一种clock mesh与H—tree混合时钟树设计方法
2016-05-14伍艳春
伍艳春
摘 要本文提出了一种clock mesh与H-tree相结合的混合时钟树设计方法,同时通过对设计中的寄存器按照一定规则进行分组并分别布局在相同大小的网格中从而具备一定的对称性和规则性,可更好的优化H-tree结构,提高H-tree的性能从而提高了整个混合时钟树的性能。实验表明,该混合时钟树结构可显著减少时钟树长度和时钟分支间的skew,降低OCV影响。
【关键词】clock mesh H-tree 寄存器组布局 clock skew
1 引言
随着芯片规模的不断增大,设计复杂度的不断提升,同种工艺下对性能追求的极限化,时钟网络的分布越来越重要。如何减小时钟skew、降低OCV影响,对时钟树综合来说,是个严峻的挑战。业界常用的时钟树设计方法有很多种,比如H-tree、二叉树、clock mesh、鱼骨等,其中H-tree的时钟偏斜skew小,但对设计的规则性要求严格;clock mesh的时钟树长度小、延时小、OCV影响小,但局部时钟偏斜较大。为了充分利用这两种时钟树结构的优点,本文提出了一种混合时钟树设计方法,能有效的减小时钟偏斜skew、降低OCV影响。
2 混合时钟树结构
混合时钟树结构如图1所示。它主要由三部分组成:H-tree结构pre-mesh、clock mesh、H-tree结构local tree。因其包含不同的时钟树结构,故称之为混合时钟树结构。
该混合时钟树先通过H-tree结构将时钟源分布到clock mesh上,clock mesh上的时钟以就近原则连接到附近的local tree起点,local tree再通过H-tree结构将时钟信号分布到每个寄存器的时钟端;同时,由于local H-tree末端驱动的寄存器布局经特殊处理后具有一定的对称性,可更好的优化H-tree的性能。因到达每个寄存器的pre-mesh H-tree和local H-tree的级数基本相同,clock mesh又将时钟信号在全局范围内均匀分布,从而可保证时钟源端到各寄存器的时钟树长度基本均衡,时钟偏斜很小;同时,通过对寄存器进行分组,将存在时序关系的寄存器集中布局在局部区域,共享同一个时钟树分支,由于同一时钟树分支中共同的时钟路径很长,OCV影响很小。
3 设计方法及实例
本章节详细描述了在一个40nm工艺、面积为3200um*6200um的设计中运用该混合时钟树结构的具体方法,并通过PT时序分析说明了该时钟树结构时钟路径短,latency、skew很小等优点。
3.1 寄存器组布局
local tree设计采用H-tree结构。但H-tree对其所要驱动的寄存器布局有严格的要求,要求其布局尽量具有对称性,这样才能更好的保证H-tree长度的均衡性,时钟skew才会更小。因此,在进行local H-tree设计前,需先对设计中的寄存器进行处理,让寄存器以一定的规则布局在规整的局部区域内。本文采用的方法是:
(1)将设计中的寄存器按一定的规则如按命名规则进行分类,将具有相同名称前缀的寄存器聚成一类。为了让H-tree结构的驱动能力更强、时钟树延时更短、时钟skew更小,每一聚类最多只能包含一级ICG单元(可以无ICG),寄存器数量必须在5与64之间。
(2)寄存器分组完成后,将每个寄存器组分别创建group bound,通过设置合适的利用率如90%指导工具将bound内的寄存器集中布局在一定大小的范围内;针对相邻bound距离过小、内部寄存器数量过少的情况,需依据一定的规则如间距大小、寄存器数量等对相关bound进行合并,合并后的寄存器布局更集中,每个bound内部寄存器的数量更均衡(其数量必须不大于64个)。
(3)寄存器布局规则化,将die以一定大小的网格grid(比如(20倍row height)宽*(16倍row hight)高,grid面积基本为64个寄存器的面积)进行网格状划分,对每个bound的位置进行微调,保证每个bound中心点均位于grid内,每个grid内最多64个寄存器。
通过上述处理后,每个寄存器组均布局在相同大小规则的grid内,且每个寄存器组内寄存器数量基本均衡,grid的规则化,为每一个local H-tree分支的对称设计提供了前提条件。
3.2 local H-tree设计
由于每个local H-tree的分支只需驱动其grid内最多64个寄存器,因此,local H-tree只需要两级驱动,分别为sink buffer tree和grid buffer tree:
(1)sink buffer tree:每个grid分成上下左右共四个小网格,每个小网格内包含16个寄存器,每个小网格内插入一个sink buffer,用于驱动16个寄存器;为了平衡该sink buffer到16个寄存器的tree长度,将该sink buffer布局在16个寄存器布局位置的中心。
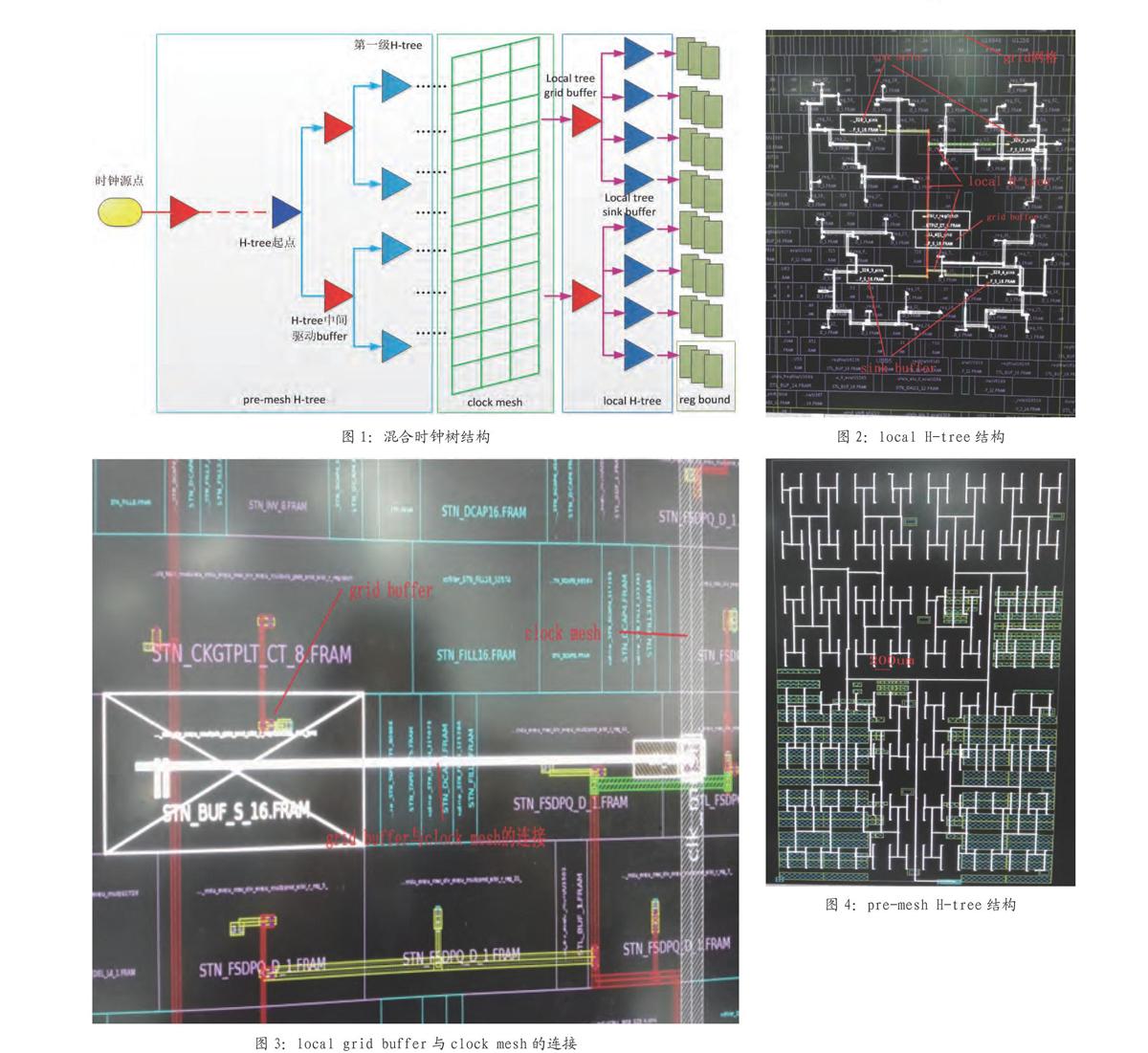
(2)grid buffer tree:每个grid内均有4个sink buffer,为了驱动这四个buffer,需要在每个grid内部插入一个grid buffer,作为local H-tree的起点。由于该grid buffer直接与clock mesh相连,针对grid内有ICG单元的情况,将该grid buffer插在ICG单元之前,如果grid内没有ICG单元,为了平衡各local tree分支间的级数,需先在4个sink buffer前插入一级专门用来平衡ICG单元的buffer,再在该buffer前面插入grid buffer,grid buffer布局在每个grid的中心,以此平衡grid buffer到4个sink buffer之间的距离
如图2所示,是local H-tree在一个grid内的分布示意图。Grid为图示黄色线内区域,grid buffer布局在grid中间位置,其驱动的4个sink buffer分别位于各自驱动的16个寄存器的中间位置,grid 与 sink buffer以H-tree的结构进行时钟走线,grid buffer作为local tree的起点,在clock mesh布局后,将与附近的clock mesh相连,完成local tree与clock mesh的连接。
3.3 clock mesh与pre-mesh H-tree设计
clock mesh与电源网格类似,设置好clock mesh横纵向金属层,网格宽度、网格间隔等约束,使用命令create_clock_mesh即可完成clock mesh的创建。
时钟源到clock mesh的分布,采用pre-mesh H-tree结构,本文采用的设计方法如下:
(1)pre-mesh H-tree级数的计算:为了更好的驱动clock mesh,pre-mesh最后一级H-tree buffer数量必须足够多,至少每200um左右需插入一级clock buffer。级数与buffer间距的关系如下公式所示:buffer间距=die(宽)/2H-tree(级数)。
(2)pre-mesh H-tree的分布:先从clock port端插入一级buffer,将该buffer布局在芯片中央位置,作为H-tree的起点;再从该起点插入相应级数的H-tree buffer,每一级buffer驱动其后一级的4个buffer,这四个buffer分别位于该buffer的上下左右四个点,形成H结构,H结构的横向间距=die宽/2该级H-tree级数,纵向间距= die高/2该级H-tree级数。
(3)H-tree结构纵向中心buffer的插入:为了让h-tree结构的时钟走线呈H结构,也为了更好的驱动能力,需分别在每级四个buffer的纵向中心点插入一级buffer,该buffer与前级buffer处于同一水平线上。
(4)驱动buffer的插入:当H结构纵向buffer间距过大、驱动能力不够时,需以一定间隔(如每200um左右)插入一个驱动buffer,以满足每两个互连buffer之间的驱动能力。
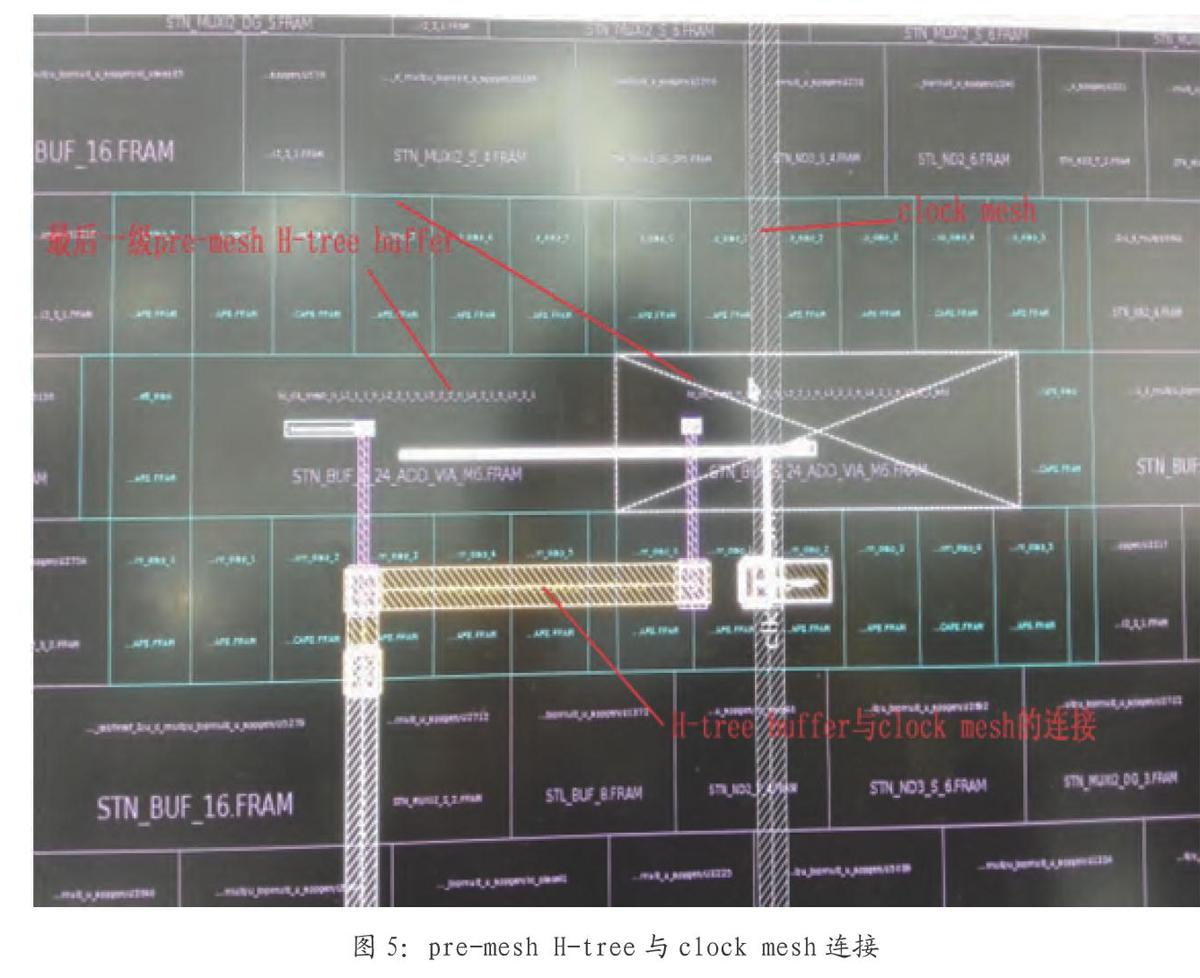
(5)当H-Tree结构完成后,将最后一级buffer的输出连接到clock mesh上,完成premesh H-tree与clock mesh的连接。
如图4所示,是pre-mesh H-tree的分布示意图及pre-mesh与clock mesh的连接示意图。pre-mesh H-tree共有5级驱动,最后一级驱动buffer以大概200um的间距均匀的布局,该级buffer的输出以就近原则连接到周围的clock mesh上。
3.4 混合时钟树延时结果
由于pre-mesh H-tree结构最终驱动同一根clock net(clock mesh),布局布线工具目前无法获取从时钟源到clock mesh之间各分支的clock延时,本文通过第三方电路仿真分析工具Hspice来获取clock mesh的延时信息。具体的分析方法如下:
(1)在布局布线工具中分析clock mesh电路结构,生成clock mesh spice网表及相应的measure文件,并收集需要独立使用仿真工具分析的clock net和clock cell,将其加到生成的measure文件中。
(2)使用Hspice仿真工具,输入1)生成的相关文件,以SDC文件格式计算并生成可被布局布线工具识别的延迟信息,完成clock mesh电路的延时计算。
(3)将生成的sdc 文件加载到布局布线工具中,即可完成clock mesh电路延时的反标。
将clock mesh的延时信息在PT中进行反标兵分析整个是钟树的latency及skew,发现时钟skew很小,在30ps以内。
4 总结
本文通过综合考虑各种时钟树结构的优缺点,提出一种混合时钟树结构,该结构由pre-mesh H-tree、clock mesh、local H-tree三部分组成,并通过对设计中的寄存器按照一定原则进行分组处理并集中布局在指定大小的grid内,保证了H-tree的设计规则性,从而更好的优化了H-tree的性能。本文结论表明,该时钟树结构可显著减少时钟树长度、增加同一grid内时钟树的共同路径长度从而减少OCV影响,同时能很好的均衡不同grid内各时钟树分支,减少时钟skew。
参考文献
[1]陈彦白.Fishbone和CTS时钟树的比较[D].上海 :复旦大学,2008.
作者单位
南京电子技术研究所 江苏省南京市 210039
