou F M, Tang Y C, Chen J Y. Detecting hospital fraud and claim abuse through diabetic outpatient services[J]. Health care management science, 2008, 11(4): 353-358.
[5]Osei-Bryson K M. A context-aware data mining process model based framework for supporting evaluation of data mining results[J]. Expert Systems with Applications, 2012, 39(1): 1156-1164.
[6]杨超.基于BP神经网络的健康保险欺诈识别研究[D].青岛大学,2014.
[7] 朱敏,刘学广.内燃机排气噪声半主动控制技术研究[D].哈尔滨:哈尔滨工程大学,2010.
