基于标记属性的多网页信息隐藏算法
2016-04-08王媛媛刘金岭
王媛媛 刘金岭
(1.淮阴工学院计算机工程学院 淮安 223003)(2.江苏省物联网移动互联技术工程实验室 淮安 223003)
基于标记属性的多网页信息隐藏算法
王媛媛1,2刘金岭1,2
(1.淮阴工学院计算机工程学院淮安223003)(2.江苏省物联网移动互联技术工程实验室淮安223003)
摘要针对现有的网页信息隐藏算法,相关文献已经提出了一些检测算法。为了提高网页隐藏信息的容量以及抗检测能力,论文提出了基于标记属性的多网页嵌入规则,将隐秘信息加密后嵌入一组关联的网页中,隐秘信息与网页紧密结合,有较好的隐蔽性和抗检测能力,隐藏的信息量也有较大提高,该算法可以为网页隐秘通信提供参考。
关键词信息隐藏; 多网页; 标记
Information Hiding Algorithm Based on Information of Multi Webpage Tag Attributes
WANG Yuanyuan1,2LIU Jinling1,2
(1. Faculty of Computer Engineering, Huaiyin Institute of Technology, Huai’an223003)
(2. Jiangsu Province Networking and Mobile Internet Technology Engineering Laboratory, Huai’an223003)
AbstractAccording to the existing information hiding algorithm webpage, literature has proposed some detection algorithm. In order to improve the capacity of hidden information and anti detection ability, a multi page embedding rule is proposed based on markup attribute. The secret information is encrypted into a group of related webpage, the secret information combined with webpage has good concealment and anti detection ability, the amount of information hiding has improved greatly. The algorithm can provide a reference for webpage covert communication.
Key Wordsinformation hiding, multi webpage, tags
Class NumberTP183
1引言
信息隐藏是信息安全研究方向中的一类技术,可以将秘密信息嵌入到普通的信息载体中,使第三方无法区别正常载体和携带隐秘信息的载体。信息隐藏主要包括两类技术:隐写术(用于隐秘通信)和数字水印(用于数字媒体的版权保护)[1]。目前已存在很多对文本、图像、音视频以及数据库进行信息隐藏的研究,在当今的网络时代,针对网页相关的信息隐藏技术愈显重要。网页信息隐藏是将网页作为隐秘信息的载体[2],从而提高网页的安全性,同时可以保护软件知识产权。
国内外针对网页信息隐藏方法的研究主要从网页标记入手,归纳为以下常用的方法: 1) 嵌入不可见字符。例如Invisible Secret、WbStego和Stegano水印软件,该方法使网页文件变大,诸如网页减肥软件可以去除这些不可见字符[3],水印的隐蔽性较差。 2) 基于HTML语法的容错性,改变网页标记及其属性值的大小写,例如Infrihide水印软件;基于重复标记的网页信息隐藏[4]。这些方法对网页源码做了明显的改变,通过查看源码极易暴露隐藏的信息。 3) 通过改变标记的属性顺序嵌入秘密信息[5],该方法需要使用数据库记录属性的顺序。 4) 基于CSS类选择符的网页水印方法[6],该方法对网页容量有要求。 5) 基于标记和数据融合以及标记字典的网页水印算法[7],该方法需要创建并保存标记字典。上述方法仍有各自的局限性,如容量较小的单网页水印嵌入,隐蔽性以及鲁棒性需要进一步提高。本文提出了一种基于网页标记的关键属性的多网页信息隐藏方法。实验结果显示,该方法有效地结合了Web页面的内容和隐藏信息,隐蔽性较好,多网页隐藏方式提高了隐藏的信息量,有较强的抗检测和抗过滤能力。
2算法原理
2.1基本定义
网页文件使用HTML语法结构,由若干网页元素构成,网页元素一般有开始标记、元素内容和结束标记三部分。
定义1:以〈body〉标记作为初始遍历对象,网页中的标记及其属性称作一个对象Oi,i为标记在网页中的顺序,Oi由标记、属性及属性值组成。
定义2:待嵌入的隐藏信息定义为S。
2.2混沌映射
Tent映射和Logistic映射是两个常用的混沌系统,将两者结合组成双混沌系统生成混沌序列,代替传统散列算法中的固定参数,并生成散列摘要,密钥空间较大[8],本文使用文献[8]的方法生成长度为n的混沌序列,用于加密待隐藏信息。
2.3信息嵌入规则及原理
网页对象Oi一般有以下特点:标记中有属性、类或id的定义,例如:
该标记定义了一个按钮及其属性和样式,其中标记、属性的大小写,属性值的单双引号区别可以忽略。
一般,标记可以设置id、name或类以便被样式表、JavaScript或jQuery访问。可以将水印信息嵌入到未定义id和name的标记中,所有未定义id和name的标记记为lj(j∈1,2,…,k),k为满足条件的标记总数。由于采用多网页嵌入策略,因此即便在一个载体网页中未定义id和name的标记较少导致隐藏容量较小,也可以通过增加载体网页数量的方法实现。本文将隐藏信息以定义标记id的形式嵌入,为了便于提取隐藏信息,将嵌入隐藏信息的标记id属性值设为单引号。
隐藏信息嵌入之前,首先进行网页预处理:扫描载体网页,将已有属性值的单引号重置为双引号,提取网页中所有未定义id和name属性的标记到一个集合序列中。
3隐藏信息嵌入及提取算法
3.1多网页信息隐藏算法流程
输入:载体网页Pi,待隐藏的信息S;
Step1:将待嵌入的隐藏信息(文本或图像)二值化转换为二进制序列S;选定初值x0作为秘钥,使用文献[8]提出的基于双混沌动态参数的单向散列算法生成长度为n的混沌序列{x1,x2,…,xn},同样将其二值化为二进制序列X。将待嵌入的隐藏信息二进制序列S与X异或得出加密后的二进制水印序列Q,即Q=S⊕X。
Step2:选定首个载体网页P1,根据待嵌入隐藏信息Q确定载体网页的个数n。
Step3:从网页的〈body〉标记处开始扫描网页P1,得到m个站内链接(去除站外链接),一般链接标记可以通过src或href属性获取,站内链接不包含“http://”,可以通过这一特点选定站内链接。
Step4:使用Rnd随机选取n-1个链接标记,从而确定需要嵌入隐藏信息的n-1个网页,即{P1,P2,…,Pn}为待嵌入信息的n个网页。
Step5:将加密后的二进制水印序列Q分为n等分,即{Q1,Q2,…,Qn}。
Step6:将待隐藏的序列{Q1,Q2,…,Qn}分别嵌入到{P1,P2,…,Pn}这n个网页。以网页P1为例:扫描网页P1,取出未定义id和name的标记lj,则增加标记的id属性值,将Q1中的二值信息分别作为lj的id属性值添加,并将添加的id值的前后分别插入约定的一个字符及符号“_”(用以区别网页中以定义的id值),直到将Q1中所有信息嵌入网页P1。反复执行Step6将{Q1,Q2,…,Qn}分别嵌入到载体网页{P1,P2,…,Pn}。
在{P1,P2,…,Pn}中每个网页的〈head〉〈/head〉之间使用jQuery标记标识待隐藏信息与载体网页的对应关系,例如:
〈script type="text/javascript"〉
$(document).ready(function(){
//P与Q的对应关系
})
〈/script〉

3.2多网页信息提取算法流程
输出:隐藏信息S。

Step3:使用秘钥x0解密{Q1,Q2,…,Qn},得到初始隐藏信息S。
4实验与结果分析
下面通过实验验证文本提出算法的有效性以及性能分析,分别从隐蔽性、隐蔽容量以及抗篡改和攻击的能力。
4.1算法的隐蔽性
在VS2012平台实现本文提出的网页信息隐藏方法,使用批量网页进行测试,结果显示嵌入了隐藏信息并没有改变网页的显示效果,在网页中嵌入隐藏信息前后对比如图1所示,信息隐藏前后HTML源码对比如图2所示。本算法嵌入的隐藏信息内容与网页本身结合,页面浏览效果视觉上没有差距,算法的隐蔽性较好。

图1 嵌入隐藏信息前后网页显示效果对比

图2 嵌入隐藏信息前后网页HTML源码对比
4.2算法的隐蔽容量
由于本算法采用多网页信息隐藏策略,因此可以在网页中嵌入大量隐秘信息。例如,将大小为459KB的秘密水印信息嵌入到同一站点的一组网页后,网页文件的大小改变不大,如表1所示。

表1 嵌入隐藏信息后网页文件大小
4.3抗篡改能力
一般网页在网络传输过程中,其内容不会被修改。若有意篡改了网页标记的内容,也可以提取部分隐藏信息,并不影响隐藏信息的读取。网页中标记及内容被篡改60%后,提取嵌入的隐藏信息如图3所示。
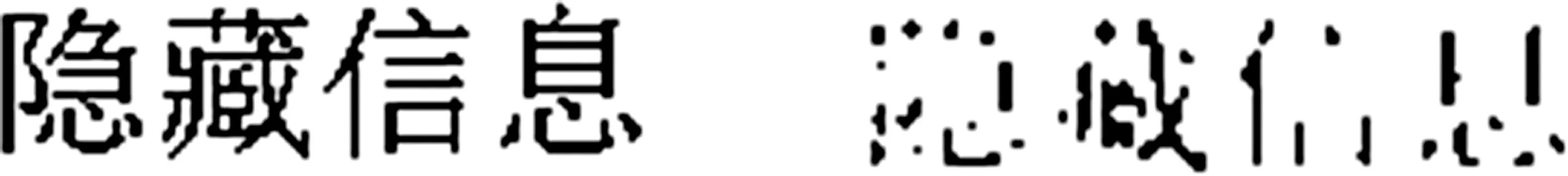
图3原始嵌入信息以及篡改后提取的隐藏信息
表2给出了目前已经提出的几种在网页中嵌入隐藏信息方法的性能比较。从表中可以看出,不可见字符以及标记大小写方法的抗检测能力较弱;属性对顺序方法需要原始数据库支持;重复标记属性和CSS类选择符引入法抗检测能力较强,但是网页较小时,单个嵌入的隐藏信息量有限。本文提出的方法将隐藏信息加密后,采用一定的策略嵌入到同一站点的多个网页中,隐藏信息与网页内容紧密结合,隐蔽性较好,同时也提高了抗检测和过滤的能力,嵌入和提取隐藏信息的算法简单,易于实现。

表2 几种常用算法性能比较
5结语
网络是目前信息传递的主要方式,网页的信息
安全日益重要,本文从页面的基本结构出发,提出了基于标记属性的多网页标记算法。实验结果显示,该算法将隐秘信息与网页内容相结合,与已提出的算法相比,具有更好的隐蔽性,隐藏信息容量更大,抗检测能力更强。
参 考 文 献
[1] Petitcolas, F. A. P. Anderson, R. J. Kuhn, M. G. Information hiding-a survey[J]. Proceedings of the IEEE,1999,87(7):1062-1078.
[2] Moulin, P, O’Sullivan, J. A. Information theoretic analysis of information hiding[J]. IEEE Transactions on Information Theory,2003,49(3):563-593.
[3] 眭新光,罗慧.一种新的基于超文本的信息隐藏方法[J].计算机工程,2005,31(12):136-137,153.
GUI Xinguang, LUO Hui. A new method of hiding information based on Hypertext[J]. Computer Engineering,2005,31(12):136-137,153.
[4] 李建国,马小虎,沈晓峰.一种基于重复标记属性的多网页信息隐藏方法[J].计算机应用与软件,2009,26(8):62-63,85.
LI Jianguo, MA Xiaohu, SHEN Xiaofeng. A Novel scheme of multiple webpages information hiding based on repeating tag attributes[J]. Computer Applications and Software,2009,26(8):62-63,85.
[5] Crinna John. Hiding binary data in HTML documents[EB/OL]. http://www.codeproject.com/csharp/steganodotnet13.asp,May,2008.
[6] 黄华军,王保卫,孙星明.基于CSS类选择符重复引入的网页信息隐藏算法[J].计算机研究与发展,2009,46(Z1):138-142.
HUANG Huajun, WANG Baowei, SUN Xingming. An Algorithm of Webpage Information Hiding Based on Repeated Importing of the CSS Class Selectors[J]. Journal of Computer Research and Development,2009,46(z1):138-142.
[7] 任俊玲,车蕾.标记和数据相融合的网页信息隐藏算法[J].北京信息科技大学学报,2012,27(4):43-46.
REN Junling, CHE Lei. A webpage information hiding algorithm based on integration of tags and data[J]. Journal of Beijing Information Science and Technology University,2012,27(4):43-46.
[8] 刘宴兵,吕淑品,唐浩坤.基于双混沌动态参数的单向散列算法[J].计算机应用,2010,30(9):2398-2400.
LIU Yanbing, LV Shupin, TANG Haokun. One-way hash algorithm based on chaotic coupled dynamic parameters[J]. Computer Application,2010,30(9):2398-2400.
[9] 黄华军,谭骏珊,孙星明.基于高阶统计的网页隐秘信息检测研究[J].电子与信息学报,2010,32(5):1136-1140.
HUANG Huajun, TAN Junshan, SUN Xingming. On Steganalysis of Information in Tags of a Webpage Based on Higher-order Statistics[J]. Journal of Electronics & Information Technology,2010,32(5):1136-1140.
[10] 任俊玲,王承权.基于标记字典的网页信息隐藏算法[J].山东大学学报(理学版),2012,47(11):40-44.
REN Junling, CHE Lei. A w ebpage information hiding algorithm based on tag dictionary[J]. Journal of Shandong University(SCIENCE EDITION),2012,47(11):40-44.
[11] 张晓彦,张晓明.一种基于表格属性的网页信息隐藏算法[J].北京石油化工学院学报,2009,17(1):43-47.
ZHANG Xiaoyan, ZHANG Xiaoming. An Algorithm of Webpage Information Hiding Based on the Property of Table[J]. Journal of Beijing Institute of Petrochemical Technology,2009,17(1):43-47.
中图分类号TP183
DOI:10.3969/j.issn.1672-9722.2016.01.001
作者简介:王媛媛,女,硕士,讲师,研究方向:信息安全、人工神经网络、计算机应用。刘金岭,男,教授,硕士生导师,研究方向:文本识别,数据库、数据仓库及数据挖掘。
基金项目:国家青年科学基金项目(编号:61402192)资助。
收稿日期:2015年7月9日,修回日期:2015年8月23日
