个性化推荐系统安全防护研究
2016-05-14
北京邮电大学网络与交换技术国家重点实验室 北京 100876
概述
随着互联网信息快速增长,个人和企业的发展都离不开互联网技术。面对如此众多的数据,用户使用信息检索时,很难快速有效地找到符合自身需求的资源。随着此类问题日益受到关注,个性化服务应运而生。个性化服务就是利用机器学习与数据挖掘的相关算法收集、分析用户数据,同时,根据分析得到的结果对用户将要采取的行为进行预测,然后产生个性化的推荐结果,以达到主动推荐的目的,从而提高站点的服务效率,并以此来吸引更多消费者[1]。个性化推荐作为推荐系统服务中的一项重要内容,常常被用在电商网站之中来为用户提供商品信息以及购买意见,以帮助用户完成整个购买流程。个性化推荐的原理是:利用各种推荐算法,如基于内容推荐算法、基于用户的协同过滤算法、基于物品的协同过滤算法、基于上下文的推荐算法等,根据系统采集的用户行为等特征,为用户寻找相近的用户群,而后在群内用户之间,互相推荐浏览过的商品[2]。用户通过使用个性化推荐系统,能够快速准确地找到所需商品,减少购物时间,提高购买和服务的效率。
在个性化推荐系统带来巨大便利与收益的同时,业界也开始更加关注用户隐私泄露、恶意信息注入等安全问题。如何保证用户隐私数据安全,如何保证推荐系统在复杂网络环境中的稳定性,如何定位并查找恶意用户等问题,成为个性化推荐系统安全问题的主要研究方向。本文从个性化推荐系统的数据安全(用户隐私安全)和推荐算法安全两个方面分析在个性化推荐系统中常出现的安全问题并提出建议性的解决方案。为个性化推荐系统的使用者及开发者提供一个可供参考的意见。
1 个性化推荐系统及其信任度
1.1 个性化推荐系统
根据1997年Resnick等人给出的推荐系统概念的定义[1]:利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐系统一般由用户信息抽取、用户建模、推荐算法三个部分组成。推荐系统模型流程如图1所示。

图1 推荐系统通用模型
在运行时,推荐系统会将待推荐对象的特征信息与系统中的特征信息进行匹配、筛选、过滤。选出匹配度较高的推荐对象,推荐给用户。推荐系统的个性化程度与用户信息的掌握情况成正比。掌握用户信息越多、越全面的个性化推荐系统,就越容易做出个性化程度与精确度较高的推荐。同时,推荐系统还需要用户不断地进行反馈,以便自身能够随着用户的变化而及时地做出调整。其中,用户的个性化信息除了包括用户的年龄、职业、学历、居住地点、婚姻状态等基本属性信息外,还包括用户所喜好的领域、分类、检索的关键词、浏览网站的内容等偏好和需求信息。
1.2 推荐系统信任度
信任度是指用户对于推荐系统推荐结果的信任程度。随着推荐系统推荐准确率的提升,信任度作为推荐系统众多评价指标中非常重要的一项,开始受到更多开发者的关注。在商品推荐的推荐系统中,用户对于推荐系统的信任度显得尤为重要。对于不同推荐系统产生的相同推荐结果,信任度高的推荐系统更能促进用户的购买欲望。同时,对于信任度较高的推荐系统,用户更愿意与之进行交互、反馈,并提供一些兴趣、爱好等个人信息;而对于信任度较低的推荐系统,用户很难产生购买意愿,甚至会担忧个人信息的安全。这样站点就失去了用户黏性,用户开始逐渐流失,失去了用户行为数据作为推荐系统的基础,导致推荐准确率下降,最终进入信任度降低—准确率下降的恶性循环。所以,保证推荐系统推荐算法的可靠与数据安全势在必行。
2 用户隐私数据安全防护
2.1 用户隐私数据安全问题
部分互联网公司为提供更加精准的服务或谋取利益,通常会共享或出售部分用户数据进行数据挖掘和分析,数据中隐含的、能够识别用户身份的标识同样会泄露用户重要的隐私信息。表1为《推荐系统实战》[2]中给出的针对用户对个人隐私泄露担心的统计数据。

表1 用户调查统计表
据《推荐系统实战》调查,用户对于隐私的担心使得他们大多拒绝或反感给出个人数据,这将直接导致个性化推荐系统推荐精度的下降。
2.2 用户隐私数据安全保护策略
2.2.1 隐私参数平台P3P
针对Web用户信息保密的问题,W3C提出隐私参数平台(Platform for Privacy Preferences,P3P)[3]。通过P3P,网站只能获取到用户选择提供的信息,从而达到保护用户隐私的目的。目前,支持P3P的网站有www.w3c.org等。但由于P3P无法保证网站在使用数据的过程中,同样遵守隐私条款,因此用户无法保证隐私数据是否安全。
2.2.2 传统的数据隐私保护算法
传统的数据隐私保护算法是对原始值进行修改,让用户提供有关敏感信息的值[4]。修改这些原始值的方法有2个。1)对“属性”进行离散化。对属性进行离散化是隐藏信息较常用的方法之一。将属性值根据情况划分为间隔长度不同或者相同的几类。如年龄,对数据使用方不再提供真实数值,而是提供属性所对应的分类。2)原始值失真。在原始值xi的基础之上引入随机因子r,由此可以得到随机变量在[-α,+α]上,随机变量的均值为0的联合分布和随机变量均值为µ=0,标准差为δ的高斯分布。
2.2.3 本地化推荐计算及用户兴趣配置文件(Dynamic User Profile, DUP)
该方法将用户隐私数据的数据挖掘和管理都交给客户端来进行。客户端根据DUP进行分析选择,然后将提给内容提供服务器。其设计如图2所示。
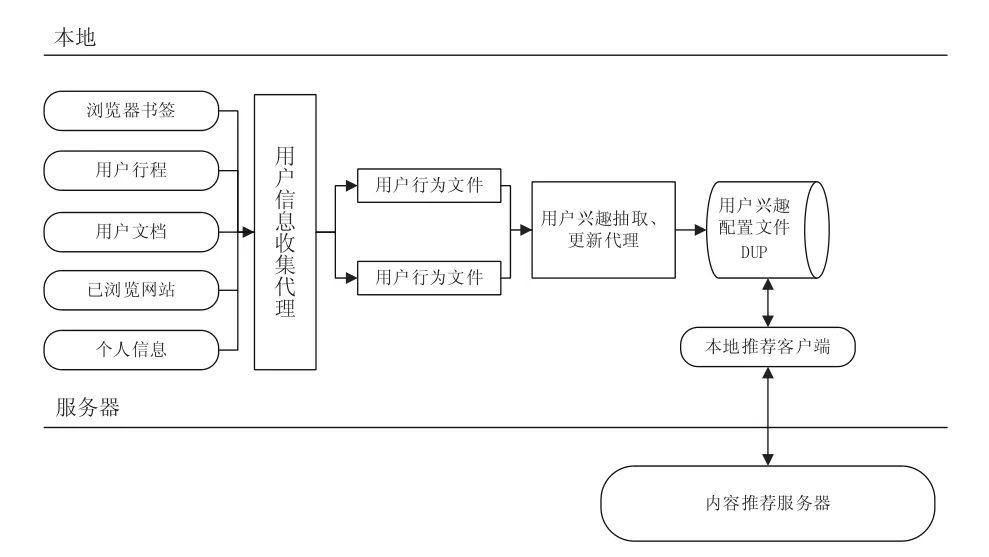
图2 DUP及推荐本地化设计如图
从图中2可以看出,该方法分为3个部分。1)用户信息收集代理: 主要负责搜集用户信息并形成格式化的用户行为文件。可以采用TF-IDF(term frequency–inverse document frequency)等加权算法在收集用户数据时计算关键词在语料库中的权重,生成词向量,从而建立用户DUP模型。同时为适应用户兴趣的变化,可引入相关的随时间衰减函数。2)内容推荐服务器。其作用为管理资源并根据客户端发送的请求发送对应的内容和收集用户反馈信息。3)本地推荐客户端。采用基于内容过滤技术,比较资源与DUP文件,然后进行推荐。
从以上描述可以看出,本地化推荐计算和DUP文件的方法可以通过本地推荐客户端防止用户数据的泄露,保证推荐的效率。但却只能应用于基于内容的推荐系统,这就使得推荐结果丧失了社交属性,因为服务器无法建立用户与用户之间的联系,同时,推荐计算的本地化要求推荐系统必须拥有本地客户端以方便进行推荐计算,这也加大了系统开发和用户使用成本。
2.2.4 采用聚合的方法保护隐私
文献《推荐系统安全问题研究综述》[5]在分布式的体系结构下使用了聚合(aggregation)的方法。首先,将系统中的用户根据某些偏好或规则聚集成为一些“用户集”。此后,推荐系统不再以单个用户作为推荐的基本单位,而是将推荐的基本单位变为“用户集”。推荐系统针对这些“用户集”所具有的数据特征做出推荐,而单个用户共享“用户集”的推荐结果。在此过程中,用户不需要将个人数据同步到服务端,所以用户个人对数据享有绝对的控制权。当需要进行数据交流时,用户先与其他用户进行数据交换,再将得到的数据与自身所在“用户集”数据进行聚合,然后再次计算得到推荐结果。在上述所有的操作过程中,用户的信息均没有暴露。
团体模型方法与聚合方法类似,同样是通过寻找用户共同属性、偏好建立用户群体模型;数据的交互与用户获得的推荐均是以用户团体为单位来进行的。
3 推荐系统攻击的安全防护
3.1 推荐系统攻击的定义
推荐系统能够为用户提供个性化推荐的前提是与用户进行交互,并记录用户的访问记录来形成“知识”,从而为用户提供推荐。然而,这些交互数据与记录均是开放式的,这使得一些攻击者利用推荐系统这一特点,人为地向其注入恶意的行为数据。诱导推荐提供做出对他们有利的推荐,从而达到谋取利益的目的。这样的攻击方式称之为用户概貌植入攻击,又叫做托攻击(Shilling Attack)[6-7]。
根据攻击的目的不同可以分为推攻击和核共计[8]。推攻击(Push Attack)是为了将目标项目的推荐频率提高。核攻击(Nuke Attack)是为了将目标项目的推荐频率降低。
3.2 协调过滤推荐系统攻击举例
推荐系统受到了托攻击,如果其推荐系统采用的是基于用户协同过滤算法,那么它产生的推荐结果将会发生很大的变化。例如:在某电商网站中,以数字1~5表示用户对图书的偏好程度,分数越高表明用户购买图书的倾向性越大。如表2所示,系统中出现有8个用户,User1-User7和User Alice,现在推荐系统将要预测用户User Alice对图书i6的喜好程度。根据Userbased协同过滤算法原理,首先要根据目标用户来寻找和目标用户偏好相似的用户。在托攻击没有发生之前,用户User6、User2和User3为与User Alice最为相近的三个用户,可以看到这三个用户对图书i6的喜好程度都很低,因此可以得知,用户User Alice对于i6的喜好程度很低。不会推荐i6给User Alice。然后,当攻击发生后,系统中多了Attack1-3三个恶意用户。由于注入的恶意信息具有很强的目的性,从而导致和User Alice 最相似的用户发生了变化,变为了Attack1-3。由于Attack1-3用户对图书i6的偏好程度较高,从而导致对User Alice的推荐结果发生了变化,误将图书i6推荐给了User Alice。
从上述实例中可以看到。恶意用户的托攻击会诱导推荐系统做出错误的判断。即使推荐算法的结果是非常准确的,但是一旦受到攻击,推荐系统将无法做出准确推荐,甚至做出错误推荐;因此,如何识别恶意用户以及恶意行为等推荐系统安全问题不容忽视。
3.3 协调过滤推荐系统攻击检测算法
推荐系统攻击者,通常是利用根据推荐系统原有的用户行为信息,来构建出大量对自身有利的攻击模型注入到推荐系统之中,从而对推荐系统的结果产生影响。而攻击检测的目的,是对推荐系统内现有用户行为数据进行分析。将已经成功注入到推荐系统中的攻击用户信息从系统中分离出来。降低攻击用户信息的影响,保证推荐系统的准确性。
3.3.1 基于统计学的检测算法
文献[9]中指出:可疑数据引起的数据异常,可以通过统计分析的方法检测到。统计检测的方法依靠统计过程控制技术确定离群项目,从而对数据异常进行检测。其中两个统计过程测量项目为:1)项目评分离群程度,通过计算项目评分与项目均值的距离,来判断项目是否在一个安全的范围内;2)置信区间,根据置信率确定置信区间,计算项目的评分均值是否在置信区间之内,如果在置信区间之内,则证明推荐系统在这段时间内是安全的。
3.3.2 基于无监督聚类的检测算法
此方法周期性地从数据库中抽取用户数据进行聚类分析,并对聚类中心的位置进行分析。如果聚类中心位置没有显著变化,则认为系统是安全的;相反,如果发现聚类中心发生显著位移,则认为系统受到了攻击,而那些偏离聚类中心过多的用户则有可能为恶意用户。
3.3.3 基于PCA的攻击检测算法
根据Mehta等人[7]对攻击过程特征的研究,恶意用户与恶意用户之间及恶意用户与正常用户之间都有着很强的相关性,反而正常用户之间的相关性较小。PCA(Principal Component Analysis)算法是一种基于变量的协方差矩阵二次排序方法,通过用最大方差找出原始变量的一些正交线性合并,这些合并后的成分就是主要成分,用它们来探索数据相关性。
第一个主要成分其中w为系数向量
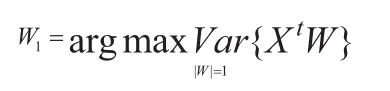
P C A对原始数据进行了特征值分解。假设数据为的矩阵形式,其中一列代表一个项目假设数据为零居中形式,现在的协方差矩阵C如下:可以将C转化为的形式。其中λ是C的特征值组成的对角矩阵,U为对应的特征向量。这表明主要成分(PCs)能够用矩阵S的行来给出。即按照C的特征值的顺序对U进行排序。这样便得到了PCA选择攻击用户的算法。降序排序后的前r个用户,即为攻击用户。
3.3.4 攻击检测算法评价及其他攻击检测算法
上述三类算法,基于概率学的检测算法相对容易实现,有其概率的合理性,但相关参数较多且难于控制。随着推荐系统规模的扩大,需要不断地对各类参数进行调整,以适应推荐系统自身的变化。基于聚类的攻击检测算法可以适应推荐系统的变化,但它基于的共识是:攻击用户与攻击用户的特征之间往往具有很高的相似度,可以通过某些聚类算法对攻击用户进行聚类。由于攻击用户的特征可能与某些正常用户相似,所以并不能通过聚类将所有攻击用户聚在一起。为解决这一问题,学者们提出可以降维评分数据。通过降维数据,使得攻击用户与正常用户的关联性减低,从而能够更好地反应用户的评分特性[9]。但在面对海量数据情况下,计算协方差矩阵的时间复杂度较高。通常使用评分矩阵的零矩阵的z-scores()来代替元矩阵进行分解[10]。即使这样,PCA算法的计算复杂度仍旧很高,面对推荐系统中巨大的用户偏好矩阵,PCA算法是很难实现的。
针对上述的种种问题,研究人员也提出了很多攻击检测算法。Tang等[11]在2011年提出分析用户的评分时间间隔的方法来进行检测。如果在一个时间段内,某个用户对一些项目产生了大量购买、订阅等行为,则此用户有很大嫌疑成为恶意用户。Zhang等人[12]在2011年提出一种数据沿袭(data lineage)的方法,通过查询用户的历史行为记录,和推荐结果来定位恶意用户。
4 结束语
在电子商务及推荐系统普及、应用、蓬勃发展的今天,人们越来越多地使用、依赖推荐系统。然而,由于推荐系统自身的开放性,很容易受到外界用户的攻击;因此,如何保证推荐系统的推荐质量、增强推荐系统的安全性,成为受到越来越多关注的问题。本文对推荐系统的数据安全及算法安全问题进行了分析和研究、提出并对比了相应的解决方案,对推荐系统的发展有着重要的意义。相信随着科学技术的不断发展,推荐系统的变革创新,会迎来一个推荐准确、隐私安全的全新电商时代。
参考文献
[1] KOBSA A. User modeling in dialog system: potentials and hazards[C]//Proc of IFIP/GI Conference on Opportunities and Risks of Artif i cial Intelligence System.1989:147-165
[2] 项亮.推荐系统实战[M].北京:人民邮电出版社,2012年
[3] 王国霞,王丽君,刘贺平.个性化推荐系统隐私保护研究进展[J].计算机应用研究,2012,29(6):2001-2008
[4] Lorrie C, Langheinrich M, Marchiori M, et al. The Platform for Privacy Preferences 1.0 Specification[EB/OL].(2002-04-12)[2016-07-19].http://www.w3.org/TR/2000/CR-P3P-20001215/
[5] 何发镁,冯勇,许榕生,等.推荐系统安全问题研究综述[C]//全国计算机、网络在现代科学技术领域的应用学术会议,2007
[6] 高峰.个性化协同过滤算法的安全问题研究[D].北京:燕山大学,2009
[7] 余力,董斯维,郭斌,电子商务推荐攻击研究[J].计算机科学,2007,l134 (15):134-138
[8] R.Burke, B.Mobasher, R.Bhaumik. Limited knowledge shilling attacks in collaborative filtering systems.//Proceedings of the 3rd IJCAI Workshop in Intelligent Techniques for Personalization, Edinburgh,Scotland,2005:76-82.
[9] Williams C. A, Mobasher B, Burke R, et al. Detecting profile injection attacks in collaborative filtering: a classification-based approach[M]. Advances in Web Mining and Web Usage Analysis. Springer Berlin Heidelberg, 2007: 167-186
[10] K. Bryan, M. O'Mahony, P. Cunningham. Unsupervised retrieval of attack prof i les in collaborative recommender systems[C]. Proceedings of the 2008 ACM conference on Recommender systems. ACM, 2008: 155-162
[11] T. Tang, Y. Tang. An effective recommender attack detection method based on time SFM factors[C].Communication Software and Networks (ICCSN), 2011 IEEE 3rd International Conference on. IEEE, 2011: 78-81
[12] F. G. Zhang. Preventing recommendation attack in trustbased recommender systems[J]. Journal of Computer Science and Technology,2011,26(5):823-828
