基于自适应希尔伯特扫描和词袋的图像检索
2016-02-23刘福岩余梦婷
徐 墨,刘福岩,余梦婷
(上海大学 计算机工程与科学学院,上海 200444)
基于自适应希尔伯特扫描和词袋的图像检索
徐 墨,刘福岩,余梦婷
(上海大学 计算机工程与科学学院,上海 200444)
提出一种自适应希尔伯特扫描方法用于解决图像检索中使用词袋模型丢失空间信息的问题。该方法通过分析特征在图像中的分布来计算在越来越精细的分辨率下每个希尔伯特路径的权重,从而为每张图像选择最优的扫描路径。探讨了基于希尔伯特扫描树的构建过程并对其优缺点进行了分析,该方法能够将图像特征的空间信息有效地加载到树的每个节点上。然后基于局部特征在图像空间的分布提出一种多层次的自适应希尔伯特扫描策略。得益于此方法,在之后为图像建立的基于希尔伯特树形结构上,物体的空间信息将被保存得更加准确,从而有利于快速重建物体轮廓。在Caltech-256数据库上进行了大量对比实验,实验结果表明该方法具有更高的检索准确率。
希尔伯特扫描;图像检索;词袋;特征表示
1 概 述
近年来,大规模数据库中相似图像检索受到越来越多的关注。给出一张检索图像,目的是从数据库中检索出与其包含相同物体或场景的图像。一个大规模检索系统必须考虑三个因素:检索准确率、内存使用和效率。
目前大部分先进的检索技术都是基于词袋模型(Bag-Of-Features,BOF)[1]。BOF模型的基本思想是将图像表示成一组视觉单词的直方图。基于BOF的检索系统首先需要提取每张图像的局部特征,例如最流行的SIFT[2];然后对特征空间聚类生成字典;最终通过特征映射,每张图像可以用一个直方图向量来表示。然而BOF忽略了特征的空间信息,不能获取物体轮廓或者将物体从背景中分离出来。
为了解决这个问题,研究者们提出了一些BOF的衍生模型。例如文献[3]将图像分割成不同尺度下2l×2l个小块,l=0,1,2,再分别计算每个小块中BOF直方图向量,最后将21个小块中的向量连接起来形成最终的图像描述向量。尽管此方法简单可行,也取得了不错的效果,但它必须将图像分解成固定尺寸,导致其对严重混杂现象,几何变形(如旋转、尺度变化等)很敏感。文献[4]提出一种空间权重BOF方法,此方法通过降低背景特征权重,从而突出物体轮廓与位置的重要性。尽管该方法对于混杂背景具有鲁棒性,但它只适用于一些特定种类的图像。文献[5]将特征从二维空间以不同角度映射到一维空间,然后选取最具代表性的表示方法作为最终的直方图描述向量。文献[6]对特征向量重新编码,将特征的空间信息加入投资向量中。此方法虽然有效,但字典维度太大,不适用于大规模图像检索。受文献[5]的启发,Hao和Kamata[7]将希尔伯特曲线与词袋模型相结合,为每张图像建立基于希尔伯特扫描的树形结构(Hilbert-ScanBasedTree,HSBT),特征空间信息通过一种聚类与过滤规则加载到树的每个节点,但该方法忽略不同扫描路径下生成的树形结构,可能导致空间信息误加载。
文中研究主要基于HSBT[7]结构,因为HSBT能有效地抓取物体轮廓并且压制背景信息,但其对于特征空间信息的加载可能存在错误。使用希尔伯特曲线对图像进行扫描时,必然导致图像中相邻两块区域在希尔伯特序列中分开。对一般图像而言,由于大量特征提取自图像中关键物体的局部外观,如果这些特征所处区域位于希尔伯特扫描的分裂处,必然造成一些空间上相关的特征在映射到一维空间后也被分开,一些融合错误必然产生在HSBT建立过程中,导致抓取的物体轮廓失真,或者不能有效地将物体从背景中分离出来,进而影响最终的检索准确率。于是,文中提出一种全新的自适应希尔伯特扫描策略用于为每张图像选择最适合它的希尔伯特扫描路径。该策略基于两个因素,第一是统计不同扫描路径下分裂出两个方块中包含的特征总数。由于一般图像中大部分特征都提取自关键物体,如果有一组相邻方块包含的特征点总数多于其他三组,这就意味着这两块区域很重要,不应该在一维空间中被分开,因此要避免使用该扫描路径。然而,如果这两块相邻区域中的大部分特征集中在其中一块中,那么经过希尔伯特扫描之后,二维空间中的相关特征在一维空间依旧离得很近,保证了特征的空间位置一致性。为了有效地融合这两个因素,加入一个权重参数用于控制它们的相对重要性。受希尔伯特扫描生成方法的启发,将此方法从特征的全局几何分布到局部几何分布进行实施,从而更加有效地运用特征的空间信息。
2 基于自适应希尔伯特扫描的词袋模型(AHS-BOF)
2.1 基于希尔伯特扫描的树形结构
假设一张图像的分辨率是m1×m2,当提取了SIFT特征点之后,用希尔伯特扫描[8]将这些特征点映射到一维空间并将一维序列平均分割成很多子区域,因为希尔伯特扫描能够尽可能保存点的邻域[9]。由于图像尺寸不一定是正方形,于是提出一种伪希尔伯特扫描[10],它最重要的优点是像希尔伯特扫描一样能够尽可能保留每个点的邻域。因此,该算法有助于文中研究工作。首先用伪希尔伯特曲线扫描整张图像得到一个一维序列,用{L,F,R}来表示。其中,L表示特征点在图像中的坐标集;F表示特征集;R表示L分割后所有子区域的集合。在映射与分割之后,通过对这些子区域进行聚类操作从而建立HSBT结构。
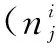

初始化:首先将线性序列S平均分割成v(1)个子区域,分解因子为δ,那么,m1×m2大小的图像就被平均分割成v(1)=m1×m2/δ个不规则的小块。由此可以统计每个子区域中的特征个数并过滤没有特征的空白区域,进而可以得到G′,F′,C′。
重要区域选择:在区域融合之前,首先选择重要的子区域,具体细节如下:

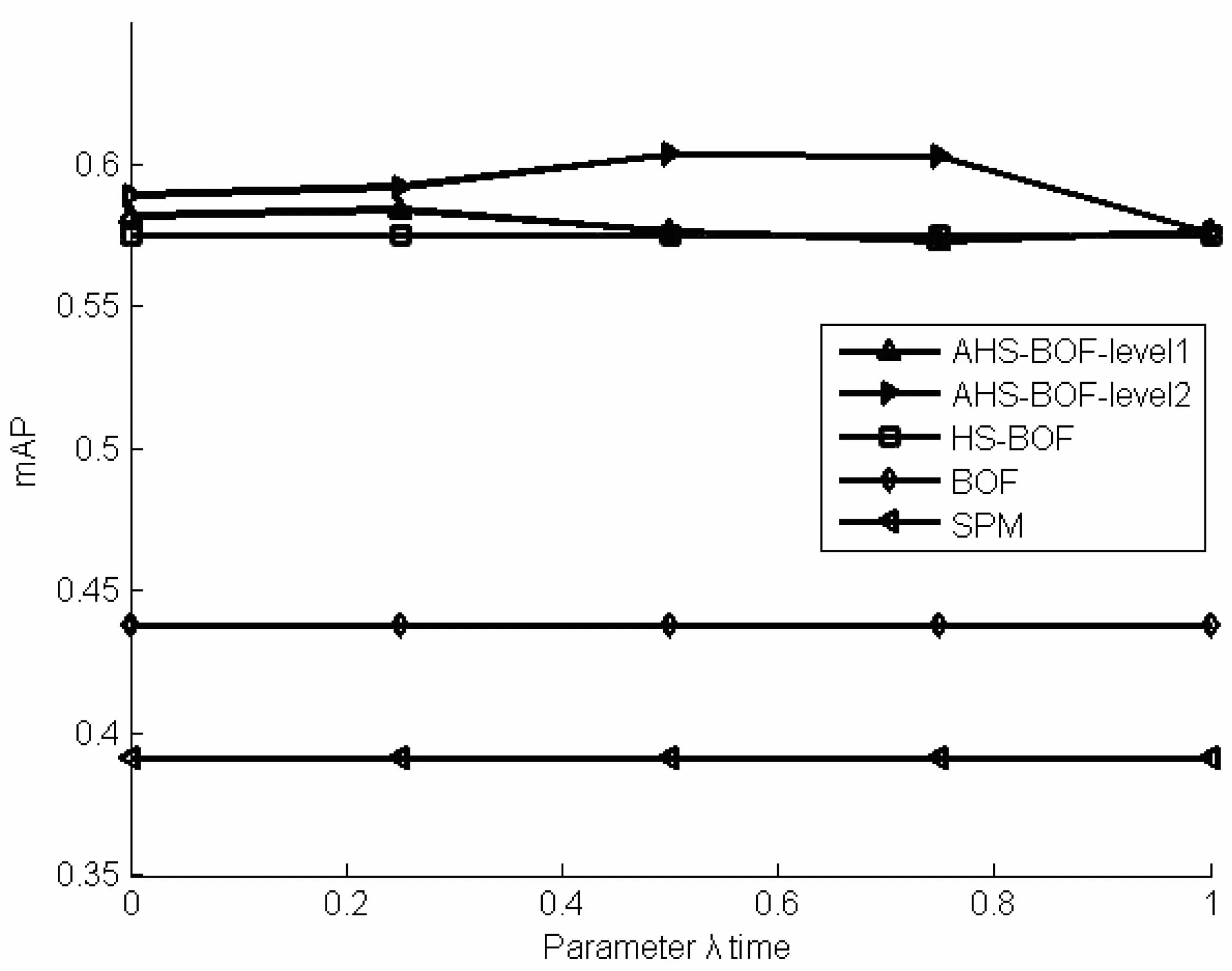
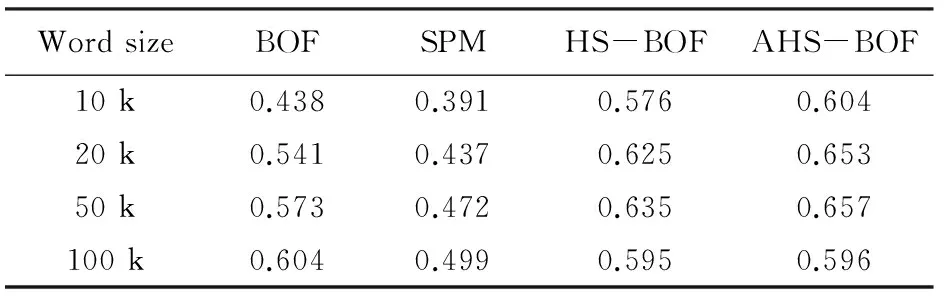
其中,M为图像中特征点的个数;Th为阈值,0 (1) 通过以上三个步骤可以为一幅图像建立HSBT结构,如图1所示。 图1 图像的HSBT结构 HSBT旨在将二维空间中的特征映射到一维空间,为每张图像生成一个树形结构。无需任何标记或手动操作,通过一定的聚类规则,特征的空间信息都被加载到树的每个节点中。 在区域融合过程中,单一并且固定的扫描路径可能会产生大量的融合误差。目标是保证从关键物体中提取出来的特征在被映射到一维空间之后尽可能离得很近。在区域融合过程中,来自关键物体的特征会更快被融合到一起,从而有利于快速且准确地恢复关键物体轮廓,避免被不必要的噪声特征干扰。下一节依据特征在图像空间中的分布提出一种全新的自适应希尔伯特扫描策略。该策略可以为每张图像选择合适的希尔伯特扫描路径,从而在建立HSBT结构时减少融合误差并快速重建关键物体的轮廓。 2.2 自适应希尔伯特扫描 对于一般图像,假设对其提取SIFT[2]特征点,那么大部分特征都是从其关键物体中提取出来的。在建立HSBT时,包含绝大多数特征的区域被选为重要区域,通过多次区域选择与融合从而建立树形结构。目标是确保这些重要区域在希尔伯特序列中尽可能离得很近,从而有效地减少融合误差,快速重建重要物体或者场景的轮廓。对于一张图像存在四种扫描方式(如图2所示,其中黑色点表示特征点),也会产生四种不同的线性序列。 图2 四种希尔伯特扫描 在图2中不难发现,第二与第三块区域包含图像中大部分特征,因此这两块区域在建立HSBT时会被选为重要区域。如果使用图中第四种扫描路径,那么块二与块三在一维序列中将被分开很远。因而,很多不相关的特征点(比如从人和道路上提取出来的特征点)会夹杂在块二与块三之间,导致很多不相关特征融入块二与块三中,产生许多融合误差,不利于重建重要区域轮廓。为了避免上述不好的扫描路径,基于特征的分布情况提出一种全新的自适应希尔伯特路径选择策略。 上面提到过,如果某区域包含了图像中大部分特征,那么该区域就是重要区域,如图3中的块二与块三。因此,影响路径选择的第一个因素是在分裂边缘(图3中的黄色线条表示分裂边缘)两边的子块中所包含特征的个数。所以,第一个因素的公式表示为: w1S=nA+nB/nC (2) 其中,nA和nB分别表示分裂边缘两边子块各自包含特征的个数;nC表示整个图像包含特征的个数;s表示第s个扫描路径。 如图2中所示,第三个扫描路径中分裂边缘两边子块包含更多特征,那么它们就是重要区域,不应该被分开。但这时会产生一个问题:如果图3中A和B两块中的特征集中分布在其中一块中,即使这两块在一维序列中被分开,绝大多数特征仍然在一维空间离得很近,因而不会产生很多融合误差。为了解决这个问题,文中又提出了另一个影响路径选择的因素: w2S=min(nA,nB)/max(nA,nB) (3) 如果接近1,那么A和B中所包含的特征个数几乎相同。当特征被映射到一维空间时,大部分特征将被分离得很远,从而产生大量融合误差;相反,接近0时,表明大部分特征集中在其中一个方块中,特征在一维空间中仍然距离很近,降低了融合误差产生的可能性。此时很难判断哪个因素对于最后的路径选择更重要,为了将这两个因素有效结合,引入一个权重系数λ来控制两个因素的相对重要性。公式如下: WS=(1-λ)·w1S+λ·w2S (4) 由文献[7]可知,对于一个矩形空间,一般需要经历数次分裂才会形成最终的希尔伯特扫描。例如一个大小为4×4的矩形需要两次分裂才会生成最后的希尔伯特扫描(为基本形,不能再进行分裂,如图4)。一般的图像尺寸从几十乘以几十到几千乘以几千,很显然仅仅计算一次分裂远远不足以评判哪个扫描路径更好。比如,当和很相近时,宏观上几乎无法判断哪个路径更好(如图2中的第二种和第四种)。因此,需要将目光投向特征在每个小块中的分布,即更细粒度的分布。需要从宏观和微观两个视角分析特征分布状况。在此基础上提出了一种多层次方法,见式(5)。 (5) 其中,i表示第i次分裂;j表示在第i次分裂中第j个子块;k表示分裂次数;l表示每次分裂下子块的个数;c表示一张图像中所有特征的个数;cij表示第i次分裂中第j个子块中特征点的个数;cij/c表示这个小块相对于整张图像的权重。 图3 第一层希尔伯特扫描 图4 4*4希尔伯特扫描 如果一个子块包含的特征点多,那么它相对比较重要,它所分配到的权重值也应该越大。 上述方法不仅考虑了特征的全局几何分布,也考虑了其局部几何分布情况。由粗到细,从宏观到微观,全方位地考虑了特征的空间信息。 2.3 基于自适应希尔伯特扫描的词袋模型 在为每一张图像选择了合适的路径并建立HSBT之后,将BOF模型与HSBT相结合,这一部分主要有两个步骤:字典生成和特征编码。 (1)字典生成。 图5 多层字典的生成示意图 (2)特征编码。 在字典生成之后,所有的局部特征必须映射到字典中的每个视觉单词上。目前有许多字典映射的方法,例如向量量化(VectorQuantization,VQ)、稀疏编码[11](SparseCoding,SP)、局部约束线性编码[12](Locality-constrainedLinerCoding,LLC)和局部软分配编码[13](LocalSoft-assignmentCoding,LSC)等。VQ是一对一映射方法,即每一个局部特征映射到离它最近的视觉单词上。但这没有考虑到视觉单词的歧义性,通常会带来量化误差。为了解决这一问题,提出了SP、LLC、LSC等方法,这些方法都将局部特征映射到多个视觉单词上,并在图像分类上取得了非常好的效果。然而这些方法或多或少都存在一些缺陷,其中最严重的缺点就是时间复杂度过大,而大规模图像检索问题对于检索速度要求很高。为了在检索准确率与检索速度寻求一个平衡,最终还是选择了VQ作为最后的特征编码方法。 对于一张图像,其树形结构的高度为h,如果h大于H,只对其前H层进行量化;如果h小于H,只使用其前h层。最终,一张图像可以被表示成一个多层次直方图。编码规则如下: (6) (7) 每一层的直方图生成之后,使用最常用的TF-IDF方法对其进行加权。最终,将每一层的直方图向量连接起来生成图像特征描述向量。在计算图像相似度时,采用文献[7]中的CHI-Square方法。 在Caltech-256上检验此方法。Caltech-256[14]由加州理工学院于2007年建立,其中包含256个类别,每个类别至少包含80张图像,图像总数为30 607。每个类别的图像都是由人工手动挑选出来的。图像类型涉及不同场景、光照、角度等条件下的自然与人工物体。实验采用mAP(meanAveragePrecision)作为评价准则。为了训练字典,随机从每个类别中选取50张图像作为训练集,训练方法采用K-means。然后再从每个类别中选5张图像作为测试集。设δ为500,Th为0.8。和文献[7]一样,提取树的前10层,字典大小设置为10k,20k,50k,100k。 图6显示了不同λ下几种方法的对比。很明显,第二层AHS-BOF的mAP优于其他几种方法。这也证明了文中的设想:多层次能够有效抓取特征的空间信息。图中的AHS-BCF-level2几乎都在HS-BOF之上,这也表明该方法可能不会为图像选择最适合它的扫描路径,但一定不会产生不利影响。在第二层,该方法相比于HS-BOF提高了大概3%的准确率。 图6 不同λ下的mAP 表1显示了在不同字典大小下AHS-BOF与其他几种方法的对比。为了还原前人的结果,所有的实验参数与文献[7]一样。当字典大小为100k时,其大小几乎等于特征的个数,因而直方图向量几乎不具有辨识力,因此,选择任何扫描路径对最终的检索结果都不会产生显著影响。所以,AHS-BOF与HS-BOF的检索结果几乎相同。 表1 不同字典大小下mAP的比较 表2比较了不同分裂层数下mAP的大小。很明显第二层的结果最好,第三层结果有所下降。这表明,过度重视特征的细节信息会将一个统一的物体割裂开,从而丢失物体全局外观。 表2 不同分裂次数下mAP的比较 文中提出的自适应希尔伯特扫描策略能够为每张图像选择合适的扫描路径,减少了HSBT中的融合误差,降低了物体重建所需树的层数,节省了物体重建时间,有效地解决了BOF模型丢失特征空间信息的缺点。然而该方法对于复杂语义或者场景(卧室、客厅等)的图像处理能力不够,并且不同数据库最优的权重参数λ也不同。未来工作中,会尝试更抽象的特征提取方法,并设计一种动态参数调节方法。 [1]SivicJ,ZissermanA.VideoGoogle:atextretrievalapproachtoobjectmatchinginvideos[C]//NinthIEEEinternationalconferenceoncomputervision.[s.l.]:IEEE,2003:1470-1477. [2]LoweDG.Objectrecognitionfromlocalscale-invariantfeatures[C]//ProceedingsoftheseventhIEEEinternationalconferenceoncomputervision.[s.l.]:IEEE,1999:1150-1157. [3]LazebnikS,SchmidC,PonceJ.Beyondbagsoffeatures:spatialpyramidmatchingforrecognizingnaturalscenecategories[C]//IEEEcomputersocietyconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2006:2169-2178. [4]MarszaekM,SchmidC.Spatialweightingforbag-of-features[C]//IEEEcomputersocietyconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2006:2118-2125. [5]CaoY,WangC,LiZ,etal.Spatial-bag-of-features[C]//IEEEconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2010:3352-3359. [6]McCannS,LoweDG.Spatiallylocalcodingforobjectrecognition[M]//ACCV2012.Berlin:Springer,2012:204-217. [7]HaoPengyi,KamataS.Hilbertscanbasedbag-of-featuresforimageretrieval[J].IEICETransactionsonInformationandSystems,2011,94(6):1260-1268. [8]HilbertD.ÜberdiestetigeAbbildungeinerLinieaufeinFlächenstück[J].MathematischeAnnalen,1891,38:459-460. [9]JagadishH,FaloutsosC,SaltzH.AnalysisoftheclusteringpropertiesoftheHilbertspace-fillingcurve[J].IEEETransactionsonKnowledgeandDataEngineering,2011,13(1):124-141. [10]ZhangJ,KamataS,UeshigeY.Apseudo-Hilbertscanforarbitrarily-sizedarrays[J].IEICETransactionsonFundamentals,2007,90(3):682-690. [11]YangJ,YuK,GongY,etal.Linearspatialpyramidmatchingusingsparsecodingforimageclassification[C]//IEEEconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2009:1794-1801. [12]WangJ,YangJ,YuK,etal.Locality-constrainedlinearcodingforimageclassification[C]//IEEEconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2010:3360-3367. [13]LiuL,WangL,LiuX.Indefenseofsoft-assignmentcoding[C]//IEEEinternationalconferenceoncomputervision.[s.l.]:IEEE,2011:2486-2493. [14]GriffinG,HolubA,PeronaP.Caltech-256objectcategorydataset[R].California:CaliforniaInstituteofTechnology,2007. Image Retrieval Based on Adaptive Hilbert Scan and Bag of Features XU Mo,LIU Fu-yan,YU Meng-ting (School of Computer Engineering and Science,Shanghai University,Shanghai 200444,China) One fundamental problem in large scale image retrieval with the bag-of-features is its lack of spatial information.An approach called adaptive Hilbert-scan depended on distribution of features in an image is proposed.This method computes weight of each Hilbert-scan at increasingly fine resolutions by analysis of feature distribution in the image,which is able to assign a suitable scanning path for each image.Hilbert-scan based tree structure is studied and its advantage ad disadvantage is analyzed.The method adds the spatial information of local features into each node of tree,furthermore a novel adaptive Hilbert-scan strategy with multi-level is designed,which is built on the distribution of features in image.Owing to merits of this method,spatial information of features will be preserved more precisely in Hilbert-scan based tree structures.Extensive experiments on Caltech-256 show the effectiveness of the method. Hilbert-scan;image retrieval;bag-of-features;feature representation 2016-02-22 2016-06-09 时间:2016-11-22 国家自然科学基金面上项目(61471232) 徐 墨(1989-),男,硕士,研究方向为图像处理与计算机图形学;刘福岩,副教授,研究方向为计算机图形学等。 http://www.cnki.net/kcms/detail/61.1450.TP.20161122.1227.028.html TP301 A 1673-629X(2016)12-0017-05 10.3969/j.issn.1673-629X.2016.12.004


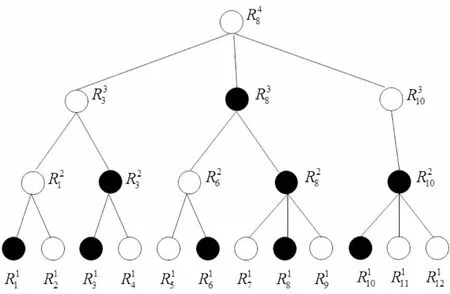






3 实 验

4 结束语
