短信文本分类技术的研究
2016-02-24王文霞王春红
王文霞,王春红
(运城学院 计算机科学与技术系,山西 运城 044000)
短信文本分类技术的研究
王文霞,王春红
(运城学院 计算机科学与技术系,山西 运城 044000)
短信作为一种重要的交流手段,发挥着越来越重要的作用。但伴随着短信的广泛使用,垃圾短信则严重影响着人们的生活,因此文中基于短信文本特征词对短信进行分类研究。其中,TF-IDF特征词权重计算方法是对文本词汇权重计算的一种经典算法,得到了广泛应用。但此方法为了简化计算,忽略了词语之间的相互关系。针对此问题,依据同一短信文本中的词汇之间存在的相互关系,文中对权重计算法进行了调整,提出了基于模糊K均值的短信文本分类算法。即先将短信文本集用TF-IDF算法处理,得到词汇-文本集,再用模糊K均值算法对得到的词汇-文本集进行处理。最后通过实验,验证了基于模糊K均值的短信文本分类算法,其分类结果的查全率和查准率都较高,有效辨别了垃圾短信。
短信文本分类;向量空间模型;模糊聚类;模糊K均值
0 引 言
短信业务作为目前的一种重要通信手段,具有短小、迅速、简便、便宜等诸多优点。据中国新闻网统计,到2010年,中国的手机用户数量达到近7.4亿,2009年短信发送量日均达到了21亿条,全年各类短信发送量达到7 840.4亿条[1]。根据中国互联网协会2008年年初发布的一项调查,中国手机用户平均每周收到的垃圾短信竟然多达8.29条,每周收到40条以上的居然达到了6.25%。在飞速的发展过程中,短信业务在给广大使用者带来方便的同时,也出现了很多问题,比如泛滥的垃圾短信、诈骗短信、谣言短信等等。这些垃圾短信给手机用户带来了很大的危害,因此需对垃圾短信进行过滤。
文中将自然语言文本处理运用到手机短信的分类研究[2-5]中。通过对短信文本特点的分析,实现对短信文本的分类。利用文本分类算法对短信信息进行分类,常用的分类算法有:决策树、支持向量机[6-9]、粗糙集和贝叶斯算法[10]。由于短信内容较少,依据同一短信文本中的词汇之间存在的相互关系,文中通过对经典的TF-IDF权重计算法的调整,并采用了模糊聚类算法,实现对短信文本的分类,达到了提高短信文本分析准确性的效果。
1 垃圾短信概述
1.1 垃圾短信的概念、特点、分类
没有经过接收者允许而收到的,内容具有违法性、欺骗性或广告性,并且侵犯了人们的合法权益,这样的短信被称之为垃圾短信。垃圾短信具有以下特点:骚扰性,未经接收者同意发布且具有广告性质,具有违法犯罪的内容等等。垃圾短信一般分为商业广告信息、非法制作各种票或证的信息、诈骗信息、赌博信息等。诈骗短信已成为危害社会治安秩序的一大公害。
目前,我国出现的诈骗短信共有三类:
1)手机费诈骗。
(1)通过赠送话费来骗取手机费:利用人们贪图小便宜的心理,使用户上当;
(2)通过朋友点歌或接收彩信来骗取手机费:人们往往以为是自己的朋友为自己点歌,所以就会毫无防备地回消息,造成手机费被骗;
(3)以冒充老朋友的身份骗取电话费:这种短信的迷惑性相当大,人们很容易上当受骗;
(4)以听取心里话的方式诈骗手机费:主要利用用户的好奇心理,诱使用户受骗。
2)银行卡诈骗。
一般是团伙作案,犯罪分子先利用短信群发器发送消息,对于上当的人,他们假扮银行工作人员、警察、银行管理中心人员等,让上当者成功地将钱存入其他账户;这种短信主要是利用用户对自身财产安全关心的心理。
3)现金诈骗。
(1)以谎称办假证、走私军火、售枪支弹药、招嫖或者提供其他违法服务或物品的方式诈骗现金:主要利用用户想走捷径的心理,将钱骗走;
(2)以谎称中奖骗取现金:这种短信利用用户贪小便宜心理,当用户联系时他们会要求先交一部分个人所得税等一系列费用,然后卷着钱财逃之夭夭[11]。
1.2 垃圾短信的危害
伴随着智能移动设备的普及,短信业务迅猛发展,垃圾短信也日益猖獗,已严重扰乱了人们正常的工作和生活,非常不利于社会稳定与和谐,主要表现如下:
(1)影响人们的正常工作和生活。无论接收者是否愿意,垃圾短信都会不分时段地发到接收者的手机。接到一条短信后,用户最少要花10 s来判断是不是垃圾短信,一天收到十几条,就需要花几分钟来查看,严重浪费了用户的时间。不管你看不看短信,都会收到短信铃声的骚扰,让用户苦不堪言,严重影响用户的工作和生活。
(2)扰乱社会秩序。垃圾短信为办假学历、假证件、出售黑车等非法行为提供了一种安全、廉价的业务促进方式,使社会秩序被严重扰乱。甚至有些垃圾短信包含着低级下流、污染社会风气的内容,直接影响青少年的身心健康[12]。
(3)垃圾短信已成为犯罪分子实施诈骗的载体。一些不法分子利用手机散布谣言,散布邪教和封建迷信的思想,煽动民众,造成民族关系紧张,影响社会稳定。不法分子通过抓住人们的心理,群发一些迷惑性短信,骗取信任,获得资金。
(4)影响正常通信。垃圾短信一般都是群发,数量极大,传输时会占用大量的通讯资源,严重的甚至会导致堵塞,使通信中断。
1.3 垃圾短信的处理
垃圾短信采用文本形式表示信息,首先需要把它转变成计算机可识别的形式。文中采用的是空间向量模型即VSM。下面介绍一些关于VSM的基本概念:
(1)特征项:指文本中能够代表该文本特点的基本语言单位。
(2)特征项权值:指特征项代表文本的能力的大小。特征项权值计算方法有很多,例如:布尔权重计算、平方根权重计算、TF-IDF权重计算等,其中TD-IDF权重计算最为常用。文中对于文本集的加权计算采用这种方法。
(3)文本向量:设文本集合中共有m个不同的特征项,分别计算出文本特征项的权值,由这些特征项权值所构成的向量称为文本向量[13]。
接下来详细介绍一下TF-IDF权重计算:
TF-IDF是一种基于统计分析的方法,用以获取字词在一个文件集或一个语料库中某文本的重要程度。TF-IDF权重计算的出发点是字词的重要性会随着它在文本中出现的次数增加,但同时会随着它在语料库中出现的频率下降[14]。其主要思想是:如果某个词或短语在某个文本中出现的频率高,而在其他文本中又很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF计算方法中有两个重要参数:
(1)TF词频。
它是指特征项在文本中出现的频率,计算公式为:
tfik=特征项tk在文档di中出现的频率
(1)
(2)IDF反文本频率。
它是对特征词在文本集中分布情况的量化,用于衡量该特征词区分不同文本的能力,常用计算公式为:
idfk=log(N/nk+0.01)
(2)
其中:N代表文本集所有文本的个数;nk代表文本集中出现特征词的文本数。
TF-IDF权重计算方法,是Salton和McGill基于香农信息理论提出的一种方法。该方法已成为目前文本聚类和分类中最常用的方法。它是将词频和反文档频率两方面因素相结合来得到特征词的权重值,计算公式为:
wik=tfik×idfk=tfik×log(N/nk+0.01)
(3)
2 模糊K均值
Bezdeck等提出了模糊K均值算法。模糊K均值算法将模糊原理与经典K均值算法相结合,是一种非监督聚类算法。其基本思想是按照一定的模糊隶属度将每个数据对象分配到某个聚类中,使得不同类中的数据对象具有较低的相似性,同一个类中的数据对象具有较高的相似性。该算法将分好的簇看做是模糊集合,一个簇对应一个模糊集合,用隶属度函数度量每个数据属于某个簇的可能性,然后依据最大隶属度原则将数据分配到隶属度最大的簇中。
2.1 算法基本思想
模糊K均值算法是基于最小化以下目标函数[15]:
(4)

2.2 算法描述
总而言之,舞台表演是声乐演唱不可分割的一部分。演唱者在平时的练习中,学习好基础知识,然后在表演实践中提升自己的舞台表演能力,在演唱中逐渐变得成熟,很好地向观众传达作品的思想情感,有助于观众更好地了解作品。演员也要在面部表情、手势动作、上下场的处理等方面多下功夫,使得“演”与“唱”协调统一,使歌唱达到声情并茂的艺术境界,从而提升音乐的魅力,向观众展现出更多更加感人、更加优美的作品,也让越来越多的观众因为演员真挚的表演而爱上音乐。
模糊K均值算法描述如下:

(2)初始化聚类中心vi,i=1,2,…,K,一般从N个数据点中任意选择K个数据点作初始聚类中心。
(3)根据式(5)计算所有聚类数据点对于每一个聚类中心的隶属度。
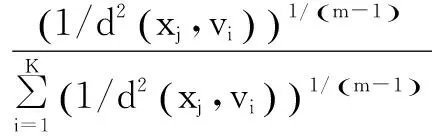
(5)

(6)

3 基于模糊K均值的短信文本分类算法
利用模糊K均值实现短信文本分类算法描述如下:
(1)输入文本集合中的特征项,建立特征项库。
(2)将文本内容输入数据库,建立文本信息库以及文本段信息库。
(3)对每个文本段信息利用TF-IDF权重计算公式算出每一个特征项的权值,构造文本向量信息库。
(4)用模糊K均值算法对文本向量进行处理。需要明确要处理的样本数、每一行的特征项个数、要分的类别数、迭代的次数、聚类的精度等等。
(5)输出一个隶属度矩阵,获得文本分类结果。
基于模糊K均值的短信文本分类算法的基本思想是首先收集待处理的短信文本集,接着要对短信文本进行分词;然后建立特征项集,利用TF-IDF对每个特征项进行加权计算,得到文本向量,构建“词汇-文本”矩阵;最后用模糊K均值算法对“词汇-文本”矩阵进行处理,输出一个隶属度矩阵。具体的算法设计如图1所示。
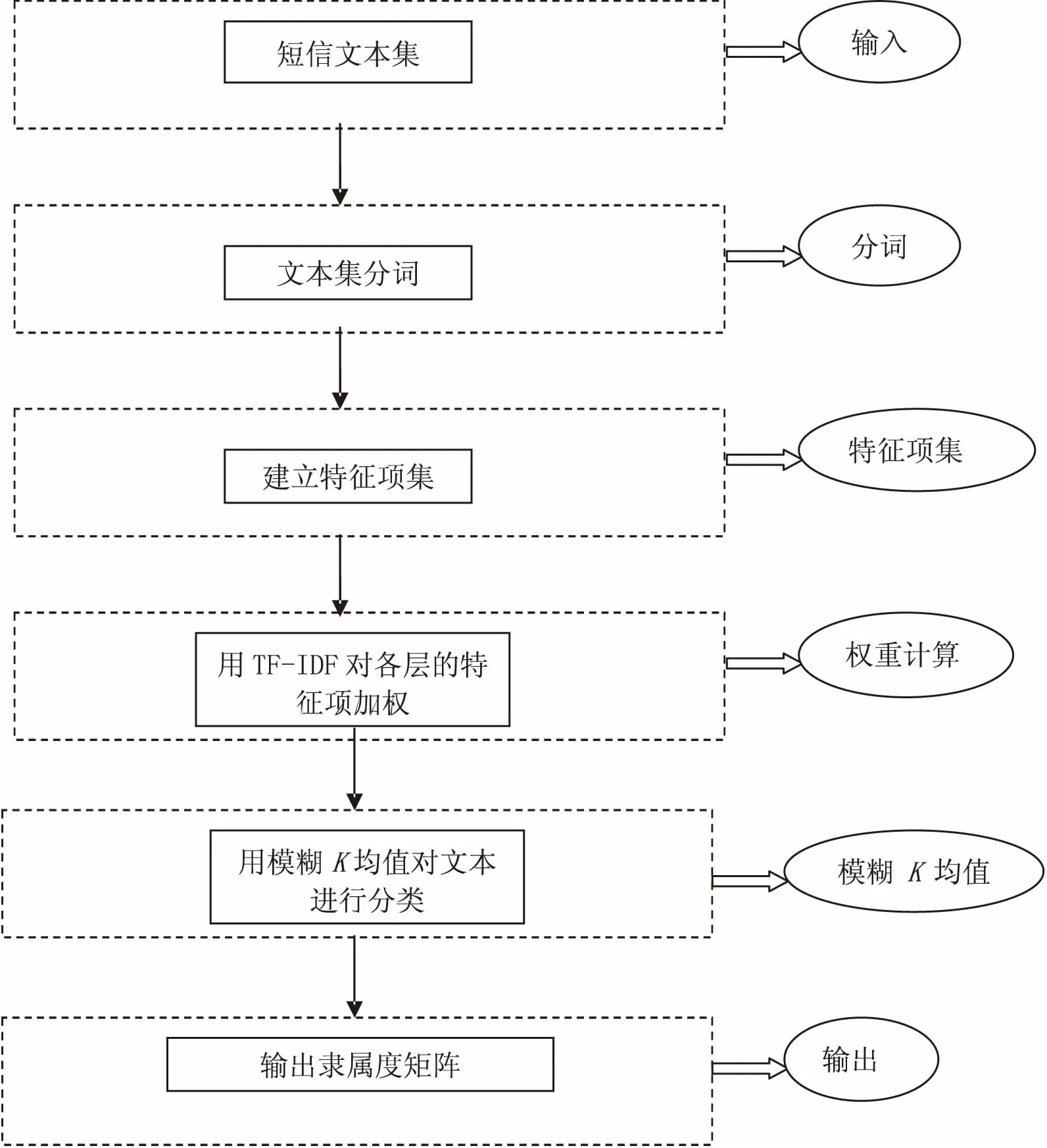
图1 算法流程图
4 实验结果及分析
根据文本检索的度量标准,文中定义了两个评估指标,即查准率(Precision)和查全率(Recall),对基于模糊K均值的短信文本分类算法进行了有效性验证。
其中:查准率p是指实际相符的文本占属于类别Ci的所有文本的比例;查全率r是指正确归类的文本占专家判定的应属于类别Ci的所有文本的比例。两项指标分别定义如下:
(7)
(8)
基于从互联网上收集的商业广告型短信、诈骗短信、非法制作各种票或证的短信、赌博类短信四方面的大量文本,分别从中各随机选取10个文本,共40个。这40个文本分别按商业广告型短信、诈骗短信、非法制作各种票或证的短信、赌博类短信的次序排列,并对其进行预处理,进而基于模糊K均值聚类算法实现了文本分类。实验结果如表1所示,列出了10个文本的隶属度矩阵,商业广告型短信和诈骗短信各2个,非法制作各种票或证的短信和赌博类短信各3个;表2给出了每个文本所属的类。
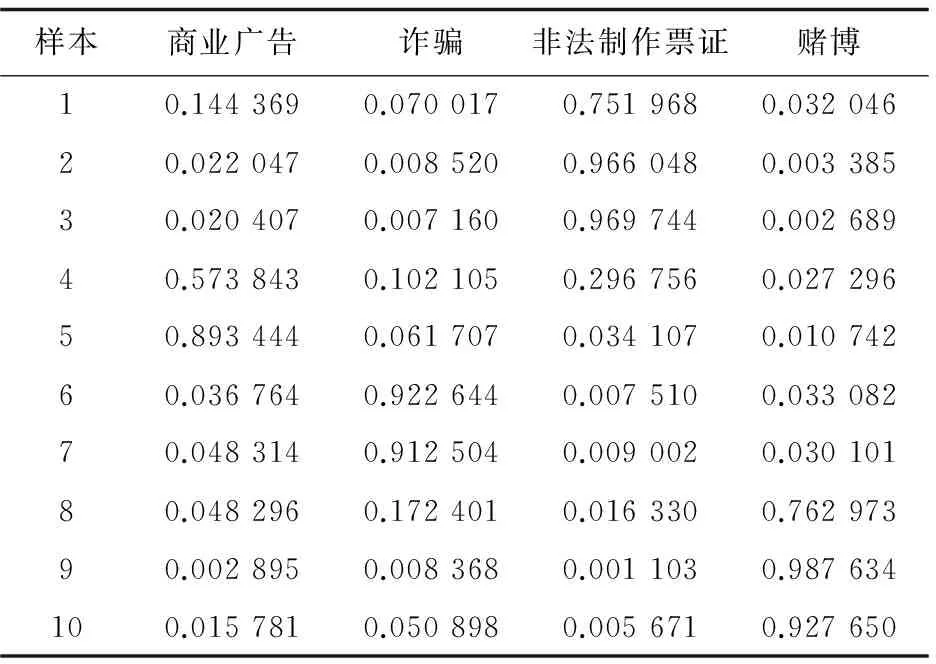
表1 输出的隶属度矩阵

表2 40个样本的分类结果
为了验证该算法的有效性,将该算法聚类分析结果与人工分类的结果进行了对比,如表3所示;并采用了聚类分析的两个评价标准—查准率和查全率对聚类结果进行量化分析,其结果如表4所示。从这两个表可以看出,基于模糊K均值对文本分类,其查准率和查全率都较高。

表3 模糊K均值聚类分析最终结果
5 结束语
文中提出的基于模糊K均值的短信文本分类算法,很好地克服了经典TF-IDF权重计算中忽略了词
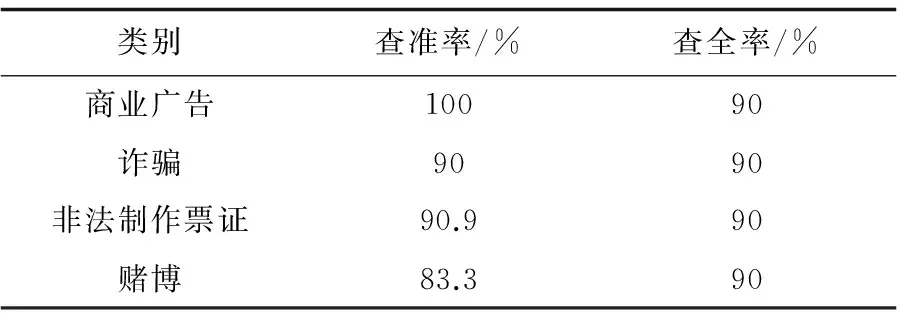
表4 查准率和查全率
语之间的相互关系的弊端。实验结果表明,该聚类算法大大地改善了短信文本聚类的效果,查全率和查准率都较高。
[1] 刘国香,张钧锋.垃圾短信分类方式的探讨[J].沧州师范专科学校学报,2011,27(4):122-124.
[2]PatelD,BhatnagarM.MobileSMSclassification:anapplicationoftextclassification[J].InternationalJournalofSoftComputingandEngineering,2011,1(2):47-49.
[3]LiuWuying,WangTing.Index-basedonlinetextclassificationforSMSspamfiltering[J].JournalofComputers,2010,5(6):844-851.
[4]LiFeng,LiJigang.StudyingofclassificationChineseSMSmessagebasedonBayesianclassification[J].JournalofTheoreticalandAppliedInformationTechnology,2012,44(1):141-146.
[5] 杨 柳,殷 钊,滕建斌,等.改进贝叶斯分类的智能短信分类方法[J].计算机科学,2014,41(10):31-35.
[6] 李 慧,叶 鸿,潘雪瑞,等.基于SVM的垃圾短信过滤系统[J].计算机安全,2012(6):34-38.
[7] 冯欧鹏.垃圾短信过滤中字特征与词特征对过滤效果的比较研究[D].北京:北京邮电大学,2011.
[8] 徐 易.基于短文本的分类算法研究[D].上海:上海交通大学,2010.
[9]LanMan,TanCL,SuJian,etal.Supervisedandtraditionaltermweightingmethodsforautomatictextcategorization[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2009,31(4):721-735.
[10] 张 兢,候旭东,吕和胜.基于朴素贝叶斯和支持向量机的短信智能分析系统设计[J].重庆理工大学学报:自然科学,2010,24(1):77-81.
[11] 赵晓芳.短信诈骗的类型、法律定性及应对策略[J].消费导刊,2008(2):125-125.
[12] 董月琴.基于Android的垃圾短信处理系统的研究与设计[D].淮南:安徽理工大学,2011.
[13] 付克志,林鸿飞.基于N-LevelVSM在Web信息检索中的研究[J].计算机工程与应用,2006,42(19):158-160.
[14] 包金龙.基于向量空间模型的信息检索系统的设计[J].情报杂志,2005,24(7):44-45.
[15] 叶吉祥,谭冠政,路秋静.基于核的非凸数据模糊K-均值聚类研究[J].计算机工程与设计,2005,26(7):1784-1785.
Research on Text Classification Technology for Message
WANG Wen-xia,WANG Chun-hong
(Department of Computer Science and Technology,Yuncheng University,Yuncheng 044000,China)
As an important means of communication,SMS plays an increasingly important role.But along with the extensive use of SMS,SMS spam seriously influences people’s lives.Therefore,the classification of SMS is researched based on the keywords in this paper.TF-IDF weight calculation method is a classical algorithm to calculate the text word weight,which is widely used.But in order to calculate simply,this method ignores the mutual relations between words.Aiming at this problem,based on the same relationship between words in the text messages,in this paper,the weighting method is used for adjusting,it puts forward the text classification based on fuzzyK-meansalgorithm.ThetextsetisprocessedbyTF-IDFalgorithm,gettingavocabulary-textset.ThenfuzzyK-meansalgorithmisusedtogetavocabulary-textset.Finally,throughtheexperimenttoverifythetextclassificationbasedonfuzzyK-meansalgorithm,theclassificationresultsofrecallandprecisionishigh.
text categorization;vector space model;fuzzy clustering;fuzzyK-means
2015-07-22
2015-11-05
时间:2016-03-22
国家自然科学基金资助项目(11241005);山西省高等学校教学改革研究项目(J2012098);运城学院教学改革研究项目(JG201418)
王文霞(1979-),女,讲师,硕士,研究方向为数据挖掘及算法分析;王春红,教授,研究方向为信息检索及算法分析。
http://www.cnki.net/kcms/detail/61.1450.TP.20160322.1522.092.html
TP
A
1673-629X(2016)05-0145-04
10.3969/j.issn.1673-629X.2016.05.031
