大数据视阈下档案学研究的困境和启示
2016-05-14王晨李耀庭
王晨 李耀庭
摘要:基于对CNKI档案类期刊的统计分析,本文探讨了大数据在我国档案领域内的研究现状,分析当前档案管理技术同非结构化的数据管理、资源转化效率同发挥档案的潜在价值、数据挖掘深度同个性化的用户利用需求之间的困境,并结合大数据理论指出其带给档案学研究的相关启示。
关键词:大数据档案学研究统计分析档案管理
Abstract:Based on the statistical analysis of ar? chive journals from CNKI, the paper discusses the research status of big data in the field of archives and points out the dilemma between archives man? agement technologies and unstructured data man? agement, resources conversion rate and exertion of potential value of archives, depth of data mining and personalized user needs. The paper also bring out some relevant enlightenment combined with big data theory.
Keywords:Big data;Archives science study; Statistical analysis; Archives management
所谓“大数据”,是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。它不单单指字面意义上规模庞大的数据量和数据集合,在认知和应用过程中更应将其理解为一种思维和管理方式,一种新的技术和数据管理视角。其实,无论将大数据看作复杂的数据集合,还是数据管理的思维方式,它的出现都是由数据的量变积累到一定程度引发的“质变”。近年来,各行业研究的重点都集中在“大数据”上,档案学的相关研究也开始聚焦大数据。我国档案学领域明确提出有关大数据的研究是在2012年,目前相关研究仍然集中在档案领域对大数据本身的认知上。鉴于此,本文从大数据在我国档案领域内的发展入手,并结合CNKI档案类期刊的共词聚类分析,探讨大数据对档案学研究带来的机遇和困境以及对我国档案事业发展的思考。
一、基于档案大数据研究的统计分析
(一)数据获取及处理
以CNKI中国学术期刊全文数据库为来源,以“大数据”和“档案”为主题进行检索。截至2016年5月,检索到2011~2016年的相关文献共计501篇。笔者从中选取研究的核心样本,并以此为依据分析档案学领域大数据研究的总体现状与核心热点。首先从501篇文献中剔除重复条目以及与档案大数据研究明显无关的学术论文和新闻报道后,得到文献456篇。然后,再按照来源刊物对456篇文献进行筛选,勾选出文献来源为档案类期刊、大学学报以及档案学相关会议和学位论文的,共得到281篇文献。最终以281篇文献样本作为档案学研究的核心样本,统计高频关键词。剔除“大数据”(99次)与“档案”(21次)后,得到排名前十位的高频关键词,其分别为档案信息(39)、档案管理(39)、档案数字化(32)、档案工作(26)、数字档案馆(22)、档案利用(19)、物联网(17)、档案事业(15)、信息技术(14)、档案管理模式(13)。
(二)关键词分析
共词聚类分析法,是通过对文献集合中“词汇对”共同出现的情况来构建共词矩阵,然后对矩阵进行聚类分析,从而确定该文献集合与所代表主题之间的关系,进而描述该学科的研究热点和发展趋势。为了较好地归纳出研究重点,在进行共词聚类分析时,先要找出关键词,进而构建共词矩阵。
1.构建矩阵。对核心样本所统计出的高频关键词两两配对,统计其在样本文献中出现的频率,建立共词矩阵,如表1所示。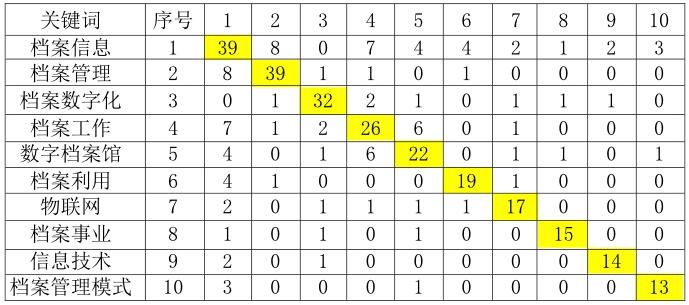
利用Ochiia系数,将共词矩阵转换为相关矩阵,以减少统计频次的悬殊对分析结果所造成的影响。矩阵中的数字表示两个词之间的相关度,数值越大,表示二者之间的相关程度越高。其中,相关度较高的有档案信息与档案数字化(0.3963)、档案信息与物联网(0.3107)等。如表2所示。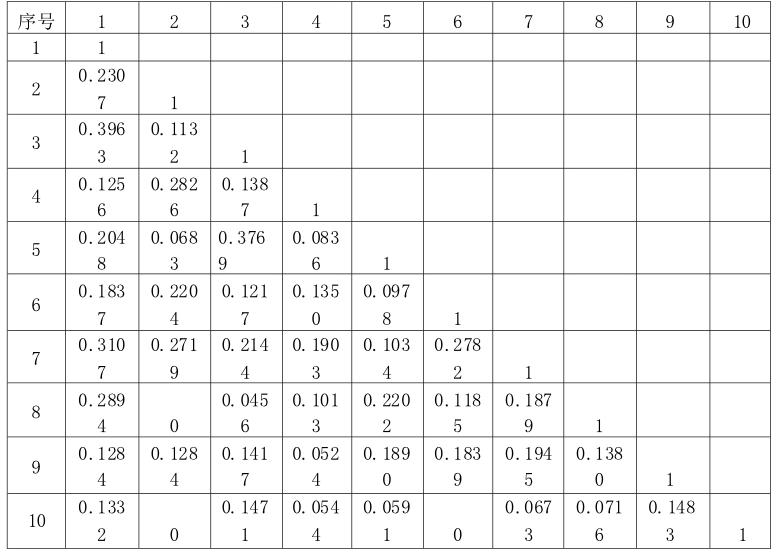
2.聚类分析。在以高频关键词为基础建立的共词和相关矩阵上,利用SPSS软件对其进行聚类分析,可以得出在大数据背景下我国档案学研究的聚焦点和关联点。将表2的相关矩阵导入SPSS进行层次聚类分析,选择“组间平均链锁距离”,生成平均联接树状图。该方法能够将关系密切的对象聚合到一个小分类,稍远的聚合成大分类,最终形成一个树状系统。从图1中可以看到,关键词1(档案信息)和3(档案数字化)二者距离最近、关联最紧密,可聚合为一类;稍远的组合有关键词2(档案管理)和4(档案工作)、6(档案利用)和7(物联网),这两组分别合并后又汇聚成一个研究大类。
3.结论分析。通过共词聚类分析,可以将目前研究热点归为以下几类:(1)档案数字化及资源管理(关键词1、3和5)。大数据背景下我国档案学研究所关注的首先是作为基础的档案资源管理,主要是针对数字档案馆、档案数据库存储以及电子文件管理等方面的探讨,同时也涉及对非结构化信息及各类电子文件如何统一标准的问题研究。(2)档案价值开发及利用(2、4、6和7)。从档案人、档案资源开发整合以及档案相关信息技术等角度,实现对档案资源的多元化开发,这些开发在该大类中显得较为突出。另外,物联网等技术不可避免地将成为未来档案价值实现的途径。(3)档案事业及档案管理模式(关键词5、8、9和10)。与相关矩阵所反映问题类似的是,我国档案领域的大数据研究集中在档案工作与管理的宏观思想上,偏重管理模式创新实践和业务探讨。尤其是在城建和高校档案等领域对档案管理全过程的理论探讨与模式创新经久不衰。
综上所述,我国档案学领域对大数据的研究总体还处在起步和探索阶段,偏重对实践业务工作的探讨,而档案资源开发利用和基础理论研究的底子相对薄弱。究其原因,这与我国档案学发展现状在技术、思维和资源层面所存在的问题密切相关。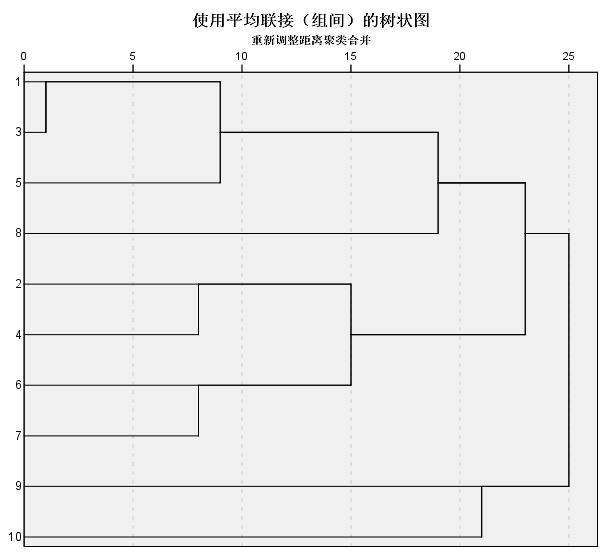
二、大数据背景下我国档案学研究的困境
大数据既为档案资源管理提供了良好的发展机遇,又不可避免地凸显出我国档案学研究领域的困境。基于上述大数据相关研究的统计和共词聚类分析结果,笔者对核心样本的研究内容做了深入的归纳总结,结合我国的档案管理现状不难发现,在该领域的关注焦点同时也正是档案学目前亟须解决的问题所在——档案资源管理及数字化、档案的价值转化与开发利用以及档案数据挖掘和个性化服务模式。从这个角度而言,笔者认为我国档案学研究在大数据背景下存在以下三大困境:
(一)现有的档案管理技术难以解决非结构化的数据管理
作为人类社会信息资源的“最终归宿”,档案的存储和管理始终是档案工作的重中之重。尤其在信息时代数据规模呈几何级增长,数据结构也开始变得复杂化和多样化,来源丰富且非结构化的碎片数据对传统数据库造成了极大冲击。以目前我国档案管理水平的现状而言,涉及大数据核心的分布式存储和并行处理等相关的云技术还没有得到普及利用,异构数据的互联互通问题还没有得到妥善解决,档案工作的管理实践还没有跟上技术发展,这种档案管理思维和技术的相对滞后直接导致了现有档案管理水平同档案管理需求之间的矛盾。
(二)现有的资源转化效率难以发挥档案大数据的潜在价值
就我国档案馆目前的资源转化和利用现状而言,一方面档案的数字化进程还处于建设时期,对大多数实体档案的利用依旧只能停留在人工挖掘档案价值的阶段,难度较大且标准各异;另一方面,现有的档案存储容量限制、管理成本限制和保管期限表的鉴定机制决定了部分低值档案需要定期销毁。对于这部分档案而言,大多在还没有达到凸显其潜在价值的外部环境时便已进入了死亡期。从长远角度看,这部分档案并非是因完全失去利用价值而被销毁的,只是在现有的技术条件和鉴定标准下无法发挥其潜在价值。正是上述两方面的问题使得我国档案馆的资源转化率长期处于较低的水平,在数据规模更加膨胀的今天,这样的不相匹配将很难发挥档案作为社会真实历史记录所蕴含的巨大潜在价值。
(三)现有的数据挖掘深度难以支撑个性化的用户利用需求
随着对信息资源关注的深入,公众对档案的开放和利用提出更多个性化的需求。进入大数据时代后,馆藏中越来越多的档案资源将不再作为“最终产品”直接面向公众,而是逐渐转变为基础资源,并协同其他相关的信息资源一起,经过更深层次的数据挖掘和分析,形成新的知识供其利用。但反观当前我国档案馆的情况,对大数据相关技术的研究和应用起步略晚,大多数档案馆的主要职能仍旧停留在以“保管为主”的档案资源管理模式上,档案资源的整合加工和统计分析较少涉及,这样的模式将很难满足新时期公众对档案开放利用的个性化需求。
三、大数据对档案学相关研究的启示
从CNKI来源的期刊统计分析可知,目前我国档案事业的大数据研究更多地集中在应用领域,在理论基础上显得相对薄弱。但是,仍然可以看到的是:“大数据时代科研范式的转变促使数据利用和服务的需求也相应发生了变化。”在这样的背景下,结合大数据背景下档案管理的挑战和困境,从用户需求出发,探索大数据的基础理论和档案学相关理论的结合点,是能够对档案学的相关研究以及档案馆的发展有所启示的。
(一)大数据对“相关关系”的探索,或将拓宽全宗内部档案及全宗之间的关系边界
同一来源的档案往往保持密切的关联性,从宏观角度来看,过去所收集的全宗内部各主题或年份的档案之间形成的是一个小型相关的关系网络。目前对档案的管理也更多地集中在全宗内部的这个关系网络里,然而大数据的出现加深了对“相关关系”的探索,拓宽了关系联结的边界。在对海量信息的处理过程中,全宗之间一些微弱、隐秘的“相关关系”开始有能力被挖掘出来并表现出一定的价值。通过这些“相关关系”的联结点,档案馆不仅可以强化全宗内档案的垂直关联性,甚至也可以在全宗与全宗之间建立起相应的横向交流关系联结,从而打造出一个畅通无阻的档案信息资源集成网络。如此一来,档案工作者完全可以通过档案管理系统对馆内档案信息资源有一个更加系统、直观和全面的认知,从而为档案的搜集整理和检索利用创造更加高效的体系,提供更多的便利。
(二)大数据对全数据的关注,或将延长非永久保存电子档案的保管期限
过去档案保管期限的设置受到档案自身价值和外部环境因素(档案馆的馆藏空间、容量以及其他相关条件)的影响,需要定期对不具有永久保存价值的档案进行销毁。随着科学技术的进步,电子档案逐渐取代纸质档案成为档案资源的主力军;而大数据的支撑技术又恰好解决了大规模数据的存储和处理问题,这也就意味着档案馆的数字化进程已无存储空间和馆藏限制的后顾之忧。与此同时,基于随机采样的统计分析方法缺乏延展性的弊端,大数据思维开始倡导建立“样本=总体”的全数据信息库,利用其强大的数据分析功能针对事实数据本身而非随机样本去进行计算和分析。这样,在档案学研究的领域里,档案价值鉴定的标准和体系将会随着“全数据”模式的出现而受到强烈冲击。对于那些即便达到保管期限、看起来价值甚微的抑或是存在错误、残缺不全的电子文件,都有可能会被发掘出新的潜在价值,并且应该在“全数据”模式下的数字档案馆内获得一席之地,而不再受到保管期限的过多约束。
(三)大数据对关联数据进行共享和深度挖掘的需求,或将反作用于现有的档案信息咨询服务模式
目前的档案信息咨询服务仍处于“你问我答,你用我取”的被动模式,用户对档案的利用需求往往受限于档案馆现有的载体形态和馆藏资源,尚且无法得到综合性的档案信息和统计结果。在大数据时代,数据化的电子档案将逐步替代纸质档案和数字化档案成为主流。通过利用大数据对碎片化档案信息的收集整理以及对相关数据信息的共享与深度挖掘,档案馆一方面可以结合用户在互联网中的社交关系,打破社交媒体同档案馆之间所存在的共享缺陷,并把碎片化、非结构化的信息资源(包括用户在社交媒体上的行为数据)整合转化为全面的量化数据,从而提前对用户的利用行为和需求做出分析和预判,变被动提供为主动“出击”。另一方面,这种对数据化信息的共享和深入挖掘可以在实际提供利用时,根据用户提出的要求,在满足用户基本信息需求的前提下主动向用户展示综合性的统计分析结果而非简单的档案调阅。同时,在大数据强大的数据关联和分析能力中加入用户反馈,实现档案咨询的智能改进将不再遥远。目前,韩国国家档案馆便在此基础上借助信息技术的发展和用户服务的推进,成功开发出了大数据时代下基于社交网络的档案信息服务新模式。
参考文献:
[1]樊树娟.大数据时代的社会变革与档案职业发展探析[J].档案管理,2014(10):17-19.
[2](英)维克托·迈尔-舍恩伯格,肯尼斯·库克耶.大数据时代:生活、工作与思维的大变革[M].杭州:浙江人民出版社,2013:29-71.
[3]陈玲霞,田湘平.大数据时代档案资源管理探讨[J].云南档案,2014(10):50.
[4]储节旺,郭春侠.共词分析法的基本原理和EX? CEL实现[J].情报科学,2011(6):932-934.
[5]李长玲,翟雪梅.我国情报学硕士学位论文的共词聚类分析[J].情报科学,2008(1):73-76.
[6]张健.档案数据库“胀库”问题研究[J].档案学通讯,2012(4):50-51.
[7]王建亚.大数据背景下档案工作的机遇、趋势与挑战[J].北京档案,2014(5):25-27.
[8]周枫.国内档案学领域“大数据”研究述评[J].档案,2014(6):9-12.
[9]刘守华.迎接大数据时代的呼啸而来[J].中国档案,2013(11):1.
[10]吴丹,于文婷.近五年国内外图书情报学教育研究进展与趋势[J].图书情报知识,2015(3):4-12.
[11]王兰成.大数据环境下档案与图书情报信息集成服务机制的构建[J].档案与建设,2014(12):4-7.
[12]武云.利用大数据创新档案管理模式和提升服务能力[J].档案与建设,2015(1):35.
[13]张峻山.基于社交网络的档案信息服务新模式——韩国国家档案馆的实践[J].档案与建设,2015(7):35-38.
