航天器热备份控制计算机软故障前向恢复方法*
2016-04-13丁志远刘波刘超伟王婧王振华
丁志远,刘波,刘超伟,王婧,王振华
(北京控制工程研究所,北京100190)
航天器热备份控制计算机软故障前向恢复方法*
丁志远,刘波,刘超伟,王婧,王振华
(北京控制工程研究所,北京100190)
针对航天器热备份控制计算机单机软故障,提出一种前向恢复方法.该方法依据航天器热备份控制计算机系统的先验知识,通过对内存分块管理和重分配,进行数据比对和数据同步,使得软故障情况下系统中各单机自主、稳定地恢复至独立输出完全一致.与传统的恢复方法相比,新方法针对航天器热备份控制计算机系统设置合适的故障识别与定位的方法,且不用增加任何硬件开销.利用返回飞行器GNCC控制计算机对该方法进行了实现,试验结果证明该方法正确可行,为航天器热备份控制计算机的自主恢复技术奠定良好的基础.
前向恢复;软故障;航天器控制计算机
0 引言
航天器控制系统承担姿态控制和轨道控制等任务,是航天器中最容易发生故障的分系统[1]故障百分比占37%.针对控制计算机的容错设计一直是控制系统研究的重点和热点.
N模冗余是典型的容错方法,以三模冗余(triple modular redundancy,TMR)为代表的TMR热备份控制计算机,当一个单机出现软故障时,另两个单机的输出可将故障掩盖,系统输出结果无误;但是,如果该单机不能从软故障中恢复,再有另一单机出现故障,系统则不能工作在TMR模式[2-3].目前国内的航天器控制计算机系统并不具备自主恢复功能,针对热备份计算机系统的恢复方法也主要是以卷回恢复方法为主[4]需要将整个系统卷回至之前的正确状态,卷回过程会浪费大量的时间.
前向恢复方法是指从出错时刻以后的某一时刻点处开始恢复.执行的任务不并需要再重新执行前一段己执行过的代码,从而极大的减少了恢复时间,并可以避免因在卷回恢复时存在的某些不足.根据实现方式的不同,概括起来有如下两种实现方式:推导型前向恢复是指在恢复时,根据要进行恢复模块的性质以及之前运行结果的规律,推导或预测出其出错时或未来的运行状态并以此为故障恢复点继续运行[5].复制型的前向故障恢复通常是通过将非故障单机的当前状态和内存数据拷贝到故障单机上,使故障单机与正常单机的状态一致后,从当前点继续运行[6].通常在N模冗余系统中常采用复制型前向恢复方法.
文献[7]给出了一种基于内存标记的前向恢复方法,将发生故障前一周期发生改变的数据传送给故障单机,从而使故障单机恢复,该方法的弊端是定位故障的效率不高;文献[8]提出了一种在线检测前向恢复技术,实时性很强,但需要从硬件层面构建整个系统的恢复功能,只能在新的型号中进行应用;文献[9-10]采用的扫描链前向恢复方法需要构建一个具备扫描链功能的仲裁逻辑,该逻辑并不具备冗余和恢复功能,不能满足控制系统的可靠性要求.
航天器热备份控制计算机采用完全同构的N模冗余技术,以控制周期为执行单位,内存中待恢复的数据也具备周期性的特点[11].为了及时可靠地将计算机系统从单机软故障中恢复出来,本文提出一种适用于航天器热备份控制计算机的单机软故障的前向恢复方法.该方法根据热备份控制计算机的特点针对标记内存技术进行优化,使得控制计算机能从软故障中连续、稳定地恢复,降低整机失效的概率,使控制计算机保持连续稳定高可靠的工作.
1 理论模型
系统初始状态为TMR三机正常状态,若一个单机出现软故障,则另两个正常单机可将故障机的故障屏蔽,输出仍然正确;但是,如果该单机不能从软故障中恢复,错误导致单机故障,则系统进入TMR双机正常状态,不再具备单故障屏蔽能力;此时若再有一台单机出现故障,则系统降级为TMR异常模式.如图1所示,设单机失效率为λ,则根据假设,若某模块在时刻t正常工作,则在t+Δt时刻发生故障的概率为P=1-e-λΔt,对于很小的Δt,该故障率可简化为λΔt.依此可推知可测单机故障概率为λΔt,同构的3个单机中任意一个单机发生故障,则系统进入双机状态,概率为3λΔt,同理双机状态降级为单机状态的概率为2λΔt.通过恢复技术,使该单机从其它两机中获取正确状态,使其从软故障中恢复,系统从TMR双机异常模式恢复为TMR三机正常模式.如图1所示,设单机恢复率为μ,则系统从双机状态恢复为三机状态的概率是μΔt,则系统从双机状态降级为单机状态的概率将减少μΔt,所以实现单机恢复功能,提高单机恢复率,可以有效避免系统降级,增加系统可靠性.

图1 TMR热备份控制计算机单机恢复马尔可夫模型Fig.1Markov model of single modular recovery for TMR hot-backup control computer
如图2所示,T0是发现故障的初始周期,L0是初始的故障数据长度,在恢复过程中,非故障单机执行完常规控制任务后,在每个周期的末尾将故障数据以Ls的速率传递至故障单机,故障单机停止常规任务的执行,接收非故障单机的传输数据,设非故障单机在执行控制任务的过程中内存数据在第n周期的变化速率是Lc(n),当第n周期结束后,故障单机接收的数据总量nLs≥L0时,非故障单机将所有故障数据以及恢复过程中的变化数据传递给故障单机,即认为恢复成功,推导过程如下:

将上述n个等式相加化简可得:

Ln是第n周期后还需再恢复的数据长度,当Ln=0时,即恢复成功,将Ln=0代入式(1):

记Lc是n个周期中内存变化速率的平均值,即

代入式(2)得:

当Ls>Lc时,Ls-Lc>0,使得恢复在理论上可行,即每次迭代可以恢复一些未被恢复的内存数据.经过一系列的迭代,直到所有的内存块都被恢复,此时故障单机恢复完成.
对于一个特定的系统而言,Lc是常量,所以要增加恢复的速率(减小n值),需减小L0或增加Ls,即减小初始数据的长度或增加数据的传输速率.传输Ls长度的数据需要先利用tc的时间进行故障数据定位,再利用ts的时间进行故障数据的传输,恢复过程所允许的最大时间长度tR≥tc+ts时,恢复可以成功,否则恢复失败.

图2 恢复方法模型Fig.2Recovery method model
2 故障识别、定位及数据同步方法
在恢复过程开始前,根据系统比对结果判断系统是否出现软故障.若发生故障,则在控制周期的末尾执行恢复过程,不影响采集、计算、系统任务的常规执行过程;整个恢复过程对应用软件透明,从而减少系统软件与应用软件的耦合性.如图3所示,恢复过程可以分为故障判定模块和数据同步模块,故障判定模块识别故障状态并决定是否启动数据同步模块;数据同步模块对故障判定模块记录的故障内存块进行同步操作,使故障单机完全跟上非故障单机的任务操作,并判定恢复过程是否结束.
2.1 故障识别
如图4所示,A、B、C各单机通过向其他两个单机发送数据来实现关键数据的交换与比对,各自的仲裁模块可以通过对交换的数据进行三取二表决来判定本单机是否发生故障,然后向其他单机发送自己的故障状态,若该单机发生故障,则接受该单机故障信息的一个单机负责对该单机进行恢复.

图3 恢复任务执行示意Fig.3Recovery task execution

图4 航天器控制计算机故障识别Fig.4Spacecraft control computer fault-identification
2.2 故障定位
2.2.1 标记内存方法
同构的N模冗余计算机系统N各模块内存中的数据是完全同步的,令第n周期系统的单机内存状态集合是Mn,第n周期到第n+1周期内存的变化集合是Cn+1;假设某单机在第n+1周期发生了故障,则非故障单机在第n+1周期的内存状态集合是Mn+1,改变的数据集合是Cn+1,故障单机在第n+1周期的内存状态集合是,改变的数据集合是设发生故障的数据集合是Fn+1.
因为:

故:

所以将发生故障的最近一个周期中,非故障单机内存中与故障单机不一致的数据发送给故障单机,即可使故障单机获得恢复.
把一个N字节的主存储器分割成M个N/M字节的内存块,并设立一个带有M个标记的标记字段,用来记录每个内存块在最近一个控制周期是否被修改,若发生修改则对应标记位被置为“dirty”,如图5所示.这样便可以知道发生故障前一个控制周期的数据变化情况,通过数据同步模块持续不断地扫描并同步那些被标记为“dirty”的内存块,并把该内存块对应的标记位置为“clean”.如果恢复任务找不到“dirty”的内存块就判定恢复过程结束.

图5 内存块标记映射Fig.5Mapping from memory block to Tags
2.2.2 标记内存方法的优化
对于控制计算机而言,f(n)=f[f(n-1),xn]是第n个控制周期的输出,xn是三机在第n个控制周期的采集输入.内存中的数据变量可以分为f(n)和xn两种(即运算数据和采集数据),其中f(n)随着每个周期的迭代可能发生改变且很难预测,当故障发生时需要进行及时同步;xn是每个控制周期起始的采集任务进行输入的变量,每个周期一定发生改变,由于故障单机在恢复期间不需要执行常规的控制任务,所以不需要对该部分数据进行恢复,当系统在某一个控制周期m判定恢复成功,则在第m+1个控制周期开始采集输入xm+1.
统计内存的变化频率,并根据结果重分配,如图6所示,将变化频率接近的内存块聚集在一起,并将需要进行甄别和恢复的f(n)和不需要恢复的xn分开进行存储.并且当xn部分的内存数据发生改变,不修改对应的内存块标记.对于除xn以外每个周期都会发生改变的数据则不进行内存标记的判断,直接传输给故障单机.在数据同步阶段,按照访问频率从低到高将被标记为“dirty”的内存块依次传输给故障单机,以避免重复传输.
本优化方法可以很大程度上减小初始数据的长度和每个周期的数据变化量,从而提高故障数据定位的效率.
2.3 数据同步
当故障单机被识别出来且待恢复数据被定位完成后进入数据同步过程,由于航天器热备份控制计算机不具备共同的仲裁和交互机构,所以需要利用网络式的通信协议建立数据同步机制,使得故障单机可以正确的接收和处理非故障单机发送给它的数据和状态信息.
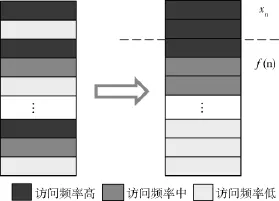
图6 内存块分布的优化Fig.6Optimization of memory block distribution
如图7所示,第一个阶段,故障单机进入数据同步过程后,向非故障单机发送一个“ready”信号,表明自己处于接收状态,并停止常规控制任务的运行以等待非故障单机传输数据,非故障单机进入数据同步过程后,便进入等待状态,等待故障单机发来的“ready”信号,收到“ready”信号后便将数据和地址信息打包传输给故障单机;第二个阶段,非故障单机以同步的速率向故障单机发送打包数据,故障单机接收数据包并存放在相应的地址空间中;第三个阶段,若非故障单机的内存块标记字段中不存在标记为“dirty”的标记时,便停止向故障单机发送数据,并发送“finish”信号通知故障单机恢复过程结束,故障单机接收到非故障单机发送来的“finish”信号后,停止接收数据并向故障单机发送一个回答信号,退出恢复过程,开始继续执行常规控制任务,故障单机收到应答信号后也结束恢复过程.

图7 数据同步Fig.7Re-synchronization of memory data
3 实验验证
GNCC硬件采用某SPARC架构芯,三机间传输速率为115 200 bps;实验中令GNCC软件系统在每个控制周期依次执行采集和控制任务、三机交换任务及恢复任务;实验型号计算机上设立任务周期设为600 ms,任务空闲时间为50%,平均每个控制周期采集输入数据约占高频变化数据的50%,从植入故障的周期开始计数.
首先,在系统中开辟64 KB实验内存空间模拟恢复任务覆盖的容错区域,内存块大小为64 B,开辟1 024 B用于内存标记字段,并建立同数据区域的映射;其次,改写采集和控制任务,分别模拟在实际任务中,使用两种不同的内存标记方法内存的变化情况;最后,在采集和控制任务中通过软件方式在某一单机上注入故障,使其不能正常同步,当平均每周期变化数据小于传输速率时可以恢复成功.
从试验数据中可以看出优化后的方法具有更高的恢复效率.
在试验对照组Ⅰ中令:(1)4 KB的内存空间每个控制周期都在发生改变,(2)16 KB的内存空间每4个控制周期改变一次,(3)其他内存空间中抽取16 KB,每8个控制周期改变一次,实验数据见表1.

表1 实验对照组ⅠTab.1Experiment groupⅠ
在实验对照组Ⅱ中令:(1)8 KB的内存空间每个控制周期都在发生改变,(2)8 KB的内存空间每4个控制周期改变一次,(3)其他内存空间中抽取8 KB,每8个控制周期改变一次,实验数据见表2.

表2 实验对照组ⅡTab.2Experiment groupⅡ
在实验对照组Ⅲ中令:(1)8 KB的内存空间每个控制周期都在发生改变,(2)4 KB的内存空间每4个控制周期改变一次,(3)其他内存空间中抽取8 KB,每8个控制周期改变一次,实验数据见表3.

表3 实验对照组ⅢTab.3Experiment groupⅢ
从表1~3可知,在既定的软件和硬件条件下,改进的内存标记方法比改进前的内存标记方法有着更精准的故障定位能力,而且还具备更高效的数据传输效率,平均可以将恢复效率提高到3至7倍.
4 结论
本文提出的改进的内存标记恢复方法可以在不中断系统工作的情况下,对航天器热备份计算机进行恢复.恢复过程通过软件实现,不需要增加硬件支持,优化后的方法可以大幅度提升恢复效率.
[1]林来兴.1990—2001年航天器制导、导航与控制系统故障分析研究[J].国际太空,2005(5):9-13.LIN L X.The failure analysis and research of spacecraft control,guide and navigation system during 1990—2001[J].International Space,2004(5):9-13.
[2]杨孟飞,郭树玲,孙增圻.航天器控制应用的星载计算机技术[J].航天控制,2005,23(2):69-73.YANG M F,GUO S L,SUN Z Q.On-board computer techniques for spacecraft control[J].Aerospace Control,2005,23(2):69-73.
[3]YANG M F,LIU B,GONG J,LIU H J et al.Architecture design for reliable and reconfigurable FPGA-based GNC computer for deep space exploration[J].Science China,2016,59(2):289-300.
[4]陆阳,王强,张本宏,等.计算机系统容错技术研究[J].计算机工程,2010,36(13):230-235.LU Y,WANG Q,ZHANG B H,et al.Research on fault-tolerant technology for computer system[J].Computer Engineering,2010,36(13):230-235.
[5]DHIRAJ K P,NITIN H V.Roll-forward checkpoint scheme:novelfault-tolerantarchitecture[J].IEEE Transactions on Computers,1994,43(10):1163-1174.
[6]SCHNEIDERF B.Implementing fault tolerant services using the state machine approach:a tutorial[J].ACM Computing Surveys,1990,22(4):229-319.
[7]STUART J,ADAMS,TERRY S.A tagged memory technique for recovery from transient errors in fault tolerant systems[C]//The 26thReal-Time Systems Symposium.New York:IEEE,1990.
[8]YU S Y,MCCLUSKEY E J.On-line testing and recovery in TMR systems for real-time applications[C]//Test Conference Proceedings.New York:IEEE,2001.
[9]MOJTABA E,SEYED G M,HOSSEIN A.SCTMR:A scan chain-based error recovery technique for TMR systems in safety-critical applications[C]//DesignAutomation&Test in Europe Conference&Exhibition.New York:IEEE,2011.
[10]GUPTA B,RAHIMI S,LIU Z.Low-cost scan-chainbased technique to recover multiple errors in TMR systems[C]//IEEE Transactions on very large scale integration(VLSI)system.New York:IEEE,2013,21 (8):1454-1468.
[11]王振华,张国峰,陈朝晖.交会对接GNC软件的自动测试[J].空间控制技术与应用,2012,38(5):42-49.WANG Z H,ZHANG G F,CHEN Z H.Automatic test of GNC soflware for spacecraft rendezvous and docking[J].Aerospace Control and Application,2012,38 (5):42-49.
Forward Recovery Technique of Single Modular Soft-Fault in Hot-Backup Control Computer
DING Zhiyuan,LIU Bo,LIU Chaowei,WANG Jing
(Beijing Institute of Control Engineering,Beijing 100190,China)
Aiming at single modular soft fault of hot-backup spacecraft control computer,a new recovery technique is presented in this paper.Based on the apriori knowledge of spacecraft hot-backup control computer,this algorithm,via tagging and reallocating memory,can make the fault computer in the system stably recover to the status that can output the same data with the non-fault ones.Compared with the traditional recovery technique,the proposed method presents new fault identification and location strategies without any hardware cost.The new algorithm is verified in spacecraft GNCC systems.The results of the experiment show that the new technique can lay good foundation of the recovery technique of spacecraft hot-backup control computer.
roll-forward recovery;soft fault; spacecraft control computer
TP2;TM6
A
1674-1579(2016)06-0047-05
10.3969/j.issn.1674-1579.2016.06.009
丁志远(1990—),男,硕士研究生,研究方向为容错计算技术;刘波(1977—),男,研究员,研究方向为容错计算技术和星载计算机体系结构;刘超伟(1982—),男,高级工程师,研究方向为容错计算技术和集成控制系统;王婧(1986—),女,软件工程师,容错计算技术和嵌入式操作系统;王振华(1981—),男,高级工程师,研究方向为航天嵌入式软件技术.
*国防基础科研(JCKY2016203B006)资助项目.
2016-09-10
