一种快速实用的测井岩性自动识别方法
2016-05-07高松洋
高松洋
(大庆油田有限责任公司勘探开发研究院, 黑龙江 大庆 163712)
0 引 言
海拉尔盆地贝尔地区岩性复杂,主要有泥岩、粉砂岩、细砂岩、含凝灰质粉砂岩、含砾细砂岩以及砂砾岩等。多数地层含有泥质和少量凝灰成分,测井响应特征相似,岩性识别难度大,严重制约着对储层的认识,影响了该区块的储量提交和进一步的勘探开发。以往针对砂泥岩的岩性识别方法主要有交会图法[1]、多元统计分析方法[2]以及基于各种不同数学演绎算法等形成的方法[3-4],这些岩性识别方法涉及到的测井曲线较多,处理繁琐且不易操作,在该区域很难达到满意的效果。本文综合分析以上各种岩性识别方法的优缺点,在岩心分析资料的刻度下,利用交会图技术结合测试分析资料提取了对岩性识别敏感的关键参数,利用主成分分析方法对该地区的复杂岩性进行了有效识别,识别效果显著。
1 岩性识别方法及应用
1.1 参数优选
对研究区的所有取心井的资料进行收集整理,包括单井测井曲线、岩心实验分析和薄片分析等相关数据。在此基础上进行岩心归位工作,该区块以正式的综合柱状图为准,结合测井曲线以及岩屑录井剖面进行岩心归位工作(见图1)。在岩心重新归位的基础上对岩心数据进行人工取值分析,为下一步岩性识别提供最原始可靠的测井曲线特征值数据。将所有取心井段的测井特征值提取之后,因受到测井曲线分辨率的影响,需要剔除掉小于0.6 m的薄层;通过取心描述结合薄片分析进行岩性综合定名工作。
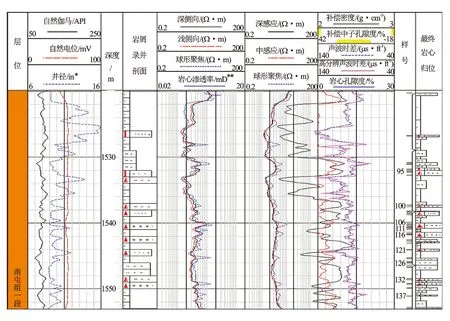
图1 H53-55井岩心归位分析图*非法定计量单位,1 ft=12 in=0.304 8 m; 1 mD=9.87×10-4 μm2,下同
交会图法有助于解释参数的选择和趋势与岩性的识别[5]。选取研究区8口井146个样本层的数据用交会图进行初步分析,其中泥岩样本48个、粉砂质泥岩20个、泥质粉砂岩22个、粉砂岩7个、细砂岩6个、凝灰质粉砂岩1个、凝灰质细砂岩1个、含砾细砂岩6个以及砂砾岩35个。初步选取了Δt、DEN、NPHI、RLLd和GR等5个参数以及构造2个与孔隙度无关而与岩性有关的参数M和N等7个对岩性变化反应较为敏感的参数[6]。
M=Δtf-Δtρb-ρf×0.01
(1)
N=φNf-φNρb-ρf
(2)
式中,Δt、Δtf分别为声波时差测井值和流体值;ρb、ρf分别为密度测井值和流体值;φN、φNf分别为中子测井值和流体值。
这7个参数可以从不同角度较好地反映各种不同岩性的特点,分析各参数的不同变化特征,从而组合起来作为复杂岩性综合识别的标准。通过交会图分析,随着砂岩粒度的增大,各种岩性整体上密度变大,电阻率数值变大,但各类岩性边界不明显,需要做进一步的判别分析。
通过进一步分析,凝灰质粉砂岩和凝灰质细砂岩样本点太少,不作为岩性识别的主要岩性而剔除掉,粉砂质泥岩和泥岩归位泥岩类,样本点数为68个,泥质粉砂岩作为过渡岩性自成一类,样本点数为22个,将粉砂岩、细砂岩和含砾细砂岩归位粉砂岩大类,样本点数为19个,砂砾岩自成一类,样本点数为35个。研究区岩性初步被划分成4个大类,再次利用交会图技术进行数据的分析工作。归类后的岩性具有较清晰的分布范围,下一步重点针对误差明显的数据点进行核实甄别工作,剔除掉受井径影响以及明显的误差点。最终确立了较为可靠的8口井78个岩性识别样本数据,其中泥岩17个,泥质粉砂岩21个,粉砂岩15个,砂砾岩25个。
由交会图分析,合并后的各大类岩性具有一定的分布范围(见表1、图2),但砂砾岩的整体分布范围较宽,测井响应特征不明显,进一步对砂砾岩样本点比对分析可知,该砂砾岩可被明显的细分为3类砂砾岩,颗粒从粗到细分别为砂砾岩Ⅰ、砂砾岩Ⅱ、砂砾岩Ⅲ。通过对该样本点的孔隙度渗透率和试油数据分析也验证了这一分类结果(见图3)。

表1 ×油田南一段主要岩性参数特征统计表

图2 ×油田南一段最终确定岩性样本交会图

图3 ×油田南一段细分类砂砾岩孔隙度渗透率和试油数据交会图
图3的孔隙度渗透率交会数据中,砂砾岩Ⅰ的孔隙度小于15%,渗透率在5 mD以下,对应试油数据以干层为主。砂砾岩Ⅱ的孔隙度15%~20%,渗透率5~70 mD,对应试油数据以水层为主;砂砾岩Ⅲ的孔隙度大于20%,渗透率大于70 mD,对应试油数据以油层和差油层为主。
1.2 模型建立
对最终确定的岩性分类进行测井响应特征分析。图4中,从泥岩到细砂岩再到砂砾岩,随着粒度增大,自然伽马有降低的趋势,电阻率、声波以及中子测井曲线值有逐步增大的趋势。
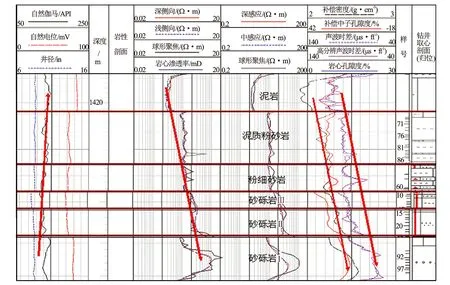
图4 ×油田南一段各类岩性测井响应特征图

图5 ×油田南一段岩性识别图版
通过对测井参数进行优选,最终确定了利用密度—中子交会图版为主、M—N交会图版为辅的交会图版判别岩性方法(见图5),图版的判别精度为84.3%。图版法的优点是简洁明了,各类岩性的大致分布范围比较清晰,缺点是实际操作时单井岩性的分层取值、读数、数据投放以及判别过程繁琐,可操作性差,且判别精度不高,不能满足实际生产开发需求。
主成分分析是利用降维的思想,在损失很少信息的前提下把多个指标转化为几个综合指标的多元统计方法。通常把转化生成的综合指标称之为主成分,其中每个主成分都是原始变量的线形组合,且各个主成分之间互不相关,这就使得主成分比原始变量具有某些更优越的性能,在研究复杂问题时就可以只考虑少数几个主成分而不至于损失太多信息,使问题得到简化,提高分析效率[7]。通过交会图分析优选出对南一段岩性测井响应比较敏感的参数Δt、DEN、NPHI、RLLd、GR、M、N。利用主成分分析方法提取第1、第2主成分进行判别分析,图版精度90%(见图6)。

图6 ×油田南一段主成分分析法岩性识别图版
第1主成分=0.2848GR-0.3589RLLd-
0.2177DEN+0.4706NPHI+0.4485Δt-
0.3903M-0.4095N
(3)
第2主成分=0.2239GR+0.2010RLLd+
0.7588DEN-0.1341NPHI-0.1536Δt-
0.3617M-0.4015N
(4)
式中,GR、RLLd、DEN、NPHI、Δt、M、N分别为自然伽马、深侧向电阻率、补偿密度、补偿中子、声波时差和岩性指示参数M、N进行Z标准化后的曲线。
2 应用实例
根据各种岩性的分布区域,将主成分分析图版程序化,挂接到卡奔软件中,可以对单井目的层进行连续处理。该方法省去了曲线方波化取值的繁琐以及人工读值误差,通过对该区域3口新取心井的处理分析,取心层共计66.92 m,测井识别61.03 m,识别精度为91.2%。图7为该地区新取心的H1井,利用该处理程序对目的层段进行岩性判别处理,处理结果与岩心描述结果吻合较好,可信度较高。其中紫色砂砾岩为第Ⅰ类砂砾岩,绿色为第Ⅱ类,红色为第Ⅲ类。
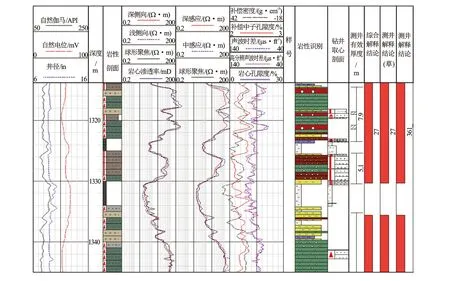
图7 H1井测井岩性自动识别图
3 结 论
(1) 针对研究区储层岩性复杂,难以识别的难题,在岩心实验分析数据的基础上进行了样本的筛选、剔除以及定名工作。
(2) 利用交会图分析技术提取出对岩性识别敏感的参数,对岩性进行了大类划分;结合孔隙度渗透率和试油数据对主要发育的砂砾岩进行了进一步的细分。
(3) 利用主成分分析方法对7个主要参数进行了降维处理;将主成分分析图版程序化,挂接到卡奔软件中,实现了对单井目的层进行连续处理解释,操作简单且识别率高,为研究区的储量提交和勘探开发奠定了基础;也可用于相同地质条件的其他区块。
参考文献:
[1] 蔺景龙, 马继明. 苏德尔特油田兴安岭群岩性识别方法 [J]. 大庆石油学院学报, 2006, 30(1): 4-6.
[2] 李汉林, 赵永军. 岩性识别的多元统计方法 [J]. 地质评论, 1998, 44(1): 106-111.
[3] 张治国, 杨毅恒. EPROP算法在测井岩性识别中的应用 [J]. 吉林大学学报, 2005, 35(3): 389-393.
[4] 刘倩茹, 薛林福. 梨树断陷砂砾岩测井岩性识别 [J]. 测井技术, 2013, 37(3): 269-272.
[5] 覃豪, 李洪娟. 应用测井资料进行火山岩岩性识别 [J]. 石油天然气学报, 2007, 29(3): 234-236.
[6] 范宜仁, 黄隆基. 交会图技术在火山岩岩性与裂缝识别中的应用 [J]. 测井技术, 1999, 23(1): 53-56.
[7] 宇传华. SPSS与统计分析 [M]. 北京: 电子工业出版社, 2007: 459-493.
