基于Scrapy的GitHub数据爬虫
2016-05-14赵本本殷旭东王伟
赵本本 殷旭东 王伟

摘 要作为最大的社交编程及代码托管网站,GitHub提供了丰富的数据来源。基于Python开源框架Scrapy设计实现了一个Web爬虫,能对GitHub的资源抓取和分析,并进行了结构化处理和存储,可为后续数据分析提供基础。介绍了GitHub爬虫的设计原理、算法的实现方式,对实验结果进行了分析。
【关键词】网络爬虫 数据爬取 Scrapy GitHub Python NoSQL
数据产生于各行各业,在互联网时代大数据概念提出后,人们发现自己手中的数据不再毫无用处,通过强大的技术手段,无形的数据可转化为有形资产。麦肯锡公司的报告指出数据是一种生产资料,大数据是下一个创新、竞争、生产力提高的前沿。 世界经济论坛的报告也认定大数据为新财富,价值堪比石油。GitHub是一个巨大的数据宝库,吸引了大量的开发人员与研究人员入驻。2014年的《GitHub中国开发者年度报告》指出,目前 GitHub 上的注册用户数量已经超过1000万。由于网站托管的开源项目众多,访问的流量也呈爆炸性增长。要想从数千万程序员中快速、准确地抓取所需要的信息变得越来越困难,所以必须使用自动化工具才能较容易的抓取下来。
本文设计并实现了一个基于Scrapy框架的Web数据爬虫,从GitHub抓取大量用户数据信息,下载到本地,进行了结构化处理和存储,为之后做数据分析提供基础。
1 网络爬虫与Scrapy
所谓网络爬虫,就是抓取特定网站网页的HTML数据。网络爬虫从一个存放URL的集合开始进行爬取,首先从队列中获取一个URL并下载此网页,提取该网页中的其它URL并放入队列中。此过程将重复直至关闭。常见的网络爬虫及其爬行策略包括:
(1)广度优先爬虫,一般全网搜索引擎的网络爬虫使用广度优先的爬行策略。
(2)重新爬取已有的页面的爬虫,目的是获得数据的定期更新。
(3)聚焦爬虫,也叫定向爬虫,为很多垂直搜索引擎使用,采取特定的爬行策略来爬取特定类型的网页。本文所研究的正是这一类型的网络爬虫。例如,网页上的某个特定主题或语言、图像、MP3文件等。
Scrapy是用Python开发的一个开源的Web爬虫框架,可用于快速抓取Web站点并从页面中高效提取结构化的数据。Scrapy可广泛应用于数据挖掘、监测和自动化测试等方面,提供了多种类型爬虫的基类,如BaseSpider、SitemapSpider等。
2 基于Scrapy的Github数据爬虫的设计
2.1 Scrapy原理
Scrapy是基于Twisted异步网络库来处理通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。其工作原理为:首先从种子URL开始,调度器会传给下载器进行下载,之后会交给爬虫进行分析,根据分析结果进行不同处理。如果是需要进一步爬取的链接,这些链接会传回调度器;如果是需要保存的数据,则被送到项目管道组件进行后期处理,包括详细分析、过滤、存储等。此外,在数据流动的通道里还允许安装各种中间件,进行必要的处理。
2.2 GitHub数据爬虫
2.2.1 GitHub网页结构与数据分析
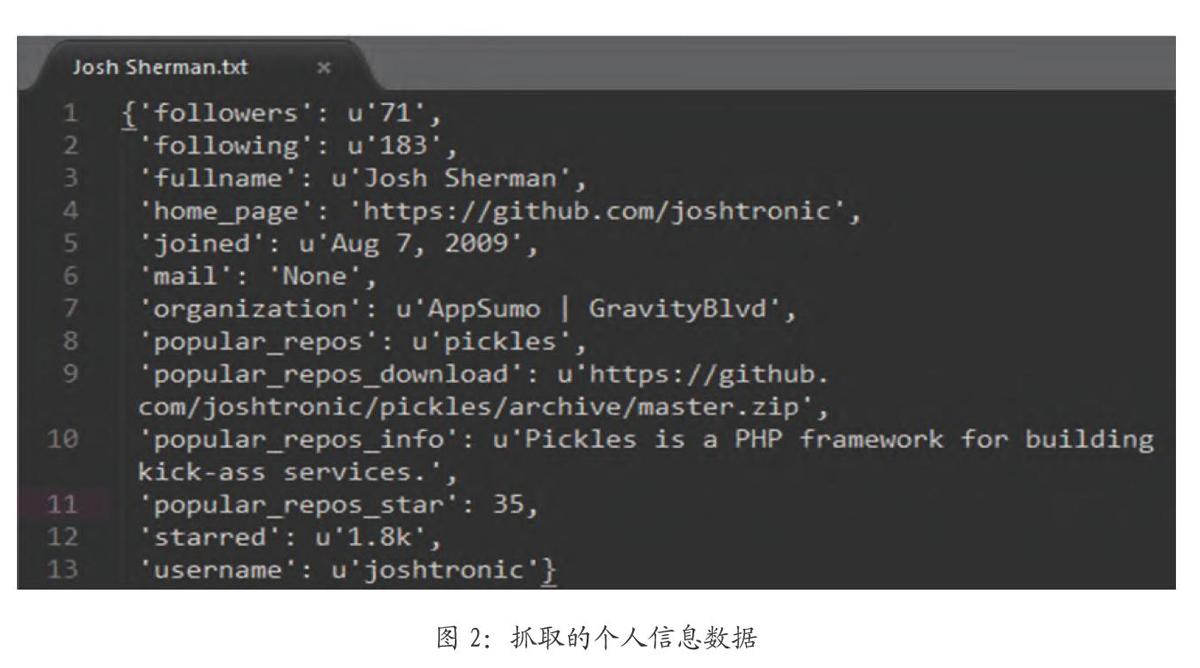
GitHub个人主页的主要信息可分为左右两块:左块为个人基本信息,右块为个人相关的项目。个人基本信息包括名字、邮箱、公司、头像等,爬取时会按照编写的爬虫规则全部保存下来,同时右块的项目信息也储存在JSON文件中。格式为:
{
“_id”:
“fullname”:
“mail”:
“username”:
“organization”:
“joined”:
“starred”:
…
}。
2.2.2 数据定义
Item是保存爬取到的数据容器,使用方法和Python字典类似。根据从GitHub网站上获取到的数据followers、fullname等对Item进行统一建模。从而在Item中定义相应的字段field。对应的item.py中的主要代码为:
import scrapy
class GithubItem(scrapy.Item):
fullname = scrapy.Field()
username = scrapy.Field()
popular_repos = scrapy.Field()
…
2.2.3 编写提取Item数据的Spider
GitHubSpider是用于GitHub网站爬取数据的类,选择从scrapy.Spider类继承。定义以下属性和方法:
(1)name属性:定义spider名字的字符串且唯一;
(2)start_urls属性:Spider在启动时从url列表开始进行爬取。第一个被获取到的页面将是其中之一,后续的URL则从初始的页面中提取;
(3)parse:是Spider的一个方法。每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该方法。该方法解析提取Item数据以及生成需要进一步处理的URL的Request对象。
Scrapy提取数据使用Selector选择器机制,使用特定的XPath表达式来提取HTML网页中的数据。此爬虫提取GitHub用户主页中的followers数据项使用代码:
people['followers']=response.xpath('//div[@class="vcard-stats"]/a[1]/strong[@class="vcard-stat-count"]/text()').extract();
即提取class为vcard-stats的div标签内的第一个a标签里的class为vcard-stat-count的strong标签内的文本数据。
2.3 数据存储NoSQL
网络爬虫系统爬取的数据量大,且多为半结构化或非结构化数据,传统的关系型数据库并不擅长这类数据的存储与处理。而NoSQL在大数据存取上具备关系型数据库无法比拟的性能优势,因此选择使用NoSQL数据库存储爬取到的数据。
2.3.1 数据存储方式
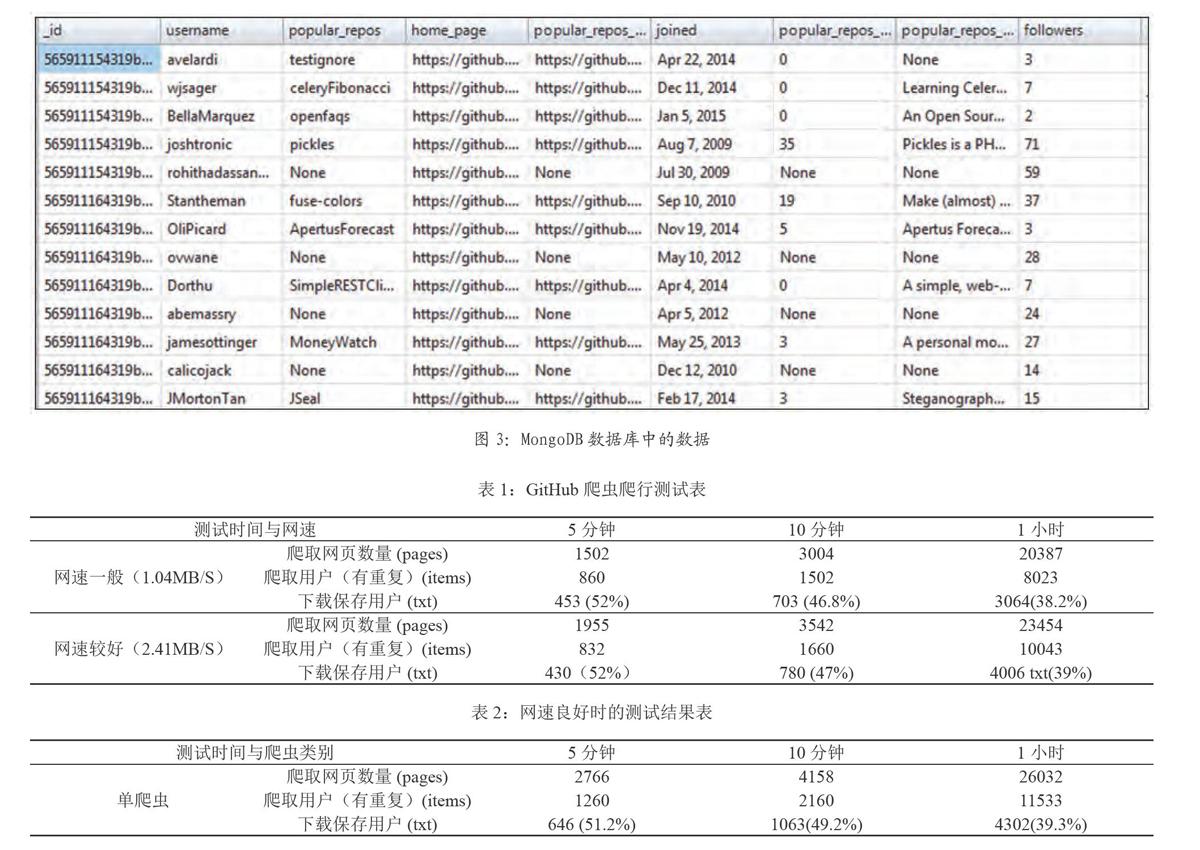
MongoDB是一个基于分布式文件存储的非关系型数据库,具有灵活的数据存储方式。MongoDB数据存储不需要固定的表结构,也不存在连接操作。其次它是一种基于文档的、无模式且不保证ACID的数据库。每当抓取数据到Item项时,都会添加进一个Mongo集合。
2.3.2 设置数据库
在settings.py文件里设置MongoDB的参数:服务器SERVER、端口PORT、数据库DB、数据库表COLLECTION,之后指定管道后添加数据库设置:
ITEM_PIPELINES={ 'GitHub.pipelines.MongoDBpipeline':300,}
2.3.3 连接数据库
在pipelines.py文件中通过管道连接。首先定义一个函数去连接数据库:
class MongoDBpipeline(object):
def __init__(self):
MongoClient(…)
def process_item(self, item, spider):
…
return item
创建了一个类MongoDBPipeline(),构造初始函数初始化类。process_item()函数处理被解析的数据。
2.4 反爬虫技术的应对措施
很多网站为避免被爬虫抓取数据,使用了一定的规则和特定的机制来实现,本爬虫主要采取以下措施:
(1)设置download_delay,即下载器在下载同一个网站下一个页面前需要等待时间。如果下载等待时间长,则不能满足短时间大规模抓取的要求;而太短则大大增加了被Ban的几率。因此在settings.py中设置:DOWNLOAD_DELAY = 2;
(2)禁止cookies,可以防止使用cookies识别爬虫轨迹的网站察觉,在settings.py设置:COOKIES_ENABLES=False;
(3)使用user agent池,防止被服务器识别,将user agent池写入rotate_useragent.py文件里。
2.5 爬虫工作方式及算法
GitHub网站上网页数以百万记,且分布在全世界各个地方的服务器。对于GitHub这样的网站来说,适合采取定向爬虫策略。即从第一个URL种子开始,来收集所有的用户信息和可以利用的用户URL并保存起来,之后遍历整个URL集合。
GitHub爬虫采取宽度优先遍历策略,其基本思路是将新下载网页中发现的链接直接插入待抓取URL队列。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
(1)首先由图开始从用户URL种子进行爬取,即用户主页面。然后通过爬虫将网页中个人信息提取出来并分别存储到每个人新创建在本地的文档中。
(2)通过判断用户的关注者即是否等于0而继续循环爬行还是重新爬行,不为0时会保存每一个被关注者的链接到URL队列里面,方便继续循环。
(3)循环爬取时会保存每一个用户的关注页面,因为如果循环完用户之后,还有个他的关注者URL页面没用到,进入关注页面会有重新一批用户,然后再添加入循环。
(4)关注者与被关注者难免会互相关注,所以爬取时会重复爬取,但不会重复下载信息。
爬虫算法用伪代码描述如下:
Begin
init
name←github
headers←{Accpet,User-Agent,..}
allowed_domains←github.com
start_url←["https://github.com/someone",]
return A
A people←Github_Item()
people←response.xpath(“//...”)
Save as TXT. call B(self,response)
B Store as followers_urls、people_urls_list
Duplicates_Removal followers_urls、people_urls_list
people_link_1←people_urls_list[0]
people_urls_list.remove(people_link_1)
call C(people_link_1)
C Count followers
IF followers≠0 THEN
followers_urls.append(url)
call A(url);
ELSE
IF followers_urls ≠ [] THEN
followers_link_1←followers_urls[0]
followers_urls.remove(followers_link_1)
call A(followers_link_1);
ELSE
people_link_1←people_urls_list[0]
people_urls_list.remove(people_link_1)
call A(people_link_1)
END IF
END IF
END
3 实验与分析
3.1 实验结果
对以上的爬虫进行python代码的编写,启动运行scrapy crawl github -s LOG_FILE=scrapy.log,下面是部分数据的展示。图2展示了用户个人信息保存在文本文件中的数据,图3为MongoDB数据库内存储的数据,可用于统计分析查询。
3.2 实验分析
实验环境使用一台PC机运行爬虫程序,并且同时运行数据存储服务器。实验测试中,临时暂停发现共爬取了221次(有重复),保存了152人,URL队列中还有623条个人主页没爬取。没有发现 Crawled (429)(太多请求)等警告信息。
爬取会时不时的停顿,有时出现twisted.python.failure.Failure错误。仔细分析记录文件scrapy.log,发现是在下载图片时变慢的。原因是Scrapy使用了twisted作为异步网络库来处理网络通讯。当下载缓慢时,twisted异步请求发生错误,出现一系列的错误回调(errback)或者错误回调链(errback chain),错误会传递给下一个errback,errback不返回任何数据。而twisted的Deferred对象会使回调函数把None作为参数返回,从而导致出错。
根据爬取的信息得到表1所示的测试结果表。
根据表1可得到图4所示的柱状图,在爬取1小时内可以明显的看出网速一般与网速较好时的差异,网速较好有一定的提升了爬虫的速度以及下载的数量。
为了观察网速对实验测试产生的影响,下面针对GitHub网站的爬取测试定在早晨6-7点钟(6MB/S)左右进行测试,得到表2所示的结果。
图5是根据表1与表2制成的柱状图,可以直观的看出网速在很好(6MB/S)的情况下,1小时内爬虫的速度与下载的信息数据比网速一般、较好时产生的数据多。为保证数据的准确性,上述测试前后进行了30余次,取平均值。
综上,可以得出网速与爬虫爬取的信息数量的快慢有关,但是下载的用户信息数量与爬取用户(有重复)的比率是差不多的,从开始的51%左右到1小时内下降至39%下载率。这也跟每个人的关注度有关,若两人互相关注,重复的抓取下来分析发现有的已经下载好了,当然这是不可避免的。
4 结语
基于Python的Scrapy框架设计并实现了GitHub爬虫,从技术上为一些数据研究们提供了方便的网络上数据获取方法。主要特点:
(1)使用方便,只需提供一个用户的主页面URL就能利用本文爬虫抓取GitHub网站中大规模用户信息;
(2)支持数据库,所有抓取的信息都保存到MongoDB数据库中,利于统计查询;
(3)支持大范围地爬取用户信息,从一个用户的URL可得到多个关联用户的URL从而衍生出大量用户;
(4)图形界面操纵方便。当所有的数据都爬取下来时,可以下载任何用户的热门项目。
本GitHub爬虫在处理重复爬取用户信息方面,采取了按名字判断的方法,使重复爬取的次数得以明显减少,但是抓取下来的用户信息也随之减少了,该问题尚须进一步探索和改进。
(通讯作者:殷旭东)
参考文献
[1]邬贺铨.大数据时代的机遇与挑战[J]. 中国经贸,2013(7):32-32.
[2]GitHub中国开发者年度报告{2014}[EB/OL].[2015-02-03] http://githuber.info/Report.
[3]Manning爬虫技术浅析[EB/OL].http://drops.wooyun.org/tips/3915.
[4]赵鹏程.分布式书籍网络爬虫系统的设计与实现[D].西南交通大学,2014.
[5]赵志.基于NoSQL的BRS系统的设计与实现[D].上海交通大学,2013.
[6]Scrapy研究探索(七)——如何防止被ban之策略大集合[EB/OL].[2014-06-29] http://blog.csdn.net/u012150179/article/details/35774323.
[7]黄聪,李格人,罗楚.大数据时代下爬虫技术的兴起[J].计算机光盘软件与应用,2013(17):79-80.
[8]Twisted 15.4.0 documentation[EB/OL]. http://twistedmatrix.com/documents/current/core/howto/defer.html.
作者简介
赵本本(1995-),男,常熟理工学院计算机科学与工程学院本科在读学生。
殷旭东(1970-),男,硕士学位。现为常熟理工学院计算机科学与工程学院工程师。CCF会员。主要研究方向为移动计算、信息安全。
王伟(1987-),男,硕士学位。现为苏州市浪潮电子信息有限公司工程师。主要研究方向为信息安全、大数据。
作者单位
1.常熟理工学院计算机科学与工程学院 江苏省常熟市 215500
2.苏州市浪潮电子信息有限公司 江苏省苏州市 215002
