基于zookeeper和强一致性复制实现MySQL分布式数据库集群
2016-03-25张旭刚李东辉俞俊朱广新郑磊
张旭刚,李东辉,俞俊,朱广新,郑磊
基于zookeeper和强一致性复制实现MySQL分布式数据库集群
张旭刚,李东辉,俞俊,朱广新,郑磊
摘 要:目前MySQL数据库间的复制技术主要有异步、半同步、同步等,这几种技术存在各自的局限性和适用场景,很难满足国家电网业务对分布式事务和性能的要求。结合国内外先进的框架和技术,利用zookeeper实现MySQL数据库间复制的监控和管理,并改进MySQL数据库的线程池,参考半同步技术模型实现数据库间强一致性复制,融合以上两种技术实现复制在毫秒级、高可靠和高性能的MySQL分布式数据库集群。
关键词:MySQL;zookeeper;强一致性
0 引言
MySQL的复制模式有异步、半同步、同步等模式。在MySQL发展的早期,采取异步复制技术,由于主数据库只管把Binary Log发出去,而不关心从数据库是否收到,主从数据库间的数据不一致非常严重,通常是把从数据库作为一种容灾和备份方案。到MySQL5.5后,提供了半同步模式,确保必须收到一个从数据库的应答才让事务在主数据库中提交,若备机应答超时,强同步会自动退化成异步模式,这种模式适用于局域网,当跨数据中心时,时延较大,通常会工作在异步模式下,而且主数据库等待从数据库的应答,影响主数据库的性能。除了异步和半同步模式,还有同步集群方案,主要有MySQL NDB Cluster和MariaDB Galera Cluster,MySQL NDB Cluster基于全内存,只支持Read Committed事务隔离级别,需要把引擎Innodb为NDB,需要高速网络环境支持,而MariaDB Galera Cluster维护和管理复杂,在跨数据中心时,性能下降比较大。
为解决上述异步和半同步复制的缺陷,同步复制在跨数据中心时的性能降低问题,本文提供一种强一致性主从数据库复制方案,并通过zookeeper监控和管理主从数据复制的一致性、主从数据库的切换、服务器负载等,实现一种高性能、高可靠、易管理的分布式数据库集群。
1 Zookeeper介绍和结构
1.1 Zookeeper介绍
Zookeeper是一个分布式的协调服务,为分布式应用提供统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等,由2n+1(n>=1)服务器节点组成,这些节点中有一个主节点(leader),leader是通过leader selection自动地从
服务器节点中选举出来,其他节点角色为follower或observer。Zookeeper提供了一个类似于标准文件系统目录结构的层次化的命名空间(hierarchal namespace)。如图1所示:

图1 层次化的命名空间
hierarchal namespace中的每一个节点都被称为 znode。Znode是组成hierarchal namespace的基本单位。在源码中对应于类DataNode,其维护着节点用户数据、父节点和子节点集合,以及本节点状态,用户可以在hierarchal namespace中创建znode,将数据保存在znode中,并监听znode的状态变化,Zookeeper会保证client对znode的操作是顺序一致性。
1.2 Zookeeper结构
Zookeeper服务器节点的实现可以分成两部分:一部分是处理与客户端交互,实现客户端对zookeeper的hierachal namespace的各种操作;另一部分是作为zab算法(paxos算法的zookeeper实现)的参与者(leader、follower、observer3种角色的其中一种),实现具体的算法逻辑。
Zookeeper服务器的hierachal namespace、znode、客户端与服务器连接、以及客户端可以监听服务器的znode状态的watch机制之间的元数据关系如图2所示:

图2 Zookeeper 组件关系图
Zookeeper使用Trie树 来实现了hierachal namespace,由PathTrie这个类来完成。为了实现从路径到znode的映射,zookeeper在内存中维护了一个znode的hashmap,key为znode在hierachal namespace上的路径,value为znode对象,znode在zookeeper源码中由DataNode这个类实现。为了实现client监听znode的状态变化,zookeeper将与客户端的连接和hierachal namespace的节点路径进行映射,WatchManager这个类就是用于维护这个映射关系的,其中NIOServerCnxn是zookeeper服务器与client的一个socket连接;为了监听Znode的目录结构的变化和数据变化,zookeeper使用了两个WatchManager,分别用来监听namespace的目录结构和数据的变化。
在paxos算法中有3种角色,分别是提案者,接受者和学习者,与在zookeeper中的3种节点类型对应,即leader、follower和observer3种类型的节点,其中observer节点只能学习已经批准的提案,而不会参与到提案的投票过程中,这个角色的设定是为了保证提案选举的性能不会随着zookeeper集群规模扩大而降低。角色间的信令交互如图3所示:
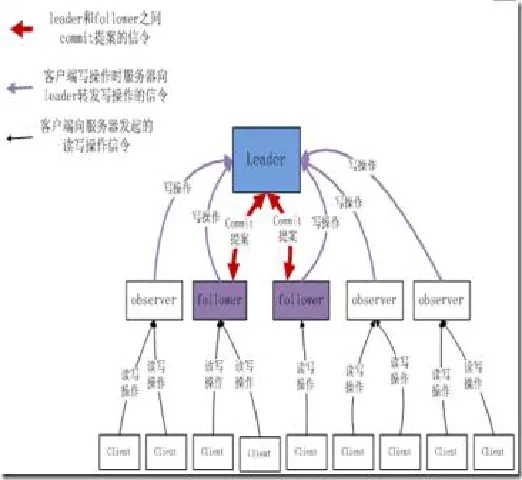
图3 角色交互图
2 Zookeeper设计与实现
基于zookeeper实现的MySQL强一致性复制集群,主要由zookeeper、agent和MySQL等组件组成,zookeeper作为系统的协调器,监控和管理系统资源,agent部署在MySQL上,负责向Scheduler上报MySQL实例的状态,包括实例的可用性、复制的一致性、服务器负载等,由mysqlreport和mysqltransfer两个模块构成,mysqltransfer用于自动扩容,mysqlreport用于上报心跳信息、资源信息。总体结构如图4所示:
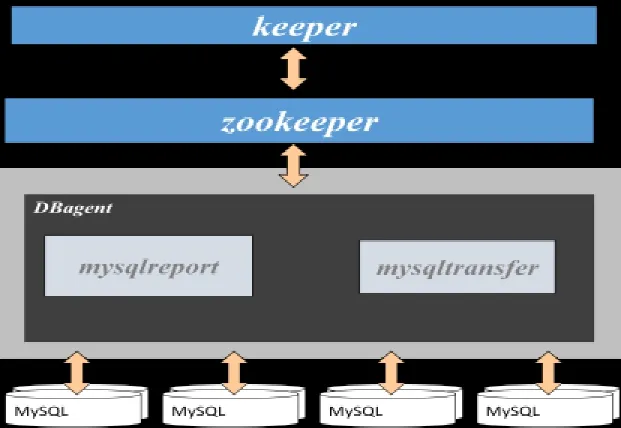
图4 系统结构图
2.1 主从一致性监控
主从数据库的一致性监控通常是在从库上执行语句show slave statusG获取Seconds_Behind_Master参数的值来判断,但这个值通常不能反映主从数据库一致性的真实情况。Seconds_Behind_Master是通过比较sql_thread执行的event 的timestamp和io_thread复制的 event的timestamp进行比较得到的一个差值。当主库I/O负载很大或是网络阻塞,io_thread复制binlog的速度会非常慢或停滞,此时sql_thread一直都能及时应用io_thread的复制,Seconds_Behind_Master的值是0,表示是没有无延时的,实际主从数据一致性延迟非常严重。
为解决以上问题,本文通过在主从数据库上创建一张表SysDB.StatusTable,dbagent将当前当前时间戳、ip、端口通过replace into方式写入SysDB.StatusTable表,mysqlreport默认3秒连接一次mysql,并对sysdb.statustable表进行读操作,根据master同步过来的时间、slave写入的时间进行相减,计算出时间差值作为延迟的时间,将以上获取的数据库信息写入zookeeper的hb@IP地址_端口号位置上,写入信息:{"agentbindport":"57086","autorebuildms":"1","conn_err":
"0","conn_info":"","delay":"0","gtiddelay":"","read_err":" 0","read_info":"","repl":"0","svrtype":"master","ver":"1.0","wri te_err":"0","write_info":""},其中delay值代表主从数据复制的延迟,单位为秒,0表示无延迟,结构图如图5所示:

图5 复制一致性设计图
通过以上方式,能准确获取主从数据库的一致性延迟,如果延迟超过设置的阈值,则在主库宕机从库承担读写角色时,从库只能读不能写。
2.2 资源监控
在MySQL分布式集群系统中,有多种系统资源需要监控,并根据结果做出反应,主要的监控资源有CPU的使用率、磁盘使用率、磁盘IO、MySQL数据库状态信息等,如图6所示:

图6 系统资源监控设计图
放到zookeeper的相关目录下,进行统一管理,并通过界面查看各资源信息,进行优化。
实际步骤是mysqlreport根据mysql的my.cnf文件,找到数据文件日志和日志目录, mysqlreport调用C语言的statfs函数分析mysql的数据文件、binlog文件在磁盘使用情况,mysqlreport获取只是统计数据文件及binlog的根目录大小,同时mysqlreport连接到mysql通过show global statusG命令获取Com_select、Com_update、Com_insert、Slow_queries等信息,Mysqlreport默认5秒一次将收集到的数据上传到zookpeeper的rsinfo@IP_端口号目录下。
通过获取以上信息,当数据库的资源使用率超过设置阈值时,调用策略应对,如当CPU使用率超过95%时,进行主从切换,防止数据库宕机。
3 强一致性复制设计与实现
在分布式数据系统中,有一个CAP原理,由三个要素组成,包括一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance),这3个要素最多只能同时实现两点,不可能三者兼顾。对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值,因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。对于大多数应用系统,并不需要强一致性,因而牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。
但在计费、ERP等系统中,对数据的一致性要求很高,数据库承受的压力也很大,在保证可用性和分区容忍性的同时,尽可能提高数据一致性的实时性,使产品具有更广泛的应用场景。
3.1 MySQL复制技术的发展
在MySQL发展的早期,就提供了异步复制的技术,Mysql 主数据库将自己的Binary Log通过复制线程传输出去以后,Mysql 主数据库就自动返回数据给客户端,而不关系从数据库是否接受到了这个二进制日志,异步复制模型如图7所示:

图7 异步复制模型
到了MySQL 5.5版本,google提供了一个半同步半异步的插件,当主数据库在将自己binlog发给从数据库后,要确保从数据库已经接受到了这个二进制日志,才会返回数据给客户端,通过收到一个从数据库的应答来实现;当备机应答超时时,强同步就会自动退化成异步模式,复制模型如下图8所示:

图8 半同步复制模型
半同步方案相对异步复制,在数据的可靠性方面得到了提高,若主数据库故障则最后一个事务,至少在一个从数据库上存在。但在主从数据库跨数据中心时,性能非常很低。
除了异步和半同步,还有同步方案,典型的有MySQL NDB Cluster、MariaDB Galera Cluster等,MySQL NDB Cluster基于全内存,只支持Read Committed事务隔离级别,需要把引擎Innodb改为NDB,需要高速网络环境支持,应用范围窄。MariaDB Galera Cluster 是一套在mysql innodb存储引擎上面实现multi-master及数据实时同步的系统架构,业务层面无需做读写分离工作,数据库读写压力都能按照既定的规则分发到各个节点上去,具有如下特点:
(1)同步复制;
(2)多主的拓扑结构,可以认为没有备机的概念;(3)可对集群中任一节点进行数据读写;
(4)自动成员控制,故障节点自动从集群中移除;(5)自动节点加入;
(6)真正并行的复制,基于行级;
(7)每个节点都包含完整的数据副本。
MariaDB Galera Cluster在功能实现上非常完美,但管理和维护困难,在跨数据中心时,性能损耗较大。
3.2 性能分析
如图9所示:
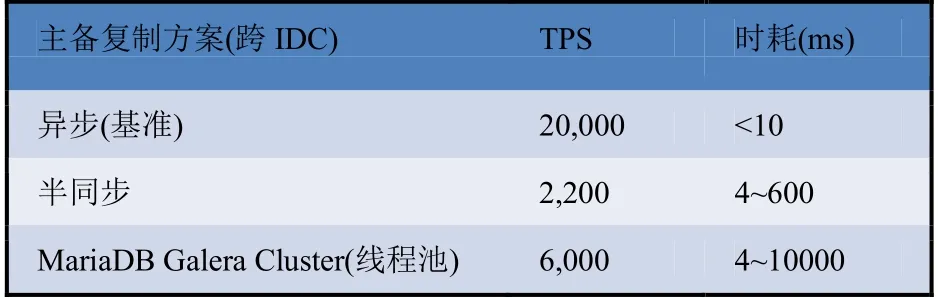
图9 同步模式对比
从上图9可以看出,在跨数据中心时,半同步、同步复制的性能损耗非常严重,这与MySQL前期版本采用的每个连接一个线程的模型有关,该模型的优势在于开发特别简单,线程内部都是同步调用,只要不访问外部接口,支撑每秒上千的请求量也够用,因为大部分情况下IO是瓶颈。不过随着当前硬件的发展,尤其是SSD、FusionIO的出现,IOPS从每秒200+发展到每秒几十万甚至百万次,IO基本上不再是瓶颈,如再采用这套模型并采用阻塞的方式调用延迟较大的外部接口,则CPU会阻塞在等网络应答上了,性能自然下降。
3.3 强一致性复制实现
在MySQL5.6企业版和MariaDB、Percona中引入了线程池,优势在于线程处理的最小单位是statement(语句),一个线程可以处理多个连接的请求。这样,在保证充分利用硬件资源情况下(合理设置线程池大小),可以避免瞬间连接数暴增导致的服务器抖动,线程池的实现模型如图10所示:
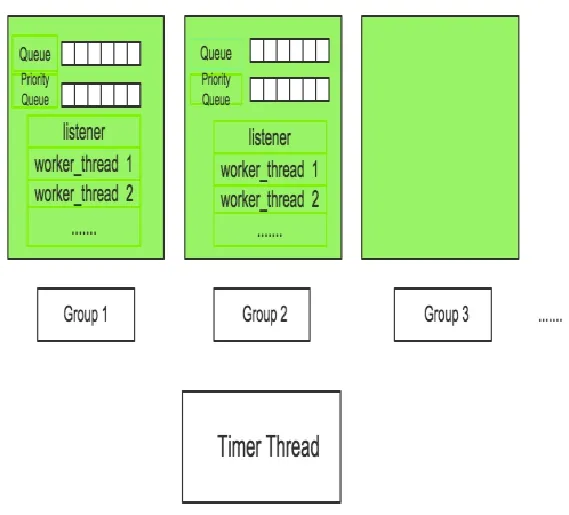
图10 线程池模型
每一个绿色的方框代表一个group,group数目由thread_pool_size参数决定。每个group包含一个优先队列和普通队列,包含一个listener线程和若干个工作线程,listener线程和worker线程可以动态转换,worker线程数目由工作负载决定,同时受到thread_pool_oversubscribe设置影响。此外,整个线程池有一个timer线程监控group,防止group“停滞”。
一个连接一个线程与线程池的对比如图11所示:
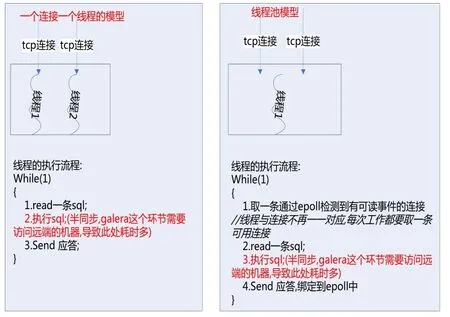
图11 线程模型对比
从上面的分析可知,半同步半异步是较轻量级的高一致性容灾方案,但是受限于已有的同步网络模型,CPU利用不起来。如果在线程池基础之上做一些修改,参考半同步的思路就可以实现一个高性能的强同步方案。
目前的做法是采用与Linux内核处理中断的思路:将上面线程池模型的第三个环节(执行SQL的逻辑)拆成2个部分:
(1)上半部分,任务执行到写binlog为止,然后将会话保存到session中,接着执行下一轮循环去处理其他请求了,这样就避免让线程阻塞等待应答了;
(2)然后MySQL自身负责主备同步的dump线程会将binlog立即发送出去,备机的io线程收到binlog并写入到relay log之后,再通过udp给主机一个应答;
(3)在主机上,开一组线程来处理应答,收到应答之后找到对应的会话,执行下半部分的commit,send应答,绑定到epoll等操作。绑定到epoll之后这个连接又可以被其它线程检测到并执行了。
流程图如图12所示:

图12 强一致性复制流程图
该同步方案完全独立于原生的主从复制系统,属于新开发功能,同时强同步的概念是从整个MySQL分布式数据库集群上来看的,保证数据在切换、或进行读写分离时数据的一致性。当主备数据延迟超过了一定的阀值时(可配置),就不会发生主从切换、进行读写分离操作,与半同步方案的差别:
(1)当备机应答超时的情况下,半同步就不会自动退化成异步模式;
(2)线程池优化,在主机上开启单独的多线程来处理从机写入relaylog后的应答实现连接的复用,提高效率。
4 总结
基于zookeeper与强一致性复制的分布式数据库集群,易于部署、管理和维护,数据一致性实时性高,可靠性得到保证,已在国网多个业务系统中应用,实践效果良好。但也存在需要改进和扩展的方向,如zookeeper在使用过程中存在占用内存过高的现象,同时扩展dbagent功能模块,实现弹性计算,如容量按需自动收缩、数据在线搬迁等,是今后研究和设计的方向。
参考文献
[1] Flavio Junqueira,Benjamin Reed.ZooKeeper: Distributed Process Coordination[M].O'Reilly Media,2013,12,210-333.
[2] 曾大聃,周傲英.Hadoop 权威指南(第二版-中文版)[M].北京:清华大学出版社,2011(1):88-89.
[3] 邓鹏,李枚毅,何 诚.Namenode 单点故障解决方案研究[J].计算机工程,2012, 38(21):25-44.
[4] PatrickHunt,MahadevKonar,FlavioPJunqueira,BenjaminReedZooKeeper:Wait-freecoordinationforIntem etscalesystemsUSENIXAnnualTechnologyConference[C] .2011:2-3.
[5] 叶谦.Zookeeper初步调研报告[J].计算机技术与发展,2011,7(7):15-25.
[6] 倪超.从Paxos到Zookeeper[M].北京:电子工业出版社,2015:43-61.
[7] Marco Aiello.leader_election[M].Distributed system.2011,1:5-9.
[8] 雷明.fast paxos算法与Zookeeper leader选举源代码分析[J].计算机技术与发展,2015.3,3(04):3-20.
[9] ZooKeeper: Because Coordinating Distributed Systems is a Zoo[J/OL]。Science,2014,3 (http://zookeeper.apache.org/doc/r3.4.6/ /).
MySQL Distributed Database Cluster Based on Zookeeper and Strong Consistency
Zhang Xugang, Li Donghui, Yu Jun, ZhuGuangxin, Zheng Lei
(Information System Integration Company, Nari Group Cooperation, Nanjing 210000, China)
Abstract:At present, the replication technology between MySQL mainly contains asynchronization, semi-synchronization and synchronization. These technologies have respective limits and suitable scenarios, and that make them hardly meet the requirements for distributed affairs and performances of State Grid Corporation of China. This paper uses zookeeper to realize the monitoring and management of replication between MySQL databases and improves the thread pool of MySQL databases, combining with the advanced framework and technology of home and abroad. It consults the semi-synchronization model to realize the strong consistence replication between the databases, and it also fuses the two above technologies to realize the replication on the millisecond, high reliability and performance MySQL distributed database groups.
Key words:MySQL; Zookeeper; Strong Consistency
收稿日期:(2015.10.13)
作者简介:张旭刚(1979-),南京南瑞集团公司信息系统集成分公司,助理工程师,研究方向:计算机应用技术,南京,211000李东辉(1970-),南京南瑞集团公司信息系统集成分公司,高级工程师,研究方向:电力系统通信信息,南京,211000 俞 俊(1978-),南京南瑞集团公司信息系统集成分公司,高级工程师,研究方向:电力系统通信信息,南京,211000朱广新(1981-),南京南瑞集团公司信息系统集成分公司,工程师,研究方向:模式识别与智能系统,南京,211000 郑 磊(1972-),南京南瑞集团公司信息系统集成分公司,助理工程师,研究方向:电力系统通信信息,南京,211000
文章编号:1007-757X(2016)01-0077-04
中图分类号:TP393
文献标志码:A
