应用经遗传算法优化的BP神经网络预测催化裂化装置焦炭产率
2016-03-18苏鑫裴华健吴迎亚高金森蓝兴英中国石油大学北京重质油国家重点实验室北京102249
苏鑫,裴华健,吴迎亚,高金森,蓝兴英(中国石油大学(北京)重质油国家重点实验室,北京 102249)
应用经遗传算法优化的BP神经网络预测催化裂化装置焦炭产率
苏鑫,裴华健,吴迎亚,高金森,蓝兴英
(中国石油大学(北京)重质油国家重点实验室,北京 102249)
摘要:焦炭是催化裂化装置的主要副产物,准确预测催化裂化焦炭产率对提高装置的操作平稳度和经济效益具有重要意义。人工神经网络(ANN)具有强大的自学习和自适应能力,在非线性预测方面具有明显的优势。本研究将遗传算法(GA)与BP神经网络相结合,基于某炼厂催化裂化装置的生产数据,分别从原料、催化剂和操作条件3个方面选取28个关键影响参数建立了催化裂化焦炭产率预测模型,分别将BP神经网络和经遗传算法优化的BP神经网络(GA-BP)的预测结果与工业数据进行对比。结果表明,经遗传算法优化的预测模型无论在预测结果的准确性还是稳定性方面效果更好。最后,本研究还通过考察原料残炭、反应温度等单一关键参数对焦炭产率的影响,进一步证明了经遗传算法优化的BP神经网络预测模型的准确性。
关键词:催化裂化;焦炭产率;神经网络;遗传算法
第一作者:苏鑫(1989—),男,硕士研究生。联系人:蓝兴英,博士,教授。E-mail lanxy@cup.edu.cn。
催化裂化(FCC)是重质油轻质化的重要手段之一,可以通过将重质原料最大程度地转化为轻质油和高质量产品来提高炼油行业的经济效益。目前,我国70%的商品汽油和30%的商品柴油均来自于催化裂化装置[1]。由于我国原油普遍偏重,目前绝大多数催化裂化装置均为重油催化裂化(RFCC),其中95%以上的装置掺炼渣油[2]。催化裂化是指蜡油和重质原料油在催化剂和适宜的温度和压力的作用下转化为干气、液化气、汽油、柴油和焦炭等。随着原油重质化劣质化程度的不断加剧,催化裂化装置的焦炭产率不断增加,严重影响了装置运行的经济效益。催化裂化焦炭是原料发生缩合反应的产物,焦炭产率增加不但通过催化裂化反应的碳平衡使汽油、柴油等轻质油品产率降低,而且生成的焦炭沉积在催化剂表面也降低了催化剂的活性使反应深度降低轻质油品的收率下降[3]。另外,催化裂化装置的焦炭产率也决定了装置的热平衡[4],如果装置焦炭产率波动较大会严重影响装置的热平衡,增加操作复杂性,焦炭产率过大还会增加再生器的负荷。因此,将催化裂化装置焦炭产率控制在较低的小范围内波动对于装置的生产操作和提高装置的经济效益具有重要作用,而其前提是能够准确地预测装置当前运行状态下的焦炭产率。焦炭产率不但与原料的反应情况相关而且与催化剂的再生过程关系密切。催化裂化装置工艺复杂,连续程度高,反应机理复杂[5],其反应过程受原料性质、催化剂性质以及操作条件相互影响,用传统的数学模型来描述催化裂化的整个反应过程有一定的难度[6]。近年来,基于数据分析的数学建模方法已经成为一个新的努力方向。
人工神经网络(artificial neural network,ANN)是一种可以模拟人类大脑的结构和功能的智能算法,具有强大的自学习和自适应能力以及分布并行处理能力,可以进行多变量影响程度分析和非线性预测分析,近年来得到越来越广泛的应用[7-9]。目前,应用相对成熟的神经网络有BP神经网络[10]、GRNN神经网络、RBF网络[11]等。神经网络具有以下优点:①理论上能够逼近任意非线性映射;②善于处理多输入输出问题;③能够进行并行分布式处理;④自学习与自适应性强;⑤可同时处理多种定性和定量的数据。BP神经网络是一种多层前馈型的神经网络,该网络最主要的特点就是信号向前传递,误差向后传递。BP神经网络可以通过样本数据训练实现从n维空间到m维空间的高度非线性映射关系,应用非常广泛[12]。但BP神经网络本身也存在一定的缺陷,其主要体现在开始训练样本阶段,初始权值和阈值都是随机生成的,其不确定性会影响到模型的映射效果,即预测精度。遗传算法(genetic algorithm,GA)是一种并行随机搜索最优化方法,具有全局寻优的特点,容易得到全局最优解[13]。如果能将遗传算法得到的结果作为BP神经网络的最佳初始权值和阈值再开始训练,就可以有效地改善BP神经网络的预测准确性和稳定性。本研究通过经GA优化的BP神经网络建立一个能够准确预测催化裂化装置焦炭产率的模型,以某炼厂催化裂化装置为研究对象,对其焦炭产率进行预测并与工业数据进行对比分析,验证模型预测的准确性和稳定性。
1 焦炭产率预测模型的构建
1.1 数据的采集与预处理
本研究以某炼厂催化裂化反应-再生系统作为研究对象,通过现场DCS系统采集了2013年3月至2015年4月间约500个监控点的数据,总共约7000万组数据,把这些数据作为本文作者课题研究的初始数据库。催化裂化典型的反应-再生系统工艺流程,如图1所示[3],通过对反应-再生系统工艺流程以及催化裂化焦炭的类型和形成途径的了解,按照催化裂化焦炭的生成和烧焦过程,从工艺角度考虑,并结合所采集数据的质量、频次和特点等,分别针对原料、催化剂以及操作条件三大类参数,筛选出影响焦炭产率的关键参数,最终得到28个关键性影响参数,如表1所示。

图1 催化裂化反应-再生系统工艺流程图
由于某些客观原因,比如装置测量仪表损坏、数据信号传输过程中失真等因素,所采集到的数据可能出现异常情况,其表现为部分数据缺失、数据突变、数据为0或负值等。对于这些异常数据,本研究根据对催化裂化各类工艺参数的理解,对这些异常值进行预处理。数据预处理原则遵循以下几点:①保证所选时间段的所有参数都有值;②剔除或使用临近数据的平均值替代异常数据;③利用莱特准则剔除部分偏离均值较大的数据;④统一各参数的统计时间。
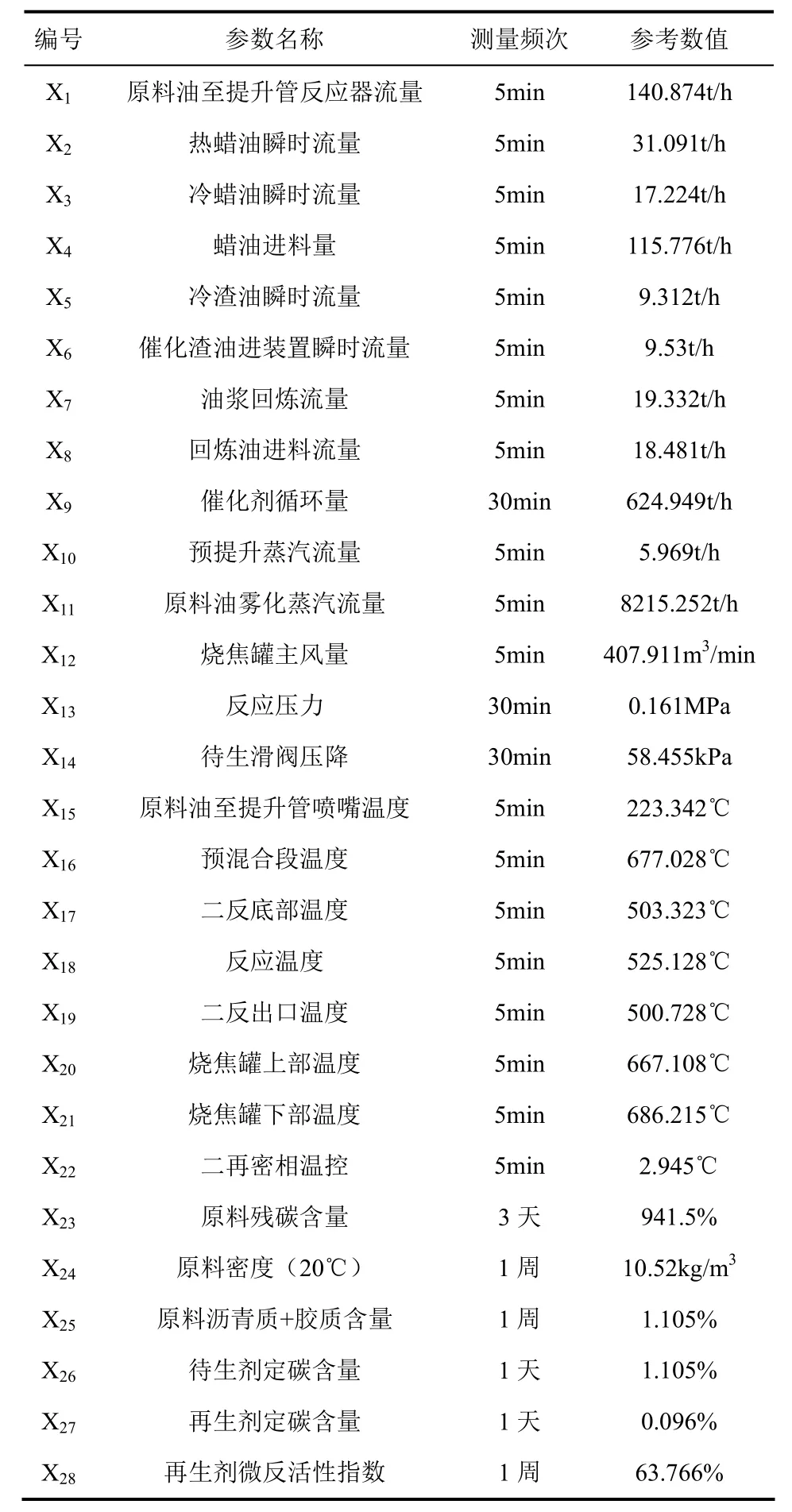
表1 影响焦炭产率的关键性参数
通过分析数据的特点,最后决定将数据的采集时间统一为60min,即将采集频率小于60min的数据进行平均处理,将采集频率大于60min的参数进行扩大化处理。按照以上思路选取现场装置约两个月的时间作为研究对象,对表1中X1~X28以及焦炭产率(Y1)进行预处理得到1295组数据如表2所示。
1.2 BP神经网络的构建
1.2.1 BP神经网络
BP神经网络[14]是一种多层前馈型神经网络,该神经网络的主要特点是信号向前传递,误差向后传递。BP神经网络由输入层,隐含层和输出层三层结构组成,如图2所示。BP神经网络通常将S形函数(Log-Sigmoid或Tan-Sigmoid)作为传递函数。所谓的反向传播学习算法就是输入信息从输入层经过隐含层最后传至输出层。如果输出误差较大,那么就将误差信号沿着原来的途径返回进行反向学习,在返回过程中通过修改各神经元之间的连接权值和阈值,得到新的输出误差,直到误差信号最小。

表2 预处理之后的影响催化裂化焦炭产率部分数据
如图2所示,输入值为X1,X2,··,Xn,输出值为Y1,Y2,··,Ym,连接权值为ωij和ωjk。从拓扑结构图中看出,BP神经网络相当于一个非线性函数,将输入值映射到输出值。

图2 BP神经网络拓扑结构图
1.2.2 BP神经网络预测模型的构建
将预处理之后的1295组所有的数据参照式(1)进行归一化处理,使其分布在0~1之间。

式中,Xnorm为归一化后的值,X为实际输入值,Xmax和Xmin为实际输入值中的最大值和最小值。
将归一化处理之后的数据分成训练组和预测组,再利用Matlab中的newff函数创建BP神经网络,然后将利用新构建的神经网络模型的预测结果进行反归一化,得到最终结果。
本研究采用输入层、输出层和隐含层各一层的三层BP神经网络结构。归一化后将28个关键性参数作为输入层,焦炭产率作为输出层,因此输入层和输出层的神经元个数分别为28和1。隐含层节点数的选择参考式(2)[4]。

式中,m为输入层的节点数;n为输出层的节点数。
由式(2)可知,该神经网络的隐含层节点数在6~16之间,利用newff函数训练样本数据构建BP神经网络模型。选取其中的647组数据训练BP神经网络得到预测模型,剩余的648组数据作为预测样本验证模型的准确性。
1.3 遗传算法优化BP神经网络
遗传算法是一种并行随机搜索最优化方法,可以在全局范围内进行寻优。它模拟“优胜劣汰,适者生存”的自然界进化原理,按照所定义的适应度函数对个体进行反复筛选,反复循环,直到满足条件。如果能将遗传算法寻优得到的最优初始权值和阈值赋予BP神经网络并开始训练,就可改善BP神经网络模型的预测准确性和稳定性[15-16],其优化过程如下:① 编码权值或阈值并随机产生一组各神经元之间的连接权值或阈值;②输入训练样本,算出它的误差,并定义绝对误差之和为适应度函数,若误差越小,则适应度越小,反之适应度就大,以此为标准来评价连接权值或阈值的优劣性;③从步骤②中筛选出绝对误差之和较小的个体,直接将其遗传给下一代;④通过交叉、变异等操作进化当前群体,产生下一代群体;⑤重复步骤②~④,这样神经网络的初始权值或阈值得到不断更新,直到足够多进化代数的适应度保持不变。
2 结果与讨论
2.1 BP神经网络模型预测结果分析
将预测样本数据代入所得的BP神经网络预测模型中,计算得到每个时间点的焦炭产率,并根据式(3)和式(4)计算预测的相对误差和平均相对误差,然后在相同条件下进行20次的训练和预测,并计算不同隐含层节点数下20次预测的平均相对误差的平均值,如图3所示,分别比较不同数量隐含层节点20次预测结果平均相对误差的平均值。

由图3可看出,当隐含层节点数为12时平均相对误差最小,因此,认为最佳隐含层节点数为12,故BP神经网络拓扑结构为28-12-1型,本研究的后续工作均是基于该拓扑结构的BP神经网络进行讨论分析的。

图3 不同数量隐含层节点焦炭产率预测值的平均相对误差
本研究使用完全相同的训练和验证数据库,并保持BP神经网络相关参数不变,多次训练和验证发现结果存在一定差异,选取两次训练结果并根据式(3)和式(4)分别计算平均相对误差,其结果分别为3.43%和4.33%。图4表示了这两次同等条件下训练的BP神经网络预测结果误差。从图4中可以看出,两次训练结果存在差异,而且最大误差将近25%,说明BP神经网络训练结果不稳定,这主要是由于BP神经网络是随机选取初始权值和阈值,这种随机性会造成训练模型准确度和稳定性都大幅降低[17]。

图4 两次训练得到的BP神经网络预测结果误差示意图
2.2 经遗传算法优化的BP神经网络模型预测结果分析
针对BP神经网络的随机选取初始权值和阈值的缺陷,本研究采用遗传算法对BP神经网络的初始权值和阈值进行优化,确定最佳的初始权值和阈值,将一定的初始权值和阈值赋予BP神经网络就可以消除其结果的随机性,提高模型的准确性和稳定性[18]。本研究利用遗传算法进化1000代,得到最优个体适应度变化曲线图,如图5所示。由图5可知,最终得到的最优个体适应度为31.697,对应的进化代数为558,之后442代适应度不再发生变化,因此,可以判定此时已达到个体最优适应度。将该寻优结果得到的初始权值和阈值赋予BP神经网络进行模型训练,其多次训练得到模型的预测结果完全一致。
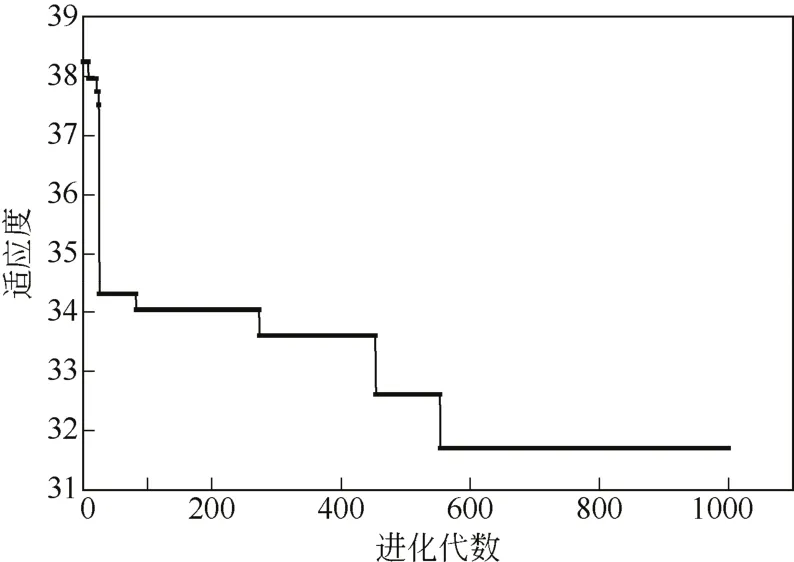
图5 遗传算法个体适应度寻优曲线
利用经遗传算法优化的BP神经网络得到的预测模型(GA-BP)对催化裂化的焦炭产率进行预测,将预测结果与工业数据进行对比分析,如图6所示。
由图6可以看出,经遗传算法优化后的BP神经网络模型的预测值总体趋势与工业数据吻合较好,基本上没有出现偏差较大的预测值。由式(3)计算得到预测值的相对误差,如图7所示。
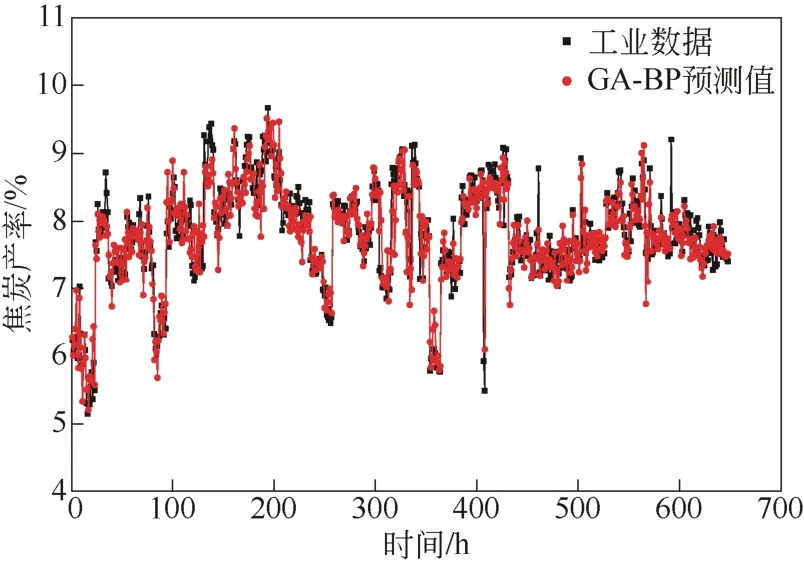
图6 GA-BP神经网络预测的焦炭产率与工业数据对比

图7 GA-BP神经网络预测的焦炭产率相对误差
由图7可以看出,利用经遗传算法优化后的BP神经网络预测模型得到的焦炭产率的相对误差大于10%的点仅20个左右,仅占总预测样本数的3.1%,而且绝大多数预测值的相对误差都在5%以下,表明该预测模型的预测效果非常好,能够准确地对焦炭产率进行预测。由式(4)和式(5)计算平均相对误差和均方误差,其结果分别为2.94%和0.111。因此,无论是从预测结果的准确性还是预测稳定性上来看,经遗传算法优化的BP神经网络预测模型能起到良好的预测效果。

式中,MSE为均方误差;Xi为实际值;Yi为预测值;n为样本数据个数。
经过遗传算法优化的BP神经网络(GA-BP)和未经过遗传算法优化的BP神经网络(BP)预测结果与工业数据对比如图8。从图8中可以看出,两种预测模型的预测结果整体趋势上与工业数据相符。为方便对比分析,将图8中某段时间数据进行放大,取图中390~430h的数据放大后如图9所示。从图9中可以看出,虽然两种预测模型的预测结果在整体趋势上与工业数据基本相符,但经遗传算法优化的BP神经网络比未经优化的BP神经网络预测预测值更接近工业数据,这主要是遗传算法可以赋予BP神经网络最佳的初始权值和阈值,这样便提高了预测模型的准确性。因此,遗传算法不但可以提高BP神经网络预测的稳定性还可以提高其准确性。
2.3 经遗传算法优化的BP神经网络模型验证
基于上述研究,为进一步验证所建立模型的准确性,本研究应用GA-BP神经网络预测模型考察催化裂化装置中的某单一关键性影响参数对焦炭产率的影响,其基本思路为:使用标定工况的原料性质、催化剂性质和操作参数,只改变其中某一个关键性参数,得到一组装置的运行工况,将这一组工况分别带入预测模型,得到焦炭产率的预测值。现分别从原料性质、催化剂性质和操作条件等方面选取几个具有代表性的关键性参数进行深入研究,分析其对焦炭产率的影响。
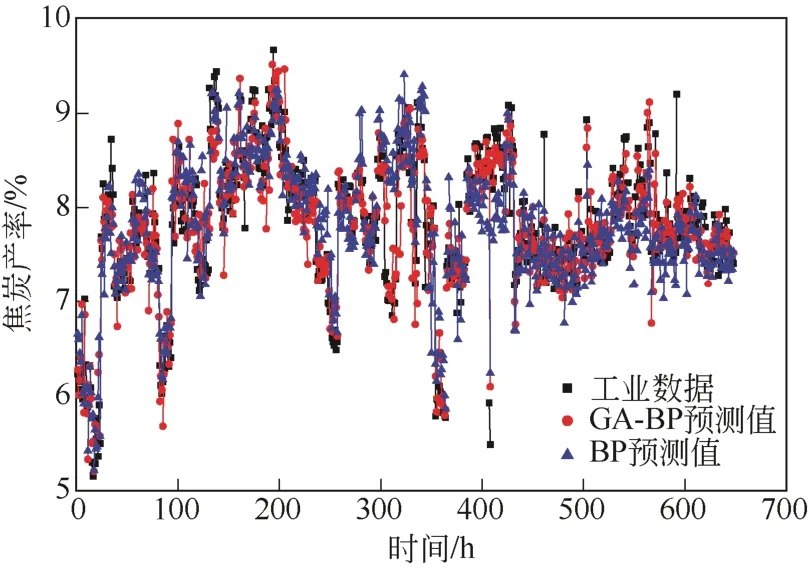
图8 BP神经网络和经遗传算法优化的BP神经网络预测结果与工业数据对比图

图9 某时间段内BP神经网络和经遗传算法优化的BP神经网络预测结果与工业数据对比图
本研究首先考察了原料残炭对催化裂化焦炭产率的影响,其具体步骤是使用装置标定工况控制除原料残炭值外的其他27个操作参数不变,只改变原料油的残炭,使其在正常范围内取值,得到一组的操作工况。分别将这一组操作工况代入到GA-BP预测模型中,得到不同原料残炭值标定工况下的焦炭产率。采用类似的方法又分别考察了催化剂循环量、预混合温度和反应温度对催化裂化焦炭产率的影响,其结果如图10~图13所示。
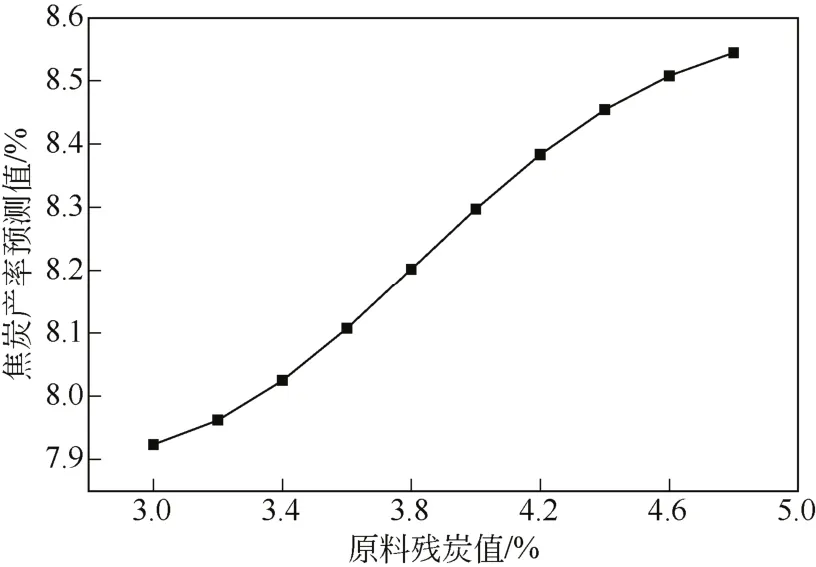
图10 原料残炭值对焦炭产率的影响
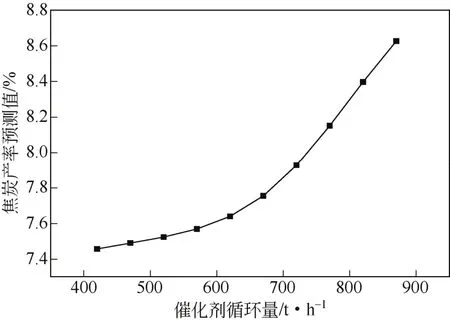
图11 催化剂循环量对焦炭产率的影响
图10表示了原料残炭值对焦炭产率的影响情况,由图可见随原料残炭值的增加,焦炭产率随之增加。这主要是由于原料残炭增加,原料油的沥青质、胶质和稠环芳烃含量增加,而稠环芳烃正是生焦的前身物,因此焦炭产率会随之增加[19]。图11表示了催化剂循环量对焦炭产率的影响情况,可见随着催化剂循环量的增大,焦炭产率随之增加。这主要是由于在该催化剂循环量的取值范围内,催化剂循环量增加,剂油比增加,则单位质量油气接触的催化剂活性中心的个数增加,反应速率和转化率相应增加,最后导致焦炭产率增加。图12表示了预混合温度对焦炭产率的影响情况,可见随预混合温度的升高,焦炭产率随之增加。这主要是由于在该预混合温度操作范围内,预混合温度越高,油气与催化剂的温差增大,更容易出现局部过热的现象,使热裂化反应程度加深,催化剂迅速积炭活性下降,催化裂化反应减弱,原料中的重组分不能与催化剂的活性中心充分接触,降低催化裂化反应而增加热裂化反应,焦炭产率升高[20]。图13表示了反应温度对焦炭产率的影响情况,可见随着反应温度的升高,焦炭产率逐渐降低但当温度升高到一定程度时焦炭产率又呈上升趋势。这主要是由于随着反应温度的升高催化裂化反应速率增大,同时热裂化反应也逐渐提高,当反应温度升高到一定程度时,热裂化反应渐趋重要,使焦炭产率有所增加[21]。图10~图13的研究结果表明,利用GA-BP神经网络预测模型考察的原料残炭等单一关键性影响参数对催化裂化焦炭产率的影响,其结果与催化裂化的反应机理完全相符,进一步证明了该预测模型的准确性。

图12 预混合温度对焦炭产率的影响

图13 反应温度对焦炭产率的影响
3 结 论
基于某炼厂催化裂化车间DCS系统中的生产数据,以原料性质、催化剂性质和操作条件3个方面共28个影响催化裂化焦炭产率的关键参数为输入参数,所对应的焦炭产率作为输出应用经遗传算法优化的BP神经网络构建催化裂化焦炭产率预测模型,研究结果表明利用经遗传算法优化的BP神经网络可以建立能够准确预测催化裂化焦炭产率的预测模型,使用现场某段时间数据进行模型验证,预测的平均相对误差为2.94%,均方误差为0.111。与未经优化的BP神经网络预测结果相比,遗传算法不但可以解决BP神经网络随机选取初始权值和阈值造成的预测结果不稳定的问题,而且还可以通过搜索最优的初始权值和阈值赋予BP神经网络提高模型的准确性。应用所建立的GA-BP神经网络预测模型,分别考察了原料残炭、催化剂循环量、预混合温度和反应温度对焦炭产率的影响,其影响趋势与催化裂化的反应机理完全相符,进一步说明了所建模型的准确性。
参 考 文 献
[1] 许友好. 我国催化裂化工艺技术进展[J]. 中国科学(化学),2014,44(1):13-24.
[2] 米英泽. 1.2Mt/a减压渣油催化裂化装置优化技术研究[J]. 能源化工,2015,36(2):35-38.
[3] 徐春明,杨朝合. 石油炼制工程[M]. 4版. 北京:石油工业出版社,2009:294-315.
[4] 陈俊武. 催化裂化工艺与工程[M]. 2版. 北京:中国石化出版社,2005:896-901.
[5] 栗伟. 催化裂化过程建模与应用研究[D]. 杭州:浙江大学,2010.
[6] MICHAELOPOULOS J,PAPADOKONSTADAKIS S,ARAMPATZIS G,et al. Modelling of an industrial fluid catalytic cracking unit using neural networks[J]. Chemical Engineering Research and Design,2001,79(2):137-14.
[7] 刘春艳,凌建春,寇林元,等. GA-BP神经网络与BP神经网络性能比较[J]. 中国卫生统计,2013,30(2):173-176,181.
[8] DESWAL S,PAL M. Artificial neural network based modeling of evaporation losses in reservoirs[J]. International Journal of Mathematical,Physical and Engineering Sciences,2008,2(4):177-181.
[9] 郝鑫. 广义回归神经网络和遗传算法研究及其在化工过程建模中的应用[D]. 杭州:浙江大学,2004.
[10] 丁云,于静江,周春晖. 原油蒸馏塔的质量估计和优化管理[J]. 石油炼制与化工,1994,25(5):23-28.
[11] 王文新,潘立登,李荣,等. 常减压蒸馏装置双模型结构RBF神经网络建模与应用[J]. 北京化工大学学报,2004,31(5):23-28.
[12] 吴仕勇. 基于数值计算方法的BP神经网络及遗传算法的优化研究[D]. 昆明:云南师范大学,2006.
[13] 丁建立,陈增强,袁著祉. 遗传算法与蚂蚁算法的融合[J]. 计算机研究与发展,2003,40(9):1351-1356.
[14] 王小川,史峰,郁磊,等. Matlab神经网络43个案例分析[M]. 北京:北京航空航天大学出版社,2013:1-7.
[15] 张忠洋,李泽钦,李宇龙,等. GA辅助BP神经网络预测催化裂化装置汽油产率[J]. 石油炼制与化工,2014,45(7):91-96.
[16] 侯嫚丹. 基于遗传算法的催化裂化反再过程建模与优化[D]. 哈尔滨:哈尔滨工业大学,2007.
[17] 江艳君,李柠,黄道. 修正初始权值的BP网络在CSTR故障诊断中的应用[J]. 华东理工大学学报,2004,30(2):207-210.
[18] 王崇骏,于汶滌,陈兆乾,等. 一种基于遗传算法的BP神经网络算法及其应用[J]. 南京大学学报(自然科学版),2003,39(5):459-466.
[19] 徐黎英. 渣油催化裂化的转化率、焦炭及干气产率[J]. 石油炼制与化工,1990(9):15-21.
[20] 龚剑洪,许友好,蔡智,等. MIP-DCR工艺技术的开发与工业应用[J]. 石油炼制与化工,2013,44(3):6-11.
[21] 江洪波,钟贵江,宁汇,等. 重油催化裂化MIP工艺集总动力学模型[J]. 石油学报(石油加工),2010,26(6):901-909.
·技术信息·
芳烃成套技术及应用获国家科技进步特等奖
2015年度国家科学技术奖的评选结果近日揭晓。高效环保芳烃成套技术及应用、京沪高速铁路工程获得国家科学技术进步奖特等奖;多光子纠缠干涉度量学获得国家自然科学奖一等奖;国家技术发明奖一等奖为南昌大学硅衬底LED项目;最高科学技术奖空缺。
获得国家自然科学奖二等奖的化学类项目有:高压下钠和锂单质及二元化合物的结构与物性、活体层次定量获取化学信号的新原理和新方法研究、分子尺度分离无机膜材料设计合成及其分离与催化性能研究、新型富勒烯的合成、石墨烯的电分析化学和生物分析化学研究、生物分子识别的分析化学基础研究等。
获得国家技术发明奖二等奖的化学类项目有:定向转化多元醇的生物催化剂创制及其应用关键技术、酵母核苷酸的生物制造关键技术突破及产业高端应用、节油轮胎用高性能橡胶纳米复合材料的设计及制备关键技术、乙烯三聚制1-己烯新型催化体系及成套工艺技术、特种液晶材料及调光膜制备技术、耐高温杂化硅树脂及其复合材料制备关键技术、基于拉伸流变的高分子材料绿色加工成型技术等。
获得国家科学技术进步奖二等奖的化学类项目有:PTT和原位功能化PET聚合及其复合纤维制备关键技术与产业化、满足国家第四阶段汽车排放标准的清洁汽油生产成套技术开发与应、青海盐湖低品位难开发钾盐高效利用技术、冷再生剂循环技术重油催化裂化装置工业应用、有机氟单体及高性能氟聚合物产业化新技术开发、红外吸收微粒的表面改性及在节能树脂中的应用、有机肥作用机制和产业化关键技术研究与推广、生物靶标导向的农药高效减量使用关键技术与应用、废轮胎修筑高性能沥青路面关键技术及工程应用等。
2015年度国家科学技术奖共授奖295项成果和7位外籍科技专家。国家自然科学奖42项,国家技术发明奖66项,国家科学技术进步奖187项,授予7名外籍科技专家国际科学技术合作奖。
研究开发
Predicting coke yield of FCC unit using genetic algorithm optimized BP neural network
SU Xin,PEI Huajian,WU Yingya,GAO Jinsen,LAN Xingying
(State Key Laboratory of Heavy Oil Processing,China University of Petroleum-Beijing,Beijing 102249,China)
Abstract:Coke is the main by-product of fluid catalytic cracking (FCC) process. It is of great significance to predict coke yield accurately to enhance stability and economic performance of FCC plant. Artificial neural network (ANN) has a strong self-learning and adaptive ability,and has obvious advantages in nonlinear forecasting. In this paper,a new model combining BP neural network and genetic algorithm (GA) was developed to predict coke yield by choosing 28 key parameters involving feedstock properties,catalyst properties and operating conditions of industrial data of FCC unit,The prediction results obtained from BP neural network and the genetic algorithm optimized BP neural network (GA-BP) were compared. The GA-BP model had a better result in both accuracy and stability. Furthermore,the influence of key parameters,such as reaction temperature,feedstock carbon residue on coke yield was investigated,which further proved the accuracy of BP neural network model optimized by genetic algorithm.
Key words:fluid catalytic cracking (FCC); coke yield; neural networks; genetic algorithm
收稿日期:2015-07-31;修改稿日期:2015-10-26。
DOI:10.16085/j.issn.1000-6613.2016.02.008
中图分类号:TE 624
文献标志码:A
文章编号:1000–6613(2016)02–0389–08
