基于相似度匹配的反抄袭算法的研究
2016-03-09李冬艳方若晨吴国玺
李冬艳,方若晨 ,许 凯,唐 菱,吴国玺
(1.华北科技学院 计算机学院,北京 东燕郊 101601);2.北京航空航天大学 软件学院,北京 100191)
基于相似度匹配的反抄袭算法的研究
李冬艳1,方若晨2,许 凯1,唐 菱1,吴国玺1
(1.华北科技学院 计算机学院,北京 东燕郊 101601);2.北京航空航天大学 软件学院,北京 100191)
论文抄袭一直是学术领域重点关注和研究的问题。为了有效的检测出抄袭的情况,本文结合模式匹配算法研究设计了论文抄袭检测方法。提出采用模式匹配中的基于字符串匹配的相似度算法,通过添加、删除、替换等操作还原文档,并计算文档间的相似距离,根据相似距离获得文档相似度,从而判断文档的抄袭比例。反抄袭算法的研究实现为遏制进一步恶化的抄袭现象,净化学术风气提供了有效的监控技术。
反抄袭;模式匹配;相似度
0 引言
计算机网络技术的不断进步使得互联网成为人们获取各方面信息的主要渠道,但由于网上资源的丰富多彩与管理的不到位等原因,也带来了一系列问题。在学术界最为严重的就是利用网络资源进行抄袭和剽窃。为了达到个人目的,很多人利用网络资源可以轻松完成一篇论文。抄袭现象的泛滥己经严重破坏了社会学术风气,破坏了知识产权。如果单单依靠法律法规和道德规范去约束这种行为,并不能发挥很好的效果。但是依靠人力审阅文章是否抄袭,这样的工作除了费时费力,还受到审阅者知识范围的限制,所以未必能准确判定出是否属于抄袭行为。
综上所述,为了更好的预防抄袭这种不良现象,规范学术不端的抄袭行为[1],提出一种检测速度快、效果好的算法并能用计算机相关语言编程实现,有很重要的意义。
1 反抄袭检测技术的研究
从20世纪90年代起反抄袭技术就已经开始研究,各种反抄袭检测工具不断涌现出来。2003年,Schleimer等提出了基于数字指纹Winnowing算法来精确识别文档复制问题,并应用于抄袭识别在线服务网站MOSS上[9]。目前,作为国外最大的反抄袭检测网站Turnitin,不仅可以实现网页检索(其网页资源覆盖量大约45亿),还可以与系统本身数据库的电子资源进行匹配检索。国外防抄袭技术的日渐成熟,对抄袭现象的蔓延起了很好的遏制作用。国内学术机构逐渐认识到反抄袭检测技术的重要性,先后研制出不同的检测系统,例如由清华大学和中国知网共同推出的“学术不端文献检测系统”不仅能够对不同类型的文档进行检测,还支持词语、句子到段落的数字指纹定义。
无论国外还是国内的反抄袭检测技术,由于中文字符和英文字符的差异性,一些国外现成的研究成果不能被我国直接利用。而国内的检测系统也会由于字符编码格式的不同,在中英文混合的文档中,导致检测的准确率降低,所以研究一种合理有效的反抄袭检测算法至关重要[2]。
从对现有的反抄袭检测技术的分析来看,其实现的技术原理主要围绕在文档信息的预处理、抄袭检测算法的实现、文本状态跳转的方法和相似度的计算等方面的设计上,利用字符串比对技术和人工智能技术,对连续的大段中文电子文档进行关键词句比较,得出对比文档的相似度。
对文档信息预处理的设计直接影响着后期抄袭检测的执行效率,因此文档信息预处理的设计也是本课题的研究问题之一,文档信息预处理的手段是多种多样的,例如以句子为单位提取信息并计算句子散列值后执行抄袭检测操作[3]。
目前检测技术用的主要算法有字符串匹配技术、基于统计的中文分词技术以及句子相似度等[5]。鉴于对现有的反抄袭检测技术的研究,本文提出的基于相似度匹配的检测技术,是以字符块(300-400个字符)作为信息提取单位,以句子作为分割单位,中文字符串采用中文分词技术划分词组集合,英文字符以空格作为单词分界标准,将划分好的文本提交到抄袭检测系统中,再通过相似度匹配算法进行检测,计算出重复率或相似度。
2 模式匹配技术
模式匹配技术在信息检索领域用的比较多,抄袭检测算法的实现也是依托基于模式匹配技术的原理进行设计的[4]。根据匹配过程中所要匹配模式串的个数,模式匹配算法分为单模式匹配算法和多模式匹配算法。下面对常用的2种模式匹配算法进行分别介绍。
2.1 单模式匹配算法
单模式匹配算法是指在一个长度为m的字符串T中找出与长度为n(n<=m)的字符串Y相匹配的子串,如果找到就返回与Y相匹配的子字符串的位置,如果没有就返回空。
KMP算法是由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此简称KMP算法。KMP算法是一种改进的常用单模式字符串匹配算法,对于任何模式和目标序列,都可以在线性时间内完成匹配查找,而不会发生退化,是一个非常优秀的模式匹配算法。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。模式串next()函数定义公式如下:
其主要思想是:在文本串和模式串匹配过程中,假如当前字符匹配失败时,文本串的指针不需要回溯,而是根据匹配的结果将模式串尽可能的向右“滑动”,然后继续进行比较直到匹配成功或者文本串后面的长度小于模式串后面的长度。假设文本串T= t1t2… tn与模式串Y=Y1Y2…Ym,当文本串T中第i个字符与模式串Y中第j个字符匹配失败时,那我们可知模式串Y在位置j之前的字符串Y1Y2...Yj-1,与文本串T的字符串titi+l…ti+j-1的匹配是成功的,即"Y1Y2...Yj-1"="titi十1...ti+j-1"=u,文本在第j个字符匹配失败,也就是T[i+j]不等于Y[j]。这时,KMP算法就可以利用己经匹配成功的字符串信息u来计算文本的跳转状态。
KMP算法状态跳转的计算方法为:当首字符匹配失败时,文本串向后移动一位继续匹配;当第j个字符匹配失败后,在模式串Y中己经匹配成功的前j-1个字符中查找是否存在最大前缀与后缀相等的字符串,并且最大前缀的下一个字符不为Y串。如果存在求出最大前缀的位置k。
KMP算法是改进得来的,添加了字符状态跳转功能,减少了不需要的匹配次数,大大提高了匹配效率,使匹配算法在速度上有了一个大的突破[6]。KMP算法解决了字符匹配回溯问题,为下面的抄袭检测算法在跳转方面的设计提供了理论依据。
2.2 多模式匹配算法
多模式匹配算法是指将模式串集合P={{{Pl,P2 } P3 } ...Pn}分别与文本串T相匹配并找出各个待匹配模式串在文本串中的位置。与单模式匹配算法不同,多模式匹配算法可以同时匹配多个模式串,具有较高的性能和检测效率[8]。下面介绍一种典型的多模式匹配算法。
AC(Aho-Corsick)算法
AC算法的核心思想是构造词典的自动机(可以使用trie树来实现), 其算法复杂度是O(m+k+z),m是文本长度,k是所有pattern长度之和,z是字符串中出现pattern的个数。
举个例子来说:Pattern P={he; she; his; hers} ,建立如下图的AC算法字典树:
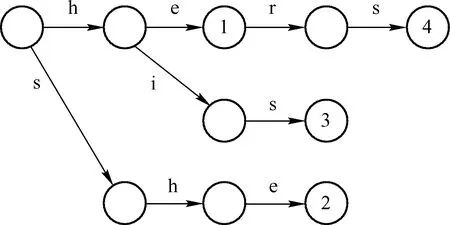
图1 AC算法字典树
其中node中有数字的表示在词典(Pattern)中,每一条边表示一个字符,同一个节点指出的不同边拥有不同的字符标签。一旦字典树构建结束,查找过程跟我们平时用查字典的过程是一样的,从根节点一步步向下查,直到找到该词或者没有之结点为止。但是,会发现其复杂度是O(m×k),此时就需要建立一个自动机:
自动机由状态(states)和行动(action)组成,在本例中,
State:字典树的节点,初始状态为0
Action:action由3个函数决定:
(1) goto函数 g(q,a),它表示:如果当前状态是q,输入字符是a,那么下一个状态是g(q,a);如果边edge(q,r)标记为a,那么 g(q,a)= r;
(2) failure函数 f(q),当q不为0的状态,failure函数表示在状态q失配,f(q)是状态机中的一个节点,标记为Pattern中某个Pattern恰当的最长后缀(如下图2的he)。
(3) out函数 out(q), 状态q,识别出某个pattern。

图2 自动机
图中的虚线就是表示failure函数的action,比如从5到2的action。如果字符串为sher,搜索到s-h-e,下一个串是r,failure函数可以使得字典树的搜索从5,跳到2,({he}是{ she}的后缀),然后迅速的找到her。 可以看到整个过程中,匹配过程直接按照自动机的顺序匹配,根本不需要回溯字符串(比如sher的例子,一旦she找到,直接从e的下一个字符r开始匹配,而不是从s的下一个字符h开始),此算法匹配的复杂度是o(m+z),z是pattern在字符串中出现的次数。
3 字符串的相似度匹配算法
由于抄袭者不断变换抄袭手段,通过替换、删除、修改非关键字而逃避检测,仅靠前面论述的模式匹配算法还很难准确检测出被改动或移动的文档。因此本文要利用基于字符串的相似度匹配算法计算出文档的相似度
基于字符串的相似度匹配算法的思想,就是通过添加、删除、替换的操作来还原抄袭文档的改动地方并统计文档之间的相似距离,然后再根据相似度算法计算文档相似度。
文本相似度算法是模式匹配算法中特殊的一类,是计算字符串之间相似程度的一种度量方法。文本相似度的计算方法主要有:基于字符串串匹配的相似度方法、基于集合模型的相似度方法、基于空间向量模型的相似度方法等。下面重点介绍基于字符串匹配的相似度算法以及实现。
基于字符串的相似度算法与文本的抄袭检测算法匹配结构的算法思路一致,通过统计两个字符串匹配相同字符个数,相同数目越多,字符串的相似度越高。
编辑距离也称为Levenshtein距离算法[7],指的是两个字符串之间,由一个通过插入、删除、替换等操作转换成另一个所需的最少编辑操作次数。编辑距离越大表示相似度越低。设文本串T和模式串S ,Ti和Sj分别表示文本串T中的第i个字符和模式串S中的第j个字符,edit(i,j)表示文本串T前i个字符与模式串S前j个字符的转化为相同字符所需的最少的操作步数。初始值edit(0,0)=0,则Levenshtein距离的计算公式为:
如果i=0且j=0 edit(0,0)=1;
如果i=0且j>0 edit(0,j)=edit(0,j-1)+1;
如果i>0且j=0 edit(i,0)=edit(i-1,0)+1;
如果i>0且j>0 edit(i,j)=min(edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i ,j))。
算法实现如下:
int d[][]; //矩阵
int n=str1.length();
int m=str2.length();
int j;//遍历str2的标记
char ch1;//str1的变量
char ch2; //str2的变量
int temp; //记录相同字符,在某个矩阵位置值的增量,不是0就是1
if (n == 0)
{
return m;
}
1)精准——就是精准定位店铺消费人群,不要再想着靠一家店铺一网打尽18~58岁的消费者了,笔者建议店铺以30岁为区分线,店铺品牌结构要不只服务30岁以上的消费者,以进口品、高端品为主;店铺品牌结构要不就只服务30岁以下的消费者,以国产品、潮流品为主;笔者认为近年来诞生于浙江、江苏、山东、河南、安徽等地的一些只销售进口品的连锁店家就是这种思维的产物;根据笔者这两年走访市场的经验可得,县城和乡镇市场额CS渠道70/80后 消费者销售额占比至少在70%以上,县城和乡镇市场的CS社区店基本上就不要考虑年轻人的生意,因为在手机和互联网培养下的年轻人,基本上都是通过网购来购物,去社区店购物的概率不大。
if (m == 0)
{
return n;
}
d=newint[n+1][m+1];
for (i=0; i <= n; i++)
{//初始化第一列
d[i][0]=i;
}
for (j=0; j <= m; j++)
{ //初始化第一行
d[0][j]=j;
}
int t=1;
for (i=1; i <= n; i++) { //遍历str1
ch1=str1.charAt(i - 1);
//去匹配str2
for (j=1; j <= m; j++)
{
ch2=str2.charAt(j - 1);
if (ch1 == ch2)
{
temp=0;
//System.out.println(t++);
} else
{ temp=1;
} //左边+1,上边+1,左上角+temp取最小
d[i][j]=min(d[i - 1][j]+1,d[i][j - 1]+1,d[i - 1][j - 1]+temp);
}
}
return d[n][m];
4 文档相似度的算法
模式匹配算法确定后就要确定整篇文档的相似度算法,通过实验验证算法的准确性。计算相似度,要先进行文档筛选,分别选取出文档库中和待检测的文档,并将其相关信息与用户填写的文档信息,采用编辑距离算法分别对题目(Topic,Topic1)、关键字(Keyword,Keyword1)、作者(Author,Author1)等加权方式计算相似度。设定文档相似阀值,关键字和题目分别是占了0.45的比重,作者占了0.1的比重。筛选出可能相似的文档。Simdu为相似度,sim()为计算相似度的方法。算法公式为:simdu=xsi.sim(Keyword,Keyword1)*0.45+xsi.sim(Topic,Topic1)*0.45+xsi.sim(Author,Author1)*0.1;
把提取的有可能抄袭的文章进行分段,再把每一段分成几个块,每块300个字符,然后分别用编辑距离算法计算每个模块的相似度,取最大的相似度,然后通过每块的相似度计算出整篇文章的相似度。具体算法如下:
if(simdu>=0.3) //文章关键信息相似度大于0.3执行操作
{
for(int i=0;i doc.fenju(doc.doc[i],i); for(int i=0;i doc1.fenju(doc1.doc[i],i); for(int i=0;i { for(int j=0;j { for(int i1=0;i1 { for(int j1=0;j1 { sima=xiangsi.sim(doc1.ju[j][j1],doc.ju[i][i1]); if(sima>=sima1) sima1=sima; //每一句话的最大相似度 } sima2=sima2+sima1; sima=0; sima1=0; } sima3=sima2/doc.jucount[i]; //整一段的相似度 sima2=0; if(sima3>sima4) { sima4=sima3; } } sima5=sima5+sima4; sima3=0; sima4=0; } sima5=sima5/(doc.doccount);整篇文档的相似度 } } 反抄袭检测算法以块为单位分解成数个字符串组进行匹配,在匹配过程中采用基于字符串的编辑距离算法统计字符串的相似距离并计算每个字符块相似度,最后得出整篇文档的相似度。此算法已经通过实验进行了验证,实验部分不在此文中论述。 通过对目前常用反抄袭检测技术的研究,阐述了几种模式匹配算法的结构、实现原理以及技术特点,重点论述了字符串基于相似度匹配模式的算法及文档相似度的计算方法,为后期实现反抄袭检测系统打下良好基础。 [1] 何方永.高校学士学位论文抄袭的原因与反思[J].教育与教学研究.2011(11):68-70. [2] 田俊峰,黄建才,杜瑞忠,等.高效的模式匹配算法研究[J].通信学报,2004,25(1):61-69. [3] 张国平,徐汶东.字符串模式匹配算法改进[J].计算机工程与设计,2007,28(20):4881-4884. [4] 李建军.反抄袭软件的局限及学术打假之策[J].编辑之友.2010(6):87-88. [5] 郝炜.具有抄袭检测功能的在线作业系统的研究与实现[D].沈阳:东北大学,2006. [6] 熊浩,晏海华,郭涛,等.代码相似性检测技术:研究综述[J].计算机科学.2010(08):9-14. [7] 胡明晓,DING Leon X.一种用于抄袭识别的文档距离度量[J].计算机工程与应用,2010(07):148-152. [8] 赵长海,晏海华,金茂忠.基于编译优化和反汇编的程序相似性检测方法[J].北京航空航天大学学报,2008(06):711-715. [9] 宋擒豹,杨向荣,等.数字商品非法复制的检测算法[J].计算机学报,2002,25(11):1206-1211. Research on anti-plagiarism algorithm based on similarity matching LI Dong-yan1,FANG Ruo-chen2,XU Kai1,TANG Ling1,WU Guo-xi1 (1.NorthChinaInstituteofScienceandTechnology,Yanjiao,101601,China;2.SchoolofSoftware,BeihangUniversity,Beijing,100191,China) Plagiarism has been a focus in the academic and research issues.In order to detect plagiarism effectively,this paper studies the method of plagiarism detection based on pattern matching algorithm.In order to determine the proportion of plagiarism,the similarity algorithm based on string matching was introduced.Algorithm using add,delete,replace,and other operations to restore the document,and calculate the similarity between the documents.Then,document similarity is calculated according to the similarity distance.The research and implementation of anti-plagiarism algorithm provides an effective monitoring technology to curb the further deterioration of plagiarism. anti-plagiarism; pattern matching; similarity 2016-08-23 中央高校基本科研业务费资助(3142011040) 李冬艳(1967-),女,吉林榆树人,硕士,华北科技学院计算机学院副教授,研究方向:网络应用。E-mail:674460377@qq.com TP181 A 1672-7169(2016)05-0060-055 结论
