社交网络中基于用户隐私信息的链路预测
2016-05-04张长伦赵意北京建筑大学
张长伦 赵意北京建筑大学
社交网络中基于用户隐私信息的链路预测
张长伦 赵意
北京建筑大学
摘要:社交网络中的链路预测算法往往仅使用用户节点度的信息,然而社交网络是真实社会关系的影射,个人用户本身存在许多隐私信息,并且这些隐私信息对链路预测有很大影响。本文在研究有向社交网络中的链路预测算法的基础上,提出一种综合考虑节点度的信息以及用户节点的隐私信息的链路预测方法,提高了预测的准确度。
1 引言
社交网络是指个体成员之间因为互动而形成的相对稳定的关系体系,关注的是人们之间的互动和联系[1]。社交网络的建立方便了用户之间的思想交流和信息共享。知名的社交网站如国外的Facebook、Twitter等,国内的新浪微博、腾讯微博等。这些社交网络不仅可以为人们的休闲和娱乐提供平台,而且还可以增强人们之间的相互沟通与理解。
在社交网络中,每个用户节点相当于一个信息频道,可以自由发布自身信息,也可根据自身兴趣关注一些感兴趣的相关人物,建立起自己的社会关系。但是由于社交网络往往拥有数以亿计的用户节点,当用户在建立自己的社会关系时,会面临着数据过载问题,因此帮助用户在大量的人群节点中发现其感兴趣的人群是非常重要的,而社交网络中的链路预测就是一个有效的工具。社交网络中的链路预测就是根据社交网络及其网络用户发布的信息,预测目标用户感兴趣的潜在相关用户,然后将预测的相关用户推荐给目标用户。
对于社交网络中存在的海量信息,其中有很多都是用户的隐私信息,对于这些隐私信息的研究,不仅可以提高网络中链路预测的精确度,而且还可以对用户的个人隐私信息提出一些保护措施。文献[2-4]介绍了社交网络中存在的隐私信息,并通过一些方式对这些隐私信息进行处理,运用处理后的信息提出一些用户个人信息保护措施以保证用户信息安全。虽然很多文献都对社交网络中存在着大量的用户个人隐私信息进行了研究,但对于社交网络中的链路预测来说运用这些隐私信息的还相对较少。因此,本文考虑使用社交网络中用户个人的隐私信息,并对这些信息进行处理,提出一种新的社交网络的链路预测方法,提高链路预测的精确度。
2 相关工作
目前,研究网络中的链路预测的方法有很多,文献[5]综述了从不同角度考虑网络的特性而提出各种不同的链路预测方法,在具体研究网络中的链路预测时,不仅要考虑网络中节点的各种属性,而且还要考虑网络结构特征,网络的结构特征一般考虑两个方向:一是基于网络的局部特征,考虑网络节点的局部结构;二是基于网络的全局特征,考虑网络的全局结构。虽然网络中链路预测的方法有很多,但大部分都是在无向网络中研究的,而在现实的社会生活中,很多网络是有向的,例如食物链网络、雇佣关系网络、微博网络等,它们之间的链接是不对称的,只能从一个节点指向另一个节点,对于这类有向网络的链路预测用原来的无向网络中的研究方法是不可行的。
在有向社交网络的链路预测中,学者们对其进行了大量的研究。文献[6]介绍一些有向网络中的链路预测方法及指标,并比较那些知名的链路预测指标及这些指标在有向网络中的适应性,且根据现有的技术提出最小子图模型的链路预测指标,实验表明该模型有较高的精确度。但对于一些社交网络仅仅考虑其方向性是远远不够的,因为网络中存在很多信息,而根据信息流的传递进行链路预测的算法也有很多,信息流的传播使网络的某些用户有了连接,因此在有向社交网络的链路预测算法方面考虑信息相似性也是非常有必要的。文献[7]通过对网络中信息流的分析,信息流会随着时间的变化而衰减,对不考虑时间对信息流影响的基于随机游走的PropFlow算法进行改进,添加信息流衰减因子,提出随时间变化的基于随机游走的T_Flow算法,并将这两个算法在实际网络中对比,T_Flow算法预测精确度有所提高。文献[8]利用网络中存在的节点信息及结构信息,提出评价节点权威性的BenefitRank机制,并结合弱连接理论给出估计加权网络节点之间未来关系相似的措施。
然而,现有的社交网络的链路预测算法在对预测节点的得分计算时,大多仅仅考虑网络中节点度的信息,但对于社交网络,它是个人真实社会关系的完美映射,网络中用户个人还存在着大量的隐私信息,如果考虑用户之间的隐私信息,则得到的预测结果更符合实际。本文在研究社交网络中的链路预测问题时,考虑用户个人存在的大量隐私信息,利用这些隐私信息并结合网络中节点本身的节点度信息计算用户之间的连边得分,根据计算的得分对社交网络进行链路预测,从而提高链路预测准确度。
3 模型
3.1继承节点集
使用文献[9]的继承节点的寻找方法,首先找到目标节点的相似节点集,然后根据相似节点集寻找继承节点集。
3.1.1相似节点集
a).目标节点直接指向的节点:
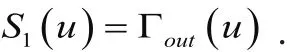
b).目标节点直接指向的节点的一跳范围内所指向的节点:
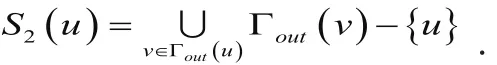
c).有共同兴趣的节点(即与目标节点同时指向的节点):
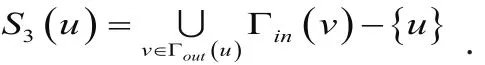
相似节点集:
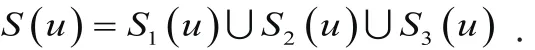
如图3-1设定目标节点为u1,则
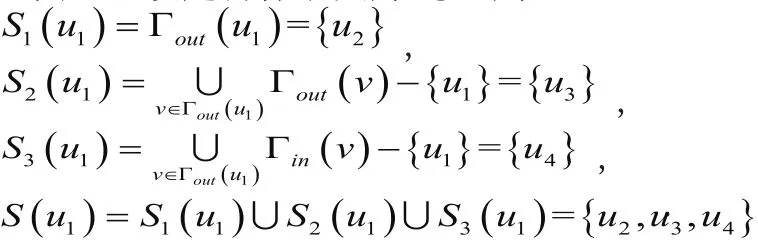
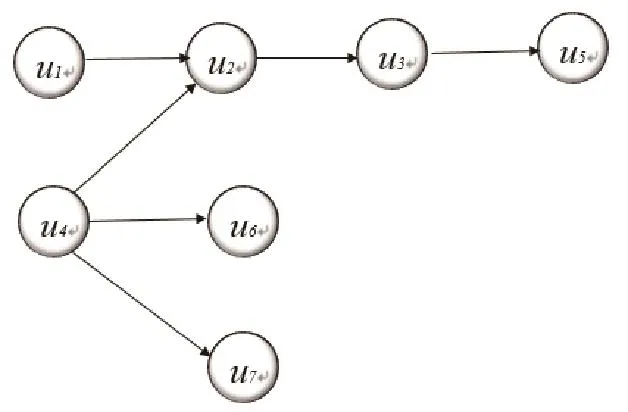
图3.1 有向网络
3.1.2继承节点集
通过相似节点所指向的节点确定为目标节点的继承节点,定义为
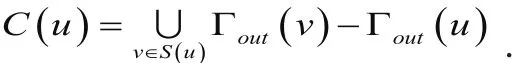
如图3-2设定u1为目标节点,则
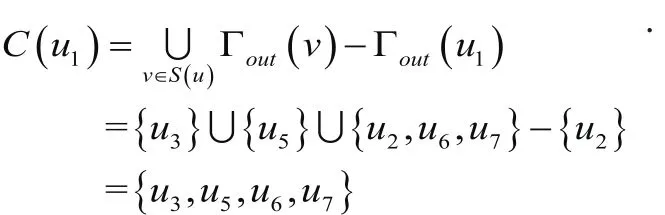
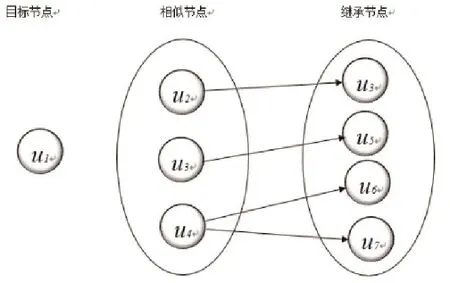
图3.2 相似节点集及继承节点集
3.2隐私信息相似性及度信息比重计算
在社交网络中,首先我们将用户的隐私信息提取出来,然后将这些信息转换成用户的属性信息(背景信息、社交信息、文本信息、交互信息),并根据一定的规则将这些信息用一系列的单词标签表示,根据单词标签的相关程度判断是否可以将此单词标签归为一类。
假设选取u为目标节点,i为继承节点集中的某一继承节点,根据节点本身的属性特征提取其隐私信息生成单词标签,则用户u的隐私单词标签为,用户i的隐私单词标签为,同时分别提取用户u, i周围相似节点的隐私信息,然后从中找出与用户u, i相同的隐私信息,并计算出这些隐私信息在相似用户中的信息比重ω,形成向量,然后得出隐私信息的相似度。即用户u, i的隐私信息相似度为
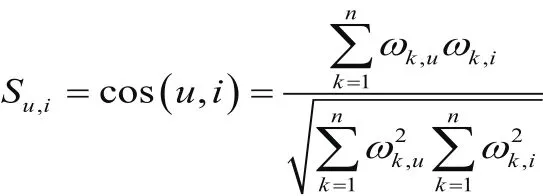
然后结合节点度的信息,借鉴ZTZH模型[10]中连边连接的计算方式(即网络连边权重的多少以概率p取决于被连接节点i的度和以概率1- p取决于被连接节点i的适应度iη,即
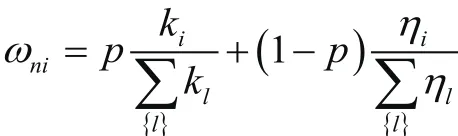
其中,{l}代表新节点n所要连接的节点的集合。)改进两节点连边的得分得计算方法。两节点连边得分的计算以概率p取决于节点i的度的信息和以概率1- p取决于节点u, i的隐私信息,即
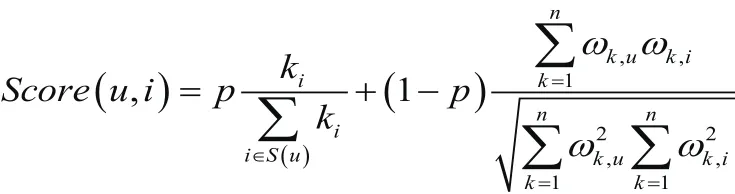
其中,i为继承节点,ki为节点i的相似节点数,ω为隐私信息比重,p为参数。而继承节点i的度信息比重计算方法为:找出节点i的所有相似节点并计数ki,同时找出节点u的所有继承节点的所有相似节点并计数,则度信息比重为
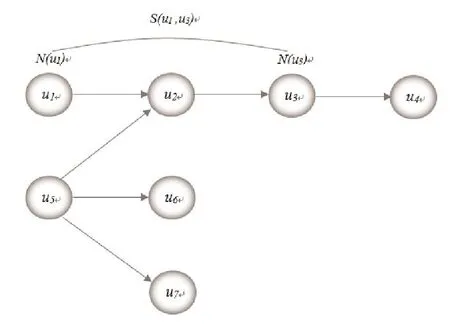
图3.3 隐私信息相似性计算
例如,在图3-3中选取u1作为目标节点,u3为继承节点,分别提取两节点的隐私信息并将其生成隐私单词标签。然后将两节点的每个单词标签作对比,根据每个单词标签在其周围相似节点中所占的比重ω生成隐私信息比重,并计算两节点隐私信息总体的相似性,即
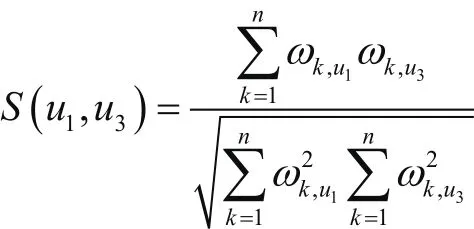
并计算继承节点u3的度以及继承节点集的所有相似节点的度,则节点之间的得分为
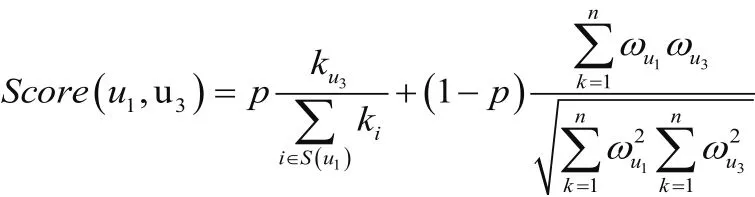
3.3计算得分
根据用户节点的隐私信息计算出两节点的信息相似性,同时计算继承节点度的信息,得到预测节点连边的得分计算方法。然后计算出两节点连边的得分,并将这些得分进行排序,根据分数高低判断两节点是否连接。即得分计算方式如下
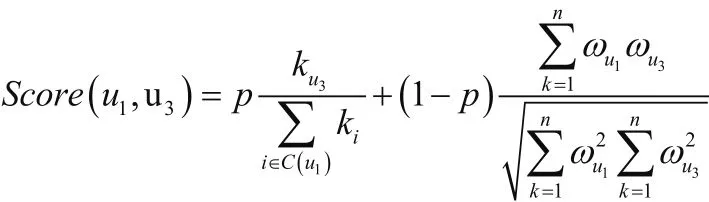
4 仿真分析
本文采用腾讯微博数据(2012KDD竞赛数据)对提出的预测模型进行仿真分析。为仿真方便,本文对原始数据进行了预处理,随机选取了8437个节点。
4.1评价指标
本文模型的仿真结果采用常用的三种评价指标进行评价,即准确率、召回率、F1度量来衡量该模型的优劣。
4.2仿真结果及分析
针对考虑基于节点度信息的预测方法、基于用户节点隐私信息的预测方法以及综合考虑基于节点度信息和用户节点隐私信息的预测方法3种不同的预测算法进行仿真,仿真结果如表4-1所示:
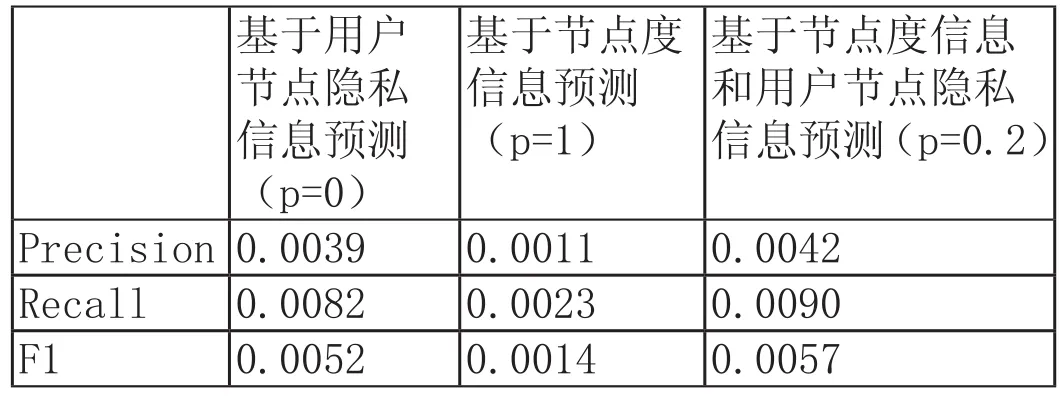
表4-1 两节点连边预测结果
从表4-1中可以看出,基于节点度信息和用户节点隐私信息的预测模型相比于仅仅基于节点度信息的预测模型以及仅仅基于用户节点隐私信息的预测模型对预测结果的准确度均有所提高。对于准确率、召回率以及F1度量,基于节点度信息和用户节点隐私信息的预测模型要比基于节点度信息的预测模型的预测结果高出了4倍左右,而与基于用户节点隐私信息的预测模型的预测结果比较接近,这说明网络中用户的隐私信息对预测的连边有很大的影响,体现出隐私信息在预测两用户是否发生连接有着重要的作用。从用户的隐私信息角度来看,两用户的信息相似度越高,说明其感兴趣的话题就越多,这两用户连接的可能性就越大。
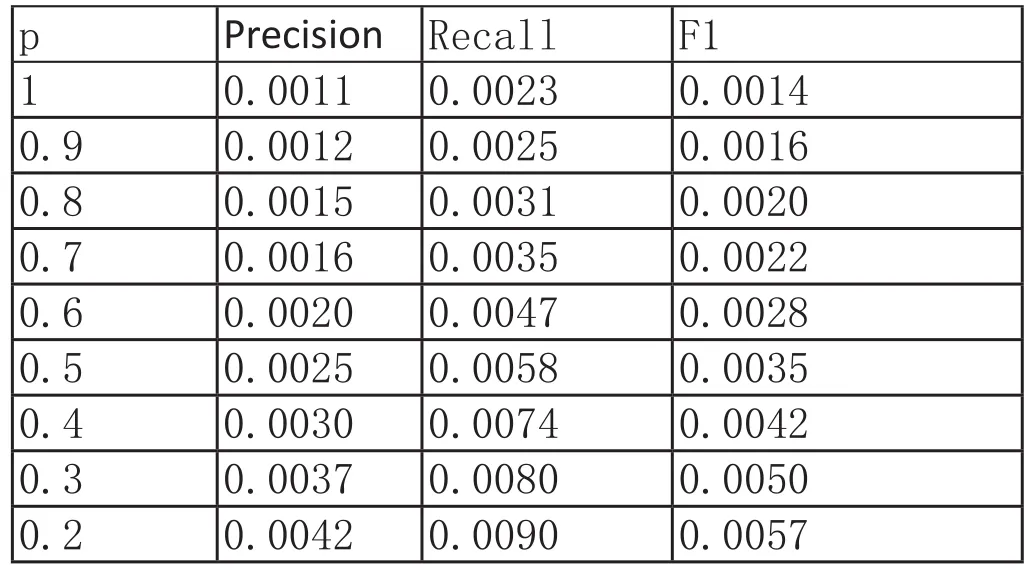

表4-2 基于节点度信息和用户节点隐私信息的预测方法与参数p的关系
从表4-2中可以看出,对于不同的参数p,预测的结果有所不同。基于节点度信息和用户节点隐私信息的预测模型,需要合适的p值来权衡用户节点度信息和用户节点隐私信息哪一方面的信息对预测的结果比较重要。当p=0.2时,模型的预测结果达到最优。由此可以看出,用户的节点度信息对预测的结果也有着一定的影响,这是因为用户节点度越高,其关注的用户就越多,则其感兴趣的话题也越多,其他用户与其发生的连接也就越高;同时该用户的隐私信息也就越多,其他用户的隐私信息与其信息相似度也有可能越高,这样两用户发生连接的可能性就会更高。因此,综合考虑基于节点度信息和用户节点隐私信息的预测模型对于好友的预测有更高的预测性能。
4.3小结
本文通过对社交网络中用户节点度及用户隐私信息的研究,提出了一种有向网络中的链路预测算法,并将这种算法运用到微博好友预测中,更符合社交网络的实际情况,取得了较好的预测结果。
参考文献
[1]Linyuan Lv, Link Prediction on Complex Network, Journal of University of Electronic Science and Technology of China, Vol.35, No.5, 651-661, 2010.
[2]Acquisti A, Grossklags J, Privacy and Rationality in Decision Making.IEEE Secur Priv 26-33, 2005.
[3]Bonneau J, Anderson J, Anderson R, Stajano F, Eight Friends Are Enough: Social Graph Approximation Via Public Listings, In: Proceedings of the Second ACM EuroSys Workshop on Social Network Systems.SNS’ 09, ACM, New York, pp 13-18, 2009.
[4]Gross R, Acquisti A, Information Revelation and Privacy in Online Social Networks, In: Proceedings of the 2005 ACM Workshop on Privacy in the Electronic Society, WPES’ 05, ACM, New York, pp 71-80, 2005.Narayanan A, Shmatikov V, De-anonymizing Social Networks, In: IEEE Symposium on Security and Privacy, 2009.
[5]Zheleva E, Getoor L, To Join or not to Join: the Illusion of Privacy in Social Networks with Mixed Public and Private User Profiles, In: Proceedings of the 18th International Conference on World Wide Web, WWW’ 09, ACM, New York, pp 531-540, 2009.
[6]Lankeshwara MUNASINGHE, Ryutaro ICHISE.Link Prediction in Social Networks Using Information Flow via Active Links.The Institute of Electronics, Information and Communication Engineers.Vol.E96-D, No.7, pp 1495-1502, 2013.
[7]Zhijie Lin, Yun Xiong and Yangyong Zhu.Link prediction using BenefitRanks in weighted networks.International Conferences on Web Intelligence and Intelligent Agent Technology, pp 423-430, 2012.
[8]Yan Yu, and Xinxin Wang.Link Prediction in Directed Network and Its Application in Microblog.Hindawi Publishing Corporation Mathematical Problems in Engineering Volume 2014.
[9]Zheng D F, Trimper S, Zheng B, et al.Weighted scale-free networks with stochastic weight assignments.Phys.Rev.E, 2003, 67(4): 040102(1-4).
项目名称
国家自然科学基金青年项目,61401015,社交网络用户行为分析及话题演化趋势预测方法研究。
关键字:社交网络 链路预测 隐私信息
