基于PLB4总线的DDR3控制器的设计与优化
2016-02-23王世中
李 哲,田 泽,王世中,郑 斐
(西安航空计算技术研究所 集成电路与微系统设计航空科技重点实验室,陕西 西安 710068)
基于PLB4总线的DDR3控制器的设计与优化
李 哲,田 泽,王世中,郑 斐
(西安航空计算技术研究所 集成电路与微系统设计航空科技重点实验室,陕西 西安 710068)
内存是计算机系统的信息存储部件,主设备与内存间信息交换的速度是影响系统性能的关键因素。PLB总线是IBM提出的嵌入式总线标准,用于主设备与片内存储以及PCIE、DMA、SRIO等高速设备的互联,在SoC设计中使用广泛。该项目中DDR3作为从设备挂接到PLB4总线上,而选用的DDR3控制器IP核基于HIF接口,使用该IP核需要设计一套简单高效的总线桥逻辑,以满足系统访存性能要求。文中提出一种基于PLB4总线接口的DDR3控制器的设计方案,通过对数据流、控制流进行深入分析,采用请求合并、多级流水、数据预测、地址与控制信息复用、读数据乱序处理等方式,对访存效率影响较大的总线桥进行了速度和面积优化。仿真证明,优化后访存性能得到显著提升。
内存;性能;速度;面积;优化
0 引 言
在高性能SoC设计中,高速的片上总线和高效的片上内存管理是不可或缺的组成部分。DDR3是由JEDEC制定的新一代DDR内存技术标准。在现行的各种总线标准中,IBM公司提出的CoreConnect总线结构具有突出的性能和效率优势,能够满足日益复杂化和高速化的SoC设计要求,成为业内标准总线之一。CoreConnect总线采用分级结构,分别通过PLB(Processor Local Bus)总线和OPB(On-chip Peripheral Bus)总线将高速设备与低速设备分离,同时把读写控制寄存器的总线操作独立开来,形成单独的DCR(Device Control Register)总线,大大减轻了数据总线的负载[1]。它支持各种传输操作,总线/事务分离以及地址流水化等功能,最大限度提升总线带宽,从而提高系统性能[2]。
1 总体结构设计
该项目需要设计满足PLB4.6协议标准的总线接口,满足DDR3协议规范的内存控制器。DDR3控制器用于用户访问片外DDR3 SDRAM存储器芯片,它提供了用户访问外部存储器芯片的通道,支持片外SDRAM数据位宽度为64位。提供软件可访问的DCR接口寄存器,用于根据不同外存芯片进行大小、延迟等参数的配置,并能读取存储控制器的当前状态[3]。
为提高SoC设计效率,采用IP复用技术,从经过硅验证的PLB4从设备IP核中剥离出PLB4从接口,选用成熟的DDR3标准IP核。需要做的主要工作就是从PLB4从接口到DDR3 IP核之间的转接逻辑,如图1所示,包括PLB4从接口模块,DDRC控制器模块,DDR PHY模块。其中PLB4从接口模块后端为MCIF(Memory Control InterFace)总线接口,MCIF总线是IBM公司定义的一种存储器控制接口,DDRC模块分为控制器和PHY两大部分,DDR控制器的主机接口为HIF(Host InterFace)接口,控制器与PHY之间是标准的DFI(DDR PHY Interface)接口。其中DDRC和PHY内部有可配置的寄存器,通过DCR接口访问。PLB4从接口模块是DDR3控制器与PLB4总线的接口处理模块,满足PLB4的总线规范要求,可以接收、传输外部PLB4总线上的指令和数据,实现PLB主设备对DDR的访问。该从接口支持64/128位PLB主设备,支持的操作类型包括1~16字节单拍、4字、8字line操作和双字、4字突发的PLB访问[4-5]。其中MCIF2HIF模块,完成从PLB4接口到DDRC控制器核之间的命令和数据转换。
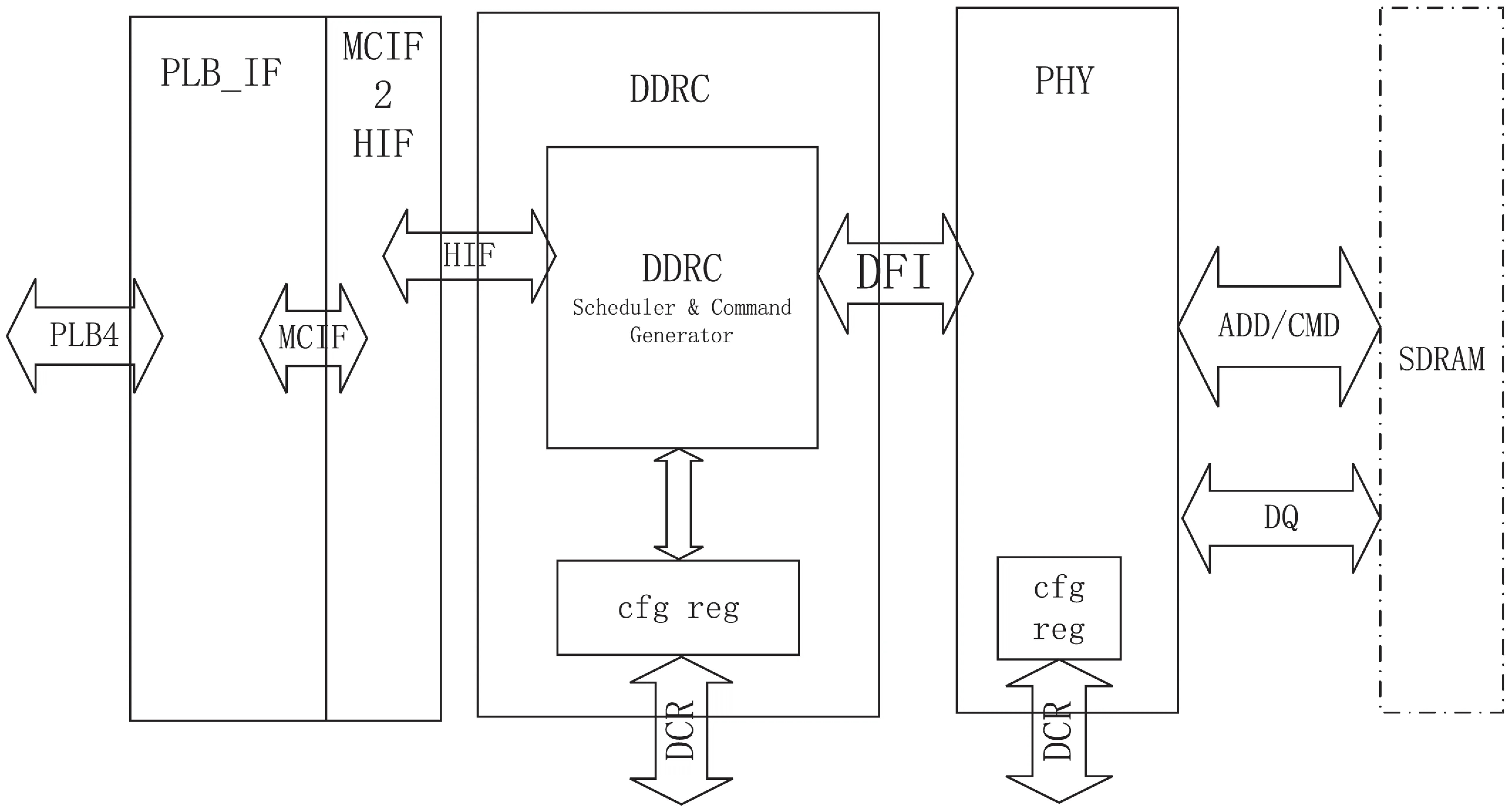
图1 总体结构
2 MCIF2HIF模块设计
由于PLB从接口后端为标准的MCIF接口,而DDRC控制器主机接口为HIF接口,需要该模块实现MCIF到HIF的数据率匹配、时序映射和转换功能。MCIF与HIF接口采用同步时钟,该模块的转换效率对访存效率影响很大,应尽量减少转换延迟。
2.1 接口时序
MCIF接口读、写操作时序如图2所示。
HIF接口的读、写时序如图3所示。
HIF在进行写操作时co_ih_rxcmd_valid有效同时写地址与写操作类型有效。ih_co_wdata_ptr_valid有效后表示读操作请求得到响应,然后可以发出写数据。写数据位宽为256位,一次写操作可以发出2个256位的写数据。co_wu_rxcmd_valid为高表示写入数据有效,同写数据一同发出的还有写掩码信号co_wu_rxdata_mask,用来表示传输的对应字节。ih_co_stall为高时表示系统忙,直到ih_co_stall变低之前系统无法响应新的请求[3]。

图2 MCIF接口时序
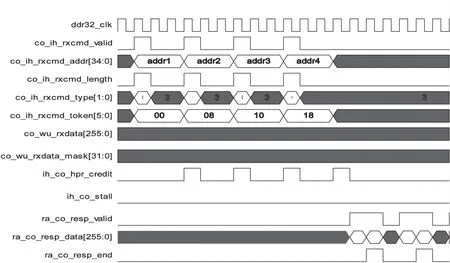
图3 HIF接口时序
HIF在进行读操作时co_ih_rxcmd_valid有效同时读操作地址与读操作类型有效。读token信号co_ih_rxcmd_token有效,ih_co_hpr_credit有效后表示读操作高优先级信用有效,然后可以发出写数据。读数据位宽为256位,一次读操作可以读出2个256位的读数据。ra_co_resp_valid为高表示读出数据有效,同读数据一同读出的还有读token信号ra_co_resp_token,用来表示读出数据的token信息[3]。
2.2 数据及控制通路设计
由于HIF接口数据线为256 bit,而MICF接口数据线为128 bit,因此在写操作时需要让MCIF接口尽量满负荷给PLB总线发送地址响应和请求写数据,并将写数据进行缓冲,对于读操作也需要对HIF返回的读数据进行缓冲。加快回地址响应的速度,可以让更多的PLB请求进来,并通过增加compaack_fifo与wr_addr_fifo,将进来的PLB请求和配套信息缓存,保证不要丢失请求及配置信息。由于PLB总线是地址和数据独立的,因此可以对写数据单独设计一个FIFO进行缓冲,与addr_fifo形成流水。
通过分析得出该模块需要使用4个FIFO:compaack_fifo、wr_addr_fifo、wr_data_fifo、rddata_fifo。compaack_fifo用于各个命令的调度、缓冲写请求并返回地址响应和写完成信号,可以将请求缓存并迅速接收下一条指令;wr_addr_fifo用于缓冲读写地址信息与操作指令信息,需要设计一个命令控制字调度状态机控制来自MCIF接口的命令控制字信息调度;wr_data_fifo用于缓冲写数据;rddata_fifo用于缓冲读数据。
通过读wr_addr_fifo,将其中的控制信息取出,同时,根据读出的控制信息适时地将wr_data_fifo中的写数据读出,通过判断HIF接口当前wr_addr_fifo的状态将写数据进行拼接并锁存。由于HIF写操作可能是256 bit或512 bit,当为256 bit时,HIF接口写操作为1拍,否则为2拍。HIF读操作均为2拍,即一次返回512 bit数据,这时由于DDRC控制器读操作仅支持BURST8操作,存储总线宽度为64 bit,所以每次读操作从HIF接口返回512 bit数据,转换逻辑需要根据控制信息从512 bit数据中适当的位置提取出正确的数据并按照预定的顺序返回给MCIF接口。控制信息的存储需要单独设计一个双口存储器,当发送HIF读数据请求时,将控制信息存储在该双口中,当HIF读数据返回后,需要读出双口中的控制信息,并根据控制信息取出相应位的数据返回给MCIF接口。
核心指令状态机转移图如图4所示。
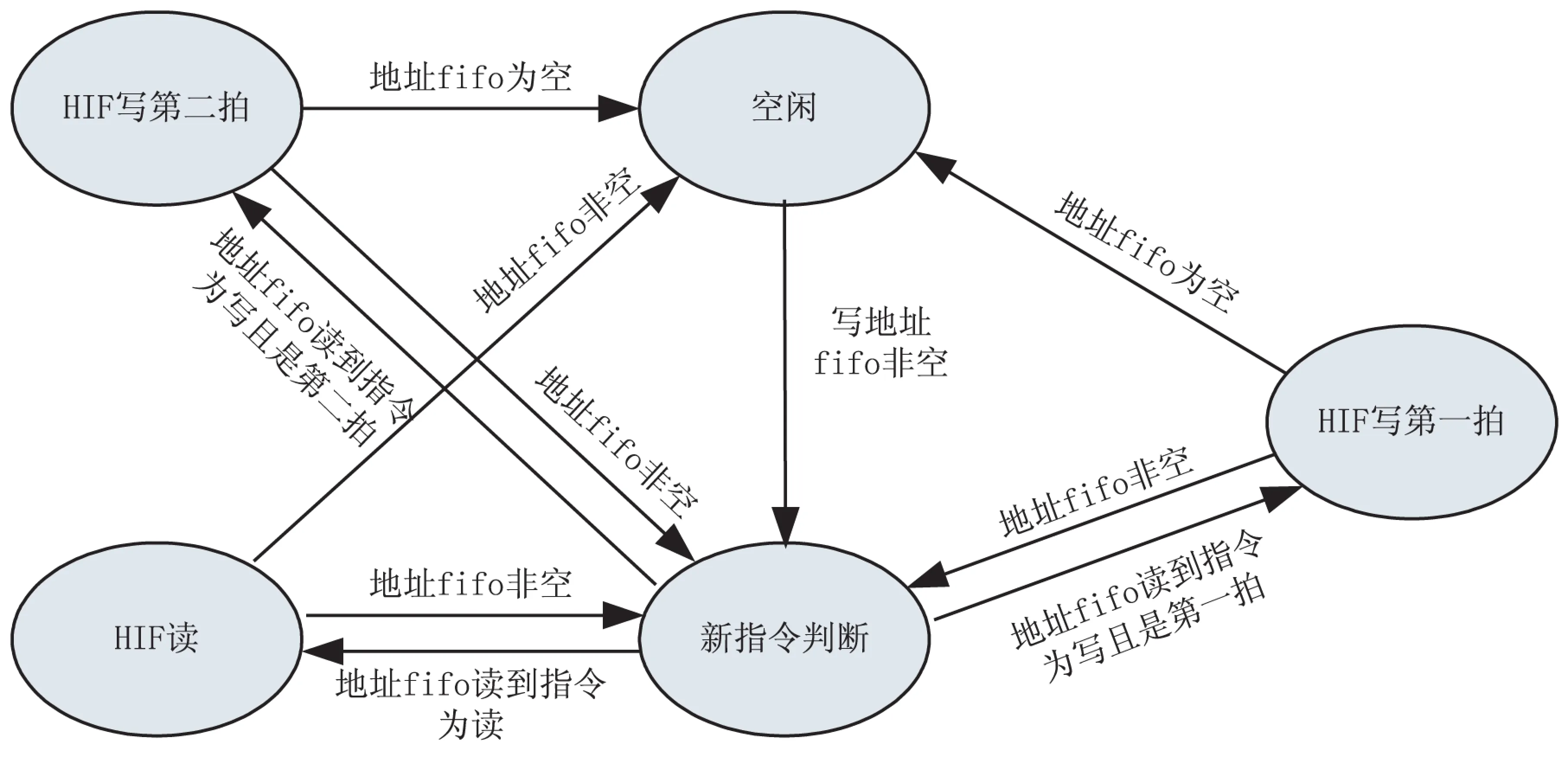
图4 核心指令状态机转移图
2.3 乱序处理设计
由于PLB4总线读操作不支持乱序[2],而DDRC是支持乱序的,即对HIF接口来说,由于每次HIF读请求需要对应一个token,而不同token的读请求返回给HIF接口的读数据可能是乱序返回的。因此,不能直接将HIF读数据返回给MCIF接口。
设计一个32位的flag寄存器和深度为32的双口存储器(先暂定为32深度,通过仿真评估后可能调整),根据HIF接口时序要求,当发送HIF读请求时,需要同时发送co_ih_rxcmd_token信号,简称为token信号。当控制指令状态机处于新指令判断状态时,将当前空闲的flag位的值赋给token,并将flag寄存器中对应位置1,flag采用从低位到高位依次顺序分配,但只有分配到31位,且flag[0]为0且已经被读走时,才能重新分配flag。否则等待flag空闲后再发送读请求。当DDRC返回读数据时,由于返回的读数据的token与之前发送的读请求的token是一致的,所以将返回数据的token作为双口存储器的地址,将对应数据写入双口中,并将flag清0。同时设计一个32位的dpram_flag寄存器,用来存储返回的token值。由于前面发送HIF读请求的token的顺序是确定的,因此期望返回的token的顺序也是确定的。当返回一个token时,将其对应数据写入双口的token值对应的地址中,同时将该token对应的dpram_flag置1,并将该token与期望返回的值比较,相等则下一拍将该笔数据从双口中取出返回给MCIF接口,并清除dpram_flag寄存器的对应位,否则,将期望值加1(当加到31时重新返回0),等待下一次返回读数据。直到期望值与后面返回的数据相等时,将该笔数据从双口中读出,从而保证返回给PLB总线的读数据的顺序。
另外,由于两笔HIF读数据返回间隔的不确定性,数据在通过双口读出后需要经过一个rddata_fifo缓存后输出到MCIF接口。设计功能结构图如图5所示。

图5 功能结构图
3 设计优化
3.1 对BURST操作的优化
由于BURST操作通常是带有连续性的,因此MCIF接口上相邻的两次读或写请求具有强相关性。可将其地址和控制信息进行合并,两次仅有一个入FIFO队列,从而提高效率和FIFO利用率。对于前面预判可合并,后面实际判断不能合并的,最终会分成两次请求入队[6-7]。
3.2 获取写数据的加速
如果上一步进来的PLB请求是写请求,则需要在回compaack之后向PLB从接口要写数据。首先对compaack_fifo和addr_fifo进行分工调整,由于compaack_fifo的最终目的是要写数据,因此只将写请求及配置信息入队compaack_fifo,而读请求不入队[8-9]。另外,通过对状态机进行优化,在回compaack同时向PLB接口发起写数据请求,并在将写数据缓冲到wrdata_fifo的同时,请求下一次的写数据,从而加速写数据的获取。这里写入wrdata_fifo的数据已经根据从compaack_fifo读出的信息,按照HIF接口的要求重组好,根据后面流程直接从wrdata_fifo读出后输出到HIF接口,实现零换乘,省去拼接和产生规定数据的时间[10-11]。
3.3 对读、写请求的优化
由于wr_addr_fifo作为该模块控制信息来源,存储了所有来自PLB4的总线请求及配套信息。控制调度核心命令状态机通过对该FIFO的读出信息来控制向HIF发送读、写请求及写数据。缩短两次读取wr_addr_fifo的间隔,对读操作,由于不需要数据,因此发完HIF读请求后,可以快速切换到下一次对wr_addr_fifo的读取状态。对于写操作,由于在发完HIF写请求之后,既要等待HIF接口的授权,又要等待写数据准备好。仿真发现此处延迟较大,若增加一个hif_wr_fifo,缓冲wr_addr_fifo的写控制信息,不用等待授权和写数据准备好,核心命令状态机就可转入下次读wr_addr_fifo状态。使HIF写命令和写数据流水,从而降低延迟[12-13]。
3.4 利用token进行速度和面积优化
co_ih_rxcmd_token信号是DDRC控制器中CAM存储器的地址,根据token发送和接收不会改变其值的特点,可以将控制信息通过token进行传递和回收。仿真发现,HIF接口最坏情况下,堵在双口中的读数据最多为4个,考虑设计余量,因此将双口深度调整为8,同时将flag和dpram_flag寄存器宽度也调整为8。由于HIF接口的co_ih_rxcmd_token信号宽度固定为6 bit,因此可以考虑将token低三位负责传递控制信息,高三位作为CAM和双口的地址,由于token分配方式一轮操作内不会重复(前一个不释放,后一个不会重用),因此CAM地址不会出现冲突。采用token为读请求来传递控制信息,可省去一个存储控制信息的双口存储器,同时将读数据双口及rddata_fifo深度均从32减为8,节省了面积,简化了逻辑设计,降低了双口读写延迟,避免双口两端同时写操作的冲突风险[14]。
4 仿真结果
仿真环境是在PLB总线及DDRC时钟均为200 MHz的情况下。将优化前与优化后的设计进行仿真,统计多种操作的访存延迟,结果如表1所示。

表1 优化前后比对表
5 结束语
文中论述了PLB4DDR3控制器的总体结构设计,重点研究了MCIF2HIF转换接口设计优化。仿真结果表明,优化后访存效率得到明显提升。文中对片上内存设计及优化具有一定参考价值。
[1] 王宏亮,毛永毅,张宏君.基于CoreConnect的OPB SPI接口设计与实现[J].测控技术,2013,32(5):72-76.
[2] IBM.128-bitprocessor local bus architecture specifications version 4.6[M/OL].[s.l.]:IBM Inc. Press.2004.http://www.chips.ibm.com.
[3] Design ware cores enhanced universal DDR memory controller databook[M].[s.l.]:Synopsys Press,2014:189-193.
[4] 陈超文,彭国杰,王忆文,等.基于PLB总线的NOR FLASH控制器设计[J].微电子学与计算机,2014,31(5):83-86.
[5] 卢 俊,颜 哲,田 泽.基于PLB双总线高速存储接口的设计与实现[J].计算机技术与发展,2015,25(4):233-237.
[6] 陈 卓,杨爱良,王 骥.基于PLB总线的多通道SGDMA设计[J].航空电子技术,2009,40(1):12-15.
[7] 吴从中,项 磊,蒋建国.基于PLB总线的H.264整数变换量化软核的设计[J].电子技术应用,2008,34(10):35-38.
[8] 苏 鹏,卞春江,张 磊.PowerPC处理器MPC8548E的DDR2接口实现[J].微计算机信息,2010,26(12-2):174-176.
[9] 刘宁宁,田 泽,裴希杰.基于CoreConnect总线的Nand Flash控制器设计[J].计算机应用,2014,34(S1):327-329.
[10] IBM.Device control register bus 3.5 architecture specifications[M].Armonk:IBM,2006.
[11] 马秦生,魏 翠,孙力军,等.嵌入式SoC总线分析与研究[J].中国集成电路,2007,16(3):45-49.
[12] 潘 波,杨根庆,孙 宁,等.基于多级片上总线的并行图像处理系统设计[J].计算机应用研究,2008,25(7):2208-2209.
[13] IBM Inc.Processor local bus functional model toolkit user’s manual version 4.7[M].[s.l.]:IBM Inc. Press,2002:214-215.
[14] Xilinx Inc.BFM simulation tutorial[EB/OL].2006-07-18.http://www.xilinx.com.
Design and Optimization of DDR3 Controller Based on PLB4 Bus
LI Zhe,TIAN Ze,WANG Shi-zhong,ZHENG Fei
(Aeronautics Science and Technology Key Laboratory of Integrate Circuit and Micro-system Design,AVIC Computing Technique Research Institute,Xi’an 710068,China)
Memory is the information storage component in computer systems.The message transmission speed between the master and the memory is the key factor to affect the system performance.PLB bus put forward by IBM is a embedded bus standard,which is used for the interconnection among masters,memory and other high-speed devices like PCIE,DMA,SRIO.It is wildly used in SoC design.This project takes DDR3 as a slave connected to the PLB4 bus,which has a host interface named HIF.So an high effective cross bus bridge logic is designed to interconnect each other and improve the memory access efficiency.A DDR3 controller solution based on the PLB4 bus interface is proposed,through analysis on the data and control flow,adopting the methods of request combination,multi-pipeline,data forecast,address and control information multiplexing,data reading out of order processing to optimize speed and size of the bridge logic which will influence the memory access delay.Simulation proves that after optimization the performance has been improved remarkably.
memory;performance;speed;size;optimization
2015-06-16
2015-09-22
时间:2016-03-04
中国航空科学基金(2015ZC51036)
李 哲(1985-),男,工程师,研究方向为集成电路设计;田 泽,博士,研究员,中航首席技术专家,研究方向为SoC设计、VLSI设计、嵌入式系统开发和应用。
http://www.cnki.net/kcms/detail/61.1450.TP.20160304.1508.006.html
TP39
A
1673-629X(2016)03-0181-04
10.3969/j.issn.1673-629X.2016.03.042
