基于超限学习机的矿区土壤重金属高光谱反演
2016-04-20马伟波李海东闫庆武
马伟波,谭 琨①,李海东,闫庆武
(1.中国矿业大学环境与测绘学院,江苏 徐州 221116;2.环境保护部南京环境科学研究所,江苏 南京 210042)
基于超限学习机的矿区土壤重金属高光谱反演
马伟波1,谭琨1①,李海东2,闫庆武1
(1.中国矿业大学环境与测绘学院,江苏 徐州221116;2.环境保护部南京环境科学研究所,江苏 南京210042)
摘要:近年来采用可见光近红外光谱反演矿区土壤重金属受到重视,但土壤中重金属含量微小,光谱特性非常脆弱,对反演模型提出了较高要求。针对复垦矿区的土壤重金属反演研究,引入超限学习机(extreme learning machine,ELM)方法进行反演建模,与传统的偏最小二乘(partial least squares regression, PLS)方法和支持向量机(support vector machine, SVM)方法进行分析比较。通过对光谱数据进行预处理和相关性分析后,对30个土壤样本数据运用3种模型进行反演,并对其中10个预测样本进行模型检验。结果表明,ELM对于重金属Zn、Cr、Cd和Cu的预测精度要高于SVM和PLS,对重金属As和Pb的预测能力与SVM基本相当。
关键词:超限学习机;土壤;重金属;遥感反演;高光谱;复垦矿区
采矿活动造成地面塌陷、裂缝和泥石流等地质灾害,给人类生命财产安全造成极大威胁与破坏。为改善采矿区地表的地质生态环境,一般会进行复垦,但复垦填充物大多为固体废弃物,如生活垃圾、粉煤灰和煤矸石等。粉煤灰和煤矸石用于充填复垦场地后,其中的多种重金属在土壤环境中释放、迁移,而且部分被农作物吸收、富集,并通过食物链进入人体,对人体健康可造成极大危害[1]。因此探测复垦矿区土壤重金属含量具有重要的现实意义和科学研究价值。
与传统的实验室检测相比,利用可见光近红外光谱对土壤属性的反演研究因更加省时省力而逐渐受到重视[2-3]。针对土壤中含量微小的重金属反演建模研究已有诸多算法[4-5],其中基于数学统计分析的方法如偏最小二乘(partial least squares regression,PLS)算法受到广泛认可,其对于多变量数据建模的可靠性得到验证。近年来机器学习领域的诸多算法也被研究者运用到土壤重金属光谱反演建模领域[6-7],如支持向量机(support vector machine,SVM)和人工神经网络(artificial neural network,ANN)等。
SHI等[8]统计了近年来对8种土壤重金属通过遥感光谱反演进行预测的文献,研究的区域分布范围很广,包括三角洲、郊区、河流沉积区、污染区和矿区等10余种,而使用最为广泛的方法就是PLS[8]。越来越多的学者在PLS基础上探索更为有效的预测方法,BALABIN等[9]利用可见光近红外光谱通过支持向量机回归(support vector regression,SVR)与ANN等几种非线性方法对土壤中的化学元素进行反演研究,发现SVR有较强的鲁棒性,但没有对重金属进行反演研究。国内也有很多学者通过基于SVM的方法对重金属进行反演预测,精度均较高[10-12]。吕杰等[10]通过SVM建模对受土壤重金属胁迫的水稻Cr含量进行光谱反演分析取得了较好的反演精度;谭琨等[13]在对复垦矿区土壤重金属进行反演研究时,发现最小二乘支持向量机(least squares support vector machine,LS-SVM)对多种重金属的预测精度超过PLS,但并不是普遍情况,LS-SVM表现出不稳定性;TAN等[14]采用自适应模糊神经系统(adaptive neural fuzzy inference system,ANFIS)算法对复垦矿区土壤重金属As进行反演,ANFIS的精度要明显优于PLS;杨一等[15]在利用可见光近红外进行枣类判别时发现,超限学习机(extreme learning machine,ELM)能够与偏最小二乘分析判别(partial least squares discriminant analysis,SPA-DA)、LS-SVM一样达到很高精度。但是ELM方法在高光谱遥感分析土壤重金属领域的应用鲜有人尝试。
笔者对经过预处理的高光谱数据,根据相关性分析方法针对6种土壤重金属提取出相应特征波段,引入ELM方法建模预测,并与同样实验条件下的PLS和SVM方法从模型精度和稳定性方面进行对比分析,以探索ELM算法在高光谱反演土壤重金属含量研究中的潜力。
1研究区域与数据获取
1.1研究区域概况
研究区域位于江苏省徐州市北郊矿区,地理位置为北纬34°17′51.61″~34°22′54.33″,东经117°03′37.69″~117°08′59.83″,总面积超过98 km2,耕地3 300 余hm2,且大部分为黄淮河冲击平原,地势较为平坦。土壤类型主要是棕土、褐土和潮土,有较深厚的土层,肥力中等。该区由于受采矿活动的影响,土地塌陷现象较为严重,土地复垦工作已于2000年完成,复垦后的土地主要用于农业种植。在研究区内选取3块小麦地,分别为煤矸石复垦填充、粉煤灰复垦填充和未复垦区域。用“S”形采样的方法在每块地中均匀选取10个样点,共30个样本,分别用自封袋装好,并做好标记带回。将带回的土壤样本分作2份,一份送至化学实验室检测重金属含量,一份送至室内光谱暗室进行土壤光谱反射率的测定。实验室重金属含量检测结果如表1所示。
表1土壤重金属含量检测结果统计
Table 1Statistics of measured heavy metal contents in the soil

统计指标w/(mg·kg-1)ZnCrCuAsPbw(Cd)/(μg·kg-1)最小值30.4765.8512.250.559.6425.05最大值95.20117.7663.559.6133.53164.99平均值62.4894.9930.813.1923.1179.85标准差19.8516.0910.663.277.8130.26
1.2光谱测量与预处理
土壤光谱测量在暗室中进行,采用美国ASD公司生产的FieldSpec3地物光谱仪测定土壤样本的光谱反射率,其波长范围为350~2 500 nm。在350~1 000 和>1 000~2 500 nm区间的采样间隔分别为1.4和2 nm,光谱分辨率分别为3和10 nm。光谱重采样间隔为1 nm,输出波段数为2 151个。光谱测量过程中每个土壤样本采集10次光谱反射率,去除异常光谱曲线后取平均值作为该样本的光谱反射率,以保证光谱测量的准确性。土壤样本的原始光谱曲线如图1所示。
土壤光谱在采集过程中不可避免地受到随机因素的影响,采集的光谱包含其他无关的噪声。为此,首先对原始光谱进行平滑处理,并在此基础上进行一阶导数变换(first derivative,FD)、二阶导数变换(second derivative,SD)、标准正态变量变换(standard normal variable,SNV)以及连续统去除变换(continuous removal,CR)。将预处理变换结果与对应样本的重金属含量进行相关性分析,将各种重金属与光谱特征变换后相关性较高的波段作为模型的特征输入参数,统计结果见表2。

图1 土壤光谱曲线
表2特征变量选取结果统计
Table 2Statistics of the selection of characteristic variables

预处理变换ZnCrCdCuAsPb连续统去除变换1211911139一阶导数变换1158576二阶导数变换5121391011标准正态变量变换562447总计333432293433
2研究方法
笔者引入ELM方法进行反演建模,并与传统的PLS方法和近年来兴起的SVM方法进行对比分析。
2.1PLS
PLS由欧洲经济计量学家Herman于19世纪80年代首次提出,是对多元线性回归建模的一种改进,可以实现多对多的建模,在建模过程中集中了主成分分析、典型相关性分析和线性回归分析方法的特点。此方法在高光谱反演领域应用较为广泛[16]。
2.2SVM
SVM是一种基于结构化风险最小的统计学习方法,它能够按照给定误差分离一组训练数据的最优化分离超平面,能处理小样本、非线性、高维数的问题,并克服神经网络中局部极小值的难点。SVM在遥感领域的应用中能够成功处理小样本训练集,并且具有较高的精度[17]。
2.3ELM
ELM由HUANG等[18]提出,是求解单隐层前馈神经网络(single-hidden-layer feedforward networks,SLFN)的一种算法。ELM以其快速学习的能力、良好的广泛性和简单的参数设置等优点而广泛应用于各个领域。根据HUANG等[18-21]研究结果,ELM原理如下。
对于一个单隐层神经网络,假设有N个任意样本(Xi,ti),其中Xi=[Xi1,Xi2,…,Xin]T=Rn,ti=[ti1,ti2,…,tim]T∈Rm。对有L个隐层节点的单隐层神经网络,可以表示为

(1)
式(1)中,j=1,2,…,N;g(x)为激活函数;Wi为输入权重;βi为输出权重;bi为第i个隐层的偏置;Wi·Xj表示Wi和Xj的内积。单隐层神经网络学习的目标是输出的误差最小,可以表示为

(2)
即存在βi、Wi和bi,使式(3)成立:

(3)
可以用矩阵表示为
Hβ=T。
(4)
式(4)中,H为隐层节点的输出;β为输出权重;T为输出期望。

(8)
在ELM中,一旦输入权重Wi和隐含层的偏置βi被随机确定,隐层的输出矩阵H就被唯一确定。训练单隐层神经网络可以转化为求解一个线性系统Hβ=T,并且输出权重β可以被确定:
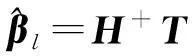
(9)
式(9)中,H+为矩阵H的Moore-Penrose广义逆。
常用的激活函数g(x)有sigmoid、sine、radialbasis、hard-limit、symmetrichard-limit、satlins、triangularbasis、linear、positivelinear和tan-sigmoid等。
2.4模型检验与评价方法
根据可见光近红外光谱预处理得到的各变换光谱进行土壤重金属含量预测时,采用决定系数R2、均方根误差(rootmeansquarederror,RMSE,ERMS)以及ERMS与预测样本平均值(M)的比值ERMS/M作为模型预测精度的评价依据。R2被广泛用于衡量模型的拟合程度,其值介于0~1之间,R2越接近于1则说明模型拟合精度越高。ERMS是实际数据与预测数据平均化的方差,是衡量平均误差的一种比较方便的方法。
考虑到预测对象在物理意义上的统计量纲以及尺度不同,采用ERMS/M统计量进行分析。ERMS/M可以反映预测误差在预测样本的整体均值中所占比例,如果所占比例过高,则预测精度应受到质疑;同时也可以将多种重金属的预测精度划归到统一尺度下进行横向对比。
3模型验证与结果分析
对每种重金属按照其浓度分布分别将30个样本按2∶1的比例划分为训练样本和预测样本,得到6组数据,每组数据包含针对每种重金属的训练和预测数据。然后针对每种重金属,将20个训练样本分别带入3种训练模型进行建模,经过多次参数修改寻优后建立最终模型;将10个预测样本数据带入模型,对模型精度进行检验和评价。
3.1模型精度分析
3种模型预测结果的R2、ERMS和ERMS/M值见表3。对3种预测方法进行对比分析,发现SVM和ELM整体上要优于PLS。在对重金属Zn、Cr、Cd和Cu进行预测时,ELM方法精度最高,其R2最高,ERMS和ERMS/M也低于其他方法;但其对于As和Pb的预测精度减弱。在预测重金属As时,虽然ELM的ERMS与ERMS/M均低于SVM,但其R2略低于SVM;在预测重金属Pb时,尽管ELM的R2略高于SVM,但其ERMS与ERMS/M均高于SVM。总体来说,在预测As和Pb时,ELM与SVM的预测精度基本相当。
表3模型检验精度统计
Table 3Statistics of accuracy validation of the models
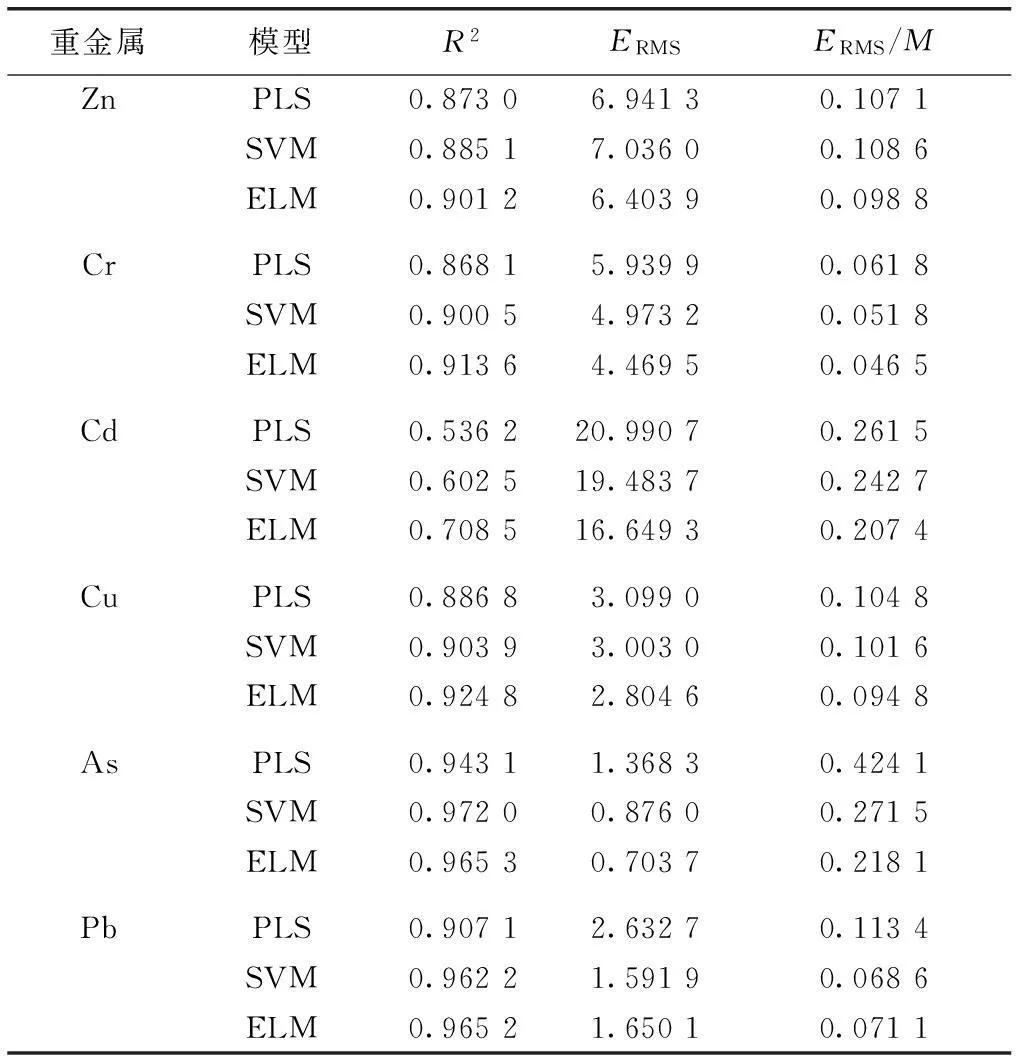
重金属模型R2ERMSERMS/MZnPLS0.87306.94130.1071SVM0.88517.03600.1086ELM0.90126.40390.0988CrPLS0.86815.93990.0618SVM0.90054.97320.0518ELM0.91364.46950.0465CdPLS0.536220.99070.2615SVM0.602519.48370.2427ELM0.708516.64930.2074CuPLS0.88683.09900.1048SVM0.90393.00300.1016ELM0.92482.80460.0948AsPLS0.94311.36830.4241SVM0.97200.87600.2715ELM0.96530.70370.2181PbPLS0.90712.63270.1134SVM0.96221.59190.0686ELM0.96521.65010.0711
R2为决定系数;ERMS为均方根误差;M为平均值。
3.2模型稳定性分析
该试验采样点分布在3个不同区域,即部分重金属样本指标存在较大差异。为分析重金属含量分布对模型的影响,分别将每种重金属按浓度进行排序,绘制浓度由低至高的分布图,如图2所示(横坐标与原始采样编号无关,只是计数样本个数)。图2中趋势线是对重金属浓度排序的拟合,浓度排序无明显线性关系且分布整体离散则以闭合椭圆形曲线表示其范围。可以看出,重金属Zn、Cr和Cd基本上呈线性(或可线性化)变化,分布整体均匀,而重金属As和Pb均存在明显的数据分团现象,难以用线性关系描述,即不同采样点重金属浓度差异较大。对比发现,在这种情况下ELM的预测能力下降,即模型稳定性下降,但其预测能力仍与SVM基本相当。对其他重金属的预测结果进行比较,发现ELM的预测能力均强于SVM。
此外,模型的稳定性可能与训练模型的样本数据量有关,具有代表性的训练样本越多,则越能训练出最接近客观实际的模型,也越能反映出模型的稳定性效能。
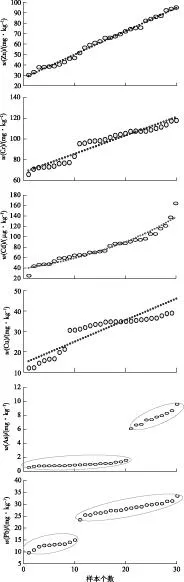
虚线为对重金属浓度排序拟合的趋势线,椭圆闭合线表示该范围
4结论
通过引入ELM建模方法,利用可见光近红外光谱对土壤重金属含量进行反演研究,采用ERMS/M统计量结合R2和ERMS对预测结果进行综合评价。ERMS/M统计量能够在一定程度上直观反映预测误差的分布情况,同时使得多种重金属的预测结果可以进行横向对比。
对3种建模方法的对比分析发现,在重金属浓度总体差异不明显时,ELM算法的预测能力强于SVM;在重金属含量空间分布差异较大时,ELM模型稳定性有所减弱,但其预测能力基本与SVM相当。总体而言,ELM算法对样本总体分布均匀的数据的预测精度要强于SVM,对样本总体分布差异明显的数据则稳定性有所减弱,但预测能力与SVM相当。后期可通过优化试验设计,获取大样本量数据进行反演预测,以探索样本数对模型稳定性的影响。
参考文献:
[1]董霁红.矿区充填复垦土壤重金属分布规律及主要农作物污染评价[D].徐州:中国矿业大学,2009.
[2]KINOSHITA R,MOEBIUS-CLUNE B N,VAN ES H M,etal.Strategies for Soil Quality Assessment Using Visible and Near-Infrared Reflectance Spectroscopy in a Western Kenya Chronosequence[J].Soil Science Society of America Journal,2012,76(5):1776-1788.
[3]SORIANO-DISLA J M,JANIK L J,VISCARRA ROSSEL R A,etal.The Performance of Visible,Near-,and Mid-Infrared Reflectance Spectroscopy for Prediction of Soil Physical,Chemical,and Biological Properties[J].Applied Spectroscopy Reviews,2014,49(2):139-186.
[4]WANG J,CUI L,GAO W,etal.Prediction of Low Heavy Metal Concentrations in Agricultural Soils Using Visible and Near-Infrared Reflectance Spectroscopy[J].Geoderma,2014,216:1-9.
[5]RATHOD P H,ROSSITER D G,NOOMEN M F,etal.Proximal Spectral Sensing to Monitor Phytoremediation of Metal-Contaminated Soils[J].International Journal of Phytoremediation,2013,15(5):405-426.
[6]LATIFI H,FASSNACHT F E,HARTIG F,etal.Stratified Aboveground Forest Biomass Estimation by Remote Sensing Data[J].International Journal of Applied Earth Observation and Geoinformation,2015,38:229-241.
[7]RODRIGUEZ-GALIANO V,SANCHEZ-CASTILLO M,CHICA-OLMO M,etal.Machine Learning Predictive Models for Mineral Prospectivity:An Evaluation of Neural Networks,Random Forest,Regression Trees and Support Vector Machines[J].Ore Geology Reviews,2015,71:804-818.
[8]SHI T,CHEN Y,LIU Y,etal.Visible and Near-Infrared Reflectance Spectroscopy:An Alternative for Monitoring Soil Contamination by Heavy Metals[J].Journal of Hazardous Materials,2014,265:166-176.
[9]BALABIN R M,LOMAKINA E I.Support Vector Machine Regression (SVR/LS-SVM):An Alternative to Neural Networks (ANN) for Analytical Chemistry? Comparison of Nonlinear Methods on Near Infrared (NIR) Spectroscopy Data[J].Analyst,2011,136(8):1703-1712.
[10]吕杰,刘湘南.利用支持向量机构建水稻镉含量高光谱预测模型[J].应用科学学报,2012,30(1):105-110.
[11]许吉仁,董霁红,杨源譞,等.基于支持向量机的矿区复垦农田土壤-小麦镉含量高光谱估算[J].光子学报,2013,43(5):102-109.
[12]谭琨,张倩倩,曹茜,等.基于粒子群优化支持向量机的矿区土壤有机质含量高光谱反演[J].地球科学,2015,40(8):1339-1345.
[13]谭琨,叶元元,杜培军,等.矿区复垦农田土壤重金属含量的高光谱反演分析[J].光谱学与光谱分析,2014,34(12):3317-3322.
[14]TAN K,YE Y,CAO Q,etal.Estimation of Arsenic Contamination in Reclaimed Agricultural Soils Using Reflectance Spectroscopy and ANFIS Model[J].IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2014,7(6):2540-2546.
[15]杨一,张淑娟,何勇.基于 ELM 和可见/近红外光谱的鲜枣动态分类检测[J].光谱学与光谱分析,2015,35(7):1870-1874.
[16]MEVIK B H,WEHRENS R.The Pls Package:Principal Component and Partial Least Squares Regression in R[J].Journal of Statistical Software,2007,18(2):1-23.
[17]COLLOBERT R,BENGIO S.SVM Torch:Support Vector Machines for Large-Scale Regression Pproblems[J].Journal of Machine Learning Research,2001,1(2):143-160.
[18]HUANG G B,ZHU Q Y,SIEW C K.Extreme Learning Machine:A New Learning Scheme of Feed Forward Neural Networks[J].Proceedings IEEE International Joint Conference on Neural Networks,2004,2:985-990.
[19]HUANG G B,ZHU Q Y,SIEW C K.Extreme Learning Machine:Theory and Applications[J].Neurocomputing,2006,70(1/2/3):489-501.
[20]HUANG G B,ZHOU H,DING X,etal.Extreme Learning Machine for Regression and Multiclass Classification[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2012,42(2):513-529.
[21]HUANG G B.An Insight Into Extreme Learning Machines:Random Neurons,Random Features and Kernels[J].Cognitive Computation,2014,6(3):376-390.
(责任编辑: 许素)
Hyperspectral Inversion of Heavy Metals in Soil of a Mining Area Using Extreme Learning Machine.
MAWei-bo1,TANKun1,LIHai-dong2,YANQing-wu1
(1.School of Environment Science and Spatial Informatics, China University of Mining and Technology, Xuzhou 221116, China;2.Nanjing Institute of Environmental Sciences, Ministry of Environmental Protection, Nanjing 210042, China)
Abstract:In recent years, the technology of visible and near infrared spectral inversion of heavy metals in soil of a mining area has been attracting more and more attention. However, the contents of heavy metals in the soil are often so trivial that their spectral characteristics are very fragile and hence the requirements of their inversions and for the models should be much higher. In a study on inversions of heavy metals in the soil of reclaimed mining areas, the technology of extreme learning machine (ELM) was introduced to inversion modeling and compared with the traditional partial least squares regression(PLS) and the support vector machine (SVM) methods. After pretreatment and correlation analysis of spectral data, the three models were used to inverse the data of 30 soil samples, and 10 of them were chosen for model validation. Results show that the model of ELM was higher than the models of SVM and PLS inaccuracy of the prediction of Zinc (Zn), Copper (Cu), Cadmium (Cd) and Chromium (Cr) and more or less the same in prediction capacity for Plumbum (Pb) and Arsenic (As) with SVM.
Key words:extreme learning machine;soil;heavy metal;remote sensing inversion;hyperspectral;reclaimed mining area
作者简介:马伟波(1991—),男,陕西宝鸡人,硕士生,主要从事高光谱反演研究。E-mail: weibo-ma@126.com
DOI:10.11934/j.issn.1673-4831.2016.02.007
中图分类号:P237;TD88
文献标志码:A
文章编号:1673-4831(2016)02-0213-06
通信作者①E-mail: tankun@cumt.edu.cn
基金项目:国家科技基础性工作专项(2014FY110800);国家自然科学基金(41471356)
收稿日期:2015-11-10
