运用FastDFS和Drill构建海量BIM族数据存储和查询平台
2016-03-16王宝会邢景轩
王宝会 邢景轩 高 远
(北京航空航天大学软件学院,北京 100191)
运用FastDFS和Drill构建海量BIM族数据存储和查询平台
王宝会 邢景轩 高 远
(北京航空航天大学软件学院,北京 100191)
BIM族数据属于半结构化数据,其数据结构相对松散且可变,难以使用传统关系数据库进行存储和查询。本文以FastDFS分布式文件系统和Drill实时查询引擎为基础,在BIM资源库下针对族数据的存储和查询构建了的分布式数据处理平台。经测试,较传统以关系数据库为核心的非分布式系统,存储性能和查询性能均有较大提升。
族数据; BIM; FastDFS; Drill
【DOI】 10.16670/j.cnki.cn11-5823/tu.2016.06.04
1 引言
BIM(Building Information Modeling)是“建筑信息建模”的简称。因其在缩短工期、节约成本、提高生产效率等方面的先天优势,BIM相关技术广泛应用于以美国为首的众多国家。[1]BIM技术的不断发展促使BIM相关数据迅速增长,建立BIM数据的资源库变得越发重要。族数据是BIM资源库中的主要处理对象。
1.1 数据介绍
1.1.1 族
族(Family)是Autodesk的BIM构建软件Revit中的一个概念。建筑模型由墙、窗、门等图元(Element)构成,族中包含了这些图元的几何定义和及其所使用的参数(其名称与含义),图1展示了Revit中的门图元及其门族,图中门图元为三维模型,其对应的族中包含了尺寸、材质等参数。族包含多个通用参数集,不同的族类型包含不同的参数集合,若图元参数的集合相同,则属于同一个族类型。属于同一族类型下具体实例的具体参数值可以各不相同。[2]
对项目中任何位置的图元族数据修改后,Revit 都能在整个项目内协调此修改,始终保持模型的一致性,如钢筋之间的间隔相等,如果修改了图元族数据中的长度,Revit会使这种等距关系仍保持不变。所以族是体现Revit参数化建模的数据基础,是BIM思想在Revit中的核心表现。
BIM资源库的作用之一便是汇总作为建筑模型数据基础的族资源,提高用户存储和查询族信息的效率,其中各不相同的族所包含的参数便是存储和查询的信息实体。

图1 Revit中的门图元与其门族
1.1.2 半结构化数据
Serge Abiteboul简要指出,半结构化数据(Semi-structured Data)既非完全无结构,又不同于传统关系数据库中的数据一般结构严谨。[3]李庆华和刘昊提出了一种用待确定文法分析半结构化数据的方法,并在文中给出了半结构化数据更为明确的定义:
“如果数据的结构所对应的语言无法用全局一致的上下文无关文法描述,但是存在数据的一个有序划分,对分割出来的每个分划,利用前i个分划的语义信息,可以得到第i+1个分划的局部一致的上下文无关文法,则称之为半结构化数据。[4]”
所谓“上下文无关”,即对于形式V→w,字符串V总可被任意字符串w自由替换,而无需考虑V出现的上下文[5]。
由此可见,区分结构化、非结构化和半结构化数据的关键在于数据是否存在全局或局部的上下文无关文法。
半结构化数据在数据结构定义上有很大的灵活性,适于描述互联网和大数据环境中多样的复杂数据,但这也使得传统的关系数据库对其无从下手,加大了数据存储、查询等操作的难度。
1.2 应用模块介绍
1.2.1 FastDFS
FastDFS(Fast Distributed File System)是一款类GFS(Google File System)的开源分布式文件存储系统,由淘宝网的资深架构师余庆开发。
FastDFS含有TrackerServer和StorageServer两种角色,分别负责调度任务和文件数据的存储。在架构和设计理念,较之其他分布式文件系统,其主要特点为轻量级、分组方式和对等结构。[6]
1.2.2 Drill
Drill是Apache Hadoop的顶级项目,是Google Dremel的开源实现。自2006年《Dremel:Interactive Analysis of Web-Scale Datasets》论文完成至今,Google以将Dremel广泛运用于Google Books的OCR检索和Gmail的垃圾邮件分析等场景。这些应用体现了Dremel实时分析、处理数据的优秀性能,也从侧面体现了Drill的实时查询在设计理念上的先进性。
由于不需要调用MapReduce,Drill可以在几秒内查询PB级的半结构化数据,为海量数据提供分布式的、低延迟的交互式查询服务。不同于Hive等查询系统提供了类SQL查询语句,Drill支持标准的SQL,减轻了开发人员的学习成本。
1.2.3 Zoopkeeper
Zoopkeeper同Drill一样,是隶属于Apache Hadoop家族的子项目,是Google Chubby的开源实现,为如Drill等分布式应用程序提供任务协调服务。
1.2.4 Neginx
Nginx(“Engine x”)是俄罗斯人Igor Sysoev编写的一款高性能的HTTP和反向代理服务器,可提供负载均衡服务。
1.2.5 Keepalived
Keepalived通过VRRP(Virtual Router Redundancy Protocol)协议为集群提供高可用性[]。VRRP,即虚拟路由冗余协议,可使用户通过虚拟IP多路访问链路上的多台路由器[8]。
2 族数据存储与查询需求分析
经总结,族数据有如下特点:
2.1 族数据是半结构化数据
图1显示,Revit族的数据模型为嵌套数据模型。显然族类型参数存在局部的上下文无关文法,根据李庆华和刘昊的定义(见引言),属于半结构化数据。半结构化数据可被类JSON的数据格式轻松表示。图3为族数据在类JSON[9]形式下的数据格式和数据实例,其中required为必须字段(有且仅有唯一值),optional为可选字段,repeated为可重复字段。

图3 族数据的类JSON数据格式和数据实例
在BIM资源库之上建立的族数据存储查询平台,应能存储和查询半结构化数据。
2.2 族数据为小文件
BIM的族数据主要以Revit的.rft文件格式存在,单个文件大小在KB级别,故族数据存储查询平台应善于处理海量的小文件。
2.3 族数据总体体量庞大
BIM思想在工程实践中经过多年的实践,积累了大量的族数据,又由于族数据是BIM从业公司的重要财产,虽然数据量庞大,但一般情况不会删除。所以族数据处理平台的存储系统应易于扩展,以适应不断增加的数据量。平台还应提供实时条件查询功能,如可在秒级时间查询出同属某种材料的门族,便于工作人员通过检索族信息的重要属性快速锁定所需族,以便其进行进一步的编辑操作。
2.4 族数据应用周期长
BIM数据应用于建筑设施的全部生命周期[10](见图4),而族数据作为BIM基础数据,更是会被反复运用于多个项目工程中。所以族数据存储查询平台应能为族数据提供高可用性存储,以保障数据的长期可靠保存。

图4 BIIM数据贯穿建筑设施全部生命周期
2 架构设计
根据族数据的存储和查询需求,在BIM资源库中设计了族数据存储及查询平台,其平台架构图见图5,物理拓扑图见图6。

图5 平台架构

图6 平台物理拓扑
平台用户界面部分由两台配置有为Negix和Keepalived的WebServer提供,其中Negix负责将存储和查询服务负载均衡至TrackerServer,Keepalived为这两台WebServer提供高可用性,并建立虚拟IP,为用户提供统一的服务接口。用户通过WebServer访问族数据存储及查询服务页面,WebServer将族数据从.rft文件转换至JSON文件。
存储系统由FastDFS集群组成,负责对JSON文件进行分布式存储,对其提供高可用性,并为查询系统提供数据支撑。
查询系统由Drill和ZooKeeper构成。Drill集群通过处理FastDFS所存的JSON文件,为平台提供实时查询服务,Zookeeper集群用于协调Drill集群的分布式查询任务。
经测试,较传统由关系数据库为核心的非分布式数据处理系统,存储性能提升近20%,查询性能提升近30%。
3 关键技术
3.1 族数据的存储
由于FastDFS为文件系统,对任何结构、非结构和半结构数据均以文件形式存储。而又如JSON等嵌套式数据模型可以自然地描述编程语言中使用的数据结构、分布式系统之间的交换消息和结构化文档等数据。所以对于族数据的存储,可在WebServer上通过Revit API解析.rft文件,提取族中包含的属性,并转化为JSON文件,存于FastDFS分布式文件系统。
用户可在WebServer中向Tracker Server申请文件存储服务,FastDFS存储文件的流程如图7所示。

图7 FastDFS存储文件流程
用户通过族数据平台的存储页面向FastDFS的WebServer发起存储请求,TrackerServer将可用StorageServer的IP及端口返回给用户,用户根据返回信息将待存储文件上传至StorageServer,最终,StorageServer返回文件ID,ID中包含文件的存储元数据。
FastDFS不同于HDFS等分布式文件系统,不会对文件进行分块存储,直接存储源文件,故FastDFS适合存储中小型文件,而且在文件名中保存元数据,不用另设置元数据的存储,简化了后期查询文件的过程。
FastDFS采取对等结构,可存在多台TrackerServer和StorageServer,且各自集群内部关系平等,从而实现存储的系统高可用性。FastDFS以分组方式组建其存储集群,集群由一个或多个分组组成,每个分组下包含一台或多台StorageServer。同一组内的StorageServer相互备份,所存文件完全一致,通过冗余备份实现文件数据的高可用性。
FastDFS支持在线扩容,存储集群的存储总容量为所有分组存储容量的线性和。当有新的StorageServer加入某一分组时,该StorageServer会在启动时,为已存在的每个TrackerServer建立一个线程用于通信。TrackerServer在接收到新StorageServer的心跳包时会更新自己分组的映射表,并将新表同步至该分组的每台StorageServer上。最后该组内一台存有全部文件的StorageServer会将全部文件备份至新进StorageServer。
当有新的分组加入时,新分组中的StorageServer会以在启动时向TrackerServer发送自己的信息。TrackerServer整理信息,建立该分组与其下StorageServer的映射表,并将该表返回给新分组中的每台StorageServer。
3.2 族数据的查询
Drill可通过存储插件连接各不相同的数据源[11](见图8),其支持的数据源除了有Hadoop家族中的HDFS、HBase和Hive外,还包括任意的分布式文件存储系统。Drill还可直接解析JSON文件。

图9 Drill任务生成流程
Drill集群中由Drillbit执行查询服务。Drillbit可部署于分布式系统中的任意节点上,且各Drillbit间无主从关系,每一个Drillbit均包含Drill的全部服务和功能,集群中的任意Drillbit都可接收来自用户的查询。[12]
当用户在WebServer发起SQL查询时,会从Zookeeper获取当前可用的Drillbit表,并从中选择一个Drillbit作为Foreman,负责接手初始查询。如图,Foreman会将SQL命令转化为逻辑计划(Logical Plan),其中包含一系列可被Drillbit识别的逻辑操作。之后,逻辑计划经优化器处理,转化为物理计划(Physical Plan),描述了查询任务的拆分情况,用于具体的分布式查询任务。
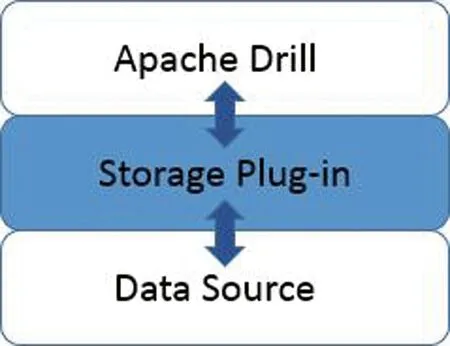
图8 Drill通过存储插件连接数据源

图10 Drill任务的分解
对于查询任务分解,Drill集群中的Foreman通过Zookeeper获得可用Drillbit表,并将物理计划中经拆分得到的子查询任务下发给各Drillbit,构建用于查询和回收结果的任务执行树(见图10),最终回传结果给用户。
4 小结
本文首先介绍了BIM的族数据和平台应用模块,随后分析了族数据的存储和查询需求,最后给出了BIM资源库下和族数据存储和查询平台的架构设计,并详细介绍了存储和查询的执行流程及原理。测试结果显示,较以关系数据库核心的非分布式数据处理系统,新平台的存储性能和查询性能为均有较大提升。
[1]王珺. BIM理念及BIM软件在建设项目中的应用研究[D]. 西南交通大学,2011.
[2]Revit 2016 help[EB/OL]. [2016-10-27]. http://help.autodesk.com/view/RVT/2016/ENU/
[3]Abiteboul, S. Querying semi-structured data. International Conference on Database Theory. Lecture Notes in Computer Science, 1997, 1186:1-18.
[4]李庆华,刘昊.用待确定的上下文无关文法分析半结构化数据[J].华中理工大学学报,1999,27(5):60- 62.
[5]维基百科上下无关文法[EB/OL]. [2016-10-27]. https://zh.wikipedia.org/wiki/%E4%B8%8A%E4%B8%8B%E6%96%87%E6%97%A0%E5%85%B3%E6%96%87%E6%B3%95
[6]余庆.分布式文件系统FastDFS架构剖析[J],程序员,2010,(11):63-65.
[7]Keepalived[EB/OL]. [2016-10-27]. http://www.keepalived.org/
[8]Configuring VRRP[EB/OL]. [2016-10-27]. http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
[9]Melnik, S., Gubarev, A., Long, J. J., Romer, G., Shivakumar, S., Tolton, M., &Vassilakis, T. Dremel: interactive analysis of web-scale datasets. Proceedings of the VLDB Endowment, 2010, 3(1-2): 330-339.
[10]A bulidngSMARTallianceTM Project, BIM Project Execution Planning Guide, 2010,Developed by Computer Integrated Construction Research Group, Department ofArchitectural Engineering,The Pennsylvania State University, retrieved fromhttp://bim.psu.edu/. 1-9.
[11]Drill Connect a Data Source Introduction[EB/OL]. [2016-10-27]. https://drill.apache.org/docs/connect-a-data-source-introduction/
[12]Apache Drill Architecture: The Ultimate Guide[EB/OL]. [2016-10-27]. https://www.mapr.com/blog/apache-drill-architecture-ultimate-guide/
Using FastDFs and Drill to Build BIM Family Platform for Storage and Query
Wang Baohui, Gao Yuan
(SoftwareCollegeofBeihangUniversity,Beijing100191,China)
BIM Family is semi-structured data.The data structure is relatively loose and variable,so it is difficult to bestored and queried usingtraditional relational database.Based on FastDFs and Drill,we build a distributed data processing platform tostoreandquery BIM family under BIM resource library.After testing,compared with the non-distributed system which it is core is the relational database,the platform performance is significantly improved.
BIM Family; BIM; FastDFS; Drill
国家科技支撑计划子课题“建筑行业设计服务共性技术集成平台研发与应用”(编号: 2014BAH25F03-04) 【作者简介】 王宝会(1973-),男,教授级高工,硕士,主要研究方向:软件架构; 邢景轩(1993-),男,硕士在读,主要研究方向:软件工程; 高 远(1992-),男,硕士在读,主要研究方向:软件工程。
TU17
A
1674-7461(2016)06-0023-06
