基于DTW距离的时序NDVI数据植被信息提取——以秦巴山区为例
2016-04-11韩晓勇陈鲁皖
韩晓勇,韩 玲,陈鲁皖
(长安大学 地质工程与测绘学院,陕西 西安 710054)
基于DTW距离的时序NDVI数据植被信息提取
——以秦巴山区为例
韩晓勇,韩玲,陈鲁皖
(长安大学 地质工程与测绘学院,陕西 西安 710054)
摘要:秦巴山区是我国重要的生态屏障,对该区的植被信息提取开展研究,可为区内生态服务功能及自然资源开发利用提供基础数据。通过加窗处理改进DTW距离相似性算法,结合临近度模糊分类方法对2005—2014年的MODIS NDVI时序数据进行植被信息提取。首先利用S-G滤波对MODIS NDVI时序数据进行重建;再利用2013年的采样数据构建各类植被的标准NDVI时序曲线,逐像元计算与标准NDVI时序曲线的加窗DTW距离,利用临近度模糊分类实现植被信息提取;最后验证提取精度。结果表明,算法具有较高的运行效率,可避免错误匹配,以较高的精度(总体精度83.8%,kappa系数0.77)实现长时间序列的植被信息提取。
关键词:NDVI;时间序列;加窗DTW;临近度;模糊分类
植被是生物圈的主要构成部分,是陆地生态系统的主体,其生长和分布受环境制约,可作为气候变化的指示因子[1]。卫星遥感从不同时间、空间尺度和不同光谱波段进行对地观测,获取大量的观测数据,在资源调查与植被变化监测等方面得到广泛应用。植被指数是植被监测的最佳指示因子之一,其中以归一化植被指数(NDVI) 的应用最为广泛[2]。MODIS NDVI产品数据更以其高时间分辨率,较长时间跨度和容易获取的优势被广泛应用于植被信息提取及变化监测[3-4]。不同植被类型在其生长周期内拥有不同NDVI时序特征,例如落叶林表现为振幅较大的单峰曲线,一年两熟的农田则为双峰曲线,可利用植被自有时序特征进行植被信息的识别[5]。Geerken利用傅里叶滤波进行NDVI时序重建,使用相似性度量方法提取草地植被类型[6]。Wardlow通过MODIS NDVI时序决策树来提取美国中部农作物信息,总体精度达84%[7]。那晓东等将离散的傅里叶变换应用于NDVI时序重建,采用傅里叶组分的相似度方法提取三江平原湿地植被信息,总体精度达79.67%,Kappa系数为0.752 5[8]。Peng利用水稻灌水期NDVI时序特征提取湖南省水稻种植面积[9]。管续栋对MODIS NDVI时序去噪后,引入动态时间规整(DTW)距离相似性方法,提取泰国东北部地区单季稻、双季稻面积,总体精度为83.38%[10]。
秦巴山区是我国重要的生态屏障,是南水北调中线工程的主要水源地,对该区域的植被信息实现高精度提取,可为其生态服务功能定位及对自然资源的合理开发利用提供基础数据。本文以2013年的野外调查数据为基础,利用时序曲线相似性评价的方法提取研究区内2005—2014年的植被特征,利用2014年的验证数据评价提取精度。
1研究区概况
选择陕西省内的秦巴山区为研究区,主要包括商洛市、汉中市和安康市,由于西安市、宝鸡市南部也属于秦巴山区,故将两市也纳入研究区(见图1),研究区总面积98 713 km2。秦岭是黄河、长江两大水系的分水岭和我国南北气候分界线,北坡为暖温带气候,南坡为北亚热带气候,在陕西境内连绵约500 km,海拔多在1 000 m以上,主峰太白山海拔3 767 m。巴山是嘉陵江和汉江的分水岭,北麓为北亚热带气候,南麓为中亚热带,海拔平均1 500~2 500 m。研究区是陕西省最大最主要的林区,属于暖温带落叶阔叶林和北亚热带常绿落叶阔叶混交林地带。秦岭与巴山之间,分布着汉中盆地、西乡盆地、安康盆地、商丹盆地和洛南盆地,盆地内耕地集中,农业生产水平较高,是陕南重要的农业生产区和人口聚居区。此外研究区还包括部分渭河平原和渭北旱塬丘陵沟壑区。秦巴山区气候具有明显的过渡特征,植被类型丰富,按照国家土地利用现状分类方法,结合遥感数据的分辨率特征,本文以水田、旱地(含水浇地)、有林地和灌木林4个二级类和1个草地一级类进行特征提取。
2数据及预处理
2.1MODIS NDVI数据
从EOSDIS(http://reverb.echo.nasa.gov/)下载研究区2005—2014年的MODIS植被指数产品(MOD13A2),空间分辨率1 km,16 d一期数据,10年共230期数据。使用MRT工具将每期HDF文件中NDVI和NDVI 质量控制文件进行拼接、裁剪,统一转换到WGS84 UTM N49投影带,并利用质量控制文件剔除质量差的像元。
2.2野外采样与验证数据
2013年4月至7月及9月对研究区内植被情况进行野外调查,共调查样点173个,为弥补野外调查样点的不足,本文利用2013年、2014年World view的高清影像,结合野外实测数据的判读特征确定130个精度验证点,两类样点的空间分布见图1。

图1 研究区地理位置及样点数据分布
3研究方法
3.1S-G滤波算法原理
理论上植被的NDVI时序曲线应是连续平滑的,但由于传感器自身性能、太阳光照角度、观测视角及云、大气气溶胶等观测条件和随机干扰因素的影响,导致NDVI时序曲线呈锯齿状的不规则波动,反映季节变化趋势不明显,限制NDVI时序在植被覆盖变化分析和信息提取等领域的应用,为此发展一系列NDVI时序重建的方法[11]。选用较常用的Savitzky-Golay(S-G)滤波方法对MODIS NDVI产品进行数据重建,S-G滤波是一种移动窗口的加权平均算法,其设计思想是利用n阶多项式来拟合滑动窗口内时序数据,多项式系数使用最小二乘法得出,NDVI时序数据集的S-G滤波过程可描述为
(1)
式中: Y*为S-G时序重建数据;Yj+i代表原始时序数据;Ci为滤波系数;N为归一化因子;m为滑动窗口宽度。
通过不同参数设置对比,选用二阶多项式,滑动窗口宽度(m=2)为5,归一化因子N为35,这既保证拟合效果,又避免过度拟合。由于滑动窗口宽度为5,滤波处理后重建的时序的长度减少为19,即损失最初两期(1月份)和最后两期(12月份)的数据,这两个月份对于植被特征标志意义不大,故本文只用滤波后每年19期重建数据进行相似性计算。
3.2加窗DTW距离
利用2013年调查数据的NDVI均值曲线作为各植被类型标准生长曲线,再逐年计算各像元时序曲线与标准生长曲线的DTW距离。年际间植被生长的水热条件、光照条件不尽相同,从而导致植被每年的NDVI时序曲线发生不同程度的扭曲,因此DTW距离更适合该类时序曲线相似性评价。
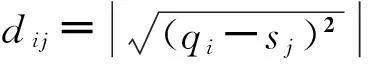
(2)

(3)

边界条件:w1=dmn,wK=d11,该路径的起止元素为距离矩阵的斜对角线的两端元素;连续性:若ws=dr,c,ws-1=dr′c′,0≤r-r′≤1 且0≤c-c′≤1,保证路径中相邻元素的连续性;有界性:max(m,n) ≤K≤m+n-1,路径所经过的矩阵元素个数K存在上限和下限。
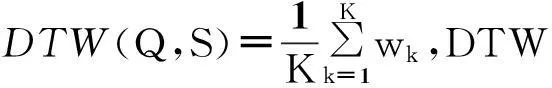
3.3临近度模糊分类
从模糊分类的角度,遥感数据的混合像元即不完全属于或完全不属于某个类别,使用贴近度来描述模糊集与标准模糊集靠近程度,将混合像元贴近度最高的类别作为该像元的归属类别。模糊集定义为待识别的像元与各植被类型参考时序曲线的DTW距离,标准模糊集是各类别参考时序曲线间的DTW距离,式(4)~式(6)为贴近度计算过程。
(4)
(5)
(6)

4结果及精度评价4.1标准时序曲线
使用迭代处理消除样点数据受混合像元及植被类型变化的影响。首先提取S-G 滤波后的NDVI样点数据,逐期计算各类均值作为初始参考曲线,再计算各样点与初始参考曲线的DTW距离,将DTW距离大于2倍标准差的样点进行剔除,将剩余样本点计算新的参考曲线,重复迭代过程,迭代计算的控制条件是前后两次参考曲线的DTW距离变化小于0.000 1,最终确定各类标准时序曲线(见图2)。图2中水田和旱地NDVI值的年内变化均为双峰结构,这与一年两熟的生产方式一致;水田的NDVI上升时间最早,结束较晚,生长期比旱地区长。草地、灌木林与有林地均为单峰曲线,65—129日三者的NDVI增长较快,此时为展叶期到快速生长阶段;129—273日NDVI处于平稳高值区,植被稳定生长;273日以后NDVI快速衰落,植被进入休眠阶段。

图2 各地类标准时序曲线
4.2加窗DTW距离算法效率
加窗DTW距离算法的设计目的是减小计算量,本文使用IDL语言将传统DTW算法和加窗
DTW算法进行对比测试,在CPU主频3.3 G HZ、内存4 G的硬件配置下,计算研究区383行518列每年19期数据的平均耗时分别为:传统DTW算法42.815 73 s,加窗DTW算法25.744 16 s,加窗DTW算法可提高39.87%的计算效率。另外,加窗算法能有效避免错误匹配,本文对水田和旱地样点数据进行错误匹配测试,加窗算法可避免18.6%的错误匹配。
4.3模糊分类
表1为各类参考时序曲线之间的DTW距离,表中的每列(或每行)是对应地类的标准模糊集。可见水田、旱地与草地、有林地、灌木林的DTW距离较大,说明水田、旱地与另外3类之间较易区分。灌木林与草地和有林地的DTW距离较小,说明三者之间易发生错分,尤其是灌木林与有林地的DTW距离为0.013 8,二者之间错分的可能性最大。

表1 标准模糊集
按照贴近度最大原则对研究区2005—2014年的植被类型进行特征提取,结果见图3。图中各地类信息的空间分布合理,水田主要分布在汉中、西乡和安康盆地,旱地分布在商丹和洛南盆地以及渭河平原区,有林地主要分布在秦岭与巴山山区,灌木林和草地主要分布在耕地与有林地的过渡地带。表2为各植被类型面积统计,2005—2014年有林地面积缓慢增加了约2 500 km2,旱地面积减少较多,尤其在2011年陕西实施的“避灾扶贫移民搬迁工程”后旱地面积显著减少,减少的主要是山区的坡耕地,其它3类的面积变化较小。
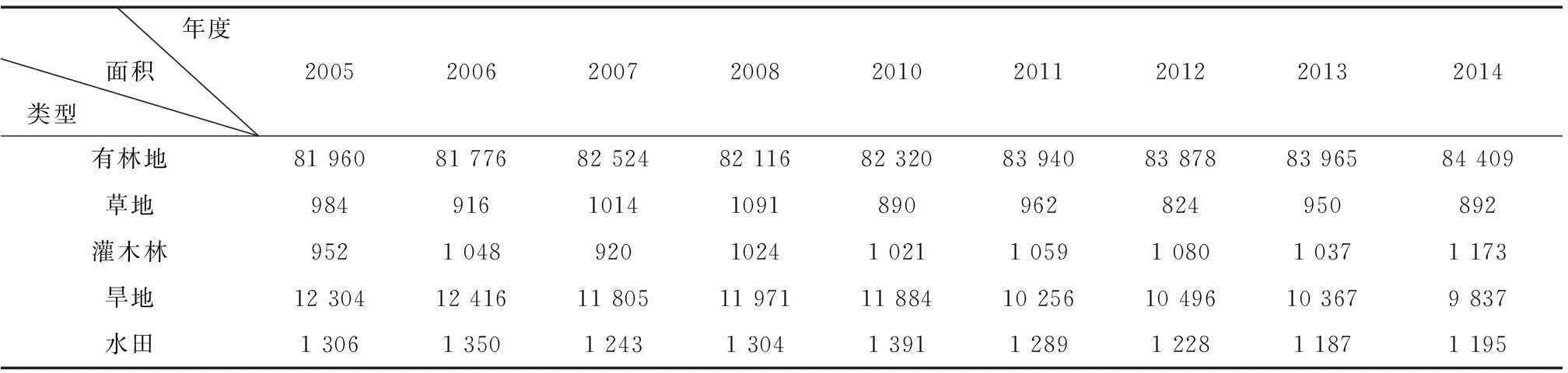
表2 各植被类型面积统计 km2
4.4分类精度
使用130个验证点对提取结果进行精度分析,得到分类混淆矩阵见表3。本文算法总体分类精度为83.8%,Kappa系数0.77,说明利用DTW距离与模糊分类相结合的方法可以较高精度提取各类植被。水田与旱地的制图精度较低,二者的漏分误差较高,图2中旱地与水田的分布特征也显示该特点。草地与灌木林的用户精度较低,说明两类的错

表3 分类精度
分误差较大,图3中可见灌木林与草地主要分布在有林地与耕地的过渡地带,这类地物在遥感影像中主要以混合像元形式存在,从而导致它们的用户精度较低。
利用2006—2014年的《陕西省统计年鉴》中各市(区)农作物播种面积对旱地和水田分类结果进行检验,旱地和水田面积的平均相对误差分别为15.3%和14.5%,最大相对误差分别为23.8%和 19.7%,分类精度整体较高。
5结论
本文使用2005—2014年的NDVI数据进行植被信息提取,时间跨度较大,基于DTW距离的相似性分析有效解决年度间气像因子差异引起的曲线偏移,并通过加窗处理有效提高DTW算法效率,减少错误匹配,结合临近度模糊分类能够避免直接选取阈值造成的因植被物候期差异造成的植被误分类,且植被信息提取结果总体精度较高。
然而在长时序提取过程中仍然存在一些问题有待进一步研究。首先提取结果受到MODIS NDVI产品数据质量的制约。例如,研究区内2009年样点的NDVI数据S-G滤波后,DTW距离全部超过2倍标准差,最终2009年的信息提取结果严重失真,这应该是与2009年存在11期大面积异常数据有关,这意味着若年度数据存在近一半的噪声数据时要设计其他方法才能保证特征提取的质量;其次是混合像元影响。混合像元的类别只代表像元内分布最广的植被类型,例如在西安东北部土地利用方式多为旱地与果园混杂分布,而果园的NDVI特征与有林地相近,从而产生在某些年度有林地-旱地之间反复的情况,从而降低信息提取精度,可通过结合作物物候和中高分辨率遥感影像进行混合像元分解,以提高提取精度实现植被类型进一步细分。
参考文献:
[1]任园园,张哲,侯钦磊,等.中国大陆植被覆盖对降水与温度变化的响应[J].水土保持学报,2013,33(2):78-82.
[2]陈燕丽,罗永明,莫伟华,等.MODIS NDVI 与 MODIS EVI 对气候因子响应差异[J].自然资源学报,2014,29(10):1802-1809.
[3]陈燕丽,龙步菊,潘学标,等.基于MODIS NDVI和气候信息的草原植被变化监测[J].应用气象学报,2010,21(2):229-236.
[4]杨斌,王金生.基于GIS的丘陵区耕地景观格局时空演变特征分析[J].测绘工程,2014,23(9):1-4.
[5]李文叶,姜鲁光,李鹏.2001—2010年鄱阳湖圩区水稻多熟种植时空格局变化[J].资源科学,2014,36(4):809-816.
[6]GEERKEN R,ZAITCHIK B,EVANS J P.Classifying rangeland vegetation type and coverage from NDVI time series using Fourier Filtered Cycle Similarity[J].International Journal of Remote Sensing,2005,26(24):5535-5554.
[7]WARDLOW B D,EGBERT S L,KASTENS J H.Analysis of time-series MODIS 250m vegetation index data for crop classification in the US Central Great Plains[J].Remote Sensing of Environment,2007,108(3):290-310.
[8]那晓东,张树清,李晓峰,等.MODIS NDVI时间序列在三江平原湿地植被信息提取中的应用[J].湿地科学,2007,5(3):227-236.
[9]PENG D,HUETE A R,HUANG J,et al.Detection and estimation of mixed paddy rice cropping patterns with MODIS data[J].International Journal of Applied Earth Observation and Geoinformation,2011,13(1):13-23.
[10] 管续栋,黄翀,刘高焕,等.基于DTW距离的时序相似性方法提取水稻遥感信息:以泰国为例[J].资源科学,2014,36(2):267-272.
[11] 李杭燕,颉耀文,马明国.时序NDVI数据集重建方法评价与实例研究[J].遥感技术与应用,2009,24(5):596-602.
[责任编辑:张德福]
Extraction of vegetation information using adding windows DTW distance with NDVI time series data
HAN Xiaoyong,HAN Ling,CHEN Luwan
(School of Geology Engineering and Geomatics,Chang’an University,Xi’an 710054,China)
Abstract:Qinling-Bashan Mountain area is an ecological barrier.The vegetation information extraction research can provide base data for ecological service function and natural resources exploitation.DTW distance similarity measure is improved by adding windows,and vegetation information is extracted by proximity-fuzzy classification from MODIS NDVI in the years of 2005 to 2014.S-G filter method is first applied to weakening the noise and reconstructing the NDVI time series.Each type of vegetation standard NDVI time series curves is generated from the 2013 sample data.For each to-be-classified pixel,a quantitative similarity between its time-curve and standard time series curves is calculated using adding windows DTW,then vegetation information is extracted in research area.Finally,validate data is used to verify the extraction accuracy.The result shows that the algorithm has high efficient and can avoid mismatch,and can realize long time serial vegetation information extraction with high accuracy (overall accuracy:83.8%,Kappa coefficient:0.77).
Key words:NDVI;time series;adding windows DTW;proximity;fuzzy classification
中图分类号:TP79
文献标识码:A
文章编号:1006-7949(2016)03-0011-06
作者简介:韩晓勇(1981-),男,博士研究生.
基金项目:国家自然科学基金资助项目(41201099)
收稿日期:2015-06-11
