改进的面向数据稀疏的协同过滤推荐算法
2016-02-23何聚厚
高 倩,何聚厚
(1.陕西师范大学 计算机科学学院,陕西 西安 710062;2.陕西师范大学 现代教学技术教育部重点实验室,陕西 西安 710062)
改进的面向数据稀疏的协同过滤推荐算法
高 倩1,何聚厚2
(1.陕西师范大学 计算机科学学院,陕西 西安 710062;2.陕西师范大学 现代教学技术教育部重点实验室,陕西 西安 710062)
用户相似性和最近邻集合是协同过滤算法中最重要的两个步骤。传统的协同过滤算法依靠用户评分计算用户相似性并寻找K个邻居作为最近邻的方法为用户产生推荐,但是在数据稀疏的情况下,仅仅依靠用户评分使得推荐效果不准确。针对以上问题,文中提出一种改进的面向数据稀疏的协同过滤推荐算法。该方法引入用户属性相似性和用户兴趣度相似性,并结合传统的用户评分相似性计算用户间的相似度,通过多次实验调整三者的权重,并且采用动态选取邻居集合的方法确定用户的最近邻,从而为用户推荐最合适的项目,增强了方法实用性,以此来缓解用户数据稀疏性问题。实验结果表明,文中方法能够充分利用用户的各类数据信息,提高了预测评分的准确性及推荐质量。
用户相似性;属性;兴趣;动态;数据稀疏性
0 引 言
在互联网越来越流行的今天,各种信息充斥着人们的生活。推荐系统随之产生,旨在帮助人们找到最有用的信息。基于用户的协同过滤推荐是在信息过滤和信息系统中一项很受欢迎的技术。其基本思想是根据用户-项目评分矩阵中已有的评分值,计算用户间的相似度,为目标用户或项目寻找最近邻,从而对未知的评分值进行估计[1]。由此可见,用户的相似度计算方法和邻居集的构造,对提高协同过滤推荐算法的推荐精度影响很大。目前的大部分协同过滤推荐算法,主要分为基于用户的协同过滤(User-Based CF)[2]、基于物品的协同过滤(Item-Based CF)[3]。然而不管是哪种方法,随着用户和项目数量的增多,都依然存在数据稀疏性问题,这种问题会导致推荐精度降低。
为此,文献[4]提出将Jaccard相似系数与传统的相似性方法结合起来计算用户之间的相似性,弥补了稀疏状况下的不足,但它依然只考虑了用户评分;文献[5]提出将用户兴趣相似性与传统的相似性方法相结合来计算用户间相似性,从两方面考虑了用户间的相似性,在一定程度上提高了推荐质量,但效果不明显;文献[6]提出了基于降维技术如奇异值分解(SVD)来解决数据稀疏性问题。该方法采用将用户-项目评分矩阵中无意义的评分删除的方法对矩阵降维,但是对奇异值分解过程很难控制;文献[7]提出综合项目评分相似性和项目分类相似性的方法,但推荐系统数据稀疏问题依然有待改善。
针对以上问题,文中考虑到用户选择商品与用户的属性特征和兴趣有很大关系,如用户的年龄、职业,兴趣等。提出一种新的相似性度量方法。引入用户属性相似度和用户兴趣相似度,并和用户评分相似度相结合,有效地改善了数据稀疏情况下的推荐质量。
1 改进的User-based协同过滤推荐算法
在推荐系统中,用户对所有产品的评价数据集包含用户集合U={U1,U2,…,Us}和项目集合I={I1,I2,…,It},用户对项目的所有评分取值构成了用户-项目评分矩阵R,例如用户Ux对项目Iy评分为Rxy。
1.1 用户相似度的改进
相似度计算是影响推荐质量的重要技术。传统的相似度计算方法[8]主要包括:余弦相似性、相关相似性和修正余弦相似性。通过在MovieLens[9]数据集上多次实验,发现修正余弦相似性的效果最好。因此文中算法是在修正余弦相似性的基础上,结合用户属性和用户兴趣度进行改进的。
1.1.1 用户评分相似性
由于用户对项目的评分是最直接反映用户对项目喜好程度的指标,所以实验采用修正余弦相似性对用户间评分相似性进行计算。用户间的评分相似性simr(x,y)为:
simr(x,y)=
(1)

1.1.2 用户属性相似性
用户数量较多的时候,并不是每个用户都会对项目有评分,即数据稀疏的情况下,仅使用项目评分来判断用户的相似性未免过单一。由于每个用户都包含一定的属性,包括性别、职业、地址、年龄等,在选择项目时,这些属性对用户的选择和喜好会有一定的影响。
假设用户的属性特征个数为n,则用户x的属性特征集合为Cx={Cx1,Cx2,…,Cxn},其中Cxn表示用户x的第n个属性特征。然后,要对用户的属性特征进行量化。例如,对用户的性别进行量化:性别为男的量化值为1,性别为女的量化值为0;对年龄进行量化:量化值为0~9,其中,令0~10岁=0,10~20岁=1等等。最后将所有用户的属性特征进行量化后就构成了用户-属性矩阵[10]。由上述得出的用户属性矩阵C表示为:
其中:s行代表s个用户;n列代表每个用户有n个属性;Cxa代表用户x的第a个属性量化值。
假设用户x和用户y的第a个属性值相同,认为Cxa∩Cya=1,否则Cxa∩Cya=0。则用户x和用户y的属性相似度simc(x,y)[11]为:
simc(x,y)=α*Cx1∩Cy1+β*Cx2∩Cy2+…+γ*Cxn∩Cyn
(2)
其中,α,β,…,γ为权重因子,并且α+β+…+γ=1。
1.1.3 用户兴趣相似性
一般来说,某一类项目被用户评价的次数越多,证明用户对这类项目越感兴趣。假设项目种类数目为x,由用户-项目评分矩阵可计算得出用户-项目种类评分数目矩阵N:
其中:s行代表用户数目;k列代表项目种类数;Nsk代表用户s评价过k类项目的数目。
实验中设定k=19,即19种不同的项目种类。
用户对某类项目的兴趣度可表示为:
(3)
其中:Nxi表示用户x对a类项目的评价总数;Nx表示用户x的评价总数。
则两个用户的兴趣相似度[5]为:
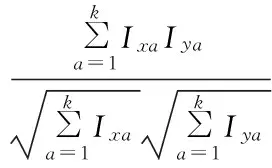
(4)
其中:n为项目的种类数;Ixa表示用户x对a类项目的兴趣度。
1.1.4 用户整体相似性
实验采用用户评分相似度、用户属性相似度和用户兴趣相似度结合的方法得到用户间整体相似度,即:
sim(x,y)=μ*simr(s,y)+ρ*simc(x,y)+τ*simn(x,y)
(5)
其中,μ,ρ,τ分别为权重因子,μ+ρ+τ=1。
1.2 最近邻选取
传统的协同过滤算法选取k个邻居用户组成最近邻集合,但是在数据稀疏的情况下,可能并没有k个与目标用户很相似的邻居,这样就会产生不准确的最近邻集合,因此会导致推荐结果的不准确。
定义1 邻居候选集合C给定推荐目标用户Ux,如果评分矩阵中∃Ux∈U,使得Rx∩Ry≠∅,那么用户y就为目标用户x的候选用户,候选集合Cx表示为:
实验采用动态选取邻居集合的方法,在为目标用户x选取最近邻的过程中,需要选定一个相似度阈值[12]simε(x),表示为:
(6)
其中:sim(x,y)表示目标用户x与候选用户y的相似度;Cx表示目标用户x的候选集合。
因此,目标用户x的最近邻集合表示为:
Sx={y|sim(x,y)>simε(x),y∈Cx}
(7)
1.3 产生推荐
通过文中提出的相似度改进方法,结合动态选取最近邻集合,根据式(5)可计算出用户间的相似度,根据式(7)可得出目标用户的最近邻集合,进而产生推荐。具体过程如下:
输入:用户-项目评分矩阵、用户属性矩阵、项目属性矩阵;
输出:推荐项目集。
Step1:根据用户评分矩阵和项目属性矩阵,计算得出用户-项目种类评分数目矩阵N。
Step2:计算用户相似度矩阵。分别用式(1)、式(2)和式(4)计算出用户评分相似度、用户属性相似度和用户兴趣相似度,选取一定的权重因子,根据式(5),计算出用户相似度矩阵sim。
Step3:最近邻选取。采用动态选取邻居集合的方法,根据式(7),找出目标用户的最近邻集合S。
Step4:产生推荐。根据用户评分矩阵R,目标用户的最近邻集合S,可计算出目标用户x对目标项目a的预测评分[13]Pxa:
(8)

2 实验设计与分析
2.1 数据集
选取的数据集为MovieLens数据集,其中包含三种规模的数据集,每种规模都包含用户评分数据、用户信息数据以及电影的属性数据。参数如表1所示。

表1 三种规模数据集
实验选择用户数为943的数据集,其中一个用户至少对20部电影进行了评价,评分范围为[1,5],然后将数据集分成了80%的训练集和20%的测试集。
2.2 度量标准
实验采用平均绝对偏差(MAE)作为度量标准,MAE越小说明评价质量越高。MAE[3]的计算公式为:
(9)
其中:Pi表示用户预测评分;Qi表示用户实际评分;N表示总的评分数目。
2.3 实验结果
2.3.1 用户属性相似性的权重因子的测定
根据MovieLens提供的用户属性信息,提取用户的性别、年龄、职业、邮编四种信息进行量化,将量化后的用户属性矩阵加入到实验中,判断各特征属性的重要性。此时用户相似性使用单一的用户属性相似性,结果如图1所示。

图1 各属性对MAE值的影响
由图1可以看出,性别属性对预测结果影响最大,其次分别是年龄、职业、邮编。经过反复实验,具体的权重因子设定如表2所示。

表2 权重因子设定
2.3.2 各相似性权重因子的测定
将用户评分相似性矩阵、用户属性相似性矩阵和用户兴趣度矩阵计算出来之后,需要设定不同的权重来表示它们的重要程度,结果如图2所示。
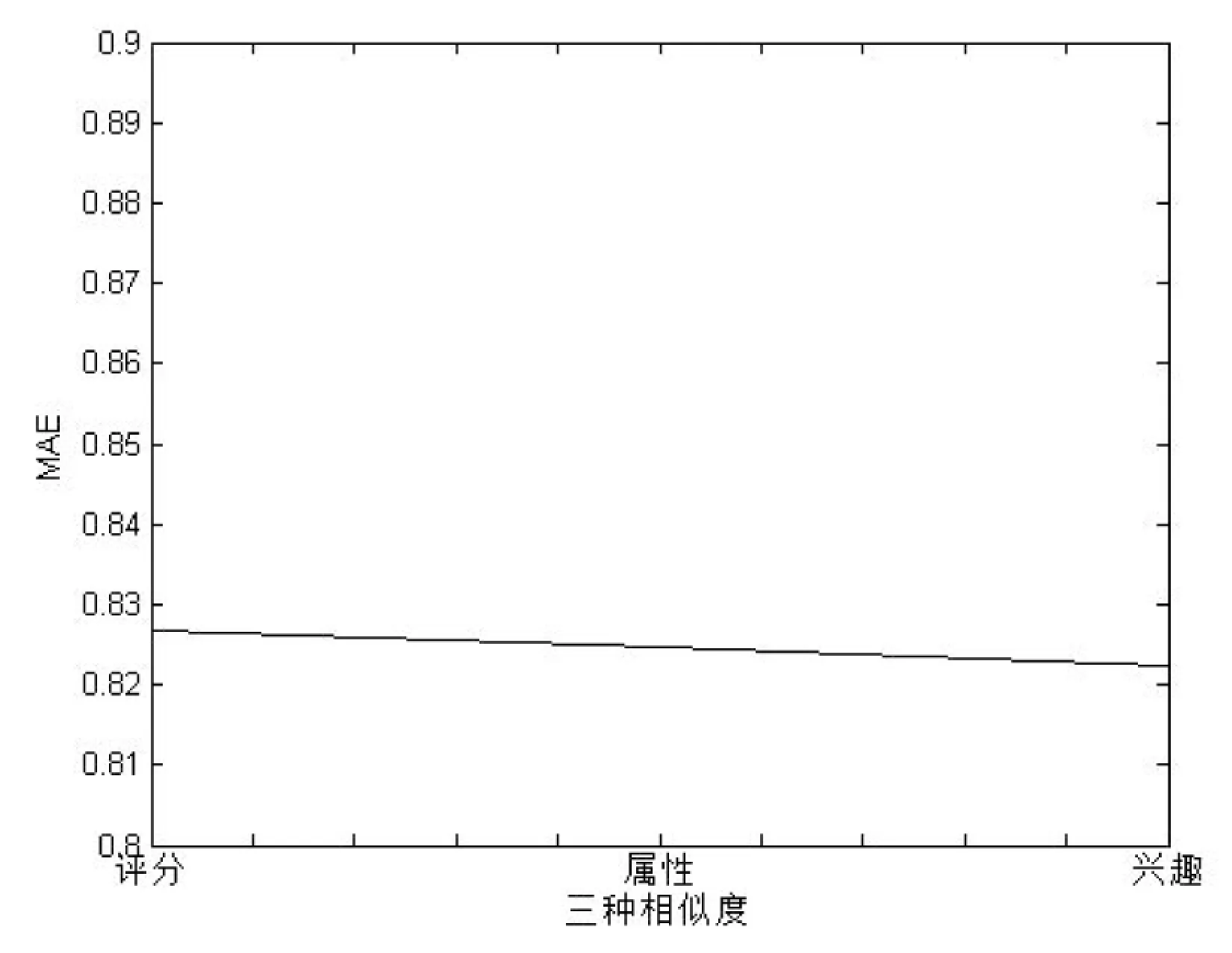
图2 三种相似度对MAE的影响
由图2可以看出,用户兴趣度相似性对预测结果影响最大,其次是用户属性相似性和用户评分相似性。经过反复实验,将用户兴趣度相似性的权重设定为0.55,用户评分相似性设定为0.15,用户属性相似性设定为0.3,这样可以使预测结果MAE达到最小。
为了检验文中实验的有效性,采用传统的基于用户的协同过滤推荐算法(UCF)和文献[5]提出的方法作为对照,邻居个数从5开始递增到30,间隔为5,然后与文中提出的方法进行对比。实验结果见图3。

图3 三种推荐效果对比
从图3可以看出,在邻居个数不同的情况下,文中提出的算法相比UCF和文献[5]提出的方法,都能取得更好的推荐质量。并且不会受到邻居个数的影响,从而具有更好的通用性。
3 结束语
文中提出的方法与传统的协同过滤算法最大的不同在于,考虑到数据稀疏情况下,用户评分相似性的不准确,从而加入用户属性相似性和用户兴趣相似性,并且采用动态选取邻居集合的方法,避免了没有推荐能力的用户加入到最近邻集合中,有效地改善了用户评分稀疏的不足。实验结果表明,该方法具有一定的改进效果。
[1] 桑治平,何聚厚.基于Hadoop的多特征协同过滤算法研究[J].计算机应用研究,2014,31(12):3621-3624.
[2] Resnick P,Iacovou N,Suchak M,et al.GroupLens:an open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM conference on computer supported cooperative work.[s.l.]:ACM,1994:175-186.
[3] Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th international conference on World Wide Web.[s.l.]:ACM,2001:285-295.
[4] Adomavicius G, Tuzhilin A. Towards the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
[5] 嵇晓声,刘宴兵,罗来明.协同过滤中基于用户兴趣度的相似性度量方法[J].计算机应用,2010,30(10):2618-2620.
[6] Billsus D,Pazzani M.Learning collaborative information filters[C]//Proceedings of the 15th international conference on machine learning.[s.l.]:[s.n.],1998.
[7] Zhou K.Combining item rating similarity and item classification similarity for better recommendation quality[J].Advanced Materials Research,2012,461:289-292.
[8] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[9] Miller B N,Albert I,Lam S K,et al.MovieLens unplugged:experiences with occasionally connected recommender system[C]//Proceedings of the 8th international conference on intelligent user interfaces.New York:ACM,2003:263-266.
[10] 刘 聪,张 璇,王黎霞,等.改进的基于用户数据的协同过滤推荐方法[J].计算机应用与软件,2014,31(8):245-248.
[11] 李鹏飞,吴为民.基于混合模型推荐算法的优化[J].计算机科学,2014,41(2):68-71.
[12] 黄创光,印 鉴,汪 静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[13] 许海玲,吴 潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
An Improved Collaborative Filtering Recommendation Algorithm for Data Sparsity
GAO Qian1,HE Ju-hou2
(1.School of Computer Science,Shaanxi Normal University,Xi’ an 710062,China;2.Key Laboratory of Modern Teaching Technology of Ministry of Education,Shaanxi Normal University,Xi’ an 710062,China)
User similarity and nearest neighbor set is two important steps in acollaborative filtering algorithm.The traditional Collaborative Filtering (CF) computes user similarity only relying on user rating and findsKneighborsasnearestneighbortoproducerecommendationforusers,butinthecaseofsparsedata,onlyrelyingonuserratingcalculationmakestherecommendationeffectinaccurate.Tosolvetheproblems,animprovedcollaborativefilteringrecommendationalgorithmfordatasparsityisproposed,whichintroducesthesimilarityofuserattributesanduserinterest,combinedwithtraditionaluserratingsimilaritytocomputesimilaritybetweenusers.Theweightsofthreeisadjustedthroughseveralexperiments,andthedynamicmethodisusedtosearchtheuser’snearestneighbortorecommendsuitableitemsforusers,inordertoalleviateuserdatasparsityproblem.Experimentalresultsshowthatthismethodcanmakefulluseofallkindsofusers’datainformation,improvingtheaccuracyofpredictedratingsandqualityofrecommendation.
user similarity;attribute;interest;dynamic;data sparsity
2015-06-28
2015-09-30
时间:2016-02-18
中央高校基本科研业务费专项资金资助项目(GK201002028,GK201101001);陕西师范大学学习科学交叉学科培育计划资助项目
高 倩(1990-),女,硕士研究生,研究方向为知识工程与智能教学系统;何聚厚,博士,副教授,研究方向为知识工程与智能系统。
http://www.cnki.net/kcms/detail/61.1450.TP.20160218.1636.074.html
TP
A
1673-629X(2016)03-0063-04
10.3969/j.issn.1673-629X.2016.03.015
