二度人脉聚类算法设计
2016-05-14张保龙黄海燕
张保龙 黄海燕


摘 要: 针对整个复杂CLASS全属性聚类的聚类算法在聚类算法中有较为复杂的实现要求,试图对社交软件中较为复杂的CLASS?USER进行整体聚类计算,难度在于将其复杂属性体系整合成高维度变量进行降维处理。通过多次连续的数据整理,特别使用了二维模糊矩阵与排序算法实现快速降维,将高达13维的高维度变量进行降维处理,最终形成一维变量,最后使用常见的K?means聚类算法对该一维变量进行聚类分析。
关键词: 全属性聚类; 社交软件; 聚类算法; 人脉分析
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2016)09?0126?02
Abstract: Since the whole complex CLASS full?attribute clustering algorithm in clustering algorithms has complicated implementation requirement, the overall clustering computation for the more complex CLASS?USER in social software is tried to carry out, which is difficult to integrate the complex attribute system into the high dimensional variables for dimension reduction processing. The ranking algorithm of two?dimensional fuzzy matrix is particularly used to fast reduce the dimension by means of repeatedly continuous data processing. The dimension reduction processing for the high dimensional variables with 13 dimensions is conducted to form the one?dimensional variable. And then the cluster analysis for the one?dimensional variable is conducted with common K?means clustering algorithm.
Keywords: full?attribute clustering; social software; clustering algorithm; contact analysis
0 引 言
现阶段,人脉分析功能已经成为当前社交软件中的必备功能[1]。为社交软件设计更加科学的二度人脉推荐算法,已经成为当前人脉大数据分析的重要任务。一定程度上,人脉分析智能化程度是评价社交软件智能化程度的重要指标[2]。本文软件是用于在线社区系统的内置交互软件。本文的设计任务是在当前社区系统USERMNG下设计二度人脉聚类算法,以分析用户非主动好友关系中与其关系更密切的用户。
1 需求分析
1.1 分析本文系统当前的系统模块
虽然系统目前基于手机APP运行,但其背景数据库来自1997年建立的BBS系统,所以系统与传统的交互软件不同,系统由论坛部分、留言板部分、个人博客部分三个交互板块构成交流框架。其中论坛部分所有内容都可以被所有用户浏览且可以由所有用户回复,留言板部分仅可由留言相关的双方浏览和回复,个人博客部分仅可由发帖人指定的用户浏览和回复[3]。
1.2 分析挖掘数据来源
本文一度人脉来源分析用户的好友列表,分析该好友绑定的手机号码是否存在于用户的手机电话本中,从而对好友进行一次聚类。
本文分析好友浏览和回复其帖子的数量,同时分析用户浏览和回复好友帖子的数量。分析每天的访问量走势。可挖掘数据来源如图1所示。
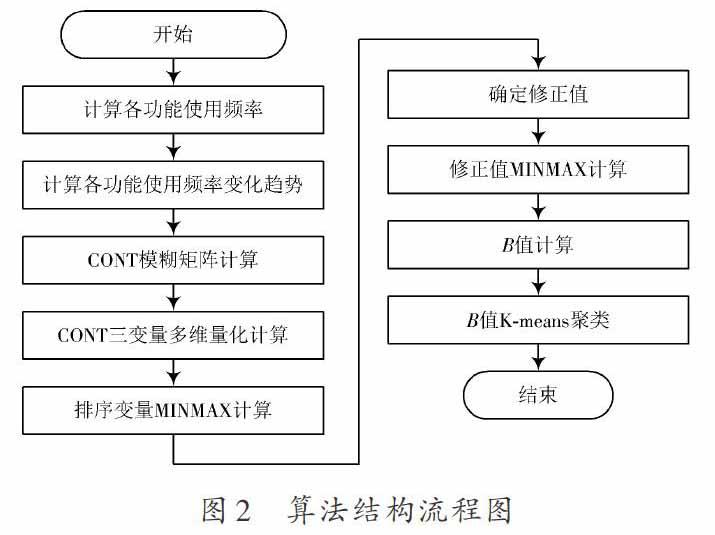
2 算法设计
2.1 习惯相似性排序
因为本文系统已经限定每个用户最多拥有500个好友,所以,本文算法的CPU压力并不大[4],人脉树结构较为单一,所以,本文并不采用神经网络算法[5],而是采用模糊矩阵算法对用户的二度好友进行归类和推荐。
设计三个变量限定每日用户使用三个功能的频率:USER.BLOG.RATE判断用户使用博客功能的频率;USER.BBS.RATE判断用户使用论坛功能的频率;USER.MSGBD.RATE判断用户使用留言板功能的频率。
3 总 结
本文算法是常用算法的顺序组合,通过该算法,可以使用较小的CPU和RAM资源实现复杂环境下的CLASS聚类[11]。因为本文使用的CLASS?USER是一个13维度的高维度变量,本文使用8步计算将其降为[0,1]区间上的一维变量[B]值,给最后针对该[B]值的K?means聚类提供了前置条件。
参考文献
[1] 刘婉.K?means在PHP环境中的应用实践研究[J].电脑爱好者,2014(3):124?126.
[2] 张庆东.探索网页脚本中实现K?means聚类的有效途径[J].软件学报,2013(2):66?68.
[3] 胡夏玲.老旧社区网站实现手机APP端转化方法研究[J].系统仿真学报,2015(1):34?36.
[4] 胡正峰.手机APP服务器端数据挖掘方法研究[J].模式识别与人工智能,2014(6):91?93.
[5] 张启琪.二度人脉计算方法研究[J].软件学报,2014(5):98?99.
[6] 李旭东.神经网络在二度人脉分析中的应用途径研究[J].电脑爱好者,2012(1):45?46.
[7] 赵红霞.分析K?means与神经网络在二度人脉分析中的软件效率差异[J].模式识别与人工智能,2014(6):77?78.
[8] 张玲.常见二度人脉分析算法的软件效率研究[J].系统仿真学报,2014(4):36?37.
[9] 刘勇.二度人脉分析算法占用CPU资源的解决方案研究[J].模式识别与人工智能,2014(3):56?57.
[10] 万红.较大用户群的用户数据资源挖掘方式研究[J].电脑爱好者,2013(6):98?99.
[11] 张霞.分析有限CPU资源模式下的非神经网络算法在大数据挖掘中的应用[J].软件学报,2015(3):128?129.
