云平台下的NoSQL分布式大数据存储技术与应用
2016-05-14吴燕波薛琴向大为麦永浩
吴燕波 薛琴 向大为 麦永浩


摘 要: 随着移动互联网云计算、大数据的快速发展,以图片、视频等组成的数据存储急剧增加,目前已有存储方式无法满足系统需要,而NoSQL分布式大数据存储技术因其具有可扩展、快速读取、海量处理等特点,其在云计算领域如雨后春笋般被广泛应用。采用基于Hadoop平台和NoSQL的MongoDB数据库技术设计非结构化数据云存储架构,证明云存储的非结构化数据存储技术可缓解当前非结构化数据存储面临的难题,提升非结构化数据存储服务质量。
关键词: Hadoop云存储平台; MongoDB数据库; 非关系型数据库; 云存储
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2016)09?0044?04
Abstract: Since the mobile Internet cloud computing and big data are rapidly developed, and data storage composed of pictures and videos is sharply increased, the existing storage methods can′t satisfy the system requirement. The NoSQL distribu?ted big data storage technology is widely used in cloud computing field due to its characteristics of extensibility, fast read speed and mass data processing. The unstructured data cloud storage architecture was designed with MongoDB database technology based on Hadoop platform and NoSQL. The unstructured data storage technology of cloud storage can alleviate the difficulties exiting in the current unstructured data storage, and improve the service quality of unstructured data storage.
Keywords: Hadoop cloud storage platform; MongoDB database; NoSQL; cloud storage
随着Web 2.0技术的发展,越来越多的非结构化数据比如文档、图片、音乐、视频等产生。IDC研究表明:当前企业中有80%是非结构化数据,并且以60%的增长率在不断增加。如何突破传统技术,实现大规模数据高效存储和利用管理是当前面临的重大挑战。
1 NoSQL数据库技术
非关系型数据库(NoSQL)是一种全新的非关系型分布式存储技术,该数据库数据不但包括日常的文本数据,还包括如图片、视频、FLASH动画等其他数据,因其具有海量存储、灵活易用、高并发等特点,可以为系统提供一个可扩展的松耦合类型数据模式,该模式严格遵循CAP定理,能够很好地支持非结构化数据的存储,满足高并发读写需求,具有很好的扩展性。
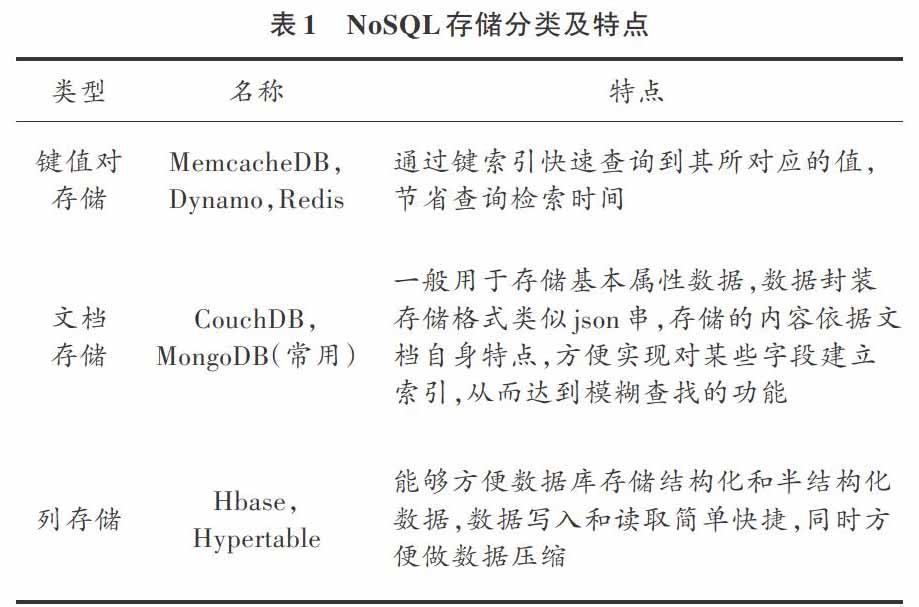
目前的NoSQL数据存储主要包括以下几种,具体见表1。
(1) 键值对存储。通过对提供的键值对数据存储,能够很好地满足系统的读写需求,例如MemcacheDB,Redis,Dynamo。
(2) 文档数据存储。能够高效满足系统的海量数据存储和访问需求,目前的存储主要包括MongoDB和CouchDB等,能够很好地提高海量数据存储的访问效率。
(3) 面向列存储。在面向列的存储系统中,数据以列为存储单位。相同列的数据存储在一起,从而支持列的动态扩展,对某一列或某几列的查询具有明显的I/O优势。典型代表有Hbase,Hypertable等。
2 MongoDB数据库
MongoDB数据库不但能够通过系统的键值对存储提高其快速写入和读取,而且能够很好地兼容传统关系型DBMS功能,它主要可以提供一种功能强大、灵活、可扩展的无结构的存储方式,该存储方式采用松散的BSON数据结构进行存储。
MongoDB的主要特性如下:
(1) 扩展性好:MongoDB数据库在设计初期,首先考虑到数据库的扩展问题,通过采用无模式的存储结构可以快速对服务器进行自动分割。采用MongoDB数据库的自动分片机制,可以实现集群中数据的动态负载均衡。
(2) 数据存储丰富多样化:MongoDB是面向文档的数据库,MongoDB抛弃关系存储模型,用户在进行添加模块时不用事先定义,即可横向灵活的更改数据模型。
(3) 检索功能丰富:该数据库不但支持辅助索引,而且方便存储JavaScript脚本和MapReduce等模式。
(4) 性能引擎优良:MongoDB数据库中的文档数据可以动态扩充,通常先将存储引擎配置到内存映射文件中,实现数据文件进行预分配,然后通过采用空间转换的形式,确保数据库的性能稳定。
(5) 配置管理便捷:MongoDB数据库为提升系统的可靠性和稳定性,通常采用服务器自身机制完成配置功能。MongoDB数据库的核心是文档数据,每个文档数据中的字段名和值一一对应存放在表中。可以通过MongoDB数据库实例方便管理相应的数据库表。
图1为MongoDB的分布式存储架构。
2.1 分片
在MongoDB数据库中,每个分片均由一台或多台服务器构成,该服务器的功能主要是通过运行MongoDB进程实现数据的存储。但在实际环境中,为了提高系统的可靠性和实现自动故障恢复,每个分片可以独立看作是一个replica set,replica set从本质上来讲,它是一种异步的主从复制机制,每个replica set至少包括一个主节点和一个以上副节点。主节点主要负责数据的写入,副节点主要负责数据的读取。replica set中两类节点之间通过oplog保证数据的一致性,所有操作数据及时间戳都会被写入oplog,因其大小固定,所有的副节点均会监听oplog的变化情况,以实现与主节点的同步。replica set通常能够实现两个以上子节点的故障自动恢复。
2.2 配置服务
配置服务主要用来存储MongoDB数据库集群的元数据信息,这些元数据信息来源于两方面:一部分是分片服务器上的集群信息;另一部分是该分片集群服务器上的文档数据和集合信息。每一个配置服务信息中都包括了MongoDB数据库中的群集信息,通常采用一个两阶段协议实现相互之间的通信,确保配置信息的一致性。配置服务器目前拥有自己的复制模型,可以对集群元数据信息备份。当任何一个集群服务器发生宕机时,集群中的元数据就自动变为只读状态,通过此种方式能够有效避免系统在不稳定的情况下,误操作导致元数据信息被改动,避免config servers节点间出现元数据不一致的情形。数据库集群中某一配置服务器发生异常,不会影响整个集群的正常工作,最终能够确保集群中写入数据或从集群中读取数据。
2.3 路由进程
路由进程可以将数据库集群中的多个组件看作是一个单一的系统,当MongoDB数据库服务器接收到用户请求时,首先查询相应的配置文件,找到存放该数据的分片服务器。然后通过配置服务协议把用户请求转发给相对应的分片服务器。当所有的分片服务器完成操作后,会将结果通过路由协议打包分别发送给Mongos。当Mongos汇总所有的数据结果后,再把最终结果返回给用户。Mongos每次启动,首先要去配置服务器中读取元数据单元,并同时保存到本地。每当配置服务器中的元数据信息发生变动时,它都会在第一时间通知所有的Mongos。
3 Hadoop大数据云存储平台
Hadoop大数据平台是Apache公司的一个开源子项目,该平台项目的主要目标是能够依据目前已有的廉价硬件设备生成系统稳定、可扩展的分布式计算架构。其中HDFS是Hadoop平台的子项目之一,它主要是能够实现分布式文件系统,为各大机构和公司建设云存储解决方案提供了参考。
云存储数据中心是由多服务器组成的服务器集群的统称,该云存储数据中心能够提供大容量、高并发的数据存储。该服务集群主要由一个主控节点和多个数据节点构成,能够通过网络设备将集群系统连接在一起,方便实现用户统一的管理和维护。
非结构化数据存储非常广泛,目前系统建设功能模块中对非结构化数据要求很多,包括图片上传下载、新闻图片发布、视频剪辑、文档管理等功能。其云存储层次结构如图2所示。
但是大部分的功能实现是通过在服务器上创建可写的目录来存储,采用此种方式有如下弊端:
(1) 性能低下。因系统所需的非结构化数据存储量大,服务器带宽和计算能力会根据数据类型进行相应分配,这样导致大量服务器存储被占用,对于一些核心设备上性能要求极高的服务器有很大影响。
(2) 集群同步难以维护。当大型项目规模需要集群支持时,为了确保实现节点内各服务器之间同步数据,通常采用基于服务器内部之间的协议保证数据传输的一致性和完整性。
(3) 服务安全管控性差。目前服务器都逐步采用集中式管控,这对服务器出入口安全提出更苛刻的要求,传统入侵都是通过对服务器上传木马实现的,为更好的提升服务安全管理,迫切需要对外服务接口进行监管。
(4) 数据安全性。针对服务器集群数据间的交换,通常采用vpn登录等方式获取所需的数据信息,而vpn通常是内外网信息的入口凭证,加强vpn等登录信息的监管是确保数据安全的重中之重。
(5) 数据持久性。基于业务应用的系统,通常采用单一数据库服务器存储,一旦数据库发生异常,无法保证数据的完整性和一致性,容易发生存储数据丢失等情况,一旦丢失,进行数据恢复往往比较困难。
本文设计的非结构化数据云存储架构建立在Hadoop之上,层次结构如下:
(1) 存储层:非结构化数据云存储系统对外提供不同的存储服务,每种服务的数据被统一存储在系统中,构成一个数据池。
(2) 管理层:管理层是非结构化数据云存储系统中最核心的一层。通过管理层实现云存储中多个存储设备之间的协同工作,确保这些设备对外提供统一的数据公众服务。
(3) 应用服务层:该层主要是根据用户自身业务而实现的业务需求,能够实现与云存储服务器集群进行交互的具体操作,最终实现用户的业务操作。
(4) 应用接口层:对应于云存储中的用户访问层。
4 本文设计内容
本文为优化HDFS的存储,引入MongoDB非关系型数据库进行相应的改进,在Hadoop云平台上搭建HDFS和MongoDB存储系统实现非结构化海量资源的存储。非结构化数据云存储平台如图3所示。
非结构化数据云存储平台中MongoDB架构如图4所示,其功能如下:
(1) Client:包含访问MongoDB的接口,维护缓存数据加快数据的访问速度,如集合位置信息。
(2) 协调服务:确保整个系统集群只有一个主控制节点,能够存储所有集合的寻址入口,实时监控集合服务的状态,将集合服务的状态信息实时发送到主控制节点;存储和管理MongoDB的模式信息,包括有哪些集合,每个集合有哪些文档。
(3) 控制节点:分配集合空间,负责元数据存储的负载均衡;发现失效的数据节点时,进行故障转移;处理MongoDB上的垃圾文件回收和schema更新请求。
(4) 集合服务:数据的I/O请求;对数据量较大的集合进行自动分片。
非结构化数据云存储平台中HDFS架构如图5所示,其功能如下:
(1) NameNode节点即控制节点,它可以看作是HDFS中的管理者,工作内容主要包括:管理文件系统的命名空间、集群配置、存储块复制等。
(2) 存储节点是数据存储的基本单元,通过将数据以块的方式存储到本地文件系统中,同时能够将所有块信息及时准确地发送给控制节点。
(3) MongoDB客户端就是获取分布式文件系统的应用程序。
通过开源Hadoop非结构化数据云存储平台,用户可以将海量非结构化数据存储到云平台上。HDFS可以用来存储PB级的数据,但数据访问延时高,不适合存储小文件等。MongoDB存储海量数据的元数据,可以实现实时读写,很好地弥补了HDFS的不足。
5 测试结果
测试实验数据来源于所在公司的商务数据。本次实验主要对Hadoop平台下NameNode节点内存损耗进行测试。为了进行NameNode内存损耗测试实验,实验设计数据如下:采用样本数分别为10 000,20 000,30 000,40 000,50 000,每组样本数中各自创建10万个文件;对引入MongoDB前后的系统进行相应实验,获取NameNode节点的内存大小并记录,实验结果如表2所示。
从实验数据中可以看出,对于原始不加任何修改的HDFS文件系统,随着文件数量的不断增加,NameNode节点的内存消耗也呈线性增长趋势。而在引入MongoDB后,文件数量等比增加,NameNode节点的内存消耗基本保持不变,内存占用率也不高。表3为响应时间对比结果。
从表3中可以看出,对于原始不加任何修改的HDFS文件系统,随着文件数量的不断增加,系统响应时间呈线性增长趋势。而在引入MongoDB后,文件数量等比增加,系统响应时间同样基本保持不变。实验结果表明,基于Hadoop云存储平台,采用MongoDB和HDFS相结合的方式,对缓解大数据NameNode节点的内存耗费和响应时间均有很好的改进。
6 结 语
本文通过对互联网发展的现状进行分析,重点研究了当前流行的NoSQL数据库代表MongoDB的数据库模型、特性以及它的分布式存储架构,并详细介绍了大数据云平台技术的特点,依据大数据云存储平台和非结构化数据库自身的特点,设计基于MongoDB和HDFS的非结构化数据云存储服务架构。针对非结构化数据元数据的特点以及MongoDB的存储特性,将MongoDB部署到Hadoop平台中,存储非结构化数据的元数据信息,而非结构化数据以文件的方式存放在HDFS系统中。这样可以降低HDFS在应对海量小文件的存储应用时,由于NameNode内存不足导致的性能瓶颈。在本文的最后设计实验对平台的可行性进行了验证,实验数据证明了改进方案的有效性和高效性。
参考文献
[1] WHITE Tom.Hadoop权威指南[M].北京:清华大学出版社,2011.
[2] 李乔,郑啸.云计算研究现状综述[J].计算机科学,2011,38(4):32?37.
[3] 谢华成,陈向东.面向云存储的非结构化数据存取[J].计算机应用,2012,32(7):1924?1928.
[4] WANG R W, ZHANG H, DENG Y F, et al. Efficient parallel radiosity for terascale applications [C]// Proceedings of 2008 International Conference on Computer Science and Software Engineering. [S.l.]: IEEE, 2008: 1074?1077.
[5] FABIANOWSKI B, DINGLIANA J. Interactive global photon mapping [J]. Computer graphics forum, 2009, 28(4): 1151?1159.
[6] 田浪军,陈卫卫,陈卫东,等.云存储系统中动态负载均衡算法研究[J].计算机工程,2013,39(10):19?23.
[7] GHEMAWAT S, GOBIOFF H, LEUNG S T. The Google file system [C]// Proceedings of 2003 ACM Symposium on Opera?ting Systems Review. [S.l.]: ACM, 2003: 29?43.
[8] 林菲,张万军,孙勇.一种分布式非结构化数据副本管理模型[J].计算机工程,2013,39(4):36?38.
[9] 胡珊珊.面向云存储的非结构化数据存储研究与应用[D].广州:广东工业大学,2014.
[10] 李存琛.海量数据分布式存储技术的研究与应用[D].北京:北京邮电大学,2013.
[11] 杨磊.基于NoSQL数据库的结构化存储设计与应用[J].科技风,2011(18):99.
[12] 朱建生,汪健雄,张军锋.基于NoSQL数据库的大数据查询技术的研究与应用[J].中国铁道科学,2014,35(1):135?141.
