融合学习者社交网络的协同过滤学习资源推荐*
2016-05-06丁永刚桑秋侠金梦甜张红波
丁永刚 张 馨 桑秋侠 金梦甜 张红波
(湖北大学 教育学院,湖北武汉 430062)
融合学习者社交网络的协同过滤学习资源推荐*
丁永刚 张 馨 桑秋侠 金梦甜 张红波
(湖北大学 教育学院,湖北武汉 430062)
传统的协同过滤推荐算法存在冷启动和数据稀疏的问题,使得新学习者因历史学习行为记录稀疏或缺失而无法获得较准确的个性化学习资源推荐。鉴于此,文章提出将学习者社交网络信息与传统协同过滤相融合的方法,计算新学习者与好友之间的信任度,借助新学习者好友对学习资源的评分数据,来预测新学习者对学习资源的评分值,以填补新学习者在学习者—学习资源评分矩阵中的缺失,实现对新学习者的个性化学习资源推荐。实证研究结果表明,该方法在一定程度上能够解决传统协同过滤方法的冷启动和数据稀疏问题,提高个性化学习资源推荐的准确率。
社交网络;协同过滤;学习资源;个性化推荐
引言
计算机与互联网的高速发展不仅影响着人们的生活方式,而且也改变着人们的学习方式乃至思维方式[1]。网络学习因具有学习资源丰富、学习过程自主控制等优点,而成为学习者弥补传统课堂学习不足和满足个性化学习需求的首选学习方式。然而,一方面由于网络学习资源数量急速增长,导致资源严重过载,使得学习者难以快速获取自己感兴趣的资源,因而在一定程度上加大了学习者的学习难度,延长了学习者的学习时间,降低了学习者的学习效率;另一方面,由于网页之间以超链接的方式进行跳转,大量符合学习者个性化学习需求的学习资源可能被放置在超链接的深层,使得学习者无法轻易获取,从而降低了网络学习资源的有效利用率。因此,针对学习者学习偏好为其提供个性化学习资源推荐,便成为了提高学习者学习效率和网络学习资源利用率的有效手段。
个性化推荐技术被认为是目前解决信息过载问题的有效途径之一,其中最著名和最广泛应用的是基于协同过滤算法的推荐技术。该技术最早被应用于电子商务领域[2],其基本原理是从用户对商品的浏览、收藏、购买、打分、评价等历史行为信息中提取用户偏好信息,据此预测用户可能感兴趣的商品,并通过动态即时地向用户推送此类商品信息来促使用户购买商品的行为不断发生[3]。近年来,教育技术领域专家和学者致力于将协同过滤推荐技术应用于网络学习领域来构建个性化学习资源推荐系统,为学习者提供个性化学习资源推荐服务,以提高学习者的网络学习效率。如杨丽娜等[4]运用协同过滤、内容推荐及聚类分析相结合的方法,提出面向虚拟学习社区的个性化学习资源推荐框架;王永固等[5]在全面阐述协同过滤推荐技术的基础上,提出学习资源个性化推荐系统理论模型;叶树鑫等[6]采用协同过滤推荐技术,为协作学习中的相似学习者提供个性化学习资源推荐。
协同过滤推荐技术在一定程度上解决了学习资源信息过载的问题,但是传统的协同过滤算法存在冷启动和数据稀疏的问题,使得新学习者因历史学习行为记录稀疏或缺失而无法获得较准确的推荐。对此,文章提出利用学习者社交网络中的好友信息,计算学习者与其好友之间的信任度,并根据学习者好友—学习资源评分矩阵,预测学习者—学习资源评分值来填补新学习者在学习者—学习资源评分矩阵中的缺失数据,以提高个性化学习资源推荐的质量,满足学习者个性化学习的需求。
一 基于协同过滤算法的个性化学习资源推荐
协同过滤算法应用于个性化学习资源推荐的基本原理是:根据学习者的历史学习记录形成学习者—学习资源评分矩阵,利用相似性度量方法(如余弦相似度、皮尔森相关系数等),通过计算学习者或学习资源之间的相似度,挖掘出与目标学习者相似的学习者集合或与学习者历史偏好相似的学习资源集合,形成“邻居”,然后基于“邻居”学习者对学习资源的评分信息,预测目标学习者对学习资源的预测评分值,并根据预测评分值的大小为目标学习者进行个性化推荐。如TopN推荐,便是将预测评分值最大的前N个学习资源推荐给目标学习者。协同过滤推荐算法的具体实现步骤如图1所示。

图1 协同过滤推荐算法实现原理
依据上述原理,目前将协同过滤推荐技术应用于学习资源推荐主要有两种方法:
1 基于学习者的协同过滤算法(LearnerCF)
LearnerCF基于学习者对学习资源的公共评分信息计算学习者之间的相似度,并依据相似度大小来确定学习者的“邻居”集合,将“邻居”集合中学习者感兴趣的、而目标学习者没有学习过的学习资源推荐给目标学习者。LearnerCF向学习者推荐和他有共同学习兴趣的学习者感兴趣的学习资源,它隐含的机理是:两个学习者之间相似度的大小,由他们共同感兴趣的学习资源评分决定。
2 基于学习资源的协同过滤算法(ResourceCF)
ResourceCF基于被共同感兴趣的学习者对学习资源的评分信息计算学习资源之间的相似性,并根据目标学习者的历史学习偏好,向其推荐与之历史学习偏好相似的学习资源。它隐含的机理是:学习资源之间相似度的大小,由它们被共同感兴趣的学习者对学习资源的评分决定。
从相似度计算的代价考虑,在学习者数量小于学习资源数量的情况下,使用LearnerCF进行个性化资源推荐较为适合;反之,ResourceCF较为适合。在网络学习中学习者的数量远远大于学习资源的数量,因此,采用ResourceCF方法能在较好地满足学习者个性化学习需求的同时,降低系统的计算代价。
上述两种方法应用于不同场合已取得了不错的效果,但是仍然存在数据稀疏和冷启动的问题。一方面,LearnerCF由于学习者评分数据的稀疏性,学习者之间的共同评分资源数很少,使得用户相似度的计算不够准确,从而导致推荐的准确度不高;另一方面,ResourceCF对资源相似度的计算主要基于学习者自身历史学习记录,避免了LearnerCF由于没有共同评分的学习者而无法准确计算学习者相似度的问题,但对于没有历史学习记录的新学习者,ResourceCF却无法进行推荐,即存在冷启动问题。
二 学习者社交网络
学习者社交网络是指学习者在网络环境下,借助社交平台(如QQ、微博、微信等)与好友交流沟通、分享信息,而形成的个性化、动态化的人际信任网络。
1 学习者社交网络和信任关系
学习者社交网络中的好友大多是其现实生活中的朋友、同学、同事或学习者所关注的人,因此,学习者与其社交网络中的好友存在一定的信任关系。但信任是一个具有主观性的概念,不同研究领域的学者对信任的概念界定不同[7]。受学者Golbeck的启发[8],文章将“信任”界定为:如果学习者甲认为根据学习者乙的学习行为进行学习能够取得好的学习效果,则甲信任乙。
2 信任度的表示
学习者之间的信任程度用信任度表示[8]。在某些情况下,信任度仅用二值表示,即信任和不信任,但是这种简单度量方法在学习者社交网络中不够准确,不能充分体现学习者社交网络中信任度的作用。因此,本研究采用离散值将信任度划分成等级,其取值范围设定为[0,1],其中0表示完全不信任,1表示完全信任。
3 信任度计算
社交网络中学习者之间的信任度难以通过显式的方法获得,这是因为学习者主动输入好友的信任度,需要花费学习者的时间;另外,由于学习者之间的信任度处于动态变化之中,不能用固定值代替。文章认为,社交网络中学习者与好友之间的互动行为在一定程度上反映了学习者与好友之间的信任关系,这种互动行为主要包括评论和转发。学习者对彼此所发布的消息评论次数越多,表示学习者之间的熟悉程度越大,其信任度越高;学习者对彼此所发布的消息转发次数越多,表示学习者之间的认同感越强,其信任度越高。实际上,学习者一般会对自身感兴趣或者不清楚的消息进行评论,但不一定转发,而学习者转发的消息往往是经过自身筛选并高度认同的内容,因此转发行为的权重相对评论行为的权重应略大一些。受学者胡勋等[9]对移动用户间信任度计算方法的启发,网络环境下学习者之间的信任度可以采用下面的公式1计算:

三 融合学习者社交网络的协同过滤个性化学习资源推荐方法
个性化学习资源推荐技术作为满足学习者个性化学习需求的有效支持服务,其推荐算法的好坏是决定推荐服务质量的关键。文章提出融合学习者社交网络的学习资源协同过滤算法(SocialCF)进行个性化学习资源推荐,其实现流程如图2所示。

图2 融合学习者社交网络的协同过滤个性化学习资源推荐流程图
从图2可知,本方法需要解决以下三个关键问题:
1 学习者社交网络信息的获取
为了获取学习者的社交网络信息,网络学习平台允许学习者以其社交平台账号如QQ、微博等账号登录,并授权学习平台获得学习者的好友列表信息。为保护隐私,此操作仅允许学习平台获取学习者与其好友的交互行为信息,而不允许对学习者的社交内容进行获取。
2 信任度与预测评分值的转换
利用公式1计算得到学习者与好友之间的信任度后,即可利用公式2计算得到目标学习者对学习资源的预测值:

3 学习者信任度与学习者—学习资源评分矩阵的融合
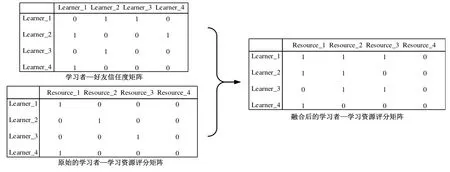
图3 学习者—好友信任度矩阵与学习者—学习资源评分矩阵融合示意图
如图3所示,将学习者任度与学习者—学习资源矩阵相融合的方法是:借助学习者—好友信任度矩阵中Learner_1“JSP程序设计”课程网站获得第十四届全国多媒体课件大赛二等奖。与Learner_2的信任关系和Learner_2对Resource_2的评分信息,产生Learner_1对Resource_2的评分,该评分依据公式2进行计算。以此类推,可补充学习者—学习资源评分矩阵中的其它空白。从图3不难看出,融合了学习者社交网络信息的学习者—学习资源评分矩阵,明显比原始的学习者—学习资源评分矩阵稠密。
四 融合学习者社交网络的协同过滤个性化学习资源推荐效果分析
为验证SocialCF方法的有效性,本研究以湖北大学教育技术学专业的120名学生为实验对象,在自主研发的“JSP程序设计”课程学习平台上进行实证研究。该学习平台在“JSP程序设计”课程网站1“JSP程序设计”课程网站获得第十四届全国多媒体课件大赛二等奖。的基础上进行二次开发,增加了个性化推荐模块和收集学习者历史评分数据和学习者社交网络数据的功能。学习者的平均好友数为4.5个,学习资源数为208个,评分记录数为1252条,数据稀疏率为95%。实证采用问卷调查和离线实验的方法对推荐效果进行评价。问卷调查方法从系统冷启动、满意度和信任度三个方面对推荐效果进行评价,离线实验方法则使用准确率、召回率和覆盖率指标对推荐效果进行评价。
1 调查问卷结果与分析
本实验实际发放问卷120份,回收120份,有效回收率100%。表1显示了CF和SocialCF调查问卷的结果。
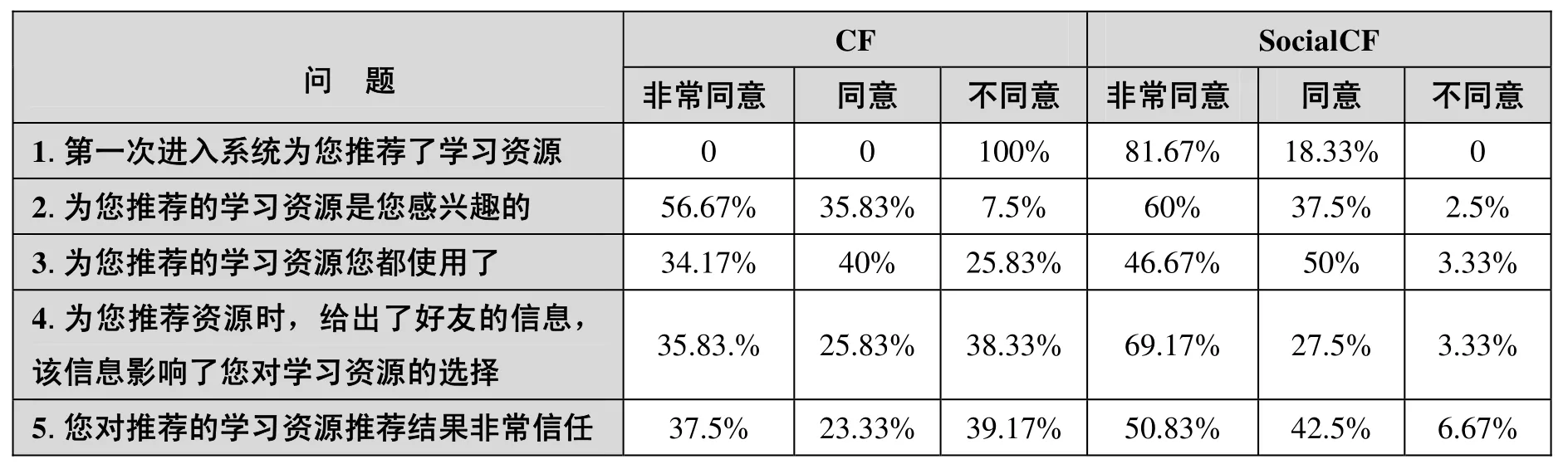
表1 CF和SocialCF调查问卷的反馈结果
在表1中,第一个问题用于评测两种不同方法对新学习者的推荐情况,即冷启动问题。由于SocialCF使用了社交网络信息,所以新学习者第一次进入系统时即可获得推荐。第二和第三个问题用于测评用户的满意度,可以看出,虽然92.5%的学习者认为CF推荐的学习资源与其学习兴趣相关,但只有74.17%用户使用了学习资源;而97.5%的学习者认为SocialCF推荐的学习资源与其学习兴趣相关,且96.67%的学习者使用了学习资源。由此可知,学习者对SocialCF的推荐结果较满意。第四和五个问题用于测评学习者对推荐结果的信任度。由于SocialCF在推荐时给出了好友信息,学习者对资源推荐结果的信任度比CF提高了32.5%,这表明学习者对SocialCF的推荐结果更加信任。
2 离线实验对比与分析
随机抽取100个用户数据进行离线实验,用于评测系统的准确率、召回率和覆盖率。其中80个用户数据用于训练集,20个用户数据用于测试集。
(1)不同topN情况下CF与SocialCF准确率和召回率的比较
准确率是指系统推荐给学习者感兴趣的资源占所有推荐给学习者资源的比例,召回率则指推荐给学习者感兴趣的资源占系统中学习者感兴趣的所有资源的比例。选择推荐列表长度分别为N=5,10,15,20,25,30,35,40,对CF与SocialCF的准确率与召回率进行测定,如图4所示。可以看出,在N的各种取值下,SocialCF的准确率和召回率均高于CF,说明SocialCF能比CF为学习者推荐更准确且更多感兴趣的学习资源。
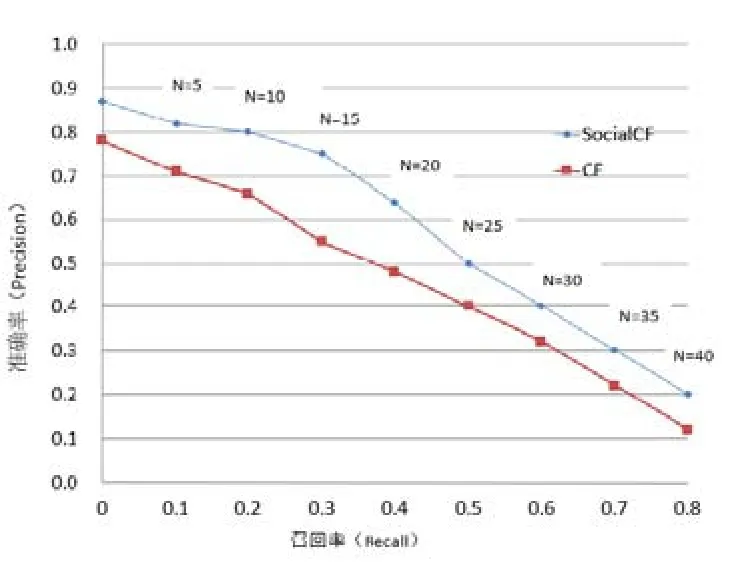
图4 不同topN情况下两种方法的精确率和召回率
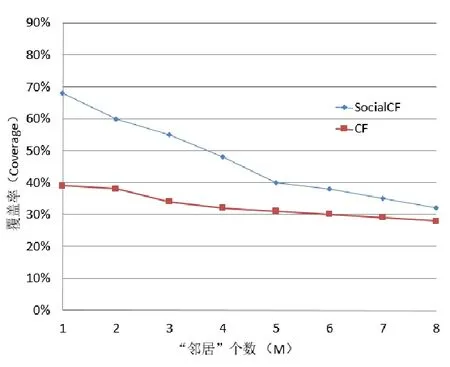
图5 不同“邻居”数情况下两种方法的覆盖
(2)不同“邻居”个数下CF和SocialCF的覆盖率
覆盖率是指向学习者推荐的学习资源占总体学习资源的比例。分别选择不同的“邻居”个数,测试CF与SocialCF的覆盖率,如图5所示。可以看出,随着“邻居”个数的不断增加,学习者的学习偏好被定位到一个较小范围,推荐的学习资源越来越少,因此CF与SocialCF覆盖率均呈下降趋势。但从总体来看,SocialCF的覆盖率仍高于CF,表明SocialCF能够在一定程度上提高学习资源的利用率。
五 总结
利用个性化推荐技术,帮助学习者在海量的学习资源中轻松、准确、高效地获取感兴趣的学习资源,既是决定网络学习效果的关键,也是避免网络学习资源浪费的有效途径。文章针对传统协同过滤算法中的冷启动和数据稀疏问题,提出运用学习者社交网络信息与传统协同过滤相融合的方法进行个性化学习资源推荐。问卷调查和离线实验结果表明,SocialCF能够在一定程度上缓解协同过滤的冷启动和数据稀疏问题,且在学习者满意度、准确度、信任度和覆盖率等方面均优于CF,故提高了个性化学习资源的推荐质量。为了取得更好的推荐效果,未来我们将进一步考虑学习者对学习资源的隐式评分数据和学习者与好友在社交网络中的其它交互行为。
[1]余胜泉.技术何以革新教育——在第三届佛山教育博览会“智能教育与学习的革命”论坛上的演讲[J].中国电化教育,2011,(7):1-6.
[2]Lee L,Lu T C.Intelligent agent-based systems for personalized recommendations in internet commerce[J].Expert Systems with Applications,2002,(22):275-284.
[3]Cheung K W,Kwok J T,Law M H,et al.Mining customer product ratings for personalized marketing[J].Decision Support Systems,2003,(35):231-243.
[4]杨丽娜,刘科成,颜志军.面向虚拟学习社区的学习资源个性化推荐研究[J].电化教育研究,2010,(4):67-71.
[5]王永固,邱飞岳,赵建龙,等.基于协同过滤技术的学习资源个性化推荐研究[J].远程教育杂志,2011,(3):66-71.
[6]叶树鑫,何聚厚.协作学习中基于协同过滤的学习资源推荐研究[J].计算机技术与发展,2014,(10):63-66.
[7]张富国.基于信任的电子商务个性化推荐关键问题研究[D].南昌:江西财经大学,2009:12-13.
[8]Golbeck J.Computing and applying trust in Web-based social networks[D].Maryland:University of Maryland,College Park 2005:15-16.
[9]胡勋,孟祥武,张玉洁,等.一种融合项目特征和移动用户信任关系的推荐算法[J].软件学报,2014,(8):1817-1830.
The Collaborative Filtering Recommendation of Learning Resources Combined with Learners’ Social Network
DING Yong-gang ZHANG Xin SANG Qiu-xia JIN Meng-tian ZHANG Hong-bo
(School of Education,Hubei University,Wuhan,Hubei,China 430062 )
The traditional collaborative filtering recommendation algorithm (CF) has the problems of cold start and data sparseness,so it is difficult for new learners to obtain learning resources recommendation because of the sparsity or the lack of history learning behavior records.Thus,in this paper,a new CF method was proposed which combined learners’social network information with traditional CF method.In order to fill the gap in the “learner - learning resource rating matrix” and achieve the recommendation of learning resources to new learners,it first calculated the trust degrees between new learners and their friends and then predicts new learners’ ratings on learning resources by virtue of that of their friends.The experimental results shown that this method can solve the cold start and data sparsity problems in some degree and improve the accuracy of personalized learning recommendation.
social network; collaborative filtering; learning resource; personalized recommendation
小西
G40-057
A 【论文编号】1009—8097(2016)02—0108—07
10.3969/j.issn.1009-8097.2016.02.016
本文为教育部人文社会科学研究青年基金项目“基于互动电视的课堂教学模式与策略研究”(项目编号:14YJC880109)阶段性研究成果。
丁永刚,副教授,在读博士,研究方向为教育数据挖掘、个性化资源推荐,邮箱为hddyg@hubu.edu.cn。
2015年8月27日
