海冰与海洋平台碰撞分析中的可视化方法
2016-03-15王宇新张驰狄少丞季顺迎霍运理郭
王宇新 张驰 狄少丞 季顺迎 霍运理 郭禾


摘要:针对基于离散元方法的海冰与海洋平台结构碰撞分析系统,对运行于CPUGPU异构高性能计算平台上的大规模粒子模拟进行可视化方法的研究.使用OpenGL完成不同规模的平整冰、浮冰、冰脊和不规则形态海冰的呈现,不同形状海洋平台结构与受力网格的绘制,海冰粒子的运动轨迹与速度的表达,海浪效果的模拟以及碰撞过程的动画演示等.通过定义合理的交互模式与接口,在一定程度上融合GPU加速的离散元计算与后处理显示,基于多进程管道通信、多线程并行输出等实现在GPU加速计算的同时实时显示粒子模拟计算结果.该方法在帮助研究者随时掌握程序执行状况的同时,大幅减少后续传输、处理和存储的数据.
关键词:海冰; 海洋平台; 碰撞分析; 后处理; 离散元方法; 大规模粒子; 可视化
中图分类号: TB122, TP319 文献标志码:B
Abstract:The visualization method about massive particles simulation running on CPUGPU heterogeneous highperformance computing platform is studied, which is applied in an analysis system for the collision between sea ice and offshore platform based on discrete element method. By OpenGL, the different sizes of level ice, floating ice, ice ridge and ice of irregular forms can be presented; the different shapes of offshore platform structure and force mesh can be drawn; the movement path and speed of sea ice particles can be expressed; the motion of ocean waves can be simulated; the animation of collision process can be demonstrated, etc. By defining reasonable interaction patterns and interface, the discrete element calculation accelerated by GPU and the postprocessing display are merged in a certain extent. Based on multiprocess pipe communication, multithread parallel output, and so on, the realtime display of particle simulation results is implemented while GPU is calculating. By the method, the researchers can realize program execution status at any time and the subsequent transmission, processing and storage of data can be significantly reduced.
Key words:sea ice; offshore platform; collision analysis; postprocessing; discrete element method; massive particles; visualization
0 引 言
离散元方法是一种计算和分析大量颗粒在给定条件下的运动规律的数值计算方法,在工程应用中广泛使用,尤其在对滑坡、雪崩、泥石流和海冰等各类自然界现象的模拟中占据重要位置.[1]离散元计算规模往往很大,一般需要高性能计算平台的支持,同时会产生大规模科学数据集.科学可视化可以通过一系列复杂的算法将数据高精度、高分辨率地绘制出来,或者将先进的科学实验过程模拟呈现,帮助研究人员从这些庞大复杂的数据中快速、有效地获得有用的信息或直观的判断.[2]例如,颗粒可视化程序VMD使用OpenGL能够绘制70×106~300×106个高质量的三维分子颗粒.[3]TU等[4]在模拟地震过程中的地表运动时,通过计算程序和可视化程序的紧密耦合实现并行可视化.KRGER等[5]开发的粒子系统可以将三维流交互可视化.方晓健等[6]针对运行在CPU与GPU混合架构的HPC系统上的并行粒子模拟进行在线可视化研究,通过GPU加速的粒子模拟与并行可视化的紧密耦合,实现并行粒子模拟运行过程中的在线可视化.
本文针对海冰与海洋平台结构碰撞分析系统,对运行于单计算节点上的CPUGPU异构高性能计算平台上的大规模粒子模拟进行可视化方法研究.
1 海冰与海洋平台碰撞过程可视化
海冰能够对港口设施、海上交通运输和生产作业构成严重威胁,其危害主要来自于结冰时的附着和破冰时的撞击.以海上石油平台为例:在结冰时,海冰会附着在平台的桩腿上,导致平台受潮汐冲击的受力面增大,增加危险性;在破冰时,浮冰随海浪撞击平台(见图1),如果与平台自身的摇动形成共振,则很可能形成颠覆.[7]
在海冰与海洋平台结构碰撞分析系统中,通过大规模粒子模拟海冰,对每个粒子与海洋平台结构的碰撞过程进行力学分析获得运动轨迹并形象地显示出来,让研究人员直观地掌握海冰的运动情况,实时观测粒子模拟中发生的现象,对计算过程进行追踪和调整.在此过程中,海冰、海洋平台结构、海浪、粒子运动轨迹与碰撞过程的可视化至关重要.
1.1 海冰的模拟显示
海冰主要有平整冰、浮冰和冰脊等结构.基于离散元方法,海冰的不同结构可以通过若干个球形粒子作为基本单元排列而成.
平整冰是一块大小可设置的长方体冰块,用若干个排列紧密的粒子表达.平整冰可通过给定的参数生成每个粒子的坐标信息生成.参数包括冰块的长、宽、高,水的深度,冰块最右侧中心点距离原点的横纵距离,粒子的直径等.平整冰高度定义为冰的层数,即在平面某一点的垂直方向上粒子的个数.在生成粒子坐标时按照从下到上、从近到远、从右到左的顺序依次计算每个粒子的空间坐标.
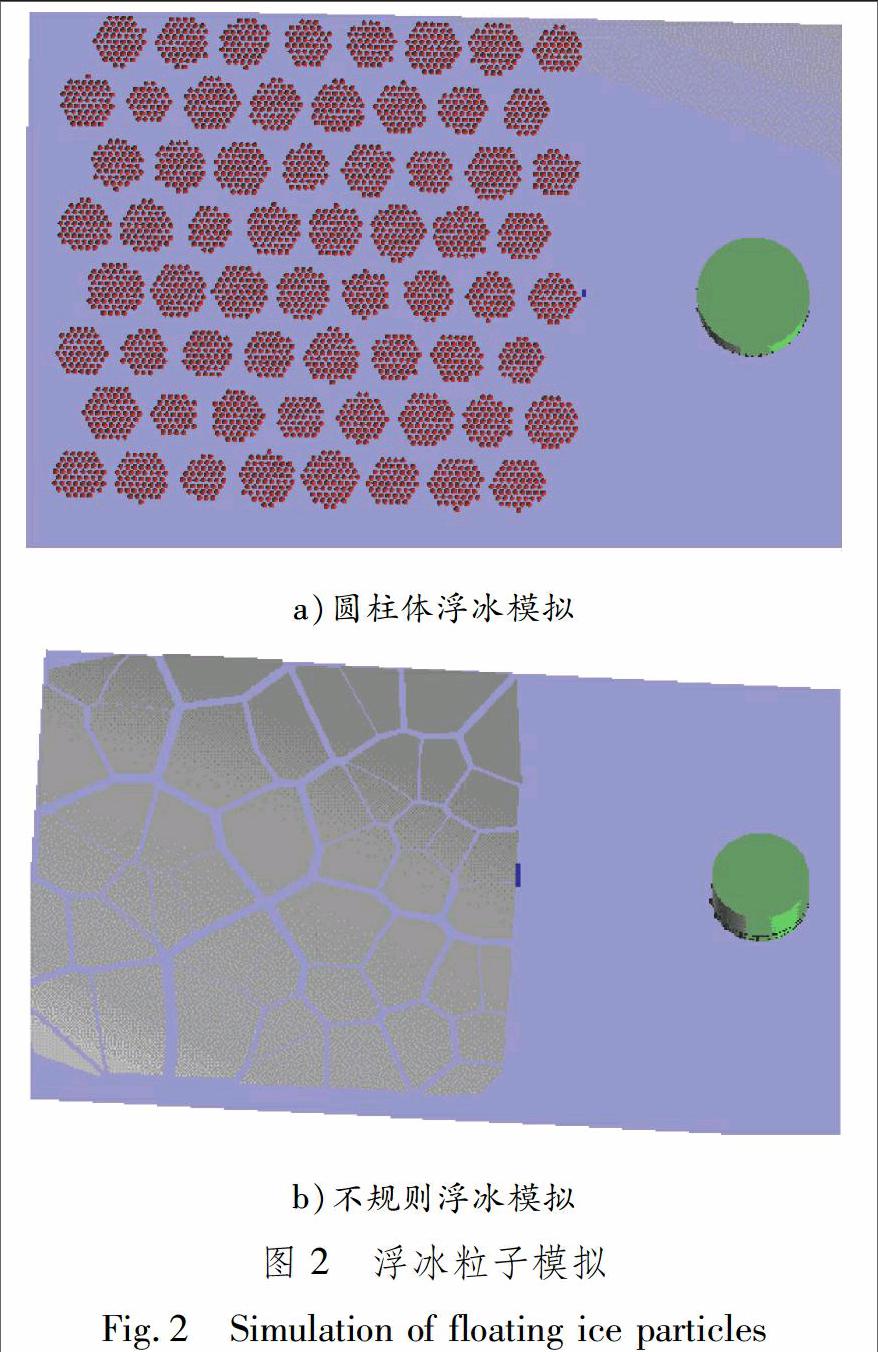
浮冰表现为不同密度散列的冰块,可用若干个单元的集合来表达,组成单元的形状可以为长方体、圆柱体和不规则的多边形柱体.浮冰的密集度即图形单元的密集程序,在视觉上表现为各个单元之间的距离远近.当单元形状为长方体和圆柱体时,浮冰的生成规则类似,以圆柱体为例(见图2a),首先根据平整冰生成规则得到组成冰块的所有粒子信息,然后根据密集度和冰块的长、宽生成平面坐标上每个圆柱体上下表面的圆心坐标.计算各几何中心与各粒子之间的距离,若小于给定的值,则保留并显示该粒子.
浮冰并不总是呈现规则形态,可以在给定区域内绘制多边形柱体的集合来表示不规则海冰.每个多边形柱体的俯视图都为凸多边形,各柱体之间根据预先设定的密度因数产生一定的间隔.生成规则采用Voronoi图的思想,由一组连接两邻点直线的垂直平分线组成的连续多边形组成.在海冰模拟实际应用时:首先在指定区域随机生成若干粒子坐标,然后分别将其按照Voronoi图的性质划分为若干区域集合,从而得到各区域的顶点坐标;再根据预先设定的密度因数缩放各区域的顶点坐标,可以得到不规则柱体的坐标集合.在实际绘制时,每个不规则柱体用若干个三棱柱拼接而成.构建一个图元函数,用来绘制最基本的三棱柱.在绘制时,根据已有的多边形的顶点坐标拆分成若干个三角形坐标,分别调用绘制三棱柱图元的函数,得到不规则柱体的集合,效果见图2b.
冰脊是冰在外力作用下形成的一排山脊状冰,在模拟时用不同厚度的长方体与四棱台拼接而成,见图3a.其中,四棱台的模拟相对复杂,采用拼凑平整冰的方法实现,即将四棱台用若干个长度相等、宽度渐变的平整冰一层层堆叠而成.因此,在定义四棱台下底面的宽度后,根据所给的底面与侧面的夹角,计算上一层平整冰的宽度,以此类推,直到达到所定义的棱台的高度.
当海冰的尺寸较大时,模拟海冰所需的粒子数量增多,计算机在显示时要花费大量的时间完成粒子球体到显示像素的转换,造成显示的迟钝,不利于观察,尤其是在转换角度、平移、缩放视图时需要对整个视图进行重绘,图像延迟现象尤为明显.考虑到在海冰尺寸较大时对局部细节的观察需求较为次要,采用直接绘制几何图形的方法模拟海冰.设定一个阈值,当表达结构所需的粒子个数超过这个阈值时则不再使用粒子拼接图形,而采用直接绘制几何图形的方式.平整冰用一个大的长方体表示;方形排列浮冰用若干个小长方体表示,圆形排列浮冰用若干个小圆柱表示;冰脊分为上中下3部分,上下部分用几何面围成封闭的台状图形,中间部分绘制成长方体,见图3b.
1.2 海洋平台结构的模拟显示
在对海洋平台结构模拟时,因为海冰与海洋平台的碰撞点在平台结构的桩腿上,所以主要考虑对桩腿的模拟.海洋平台结构桩腿可分为2种结构:圆柱体和圆锥组合体.圆柱体结构表现为一个单一的几何体,见图4a,可以定义半径、高度等物理属性和位置属性.OpenGL没有直接绘制圆柱体的方法,所以通过绘制2个圆盘和1个曲面来构成一个圆柱体.圆锥组合体结构见图4b,表达为圆柱体和圆台的组合体,整个结构体通过绘制2个圆盘即上下圆柱体面和4个曲面组成.
在海冰粒子与平台结构发生碰撞时,希望能够观测到海冰粒子相对于结构的位移情况,需要在其上绘制一些局部力网格,包括垂直方向的直线和水平方向的曲线.在实际绘制时不能在面上直接绘制直线或曲线,而是在结构半径基础上向外延伸一定距离绘制一个有一定宽度的线条,这样不会产生覆盖.
1.3 碰撞过程的效果和动画视频
粒子是模拟海冰的基本元素,粒子的属性需要参与之后的GPU计算,因此需要将前处理中对粒子物理属性的要求写入固定接口格式的文件后由GPU程序读取.每次当粒子属性发生变化时只需在前处理程序中做出相应修改,这对于GPU计算程序是透明的.在GPU计算程序计算粒子的运动轨迹时,粒子的速度十分重要,与粒子坐标一起保存.显示程序在显示粒子轨迹时同时获取粒子的速度,按照定义可根据速度不同显示出不同颜色(见图5a)有利于更准确地表达海冰在运动过程中各个区域的受力和速度情况.海冰是在海浪的作用下运动的,海浪是海冰模拟中的重要组成部分,虽然不参与计算,但却能更好地对海冰的运动进行显示.海浪在视觉上表现为一个不断起伏的曲面,在用计算机模拟波浪效果时,将海浪划分为若干个由1个水平方向的长方形和2个垂直方向的长方形组成的小单元,每个单元属性包括波高、水面宽度、单位宽度等.若干个单元紧密排列在一起,相邻单元之间通过一定的高度差实现曲面的模拟.每个单元组的高度根据时间的推移不断变化实现波浪的效果,见图5b.在连续不断地对数据读入并可视化时,可以观察到较为流畅的动画效果.在显示程序运行的过程中,可以通过连续不断地对显示界面进行固定间隔的截图,将图片连续保存后处理成视频文件,方便研究人员的再观察,见图5c.
2 计算过程中的实时显示和优化
传统的离散元模拟程序一般由主计算程序在粒子模拟计算后输出每一步粒子的坐标和速度等信息并写入文件中,然后由后处理显示程序读取粒子信息文件,并显示粒子的运动轨迹.[8]这种做法的问题在于必须等到计算程序完成所有粒子所有步数的计算之后才能读取计算结果,观察到粒子的运动轨迹.我们的目标是在GPU计算的同时在屏幕上绘制出当前粒子的位置信息,实时显示已计算出的粒子的运动轨迹.这样边计算边显示可以实时掌握计算程序的执行状况,以便在出现问题时随时做出相应改变,而不必等到整个程序的结束,以节约时间和资源.根据GPU卡的工作方式,实现GPU计算程序与显示程序的实时交互方法有利用共享数据缓冲区和利用命名管道2种.
2.1 利用共享数据缓冲区实现
当GPU计算程序和基于OpenGL的显示程序都是由GPU执行时,OpenGl的缓冲区可以映射到GPU计算程序的地址空间,被当做全局缓存访问,因此可以采用共享数据缓冲区的方式使2个程序进行实时交互,以减少数据的传输.[9]
数据缓冲区有像素缓冲区(Pixel Buffer Object, PBO)和顶点缓冲区(Vertex Buffer Ojbect, VBO)2种.前者存储的是像素数据,后者存储的是顶点数据.[10]VBO可以存储顶点坐标、索引数据、顶点法线和顶点颜色等数据,适用于多面体结构的离散元颗粒,如大尺寸海冰的绘制等.VBO使用的完整过程如下.
1)创建并激活VBO缓冲区,将缓冲区句柄绑定到缓冲区对象,并申请存储空间来存储数据.本系统中的大尺寸海冰由多个三角形面拼接而成,会有多个顶点重复使用的情况,为节省存储空间和优化显示程序,需要顶点坐标数组和索引数据数组这2块缓冲区
2)注册2块VBO缓冲区到CUDA,并将其映射到CUDA的地址空间,这样CUDA计算程序才能访问VBO缓冲区.GPU计算程序执行CUDA核函数时计算出需要显示的顶点数据和索引数据,将数据写入到VBO中后解除CUDA对VBO的映射.
3)显示程序可以访问VBO顶点数据进行OpenGL渲染绘制.绘制首先要指定相对于缓冲区起始位置的偏移量,对诸如glVertexPointer()这样的顶点数组函数进行初始化;然后启用顶点数组;最后根据索引数据数组中给出的索引,查找到相应的顶点进行绘制.
使用VBO能够优化计算和显示程序的交互过程,提高实时显示效率.
2.2 利用命名管道实现
随着GPU计算成为大规模科学计算的主流方式,很多专用于计算而不能显示(没有显示器接口)的GPU卡出现,如目前常见的NVIDIA Tesla K40 GPU卡,因此利用共享的GPU数据缓冲区进行实时显示不可行.同时,由于CPU上多进程间无法进行大数据量的内存数据交互,因此将设计目标调整为在GPU计算程序完成一定步数的计算后通知显示程序读取已有的硬盘文件数据,即采用命名管道实现GPU计算程序与显示程序的通信.
命名管道是一种经典的进程间通信机制,可以在同一台计算机的不同进程之间或在跨越一个网络的不同计算机的不同进程之间进行可靠的、单向或双向的数据通信.[11]本文系统中采用命名管道实现计算进程和显示进程的交互,在显示进程中创建命名管道服务器端,在计算进程中创建命名管道客户端,连接到服务器端进行交互通信.GPU端计算程序完成每一步的计算并由CPU端将当前的粒子信息输出后,通过命名管道通知显示进程有新数据到达,显示进程接收到通知后到指定位置读取粒子信息并显示.具体交互模式见图6.
2.3 CPU端多线程并行输出数据文件
离散元模拟计算的规模往往很大,每一步都要计算几十万甚至上百万的粒子,即使计算能力很卓越的GPU也需要一段时间才能完成一步的计算,而这期间CPU端是空闲的,因此可以利用这段时间让CPU写文件输出上一步粒子计算的结果,与GPU端的大规模计算并行执行.具体实现过程为:GPU端程序完成一步计算后,将数据通过PCIE接口传回CPU端主线程,后者使用CreateThread创建专用的输出线程,并以获得的记录粒子信息的数组为参数调用输出线程函数,然后立即返回控制GPU下一步的计算.在此过程中CPU端创建的输出线程写入硬盘文件输出粒子信息与GPU端计算下一步的粒子信息并行进行.
实验在CPU Intel Core i7 Extreme 990X,GPU NVIDA Tesla C2050,12GB DDR3内存的硬件环境下进行,分别实现17万、40万、70万和130万粒子计算5 000和10 000步的运行效果,时间对比见图7.
从实验结果中可以看出,GPU计算结合CPU并行输出可以节约大约25%~30%的时间,显著提高程序的运行效率.在计算程序CPU端写入大规模数据到硬盘、显示程序读取硬盘大规模数据进行显示的过程中,很大一部分时间消耗在硬盘I/O上,由于硬盘的读写速度比内存读写慢很多,因此可以使用RAMDISK技术将一部分内存划分出来虚拟为硬盘,用来保存大
规模数据.通过这种方式,可以明显提高实时显示图像的流畅度.采用固态硬盘也有同样的效果.
3 碰撞分析系统的实现
海冰与海洋平台结构碰撞分析系统采用Visio Studio 2010开发平台,VC++语言,OpenGL编程接口库和NVIDIA CUDA 5.0编程平台等开发实现.软件划分为前处理、计算和后处理3个基本模块,界面见图8.
前处理模块中的预览功能,可以在GPU计算程序开始前观察给定参数的海冰结构和碰撞障碍物结构以及两者之间的方位信息,为进一步的科学计算提供相对准确的位置判断和事实依据,以更高效地完成海冰运动轨迹的计算,避免无效计算导致资源浪费.前处理模块分为3个子模块:在海冰属性定义子模块中,完成对海冰块体的定义,包括海冰的结构,冰块的尺寸、层数、温度、盐度和初始速度等物理属性,冰块的边界属性,以及海水的密度、深度等;在海洋平台结构属性定义模块完成结构的属性定义,包括结构体的形状、个数以及与海冰的相对位置等;
后处理显示程序与计算程序有一定程度的融合,通过合理的交互模式与接口,在计算的同时实时地呈现出GPU加速的粒子模拟计算结果.同时,后处理模块还能够呈现平台结构在与海冰发生碰撞时的受力情况,包括横向、纵向和垂直3个方向的力随着时间推移的变化情况,见图9.
4 结束语
本文介绍一套海冰碰撞模拟可视化系统的设计思想与实现技术.在对各种参数进行预先定义,并利用离散元模拟海冰的运动轨迹及与海洋平台结构的碰撞过程进行GPU高性能计算的基础上,使用OpenGL编程接口和各种加速优化技术对整个过程进行模拟实时显示,使得对海冰的建模过程更加方便、直观,模型参数更加精确,保证计算过程的准确性和合理性,提高研究人员的工作效率,改善用户体验.
参考文献:
[1]季顺迎, 岳前进. 工程海冰数值模型及应用[M]. 北京: 北京科学出版社, 2011: 12.
[2]俞宏峰. 大规模科学数据可视化[J]. 中国计算机学会通讯, 2012, 8(9): 2936.
YU Hongfeng. Visualization of large scale scientific data[J]. Communication of the CCCF, 2012, 8(9): 2936.
[3]ROBERTS E, STONE J E, LUTHEYSCHULTEN Z. Lattice microbes: Highperformance stochastic simulation method for the reactiondiffusion master equation[J]. Computational Chemistry, 2013, 34(3): 245255
[4]TU T, YU H, RAMIREZGUZMAN L, et al. From mesh generation to scientific visualization: an endtoend approach to parallel supercomputing[EB/OL]. (20150301)[20061231]. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.650.9262.
[5]KRGER J, KIPFER P, KONCLRATIEVA P, et al. A particle system for interactive visualization of 3D flows[J]. IEEE Transactions on Visualization and Computer Graphics, 2005, 11(6): 744756.
[6]方晓健, 徐骥, 戚华彪, 等. GPU 加速的并行粒子模拟在线可视化[J]. 计算机与应用化学, 2011, 28(10): 12341239.
FANG Xiaojian, XU Ji, QI Huabiao, et al. Insitu visualization for GPUaccelerated parallel particle simulation[J]. Computers and Applied Chemistry, 2011, 28(10): 12341239.
[7]狄少丞, 季顺迎. 海冰与自升式海洋平台相互作用GPU 离散元模拟[J]. 力学学报, 2014, 46(4): 561571. .
DI Shaocheng, JI Shunying. GPUBased discrete element simulation of interaction between sea ice and jackup platform structure[J]. Chinese Journal of Theoretical and Applied Mechanics, 2014, 46(4): 561571.
[8]郑文刚, 刘凯欣. 离散元法工程计算软件的前后处理系统[J]. 计算机工程与科学, 2000, 22(6): 1416.
ZHENG Wengang, LIU Kaixin. A preprocessing and postprocessing system for an engineering computation software of discrete element method[J]. Computer Engineering & Science, 2000, 22(6): 1416.
[9]DEMIR V, ELSHERBENI A Z. Utilization of CUDAOpenGL interoperability to display electromagnetic fields calculated by FDTD[EB/OL]. (20150301)[20111013]. http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6047338.
[10]刘进锋, 郭雷. CUDA和OpenGL互操作的实现及分析[J]. 微型机与应用, 2011(23): 4042.
LIU Jinfeng, GUO Lei. Realization and analysis of CUDA and OpenGL interoperation[J]. Micro computer & its Applications, 2011(23): 4042.
[11]JONES A, OHLUND J. Windows网络编程技术[M]. 京京工作室, 译. 北京: 机械工业出版社, 2000: 66.
(编辑 武晓英)
