基于Web的图像检索技术研究
2016-03-2261683部队张相国
61683部队 张相国
基于Web的图像检索技术研究
61683部队张相国
如今,在Web图像检索过程中,有很多成熟的技术,如基于Web的数据仓库,Web数据挖掘,Web数据源集成技术。因此,必须建立适当的数据模型页面,数据模型可有效地用来获得从Web信息。为了应对中国的数据网络,还必须使用一系列中国自然语言处理技术。根据对比技术,自动分割,其它如信息抽取,自动摘要,自动文档分类,中国话和像自动发现的概念来确定语义关系的词与词之间的技术概念是必不可少的。需要实现上述坚实的技术积累和自然语言处理能力。
而如何利用现有成熟的传统图像检索手段,并迅速开发出一种快速,便捷的方式,以提高检索效率,本文会发现中国和页面之间的图像的固有特性是基于现有的搜索引擎的研究和检索装置和接触,提高在原始文本搜索中使用的模型和方法,提出了新的文本相似性匹配算法,并引入检索反馈技术,这些技术的引进到图像检索,使它更容易的搜索装置落实和提高检索效率。
1 文字和图像之间的关系
在文本检索,各大搜索引擎考虑的Web页面相关联的文本信息和其语义,这些文本反映了一个网页的信息内容,但与页面中的图片内容不完全一致。HTML页面,基于HTML语言的格式,图像采集信息反映的短信,这些文本的语义分析具有十分重要的意义。作为一个HTML文档标签的文本消息以及周边,并在页面图文并茂的内容是紧密相连的。
1.1显示了文本标记的图像
为了识别嵌入到网页中的图像的内容,这必须小心检索和标记文本反映图像内容的HTML文档。大量的研究和HTML页面格式的实际网页的分析之后,可以看到标有文字和图像内容有以下几个方面的联系最紧密的。
说明:
(1)的图像,文本显示在图像的周围,用句,句子过度内容显示图像时,图像被放置在桌子上,在细胞中相同的元件或文本邻近并通常表示图像的含义。
(2)图像的标题,图象信息通常是由一个关键词来表示。当一些文字用语的摘要信息
(3)利用图像,并更换标签指示标记图像时,图像不显示图片,显示的摘要信息。
(4)在页面的标题,该标题反映了页面的中心的内容,如图像内容和标题页之间的网络的性能也有一定的联系。
1.2文本的权重的比较
在页面图像信息上述图像检索讨论,首先是描述图像内容特征建立查询,然后比较,获得需要被检索到的图像描述信息并区分的相似和查询之间的差异。然而,上述信息图像聚焦在一个不同的角度,并在暴露于图像信息的程度是不一样的。标题页和一个简单的条目,取其相对接近的视频标题图像主题的标题图像。的图像和标签图像的描述是图像信息,它是该内容的相对更详细的文本描述。因此,各种类型的文本信息之间的比较来区分,以确定是否搜索请求,其重量份额应有所不同。的根据在下面的尺寸中的份额加权序列的信息的重要性:
Image Caption>Image Title>Image Alternate>Page Title
2 图像信息检索
什么检索使用Web搜索引擎的模式,这将直接影响提供获取搜索结果的质量。现在我们使用多个布尔检索模型,概率检索模型,概率推理网络模型和向量空间模型。这是近年来使用更多更好的,信息检索模型:向量空间模型。
2.1 相似性检索模型
在使用向量空间模型搜索,首先描述在Web视为条目的有序序列短信图像,因此上文概述的信息被称为:ICW,ITW,IAW,PTW。在该模型的应用,我首先要量化这种信息,文档结构图作为特征矢量V(D)=(T1,ω1(D); ...; TN,ωN (D)),其中TI( I = 1,2,...,n)是相互相同的条目而言列表,ωi的(D)在D的Ti的重量,通常被定义为发生钛TFI(四)D的函数中的频率,亦即:
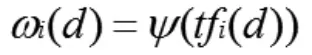
在信息检索中常用的词条权值计算方法为 TFIDF 函数:
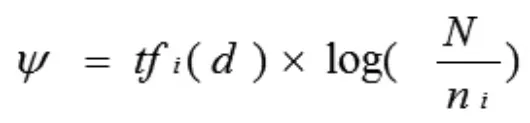
其中N为所有文档的数目,ni为含有词条ti的文档数目。TF-IDF公式有很多变种,下面是一个常用的TF-IDF公式:

两文档之间的相似度可以用其对应的向量之间的夹角余弦来表示,即文档di,dj的相似度可以表示为:
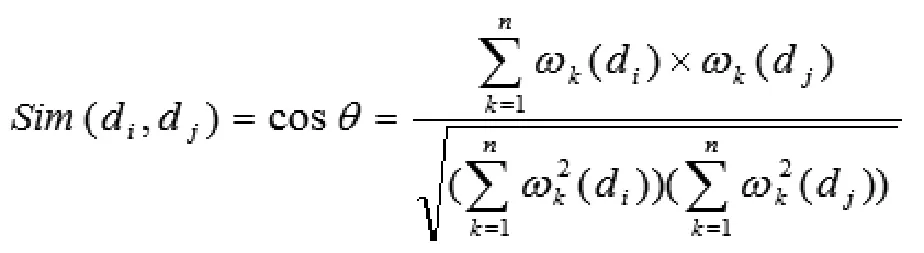
处理查询,先查询状态•量化,主要是基于布尔模型:
当ti在查询条件Q中时,将对应的第i坐标置为1,否则置为0,即:

即当两个相同的条目,这一个是1,其余情况为零。由此可以看出,当含有相同术语的文档时,相似性= 1;且其中不存在相同的术语,相似度=0。从而文档d与查询Q的相似度为:

根据一些机器学习算法,例如神经网络算法,K-最近邻算法和贝叶斯算法文档之间的相似性,以及组合可分为设置的文件的一些小的子集的文件。
在查询过程中,可以计算每个文档和查询之间的相似性,然后将结果可以基于该查询的大小的相似性进行排序。
VSM可以自动区分文档和相似性排序结果,可以有效地提高检索效率;它的缺点是大量的计算相似的,在添加新文档时,必须计算的字的权重。
图3中的产品质量信用理论模型是企业产品质量信用关系模型的一种表达方式。产品质量信用意愿、产品质量提供能力是产品质量信用水平的内部决定因素,对应的影响指标为决定型指标。产品质量保障能力是产品质量信用水平的外在表现因素,对应的影响指标为反映型指标。即产品质量信用意愿、产品质量提供能力和产品质量保障能力三个方面是该关系模型的输入,输出的是产品质量信用水平。因此,企业产品质量信用评价的关系表达式可以表示为:
2.2技术和词语匹配
2.2.1常用词切算法
统计似然方法通常不依赖于字典中,但任何原始和一个统计单词频率发生之前立即字,分别后,字出现的更高的数量变大。当频率超过预定阈值,这将被索引为一个字。这种方法可以有效地提取未知单词。
2.2.2匹配方法
(1)字典存储格式:
首先,建模,三层结构的存储的形式是一个树结构,如下:
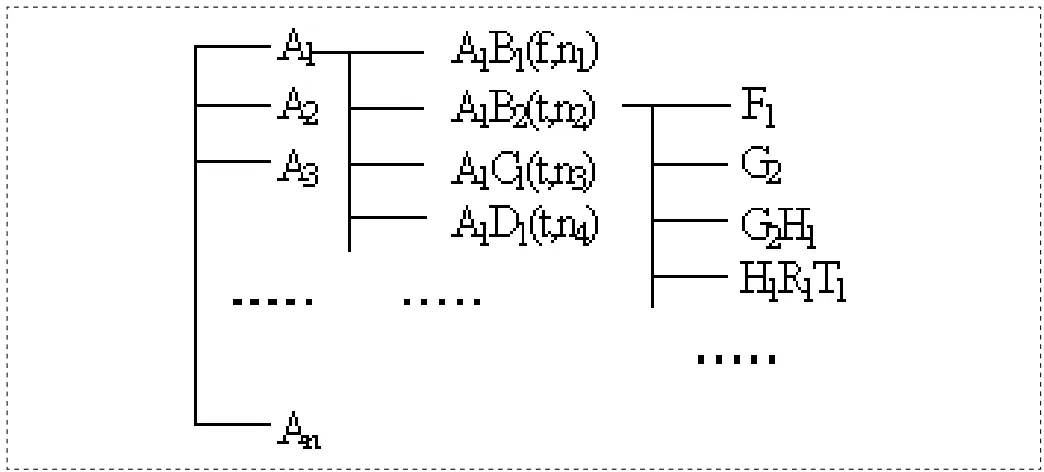
层存储所有的话。第二层和多双字字(因为有可能是ABC字,而不是下一个字AB案)之前保存所有的字,并做不同的标签(T / F)。每个字对应于一个系列词语,所有字中的第二层的一个节点,用于存储第一个字的一个双字(包括上述两种情况)。和,这里,对于每个双字,则需要记录双字的最大长度是所有字的第一个字,在实践中,可以保存移除的双字的部分的最大长度(表示为n),第三层存储的所有单词,双头特征。为了减少存储空间,不是仅去除(如上所示)的双字存储部等。已经有的每一层的每个节点的基础上的,可以使用散列,二进制搜索方法来查询。有了这个分层存储架构,可以快速缩小在一个小范围内的搜索词,它有利于字工作效率。
(2)匹配
由于字的长词汇通常比切口的字长的最大分离越大,为了提高分割的效率,而不是在连续的还原方法的词,但使用正向单独生长方法。
假设一个句子C1C2 ......是文字处理算法描述如下:
1)个字(在C1C2的开头),查询是否有在辞典C1C2。
2)不存在,C1是一个字,一个字结束时,返回1。
3)存在,判断是否C1C2字,并获得中国汉字的字典的术语低级节点的最大长度,设定为n。
4)如果n = 0,所述第一子码字的结束时,保存的结果。
5)否则,I = 2,转6)。
6)I = I + 1,若i = N + 3,开关8);否则,转向7)。
7)然后取一个字(这里C),第三层决定是否一词开始C3......字(精确匹配不是必需的,只要匹配的话,我就开始)。
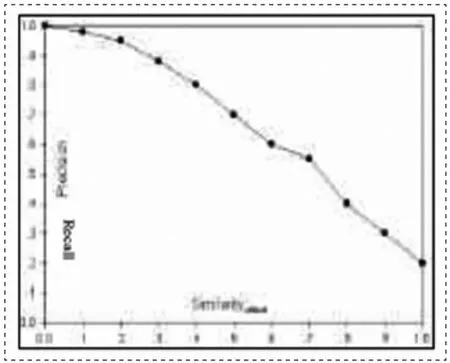
8)如果有,这个词的结尾,可以只返回C3 ...... CJ (J 9)否则,转6)。 (3)统计方法 由于不完整的字典,字典中的很多话可能没有注册的句子来处理未知的话,我们嵌入统计方法的频率在原来的算法,一些连续场作为一个分词的频率较高,我们先设定阈值频率f。 已成立C1 ......道道由分割算法和模糊处理算法C1 ......慈用一个词在一个分段的,是CJ之间的所有单个的词......道道通字,词和CJ,即C1 ......慈和CJ ...... Cn为相邻两个最近多字,然后CI + 1 ...... CJ-1作为多字词频统计,完成制品的所有分割后,如果CI + 1时出现的次数...... CJ-1到达f,则它被认为是一个字,否则,它被分成单个词。 同时,对于相同或类似的专业领域,建立动态的词汇,由这个词不断补充词库获得的统计数据,字典可以实现动态维护。 通过上述处理方法,基于字典,结合匹配的次数依据不仅保证了分割速度快,精度高的优点搜索操作的统计方法,并在这方面最大限度的标识名称,位置和其他技术术语不能登录。 由于查询图像的开始,它往往是与我们想要的不一致,所以我们无法找到我们想要的,因此,许多系统已出台相关意见,那就是,通过选择一些正确/错误反馈搜索结果的一个例子,以逐步改善。参考文本信息检索的方法,我们也推出了相关的反馈来修改用户提交的查询,使得被修改的查询更贴近用户的实际需求,以提高该系统的性能。通过修改用户提交的相关反馈,检索性能比原来已经一定程度的提高。然而,大多数不具备相关的反馈的内存容量,每个结果,这不仅提高了查询结果后的反馈。因此,我们引入了一个语义网络中,每个记录到语义Web反馈的结果,以便增加越来越多地使用该系统的频率的效果。 本文介绍了反馈系统,主要集中在查询(Q1,W1,Q2,W2,...,Qm的,,WM)在WJ修整查询来定义初始WJ已有些偏差反馈系统可以适当地调整WJ,使查询(Q1,W1,Q2,W2,...,Qm的,,WM),但也反映了检索的目的。当查询到的画面,无论在哪里与目标关联ř图片n的图像和目标为m = R + N个。根据用户反馈的结果反馈系统,并重新生成查询如下: 其中载体是一种图象检索结果网页矢量表示,矢量,选择相似度计算部件作为反馈信息。在公式5,一般选γ=1,0<β<1,0<α<1,α和β选择的影响深度的反馈值,也直接影响了检索的准确度。 实践表明,以比无反馈图像检索精度反馈系统中的图像检索系统由约10%,且m,较高的检索的准确度提高。 我们设计了一个检索系统,不提供反馈反馈选项,并在选举制度提供反馈超值的选择。当m值较小时,直接显示检索到的图像,并选择是否为用户目标图像之间的相关性。这些都是以提高应用反馈系统的用户界面。这里是合适的度量m = 1时,检索精度和反馈系数α,β的数字之间的曲线关系可以得出α= 0.1检索最大值精度精密图2可以在0.5被吸引到0.6检索之间β精度时精度取最大值。从图1和2,可以得到,当α=β= 0时,没有反馈检索精度精密= 48%,当α= 0.1,β= 0.5或0.6检索精度精密= 61%,引入了反馈系统的时允许检索的准确度是由13%的提高。 图1 检索精度Precision与系数α的关系 图2 检索精度Precision与系数β的关系 图3 相似度临界值与检索精度的关系 图4 相似度临界值与 检索完全度的关系 要测试的模型搜索,下载包含4000多个中国网页图像(从超过1000个网址),这些HTML文档检索。创建的查询后,具有相同语义的扩大网络进入的入口处,构建多个IQW匹配查询,然后计算它们的相似度,分别基于所述相似性阈值规定屈服查询的结果。实验表明,一个合理的阈值可以被选择以确保高度的相似性检索精度和检索的完整性。因为它可以从图3可以看出,当该相似性阈值>0.6,以确保从图4看出>80%的检索精度,当相似性阈值<0.6,以确保>60%完成检索。当相似度阈值是0.6,这种模式可以保证> 80%的搜索检索精度和检索全>60%。 为了确定ICW,ITW,IAW,PTW右相似度计算值,测试所有的系数为0.1至1.0。最终拉伸重量ICW,ITW,IAW,PTW为0.4,0.3,0.2,0.1时,它可以合理地反映这些文本和图片的相关性,以确保检索的准确性。 了解搜索公式和反馈的搜索引擎的原理,我们可以根据理论相应的搜索引擎,并可以做一个对比的搜索结果。但为了更好地使用和要小心,以更好地归类文档,此引擎查询反馈更多的培训,使网络搜索引擎有更好的情报和个性化功能。 参考文献 [1]张量,詹国华,袁贞明.基于Web的图像搜索[J].计算机工程,2002,5. [2]朱学芳.多媒体信息处理与检索技术[M].电子工业出版社,2003. [3]陈滢,徐宏炳,王能斌.协作式Web资源发现系统模型[J].计算机学报,1998,4. [4]阳小华,周龙骧.World Wide Web 的索引与查询技术[J].计算机科学,1997.3 检索反馈




4 结论
