一种适于应用程序员设计FPGA异构系统的框架※
2016-03-20沈镇柴志雷柴镇
沈镇,柴志雷,柴镇
(江南大学物联网工程学院,无锡214122)
一种适于应用程序员设计FPGA异构系统的框架※
沈镇,柴志雷,柴镇
(江南大学物联网工程学院,无锡214122)
本文提供一种适于应用程序员方便使用FPGA平台的框架。它让用户从硬件和系统结构中抽离出来,更关注算法和应用程序。这个框架综合了Xilinx ISE和Vivado,可以立即使用。在本文的框架上,一个软件人员实现了一个广泛使用的特征提取算法,表明本文的框架的确适用于只有少量硬件知识的应用程序员。
FPGA;嵌入式系统;特征提取;应用程序
引 言
众所周知,在最近的十年,生产商已经放弃试图通过提高单核频率来提升性能,大多数主流通用处理器性能增长都借助增加处理器核的数量。有很多关于多核的研究调查[1-2],然而,正如参考文献[2]中介绍的那样,现行的并行架构在常规项目(如稠密矩阵计算)上有好的加速效果,但是大多数在非常规项目(如计算机视觉)上的表现则差强人意。
FPGA作为一种可编程逻辑设备,支持不同类型的细粒度并行,也擅长处理非常规项目。它的性能和功耗的优势经常被得到证明[3-4]。但是,当前在纯FPGA上实现应用依然是一个困难的工程,即使是对一个熟练的工程师而言,因为它需要底层VHDL/Verilog硬件语言和硬件细节的知识,而且在实现应用之前,还需要解决设备驱动的问题。
最近出现了很多针对于FPGA的异构SoC,例如Xilinx Zynq-7000[5]和Altera SoC FPGA。异构FPGA的一个优势就是通用处理器部分可以使FPGA使用者从复杂的驱动程序里面解脱出来。另一个优势是异构FPGA通过结合传统与非传统的处理器,有潜力达到更好的能效,这已经从理论[7]和实践上[8]进行了研究。另一方面,HLS (High-Level-Synthesis)[6]技术到今天已经足够成熟,能够支持C/C++对FPGA的设计更抽象。例如,Xilinx的Vivado HLS[9]支持程序员使用高级语言C/C++基于Xilinx FPGA设计系统。Zynq SoC加上HLS是当前一个明显的发展选择。然而,尽管异构SoC加上HLS提高了系统设计的抽象度,并且将用户从FPGA驱动问题中解放出来,但它还是更适合系统程序员。这是因为程序员必须掌握算法、架构、接口、物理地址分配、软件驱动的实现和应用软件的实现等相关知识。这种设计流程的缺点是系统程序员一般有更多硬件架构和软件知识,但是对算法和应用了解较少,反之亦然。
HLS对于FPGA的设计,可被视为通用计算机系统的编译器。显然,尽管使用了高级语言,HLS用户还是需要直面FPGA。因此,类似于通用处理器的操作系统,FPGA中也需要一个虚拟层通过屏蔽硬件细节进一步提高用户的开发效率。从这个角度看一些工作已经展开了。LEAP[11]是一个FPGA操作系统,解决高延迟、抽象交互、多片FPGA的内存模型和混合算法。RAMP[1]项目为处理器加速。CoRAM[12]项目侧重在应用程序到多级内存的接口和可重构逻辑的内存模型。更多的相关工作在参考文献[10]、[13]、[14]中可见。
本文提出了一个方便应用程序员使用FPGA异构平台的框架,这个框架专为嵌入式系统下计算机视觉应用做了优化。它使用Xilinx Vivado,因此可以立即使用,而不是重新实现一套开发工具。用本文框架开发应用,在CPU和FPGA上都使用C/C++。程序的主入口在CPU端,FPGA在执行期间重新配置和调用。它让用户不用处理硬件和结构细节,让他们更关注算法和应用程序。通过实现一个常用的计算机视觉特征检测算法——SURF (Speeded-Up Robust Features)[15],从一个应用程序员的角度验证了该框架,显示了这个框架适用于应用程序员使用FPGA异构平台。
1 框架结构
如图1所示,在FPGA端和CPU端,框架支持应用程序员使用C/C++。在FPGA端,算法或者模块使用C/C++设计,接着由硬件并行加速,同时设计一个接口,其包含AMBA和AXI,然后用HLS工具翻译,综合生成IP核。这些包含AXI的IP核可以挂载到合适的位置,来构造整个FPGA部分。用户的IP核是应用程序员面向应用开发的,其他模块(如FPGA驱动I/O和内存)都是本文框架提供的一部分。因此,应用程序员可以集中关注如何更好地实现指定应用的算法和模块。由于在Vivado HLS中提供了C/C++语言支持和优化方案,所以算法或者模块可以由软件程序员实现。通过提前分配固定地址,用户可以避免在不同的应用中每次都要手动挂载IP核,这进一步使得C/C++程序员不需要太多的架构知识就能够为FPGA开发算法。在CPU端,算法或者模块也是使用C/C++开发,然后在CPU上执行。它们编译和链接生成可执行文件,在CPU上执行的模块可以通过带AXI协议的接口与FPGA部分进行通信。
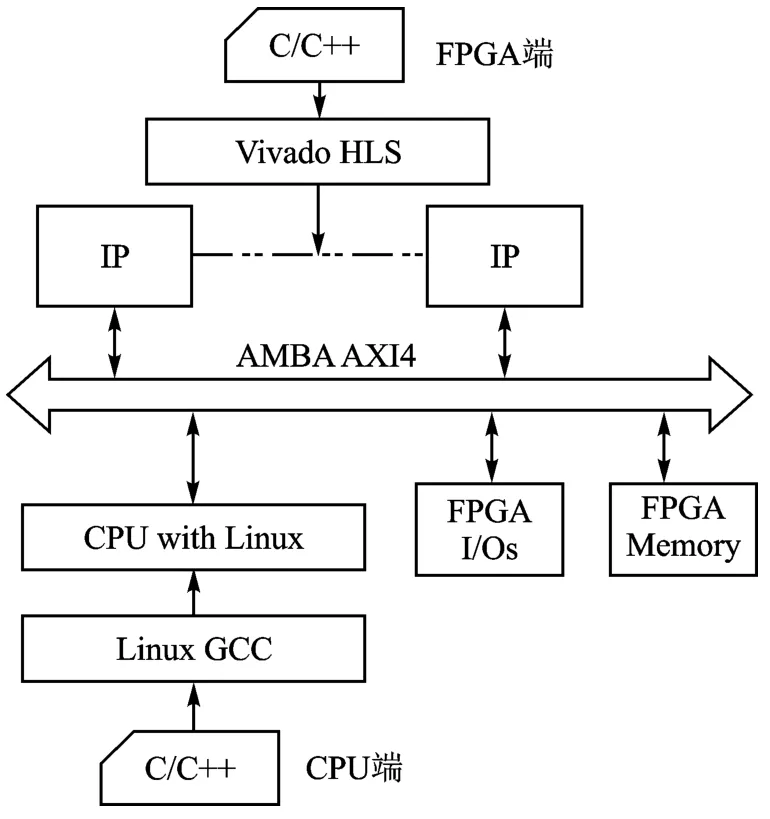
图1 框架体系结构
1.1 FPGA端系统设计
FPGA端架构略——编者注,在当前版本的框架中, AXI用作IP核、I/O、FPGA内存和处理器之间的互连协议,AXI4、AXI stream和AXI-lite在FPGA内实现。通过实现这个架构和提前分配用户IP核地址,使IP核、FPGA部分的I/O和内存对处理器是可见的,并且可以像资源一样管理。分配的IP核地址空间可以映射到虚拟地址,由CPU上的操作系统进行管理,使得CPU用户不用开发设备驱动来实现与IP核的通信,因此,应用程序员可以更好地在CPU端开发算法。为了实现扩展性,框架设计成可以包含多个IP核和I/O接口。
1.2 CPU端系统设计
为了方便CPU应用程序员调用FPGA上实现的功能,本文的框架提供了一系列的API,方便他们使用FPGA模块而不需要实现一些特定的驱动程序,包括用特定的功能模块配置FPGA、设置FPGA模块参数与FPGA通信等。
Config(lib_name,bin_file,algorithm_info);用指定的比特流配置FPGA和保存算法信息中FPGA资源相关的信息,以方便后续CPU的管理
Algorithm_set(point IPcore,parameter_name,parameter_value);在运行之前为FPGA模块配置算法参数
FPGA_mem_request(point point_name,data_size); FPGA_mem_release(point point name);请求和释放一块FPGA内存
ARM_tx(point ARM_source,point FPGA_destination,intncols,intnrows);ARM_rx(point ARM_destination,point FPGA_source,intncols,intnrows);实现CPU和FPGA之间的内存拷贝
Start(point IPcore);参数配置好之后,启动FPGA模块
reset(point IPcore);重置FPGA模块
2 基于框架的设计流程
图2是一个C/C++程序员实现FPGA异构系统的设计流程图。使用了本文的框架后,只有虚线以上的部分是需要应用者完成的,具体的将在后面介绍。
2.1 FPGA端用C/C++设计算法/模块
为了方便用户设计带有AXI的算法或者模块,在本文的框架中提供了一个模板。用户可以在该模板中嵌入他们的设计,然后使用#pragma构造带AXI的接口。算法优化需要利用更多的并行性,Vivado HLS提供了一些优化方案,如果用户有一些系统架构方面的知识,也可以手动进行优化。需要说明的是,Vivado HLS中仿真阶段的调试是不在这里讨论的。

图2 实现FPGA异构系统设计流程图
2.2 算法设计后生成IP核
用C/C++实现的算法/模块可以由Vivado生成一个IP核,它在后面可以作为一个组件,然后,这个IP核可以通过AXI挂载在一个合适的位置。因为分配的固定地址列表和总线互连的体系结构是提前实现的,用户可以在无需了解太多架构知识前提下,将他们的IP核挂载在指定的位置。
2.3 CPU端用C/C++设计算法/模块
算法或者模块适合在CPU上执行,主程序可以使用C/C++在传统的软件开发环境中实现。正如第1.2节介绍的那样,框架提供的API可以让用户配置FPGA、设置参数和使用FPGA模块,因此通过使用这些API,程序员能够操作FPGA模块和解析数据。用户设计一个新的FPGA模块就需要设计一个API,以方便上层用户以纯软件的方式调用FPGA功能。
2.4 为CPU生成可执行文件
第二部分的项目由Linux GCC编译和链接生成可执行文件,它在执行时可以重新配置FPGA和调用FPGA模块。
本文框架的用户可以分为3类:①同时在FPGA和CPU上实现算法;②只在FPGA上实现算法;③只在CPU上实现算法。对于第一种用户,需要用到上面描述的整个设计流程;对于第二种用户,除了实现IP核,还需要为上层用户提供软件API,它具有特定的功能,可以根据需要配置和操作相应的IP核;对于第三种用户,如同常规的软件程序员,他们在CPU上使用由第二种用户提供的API,甚至不知道已经用到FPGA模块。当更多的IP核被不同的程序员实现时,大量的应用就能够通过传统的软件开发程序员在CPU上开发。
正如图2所示,用本文的框架开发FPGA异构平台系统,可以省略两个步骤:构造FPGA系统和开发设备驱动。这两步都是系统层面上的,需要用户拥有更多的计算机体系结构和操作系统的知识。此外,FPGA的重构是本文框架提供的一个内置函数,对于一个应用程序员来说,它的实现是极难的。
3 框架评估
为了验证本文框架对于C/C++应用程序员的可用性,在本节中,将展示使用本文框架的SURF特征提取的实现结果。
实验平台是一块用于视觉计算的开发板,其他使用SoC的异构平台也可以使用本文的框架。如图3所示,开发板包含Xilinx Spartan-6 XC6S LX150T FPGA和三星Cortex-A8 S5PV210 1 GHz的处理器。FPGA和ARM通过16位的数据总线和16位的地址总线连接,地址总线通过片选信号可以切换到两个不同的地址空间。4个GPIO用作控制信号,4位SPI和7位GPIO用于处理器配置FPGA,有4个16位的DDR3与FPGA连接,为视觉算法计算提供了高带宽内存访问,CMOS和Camera Link两个接口提供视频输入。

图3 用于视觉计算的ARM--FPGA异构开发板
3.1 SURF算法简介
SURF[15]是一个常用的算法,用于局部特征检测和描述,它对图像缩放、旋转和光照等变化不敏感。SURF主要分为3个步骤:初始化、特征提取和特征描述。
初始化:这一步主要是做一些准备工作,例如加载图片,得到图像像素点的大小和积分图。
特征提取:这一步检测图像或者视频帧里面的特征点。通过对图片进行多尺度的缩放,构建一个基于尺度空间的Hessian金字塔,然后对它进行分析。因此,特征点是从不同尺度上得到的,保证了算法对尺度变化的鲁棒性。尺度空间分析后,用非最大抑制在一个3×3×3的模板里求出最稳定点,也就是说,如果某点的值大于模板内其他26个点的值,它就被认为是特征点。
特征描述:在这一步,每一个特征点都求得一个特征向量用于描述这个点。首先计算特征方向以保证算法旋转不变,然后根据特征方向来计算特征向量,接着每一个特征点都由一个64维的特征向量表示,最后对它进行归一化来保证光照不变性。
3.2 在框架上实现SURF特征检测算法
因为初始化和检测阶段具有明显的并行性[16],它们更容易被软件程序员优化。因此,在本文,只在FPGA上实现了初始化和特征检测两个步骤。根据第3部分的设计流程图,用本文的方法实现SURF的过程如下:
①用C/C++设计SURF检测代码。首先在Xilinx Vivado上建立一个HLS工程,然后定义SURF检测的实体:

在本文的框架中提供了实体模板,方便程序员使用。其中hls int32为32位的整型,inout_pix为输入和输出缓存的首地址,byte_rdoffset为读的偏移量,而byte_wroffset为写的偏移量,rows和cols为图片的行和列。最后,用C/C++编写的SURF检测模块就完成了。
②在SURF检测模块中添加AXI4。检测模板包含AXI4的接口,可以利用Vivado HLS提供的定义。

下面定义了AXI4-Lite的返回寄存器:

③优化SURF检测代码,实现更好的并行度。软件人员可以利用Vivado HLS提供的方法优化他们的C/C++代码,而更进一步的优化则需要手动进行。
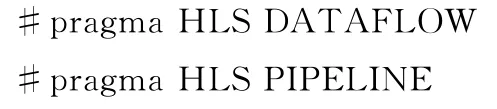
④SURF检测模块生成Pcore,由Vivado中的EDK将SURF代码生成Pcore。
⑤将Pcore挂载在框架的FPGA端。将上述产生的Pcore挂载到本文框架的FPGA上。由于使用的是Spartan-6的FPGA开发板,所以采用的是Xilinx ISE。本文的框架在FPGA上是一个已经设计好的工程,SURF算法的Pcore只需要选择作为一个IP模块,就可以很容易地连接到框架的一个固定接口上。
⑥生成配置FPGA的比特流,并且为上层用户设计API。当将用户的Pcore连接到FPGA的框架上后,整个系统可以合成一个比特流文件,用来配置FPGA。然后,按照第3部分来设计API,供上层用户使用。
⑦最后一步在CPU上设计模块,基于API在异构平台之上构建整个应用程序。
3.3 实验结果
首先对SURF在带有本文框架的FPGA异构平台、ARM嵌入式平台和PC三个平台上的执行时间进行了比较,然后比较了SURF算法在带和不带有本文框架时,在FPGA上的资源消耗情况,最后验证了图片的检测结果和带框架的检测结果的准确性。除了之前介绍的开发板信息,在实验中,SURF检测算法的工作频率为62.5 MHz,PC的CPU为3.1 GHz AMD Athlon(tm)II X4 645,DDR3的频率为1.6 GHz。SURF检测算法的相关参数如表1所列。需要说明的是,在CPU中使用的是浮点型,而在FPGA中使用的是定点型。

表1 配置参数
3.3.1 运算时间
为了比较不同平台上SURF算法的执行时间,实验用的是同一组图片。图4(a)所示是不同平台和不同分辨率时的执行时间,图4(b)是放大后FPGA和PC的运算时间。从图中可以看出,FPGA的运算速度最快,同时随着图片容量的增大,加速的效果越明显,主要是因为并行计算时间的增加是线性的,这也反映了软件人员使用FPGA的重要性。
SURF检测算法在FPGA异构平台上的总运行时间图略——编者注,包括图片从ARM到FPGA的传输时间、计算时间和最后把结果从FPGA传回ARM的时间。从图中可以看到,把图片从ARM传到FPGA是最耗时的。即使认为计算时间包含这3个部分,它的时间也是远远低于ARM的,如果在FPGA上直接加摄像头捕捉图片就可以减去从ARM到FPGA传输图片的耗时。此外,要避免频繁地重配FPGA,因为Spartan-6 XC6SLX150T的重配时间需要2 s左右。

图4 不同平台上SURF检测执行时间
3.3.2 资源消耗
带本文框架和不带本文框架时,SURF检测算法的资源消耗情况图略——编者注。从图中可以看出,框架只占用了非常少的一部分资源,随着FPGA集成度不断增大,系统框架所带来的资源消耗是可以容忍并且愿意使用的,因为框架可以极大方便程序员使用FPGA异构平台。
3.3.3 检测结果
图5所示是带框架的FPGA异构平台的SURF检测算法的检测结果,显示了带框架后计算结果的准确性。虽然使用定点计算会导致计算结果与准确结果有一定偏差,但是通过调整阈值可以提高结果的准确性。
结 语
传统的FPGA的开发方法,对于软件程序员来说是非常困难的,尤其是当应用程序员对系统结构知识了解不多的时候。但是,应用程序员又最了解市场和用户的需求,通用处理器领域,多层结构使应用程序员远离了底层细节,提高了生产力,缩短了研发到投放市场的时间。随着集成度越来越高,FPGA可以容忍来自系统虚拟化的资源消耗,同时,FPGA也需要虚拟化技术来提高资源管理和生产力。本文设计的框架可以使得C/C++应用程序员更关注在FPGA和CPU上实现特定的功能。同时,框架集成到了商业工具链(如Xilinx Vivado)中,可以立即使用。一个软件人员在包含此框架的基于FPGA的异构平台上成功实现了一个常用的特征检测算法,表明此框架是可用的。下一步,适合软件人员的调试方案也将集成到此框架中,此外,其他虚拟化技术(如虚拟内存、多片FPGA的分区),在LEAP和CoRAM中研究的一些内容也会集成到这个框架中。

图5 FPGA加速异构平台的SURF检测结果
编者注:本文为期刊缩略版,全文见本刊网站www. mesnet.com.cn。
[1]J Wawrzynek M,Oskin C,Kozyrakis D,et al.RAMP:A Research Acceleratorfor Multiple Processors[C]//Technical Report,2006.
[2]U Vishkin.Is Multicore Hardware for General-purpose Parallel Process-ing Broken[J].Communications of ACM,2014, 57(4):35-39.
[3]C Pascoe,A Lawande,H Lam,et al.Recon gurable Supercomputing with Scalable Systolic Arrays and In Stream Control for Wavefront Genomics Processing[C]//Proceedings of International Conference on Engineering of Recon gurable Systems and Algorithms,2010.
[4]X Tian,K Benkrid.High-Performance Quasi-Monte Carlo Financial Simulation:FPGA vs.GPP vs.GPU,ACM Trans. Recong.Techn.Syst.3,4,Article 26(November 2010), 22 pages.
[5]Xilinx.Zynq-7000 SoC[EB/OL].[2016-05].http://www.xilinx.com/products/silicon-devices/soc/zynq-7000/index.htm.
[6]G Martin,G Smith.High-Level Synthesis:Past,Present,and Future[J].IEEE Design and Test of Computers,2009:18-24.
[7]E S Chung,P A Milder,J C Hoe,et al.Single-Chip Heterogeneous Computing:Does the Future Include Custom Logic, FPGAs and GPGPUs[C]//Proceedings of IEEE/ACM International Symposium on Microarchitecture,2010:225-236.
[8]E S Chungy,J D Davisy,J Lee.LINQits:Big Data on Little Clients[C]//Proceedings of ACM/IEEE International Symposium on Computer Architecture,ISCA 2013.
[9]Xilinx.Vivado Design Suite[EB/OL].[2016-05].http:// www.xilinx.com/products/designtools/vivado/.
[10]Altera.Altera SDK for OpenCL Programming Guide[EB/ OL].[2016-05].http://http://www.altera.com/literature/hb/opencl-sdk/.
[11]A Parashar,M Adler,K E Fleming,et al.LEAP:A Virtual Platform Architecture for FPGAs[EB/OL].[2016-05].http://asim.csail.mit.edu/redmine/attachments/76/.
[12]S T Yamazaki,J C Hoe.PyCoRAM:Yet Another Implementation of CoRAM Memory Architecture for Modern FPGA-based Computing[C]//3rd Workshop on the Intersections of Computer Architecture and Recon gurable Logic,2013.
[13]H K H So,R Brodersen.A Uni?ed Hardware/Software Runtime Environment for FPGA-Based Recon?gurable Computers using BORPH[J].ACM Transactions on Embedded Computing Systems(TECS),2008,7(2).
[14]R Kirchgessner,A D George,H Lam.Recon gurable Computing Middleware for Application Portability and Productivity[C]//Proceedings of IEEE International Conference on Application-speci c Systems,Architectures and Processors, 2013:211-218.
[15]H Bay,T Tuytelaars,L V Gool.Surf:Speeded up robust features[C]//Proceedings of European Conference on Computer Vision.
[16]Z Fang,D Yang,W Zhang,et al.A Comprehensive Analysis and Parallelization of an Image Retrieval Algorithm[C]// Proceedings of IEEE International Symposium on Performance Analysis of Systems and Software,2011.
沈镇(硕士研究生),主要研究方向为嵌入式系统、图像处理;柴志雷(副教授),主要研究方向为嵌入式系统设计技术、机器视觉、FPGA操作系统等;柴镇(硕士研究生),主要研究方向为嵌入式系统、可重构计算。
A Framework for Application Programmers to Design FPGA-based Systems※
Shen Zhen,Chai Zhilei,Chai Zhen
(School of Internet of Things,Jiangnan University,Wuxi 214122,China)
In the paper,the Open HEC(Open Framework for High-Effciency Computing)framework is proposed to provide a design framework for application-level software programmers to use FPGA-based platform.It frees users from hardware and architectural details to let them focus more on algorithms/applications.This framework is integrated with the commercial Xilinx ISE/Vivado to make it to be used immediately.After implementing a widely-used feature detection algorithm on Open HEC from the perspective of software programmers,it shows that this framework is applicable for application programmers with little hardware knowledge.
FPGA;embedded system;feature detection;application program
TP368
:A
薛士然
2016-05-24)
