双结构网络中URL去重机制研究
2016-04-15袁志伟
袁志伟,杨 鹏,刘 旋
(东南大学 计算机科学与工程学院,计算机网络和信息集成教育部重点实验室, 南京 211100)
双结构网络中URL去重机制研究
袁志伟,杨鹏,刘旋
(东南大学 计算机科学与工程学院,计算机网络和信息集成教育部重点实验室, 南京 211100)
摘要:针对双结构网络的特点及其URL去重面临的挑战,根据Bloom Filter的工作原理,提出一种基于可扩展的动态可分裂Bloom Filter的URL去重机制,并在原型系统中进行实现和部署。实验结果表明,该机制能够有效适用于大规模、高性能和分布式的双结构网络爬虫应用。
关键词:统一内容标签去重;动态可分裂;布隆过滤器;双结构网络;网络爬虫
当今互联网已经由服从泊松分布的随机网络演变为服从幂律分布的无标度网络[1],主要表现为极少数网站(如Google,YouTube等)拥有远远高于普通网站成千上万倍的连接数,成为互联网80%流量的主要源头[2]。并且传统网络中点对点传输的体系结构,导致热门信息在互联网中冗余传输,进一步引发互联网流量的无标度增长。为了分担互联网骨干网流量,文献[2-5]主张为当今互联网主结构增加具有广播推送能力的播存次结构,形成双结构二元互补网络,简称为双结构网络。
播存次结构由广播发送端、边缘服务器和用户终端三部分组成,如图1所示。广播发送端借助于网络爬虫将互联网中热门内容进行统一标引并形成统一内容标签UCL(Uniform Content Label),UCL的数量巨大但只有1 KB,保存于用户终端,而网页全文数据容量很大,保存于离用户若干跳的边缘服务器。卫星广播只将UCL推送到用户终端(PC机、手机、pad等),而将UCL和网页全文都推送到边缘服务器。用户通过浏览UCL摘要信息,决定是否向边缘服务器获取网页全文。只有当边缘服务器不存在网页全文时,才需要向互联网远端服务器获取。
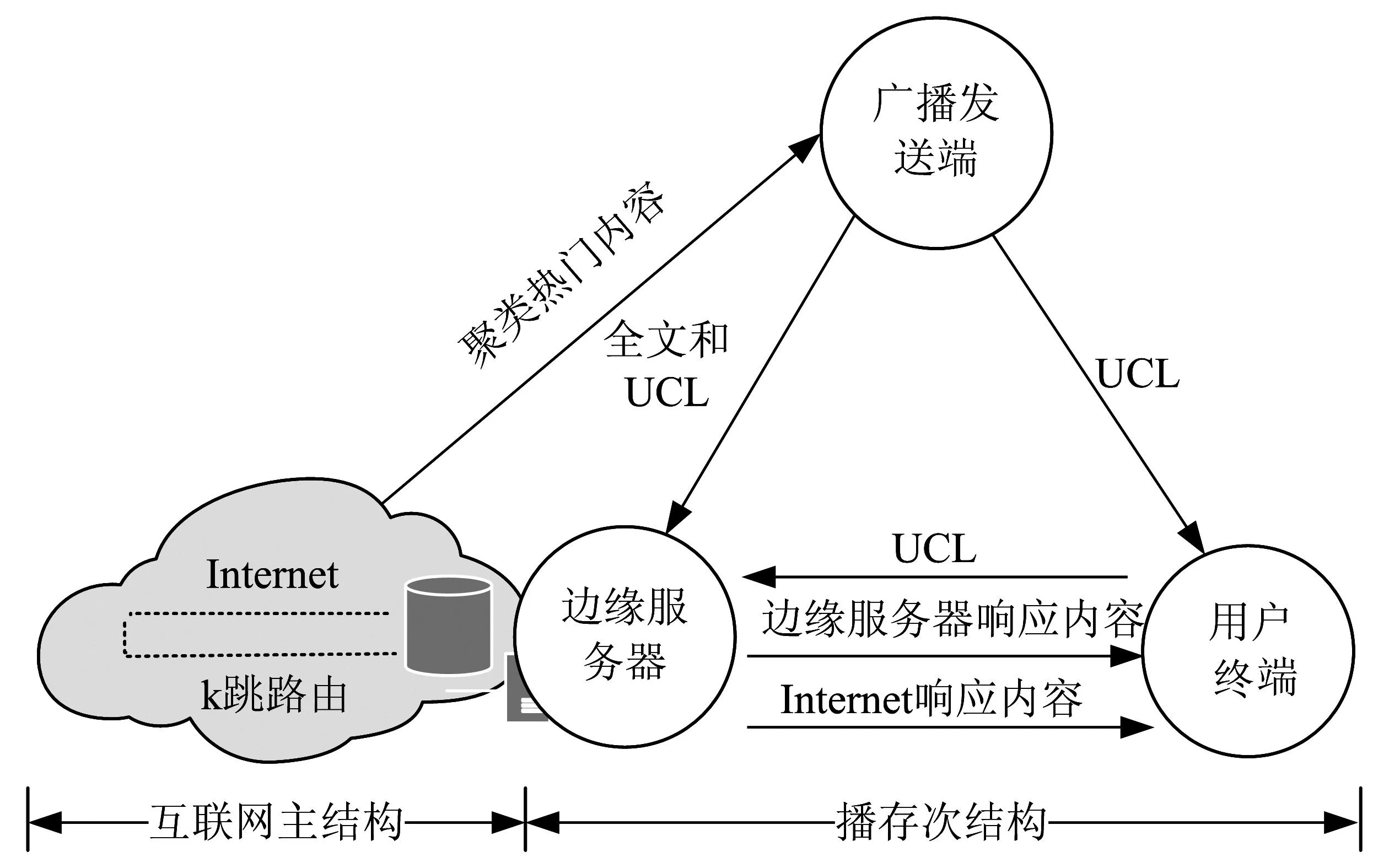
图1 双结构网络架构Fig.1 Dual-structural network
UCL的数量巨大,需要通过网络爬虫对热门内容进行自动化标引,然而互联网URL数量数以亿计且URL间可能相互链接,网络爬虫在爬取过程中会将已经爬取的URL再次加入到等待爬取的URL队列之中,这样导致网络爬虫多次下载同一个页面,消耗了网络带宽资源并降低了爬取效率。所以网络爬虫在爬取过程中需要判断每一条URL是否已经被爬取过,以避免重复爬取,这个过程称为URL去重[6],是任何一个网络爬虫亟需解决的关键问题。
笔者首先介绍了Bloom Filter的工作原理,并在综合分析了双结构网络中网络爬虫URL去重的基本需求后,提出一种针对双结构网络中去除重复URL的动态可分裂Bloom Filter。最后在原型系统中验证了该方案的有效性和可行性。
1Bloom Filter
经典Bloom Filter[7-14]由1个二进制数组和k个哈希映射函数(Map Hash)组成,用来表示一个集合,其基本工作原理是Bloom Filter通过k个哈希映射函数将元素映射为二进制数组的k个位置。当向集合插入某元素时,使用k个哈希映射函数对该元素进行k次哈希计算,并且将二进制数组中与k个哈希计算结果相对应的k个二进制位置为1。在查询某元素是否在集合中时,使用k个哈希映射函数对该元素进行k次哈希计算,只有当二进制数组中与k个哈希计算结果对应的二进制位都为1时,才判定该元素在集合中。二进制数组中的每一位初始化为0。图2为k=3时,经典Bloom Filter的示例图。

图2 k=3时经典Bloom Filter的示例图Fig.2 Example of classical Bloom Filter when k is 3
由于Bloom Filter使用哈希映射的方式存储元素,查询时有可能会发生误判(false positive)。误判是指某个不存在于集合中的元素被误判为属于该集合[7-8]。假设二进制数组的长度为m,集合中元素个数为n,则误判率f的计算公式[7-8]为:
(1)
式中,p0表示二进制数组中某一位为0的概率。理论计算表明最小误判率fmin的计算公式[7-8]为:
(2)
此时,哈希映射函数的个数k的计算公式[7-8]为:
(3)
由式(2)可知,Bloom Filter的误判率主要取决于m和n的比值,并且误判率只能减小,无法消除。所以Bloom Filter不适合“零错误率”的应用场景,但是对于容忍低误判率的应用场景下,Bloom Filter可以通过极低的误判率换取到存储空间的极大节省和读写性能的极大提高。
Bloom Filter是一个时间和空间效率很高的数据结构,它在不同领域获得了广泛的应用。文献[9]使用Bloom Filter设计了分布式的Web 缓存共享机制,文献[10]使用Bloom Filter表示De Bruijn graph,文献[11]使用Bloom Filter计算DNA的子串的数量,文献[12]则使用Bloom Filter进行深度包检测,文献[13]使用Bloom Filter存储CCN中的PIT表,文献[14]使用Bloom Filter压缩多播转发表,并对经典Bloom Filter进行了改进。
2双结构网络中的URL去重
网络爬虫的去重可以看作一个URL筛选过程。将所有URL看作一个队列Q=[x1,x2,x3, …,xN],其中N表示队列中元素的数量。如图3所示,对于每一个从队列中弹出的元素,网络爬虫都需要运行去重算法判断是否需要进一步爬取。

图3 URL去重流程图Fig.3 Graph of detecting duplicated URLs
双结构网络使用分布式爬虫并行爬取热门内容,为了尽快地将当天新增热门内容进行广播,每一个网络爬虫每天都需要爬取大量的网页,从而对URL去重的效率提出很高的要求。文献[15]指出对于一个每秒钟爬取300个网页的爬虫系统,每秒需要进行至少2 000次的URL去重查询工作。
为了加快处理效率,双结构网络使用Bloom Filter进行URL去重。除此之外,双结构网络中的URL去重策略还面临以下几个挑战:
1) 双结构网络使用内存数据库存储Bloom Filter。由于内存数据库的容量受到内存的限制[16-17],所以双结构网络中的Bloom Filter不能太长。
2) 互联网中的URL数量众多,而且会随时间增长,一段时间之后,Bloom Filter会超过预先设定的误判率的要求,需要对Bloom Filter进行扩展。所以双结构网络中的Bloom Filter应该是可以扩展的。
3) 为了避免带宽成为瓶颈,双结构网络的网络爬虫应该是分布式部署的。同时为了加快处理效率,每一个网络爬虫应该不需要和其他网络爬虫进行交互,就可以确定某一条URL是否已经被爬取过。
当前基于Bloom Filter的URL去重方案在可扩展性、性能等方面存在缺陷,并不能适应于双结构网络。Internet Archive 爬虫使用32 kB大小的Bloom Filter存储每一个域名下URL,在之后的批处理阶段会使用2 GB空间的Bloom Filter来存储多个网站的URL[6]。Apoide爬虫采用了和Internet Archive爬虫相似的思路,每一个域名都使用了一个8 kB的Bloom Filter来存储该域名下的URL[18]。但是双结构网络的网络爬虫主要爬取互联网中的热门网站,而使用一个固定大小的Bloom Filter存储热门网站的URL是不够的。
为了提高在双结构网络中Bloom Filter的并发读写效率,一种合理且高效的方案是将Bloom Filter分布式存储,增强并行化,提高效率。笔者结合双结构网络环境的特点提出了一种动态可分裂Bloom Filter(Dynamic Splittable Bloom Filter, DSBF)。
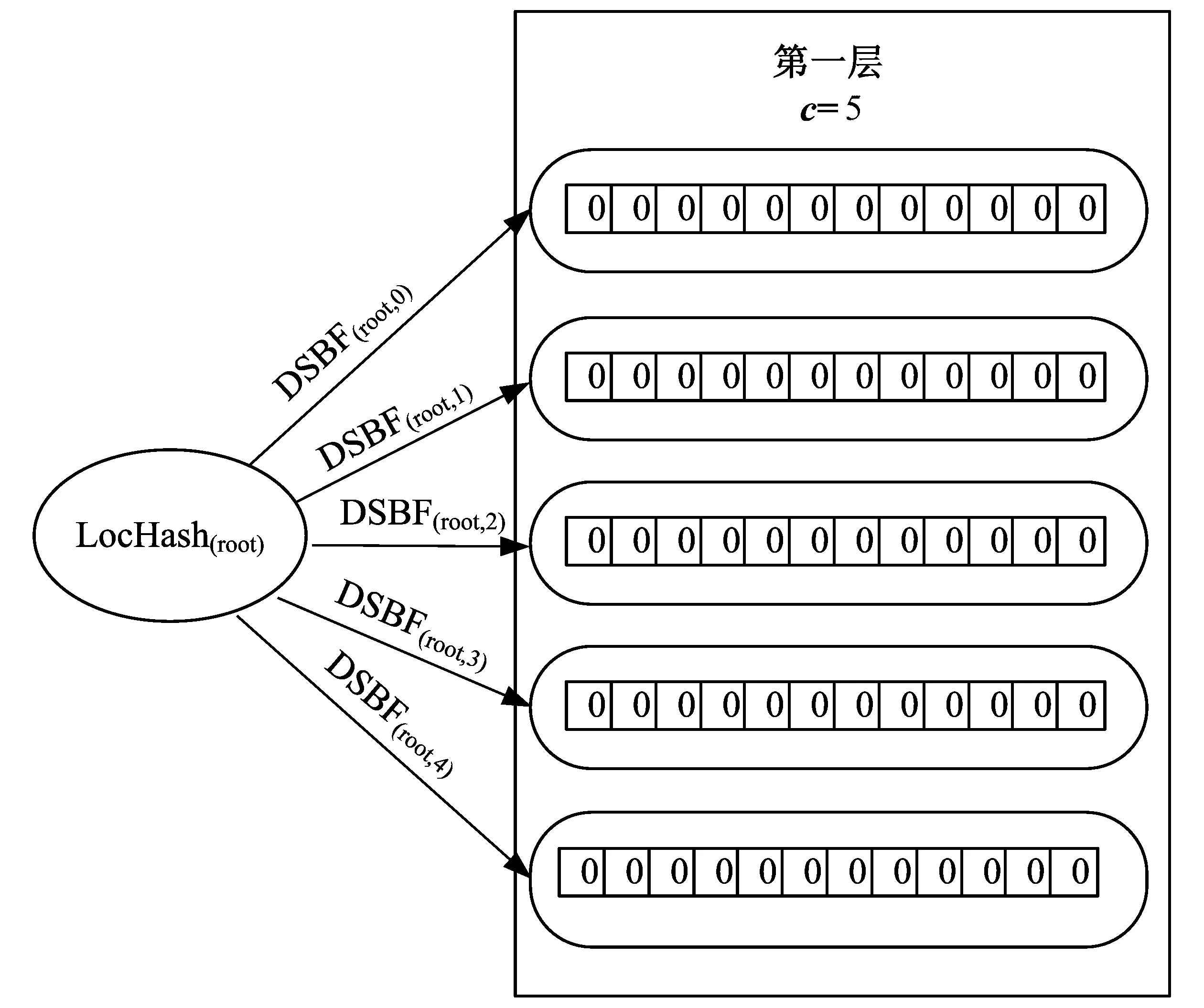
图4 初始时动态可分裂Bloom Filter的结构Fig.4 The initial structure of splitting DSBF

图5 分裂中的动态可分裂Bloom FilterFig.5 The structure of splitting DSBF
3一种动态可分裂的Bloom Filter
如图6所示,动态可分裂Bloom Filter采用树状的分层存储结构,它用到两种哈希函数,一种是经典Bloom Filter中的哈希映射函数,一种是新引入的哈希定位函数(LocHash)。根结点(第0层)中存放一个哈希定位函数。在除树根外的各层中,每一个叶结点中存放一个经典的Bloom Filter(称为叶片Bloom Filter),它用于存储元素;每一个非叶结点中存放一个哈希定位函数,它把没有存储在本结点的元素导向到它的子结点。动态可分裂Bloom Filter主要包含4种操作:初始化,插入操作,分裂操作和查询操作。

图6 分裂后的动态可分裂Bloom FilterFig.6 The structure of splitted DSBF
如图4所示,动态可分裂Bloom Filter初始时只包含根结点和第一层的c个叶结点。c表示初始时预先设定的叶片Bloom Filter的个数,c的大小由误判率上限fmax、元素个数n和每个叶片Bloom Filter的长度m共同决定。
向动态可分裂Bloom Filter插入元素时,需要对元素进行H次(H代表树的高度,H≥1)哈希定位计算,以确定该数据元素具体存储到哪一个叶片Bloom Filter中。具体过程如下:首先,使用根结点的哈希定位函数对该数据元素进行哈希计算,判断该数据元素存储到根结点的哪一个子结点中。接着,判断该子结点是否是叶结点。如果是,则将该数据元素直接存储到该叶片Bloom Filter中;如果不是,则使用该非叶结点的哈希定位函数继续上述计算过程,直至将该数据元素最终定位并存储到一个叶片Bloom Filter为止。
当某一个叶片Bloom Filter(记做结点d)存储的元素过多,导致它的误判率超过fmax时,需要对其进行分裂。具体过程如下:首先,在待分裂结点d的下一层新增c个叶片Bloom Filter,并使它们成为结点d的子结点。接着,为待分裂结点d增加一个哈希定位函数,并通过该哈希定位函数将结点d存储的数据元素通过再哈希的方式,存储到d的对应子结点(某个叶片Bloom Filter)中。最后删除待分裂结点d存储的Bloom Filter,只保留结点d的哈希定位函数。图5和图6是分裂操作的示意图。分裂过程中,动态可分裂Bloom Filter仍旧可以对外提供服务:插入数据元素时,将元素插入到待分裂结点d的子结点中,查询时,则需要查询待分裂结点d和它的子结点。
查询操作类似于插入操作。需要对元素进行H次哈希定位计算,以确定该数据存储在哪一个叶片Bloom Filter中,之后再对该叶片Bloom Filter执行具体的查询操作。
动态可分裂Bloom Filter的结构是一棵树,树中的叶结点提供读写服务,内部结点只提供元素的导向服务,所有的元素都会存储到叶结点之中。在接下来的讨论中,我们假定每一个叶片Bloom Filter二进制数组长度为m,集合中元素个数为n,误判率上限为fmax。
动态可分裂Bloom Filter的每一次分裂都是有代价的,为了减少分裂次数,它初始化之后的c个叶片Bloom Filter应该足够存储预先估计的元素个数。此时每一个叶结点可以存储的元素个数u的计算公式为,
(4)
那么c的计算公式为,
(5)
由于c必须是一个整数,而且c越大误判率会越低,所以公式5对于所求的c取上界。此时哈希映射函数的个数k的计算公式为,
(6)
任何Bloom Filter都存在误判率,动态可分裂Bloom Filter也不例外。由于动态可分裂Bloom Filter使用哈希定位的方式将元素存储到不同的叶结点中,所以它相对于单个Bloom Filter具有更好的误判率。动态可分裂Bloom Filter的查询最终都是对单个叶结点的查询,所以它的误判率主要取决于误判率最大的叶结点。那么,误判率fmax的计算公式为,
(7)
式中:s表示叶结点的个数;fi表示第i个叶结点的误判率。如果哈希定位函数的输出是完全均匀的,即元素的导向过程是完全随机的,那么所有叶结点的误判率都相等,此时误判率fmax就是任意一个叶结点的误判率,此时fmax的计算公式如下,
(8)
和式(2)进行对比可知,动态可分裂Bloom Filter可以取得比经典Bloom Filter更低的误判率。尽管这种降低是以更大的存储空间为代价,但是动态可分裂的Bloom Filter可以将叶片Bloom Filter分布式存储,存储空间不会成为动态可分裂Bloom Filter的负担。
动态可分裂Bloom Filter中包含了两种哈希函数:哈希映射函数和哈希定位函数。哈希映射函数存在于叶结点中,它的值域是{1,2,3,…,m},它的计算结果映射了叶片Bloom Filter的某一个二进制位。哈希定位函数的值域是{1,2,3,…,c},它存在于内部结点中,它的计算结果决定了内部结点将元素导向到哪一个子结点。
由于哈希定位函数和哈希映射函数的作用并不相同,所以哈希定位函数和哈希映射函数可以使用相同的常用哈希函数取模(分别对m和c取模)实现。哈希定位函数的结果决定了内部结点将元素导向到哪一个子结点,为了保证所有子结点能够均匀负担读写任务,要求不同层之间的哈希定位函数相互不同。如果不同层的哈希定位函数相同,那么会使元素的导向不再随机,造成部分叶结点无法提供读写功能。如图6所示,如果LocHash(root)和LocHash(root,3)是同一个哈希定位函数,那么所有导向到结点DSBF(root,3)的元素都会存储到DSBF((root,3),3)中,结点DSBF(root,3)的另外4个子结点将无法提供服务。但是,同一层的哈希定位函数可以相同的,这是因为同一层结点的元素导向过程不会产生相互影响,能够保证元素导向的随机性。

(9)
由式(9)可知,动态可分裂Bloom Filter的存储能力是随着H的增加以几何级数增加的。
上文为了讨论方便,设定了每次分裂都分裂为c个子结点,实际上分裂的子结点数量并不一定必须是c。
由于动态可分裂Bloom Filter的读写增加了元素从根结点到叶结点的导向过程,元素需要经过最多H次的哈希定位计算,会略微增加读写时间。但是由于其存储能力以几何级数增加,即便元素数量很多,它的层数也不会太大。经典Bloom Filter的时间复杂度为O(k),动态可分裂Bloom Filter的时间复杂度为O(k+L),而O(k)=O(k+L)=O(1)。因此,动态可分裂Bloom Filter能够取得了经典Bloom Filter同样的时间效率。
4实验与结果分析
笔者使用播存次结构原型系统中爬取的150多万URL进行动态可分裂Bloom Filter测试工作,每一个Bloom Filter都使用Redis数据库进行存储。
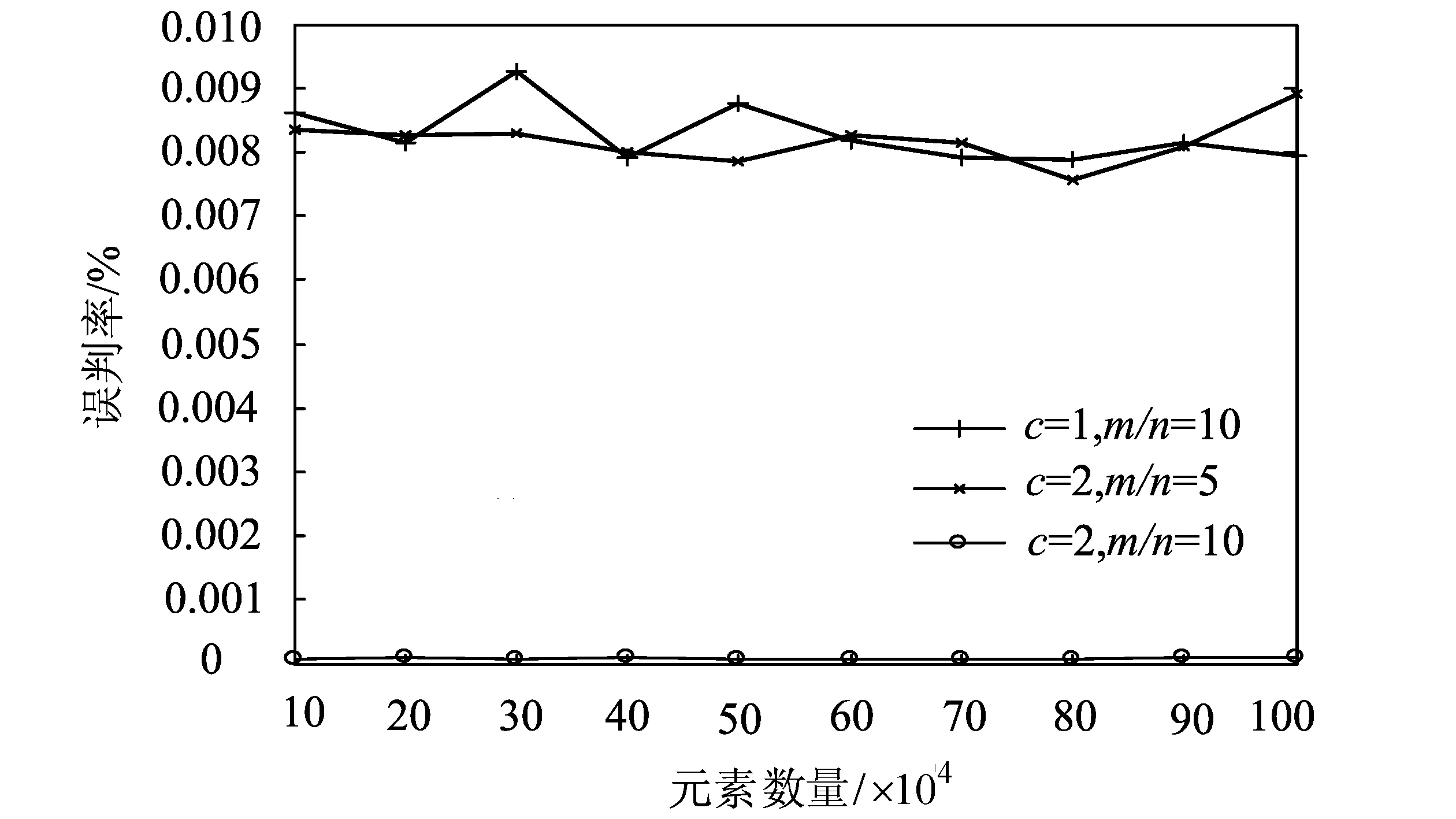
图7 动态可分裂Bloom Filter和经典Bloom Filter的误判率对比Fig.7 The false rate comparison of the DSBF and CBF
实际上经典Bloom Filter可以看作H=1,c=1的动态可分裂Bloom Filter。图7展示了两种Bloom Filter的误判率对比结果,每一条曲线都代表了H=1的动态可分裂Bloom Filter的误判率,其中c=1的曲线表示经典Bloom Filter的误判率,m表示叶片Bloom Filter中二进制数组的长度,n表示动态可分裂Bloom Filter存储的URL数量。实验首先选取n条URL存入动态可分裂Bloom Filter中,然后选取另外的n/10条URL进行误判率的计算。由图可知,在存储空间相同的情况下,动态可分裂Bloom Filter的误判率和经典Bloom Filter的误判率相同,如果使用更多的存储空间,动态可分裂Bloom Filter可以取得更低的误判率。虽然这种降低是以更多的存储空间为代价,但是由于动态可分裂Bloom Filter可以将叶片Bloom Filter分布式存储,所以存储空间的增加并不会成为它的劣势。
由于动态可分裂Bloom Filter的叶片Bloom Filter可以分布式存储,每一次的URL去重可能需要网络数据传输,所以网络延迟可能会成为动态可分裂Bloom Filter的瓶颈,一种合理且有效的方式是采用批处理的方式解决网络时延问题,即一次向动态可分裂Bloom Filter发送多条URL。
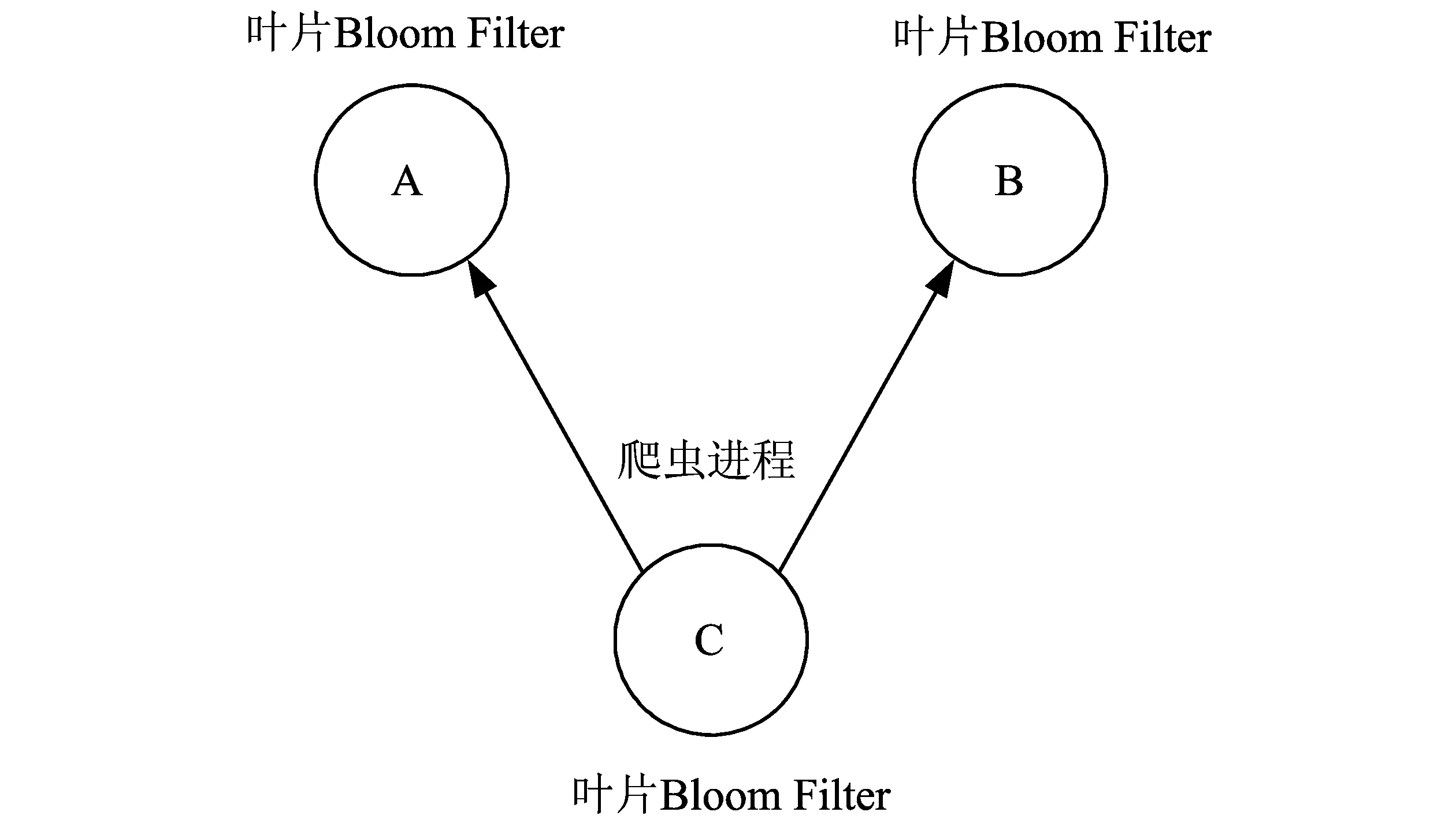
图8 去重效率实验结构图Fig.8 Experiment frame work of detecting duplicated URLs
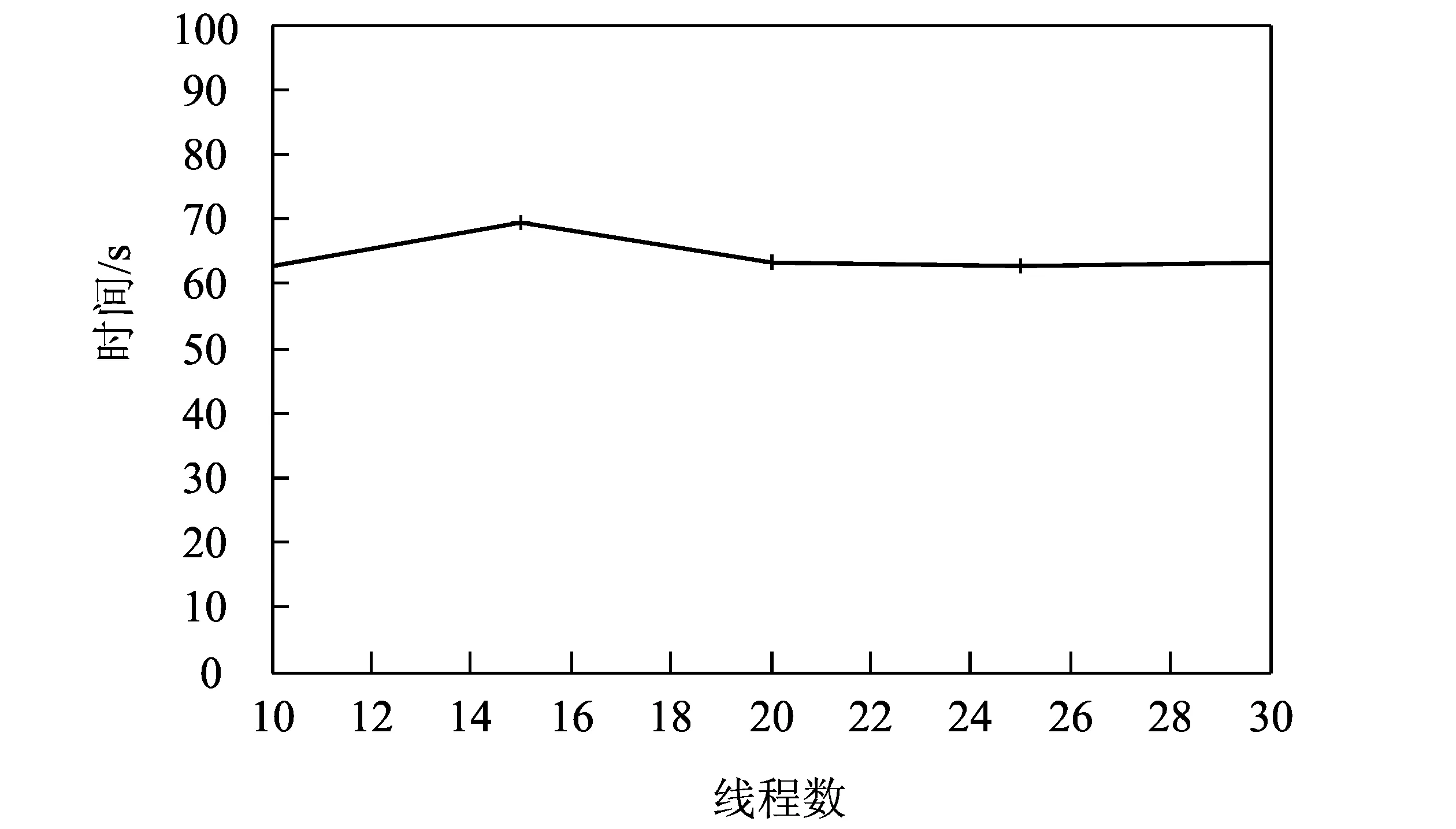
图9 去重效率实验结果Fig.9 Experiment results of detecting duplicated URLs
URL去重效率是动态可分裂Bloom Filter的重要性能指标,本文通过实验测试动态可分裂Bloom Filter的去重效率。图8展示了去重效率实验的结构图。实验构建了一个H=1,c=3的动态可分裂Bloom Filter,如图8所示,A,B,C分别存储了一个叶片Bloom Filter, C部署了一个爬虫进程,该进程通过多线程的方式进行URL的去重,每一个线程每次处理300条URL数据。实验中,通过ping命令进行测试发现,传输64 bytes数据,C点到A点时延约为0.35~0.42 ms,而C点到B点的时延约为0.38~0.45 ms。
图9为动态可分裂Bloom Filter的URL去重效率实验结果图。每一次实验都会进行100万条URL的去重,由图中可知,H=1,c=3的动态可分裂Bloom Filter每秒钟约可以处理1.5×104条URL,基本可以满足双结构网络中多个网络爬虫并行进行URL去重的需要,并且随着c的增加动态可分裂Bloom Filter的处理速率能够进一步增加。

图10 Internet Archive中每个Bloom Filter存储的URL数量Fig.10 The unmber of URLs for eachbloom filter in internet archive
Internet Archive 使用32 kB大小的Bloom Filter存储一个域名下的URL,如果k=10,根据式(3),该Bloom Filter约可以存储1.8×104URL。固定大小的Bloom Filter存储大型网站空间不足,存储小型网站又会造成空间的浪费。本文使用网络爬虫对腾讯网、新浪网、新华网等网站进行爬取,图10展示了爬虫在一天时间里所提取到的各个网站的URL数量,即为Internet Archive 爬虫中每个Bloom Filter中存储的URL数量。由图10可知,Internet Archive 爬虫32 kB大小的Bloom Filter并不足以存储热门网站的URL数量,并且由于每一个Bloom Filter存储的URL数量也不够均衡,会造成空间的浪费。如果将上述所有URL存储到H=1,c=10的DSBF中,则每一个Bloom Filter的存
储的URL数量基本均衡,图11为实验结果图。

图11 DSBF每个Bloom Filter存储的URL数量Fig.11 The number of URLs for each bloom filter in DSBF
5结论
Bloom Filter能够适用于大规模数据集合的存储和查询工作。只需要以极低的误判率为代价,它就能够大大节约存储空间并且查询和插入时间不会随着集合中元素的增加而增加。笔者介绍了Bloom Filter的原理,并围绕双结构网络中URL去重的实际需求后,提出了更加适用于分布式部署的动态可分裂Bloom Filter的URL去重机制,就其相关参数进行了理论分析,在原型系统中实验证明了其有效性和可行性。
参考文献:
[1]LI X,CHEN G.A local-world evolving network model[J].Physica A:Statistical Mechanics and its Applications,2003,328(1):274-286.
[2]杨鹏, 李幼平.二元互补未来互联网体系结构[J].复杂系统和复杂性科学,2014,11(1):53-59.
[3]杨鹏,李幼平.播存网络体系结构普适模型及实现模式[J].电子学报,2015,5(5):974-979.
[4]李幼平, 杨鹏.共享文化大数据的新机制 [J].中国计算机学会通讯,2013,5(9):36-40.
[5]顾梁,杨鹏,罗军舟.一种播存网络环境下的 UCL 协同过滤推荐方法[J].计算机研究与发展,2015,52(2):475-486.
[6]HEYDON A,NAJORK M.Mercator:A scalable,extensible web crawler[J].World Wide Web,1999,2(4):219-229.
[7]BLOOM B H.Space/time trade-offs in hash coding with allowable errors[J].Communications of the ACM,1970,13(7):422-426.
[8]BRODER A,MITZENMACHER M.Network applications of bloom filters: A survey[J].Internet Mathematics,2004,1(4):485-509.
[9]FAN L,CAO P,ALMEIDA J,et al.Summary cache:a scalable wide-area web cache sharing protocol[J].IEEE/ACM Transactions on Networking (TON),2000,8(3):281-293.
[10]CHIKHI R,RIZK G.Space-efficient and exact de Bruijn graph representation based on a Bloom filter[J].Algorithms for Molecular Biology,2013,8(22):1.
[11]MELSTED P,PRITCHARD J K.Efficient counting ofk-mers in DNA sequences using a bloom filter[J].BMC bioinformatics,2011,12(1):333.
[12]KOCAK T,KAYA I.Low-power bloom filter architecture for deep packet inspection[J].Communications Letters,IEEE,2006,10(3):210-212.
[13]HEYDON A,NAJORK M,MERC Y W,et al.DiPIT:a distributed bloom-filter based PIT table for CCN nodes[C]∥IEEE.21st International Conference on Computer Communications and Networks,USA:NY,2012:1-7.
[14]LI D,CUI H,HU Y,et al.Scalable data center multicast using multi-class bloom filter[C]∥IEEE.19th IEEE International Conference on Network Protocols(ICNP),[S.l.],2011:266-275.
[15]SHKAPENYUK V,SUEL T.Design and implementation of a high-performance distributed web crawler[C]∥IEEE..Proceedings of 18th international conference on data engineering.USA:California,2002:357-368.
[16]HAN J,E HH,LE G,et al.Survey on NoSQL database[C]∥IEEE.6th international conference on Pervasive computing and applications.Port Eliabeth:IEEE,2011:363-366.
[17]STRAUCH C,SITES U L S,KRIHA W.NoSQL databases[EB/OL].[2012-07-11].http:∥www.christof-strauch.de/nosqldbs.pdf.
[18]SINGH A,SRIVATSA M,LIU L,et al.Apoidea:A decentralized peer-to-peer architecture for crawling the world wide web[C]∥Distributed Multimedia Information Retrieval.Berlin Heidelberg:Springer,2004:126-142.
(编辑:朱倩)
Research on Detecting Duplicated URL in Dual-Structural Network
YUAN Zhiwei,YANG Peng,LIU Xuan
(SchoolofComputerScienceandEngineering,KeyLaboratoryofComputerNetworkandInformationIntegrationoftheMinistryofEducation,SoutheastUniversity,Nanjing211100,China)
Abstract:In this paper,the concept of Dual-Structural Network is firstly introduced and the principles of Bloom Filter are surveyed.Then,the basic requirements for detecting duplicated URLs in Dual-Structural Network are analyzed. Moreover,a dynamic splittable Bloom Filter for web crawlers is proposed, which can increase its capacity according to application requirements and fit large-scale, high-performance and distributed web crawlers. Finally, the feasibility and efficiency of the proposed Bloom Filter is demonstrated by a series of experiments.
Key words:duplicated URL detection;dynamic splittable;bloom filter;dual-structural network;web crawler
中图分类号:TP301
文献标识码:A
DOI:10.16355/j.cnki.issn1007-9432tyut.2016.01.014
作者简介:袁志伟(1990-),男,山东日照人,硕士生,主要从事网络安全、双结构网络的研究,(E-mail) yuluoyzw@163.com通讯作者:杨鹏,男,博士,副教授,主要从事未来网络体系结构、分布式计算的研究,(E-mail) pengyang@seu.edu.cn
基金项目:国家863计划课题基金资助项目:基于内容聚类与兴趣适配的高效内容分发技术(2013AA013503);国家自然科学基金资助项目:具有互补双结构的新型网络及关键技术研究(61472080);中国工程院咨询研究基金资助项目:国家第二网络战略研究(2015-XY-04)
收稿日期:2015-05-25
文章编号:1007-9432(2016)01-0068-07
