数据挖掘在学生专业成绩预测上的应用
2016-03-08崔仁桀
崔仁桀


摘要:学生特征的提取以及学习效果预测一直是教育数据挖掘领域的热门课题。本文将结合国内高校教育现状和现有的教育数据挖掘成果,以weka作为实验平台,应用C4.5算法对本科生的专业培养数据做建模分析以及成绩预测,通过采集到的实际数据做实验验证,找到潜在于成绩信息之中的学生行为规律,为提前干预学生学习行为,优化教育决策做出有意义的指引。
关键词:计算机应用;数据挖掘;weka;学生成绩预测
中图分类号:TP391
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2016.01.007
0 引言
教育数据挖掘领域从2009年兴起至今已经得到了飞速的发展。EDM社区对教育数据挖掘做了如下定义:教育数据挖掘是一个新兴学科,致力于探索特定(来自于教育环境)数据的先进方法,并使用这些方法来更好的了解学生,并将其应用到他们的学习环境中。在高校的校园信息化建设已经日臻成熟的大趋势下,高校教务信息管理系统里积存了大量教务数据,教育数据挖掘领域根植的环境已经具备,本文将以此为背景,利用课程成绩对学生的专业学习行为进行建模,并对其未来的学习成果做出预测。研究过程中将基于weka实验平台,应用经典的C4.5决策树算法作为模型建立方法展开研究和实验。
本文的组织结构如下。第一章阐述研究主题内容的定义和算法原理简述;第二章从数据预处理,算法应用和模型评估三个方面来分析机器学习方案的创建过程;第三章以实际数据为例执行建模实验,分析和讨论实验结果,得出实验结论。第四章对全文的研究作总结,并对未来的研究做出展望。
1 研究背景与算法简述
1.1 研究背景讨论
关于学生表现的预测,有很多专家和学者做出了尝试和贡献。M.Vranic,D.Pintar and Z.Skocir通过应用聚类、关联分析和探索性数据分析等多重手段,分析了如何用本科生的生源情况,高考成绩,以及大一的重点课程“电子工程基础”的课堂表现情况预测出学生在这门课程的最终表现;Judith Zimmermann等学者从苏黎世联邦理工大学的一个专门制定的研究生推免计划中获得学生本科生和研究生成绩信息,以GGPA代表学生研究生的评定等级,应用多种预测和统计手段进行基于模型的成绩预测研究,分析如何用本科成绩单上得到的数据来预测GGPA,来推断其在研究生期间的表现。
然而对于这些跨越了学历阶段之间的预测分析并不适用于国内的教育体制,两个问题:1.首先以GGPA评定整个学历的学习行为未免过于粗糙,我们难以察觉出学生的具体特征;2.对于特定课程的预测需要用与之相关的解释变量做模型训练才更有意义,然而如果学习阶段相差过大,学习内容和环境都有很大差别,这样极大弱化了自变量和目的变量之间的相关性,使得预测结果的说服力大大降低。
为了克服这两点矛盾因素,我们将预测素材和预测目标都锁定在本科教育阶段。图1列出了目前主流的计算机科学与技术专业的培养课程体系的主要内容。方案的主要思想是将重要的基础课程放在大一大二两个学年,将较为高阶和关键的专业课放在大三学年,大四学年供学生根据自己意愿自由选择更偏向于社会应用课程以及毕业设计。以此为指导,我们选用课程体系中的学科基础课,专业基础课作为解释变量,来预测与之相关的高阶专业课的学习成绩,以达到加深对于学生学习行为的理解,和提前对学生学习进行干预,帮助其更好的完成专业培养的目的。
1.2 C4.5决策树算法原理简述
决策树是一种预测模型,它以决策节点、分支和叶节点的构造形式表示,将实例通过属性值逐步判别为某个类别标签上。我们需要用训练数据集来做决策树模型训练,然后将得到的树形结构进行保存并应用到测试数据和实际数据中。
本文将使用最为先进的C4.5决策树算法,它基于从上到下的递归分治策略,选择信息熵增益最大的属性作为树的根节点,为每一个可能的属性值创建分支,这样将实例分成多个子集。算法将递归地执行这一步骤直到所有子节点的所有实例都属于同一类别,也就是叶节点的产生。不过要将决策树算法应用到成绩预测问题的最关键部分在于我们要调整我们的数据集。决策树算法需要应用在拥有名称性类别属性的数据集上,我们需要将我们的目标课程成绩离散化后才能使用算法,具体的离散方法会在第2.1节讲到。在weka中C4.5的实现是J48算法,我们可以通过调节api提供的多种参数来改变决策树的生成和修剪过程,使得预测模型规模更加符合我们的预期,而且也往往伴随着预测效果的提升。
2 决策树预测方案的设计
2.1 数据预处理
为了构建预测模型,我们需要将多门课程的成绩数据合并到同一数据集下,并指定数据的目标类别属性(预测的专业课程)。为了将数据构建成分类模型,我们需要将预测的专业课程成绩离散化,把数值型属性转换成名词型属性。成绩的离散化可以通过表1的方式进行转化。
由于数据收集来源和渠道的多样化,在数据预处理阶段不可避免的遇到缺失值的处理问题。在实际教育场景中,成绩缺失的主要原因分为两种:
(1)学生缺考或者申请缓考,这两种成绩缺失是由于多种客观因素造成的,然而一般都会有相应的补考数据存在。为了正确判断学生的学习表现,我们应该用对应的补考成绩替换缺考的缺失值。如果实在找不到可替代的值,将其置为0或者“未通过”。
(2)学生流失,原因包括辍学或者转专业等。事实证明,高校专业范围内每级的学生流失率平均要达到3%到7%左右,这部分学生未能完成全部专业培养计划,所以他们的数据对于构建学生成绩预测模型没有意义,应该被过滤掉。
另外对于多次补考、重考的数据实例,我们选择“采用第一次有效成绩作为属性值”的原则,这样可以避免补考出现的较高成绩影响我们对于学生实际学习行为的判断,同时避免了因特殊原因缺考而出现的0分成绩对于学生学习成果造成的过低估计。
2.2 剪枝优化与模型建立
本文的1.2节已简述了C4.5算法的工作原理,将其应用到我们准备好的数据集上就可以得到决策树模型。然而树模型在C4.5算法的训练之后完全展开通常会包含着很多不必要的结构,使得树模型的非常的庞大和繁琐。所以在应用决策树模型之前最好要进行剪枝优化。剪枝根据策略不同分为先剪枝和后剪枝两类。C4.5算法采用的是后剪枝策略,即在得到决策树模型以后再反向对其修改其结构,改变或提升其子树的位置,使得模型的可信度更高。Weka中为J48算法提供了信心因数(confidenceFactor)参数。通过对信心因数的调整,算法会将具有更高可信度的子树进行提升,从而调整整个树形结构。
2.3 模型评估
对于应用于分类问题的模型,需要通过准确率来衡量分类器的性能。模型的建立和评估往往是一体的,算法需要在训练数据集中应用,训练出应用模型,然后再将模型应用到测试集中得到评估结果。测试集和训练集必须保持独立性,才能得到真实可靠的误差率,有效的判断出模型是否存在过度拟合等问题。
一种非常有效的评估方式是交叉验证法,它不是简单的将数据集分割成训练集和测试集,而是对整体数据集分割成多等份,每次选用其中一份作为测试集,其余数据作为训练集。将每一次训练出的模型进行测试并得到结果,然后将得的预测精度取出均值和方差,得到最准确的评估反馈。最后,将算法应用于整体数据集训练出最终的模型结果。本文采用的是十折交叉验证算法作为模型的评估手段,即将数据集平均分成十份,完成十一次建模过程来得出最终的模型及其性能数据。
3 实验验证与结果分析
本次研究中我们用收集到的了某高校计算机科学专业的整级学生的专业课数据信息,包括其培养计划内的专业基础课和高阶专业课中的“数据库系统课程设计”共12门课程的等级成绩,通过预处理筛选无效实例后,最后得到424个数据实例。本章通过应用第二章阐述的方案设计流程,以高阶专业课的等级作为预测的目标类别属性,完成学生成绩预测模型的创建,并从模型结果中提取出规则结论。
3.1 可视化分析与分类基线精准度
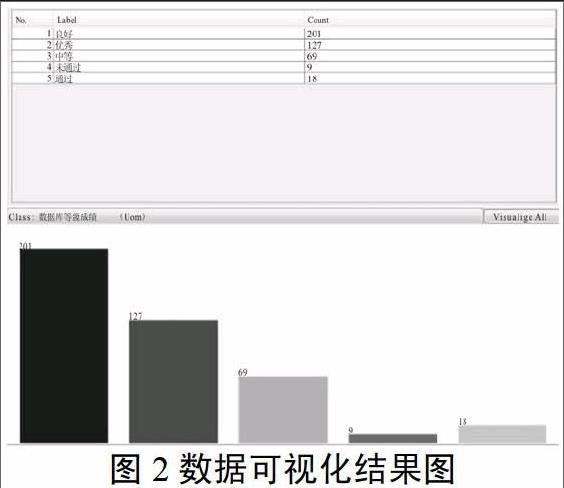
图2展示了离散化以后weka的数据可视化结果,从图中可以看到类别属性“数据库系统课程设计”的等级成绩的每个属性值的分布情况。
另外,在评估模型性能之前按需要一个基准线来对数据的可预测性做大致考量。OneR算法是一个非常简单有效的分类算法,它会寻找出数据集中对于目标预测的贡献值最突出的属性作为唯一的分类依据。本例中OneR选择了计算机导论的成绩,得出本数据集的分类基准线在40.7%。
3.2 决策树模型分析
我们将数据载入weka平台,并调用J48算法对其进行建模。并不断调整minNumObj参数以获得最佳的树形结构,最终结果如图3所示。
交叉验证的结果显示决策树模型的预测性能为83%,明显高于基线精准度。从图中可以看出,模型以“计算机导论”作为模型根节点,可见其是信息熵增益最强的属性,其次是数据结构,算法设计与分析和离散数学等。因此在众多基础课程中,“计算机导论”与“数据结构”对于预测目标课程“数据库系统课程设计”的成绩的贡献度最大,对于预测结果较差的学生应着重增强对这两门成绩的补习。
从图4所示的混淆矩阵中我们注意到,决策树模型对于成绩较低的“未通过”与“通过”两个类别的判断比较准确,这意味着这个模型可以较好的预测出有挂科倾向的学生,模型可以帮助我们有效的避免学生挂科,及时进行有针对性的补习,有很高的实用价值。
我们可以根据这些属性之间的相对关系来判断学生未来的学习趋势,进行提前干预和矫正,让其在专业学习上取得更好的成就。这些规律都会对矫正学生学习行为,辅助教育决策的优化起到很好的辅助作用。
4 结论与展望
4.1 结论
本文结合教育环境中的成绩数据特点,应用经典的C4.5决策树算法为本科生的专业学习表现构建了完整的预测模型方案,包括将数据进行必要的与处理工作来适应建模算法的要求,对决策树模型的剪枝优化,以及最后用十折交叉验证方法对模型性能的评估等。
此外,本文对采集到的某高校计算机科学技术专业424个实例构成的数据集的进行了分类建模分析,以“数据库系统课程设计”的成绩预测为例,完成了整个数据建模流程,得出了能够有效识别学生学习行为并预测学生未来成绩的决策树模型,并从中推导出了一些有价值的规则。
4.2 展望
本次研究有很多环节可以做更多补充和完善。首先对于学生特征来讲除了课程成绩以外,任课教师和出勤率等因素也可能导致对学习造成较大影响。然而由于本次研究所采集的数据数量集较小,无法很好地反映出这种变化幅度较轻的因素带来的影响。在将来的研究中我们可以扩大研究对象范围,扩展更多属性作为分析因子,得出更加全面的结论。
