利用Pittsburgh遗传算法优化模糊规则的网络入侵检测
2016-02-23栾玉飞赵旭东亚森艾则孜
栾玉飞,赵旭东,亚森·艾则孜
利用Pittsburgh遗传算法优化模糊规则的网络入侵检测
栾玉飞,赵旭东,亚森·艾则孜
针对计算机网络中安全性问题,提出了一种融合模糊规则和Pittsburgh型遗传算法的网络入侵检测方案。首先,通过一种启发式过程来确定每个模糊if-then规则后件类和确定性分数。然后,利用Pittsburgh型遗传算法,通过交叉和变异操作来进化模糊系统的规则,产生高分类率的模糊规则。最后,通过协同进化后的模糊系统实现入侵检测。在DARPA数据集上进行实验,结果表明该方案能够精确的检测U2R、R2L、DoS和PRB类网络攻击,具有很高的安全性。
网络入侵检测;模糊规则;Pittsburgh型遗传算法;规则优化
0 引言
当前计算机网络尽管具有多重安全策略,譬如,访问控制、加密以及防火墙的应用,然而,网络安全的漏洞还是与日俱增。因此,迫切需要智能的入侵检测系统(Intrusion Detection System,IDS)来自动地检测新型的入侵行为[1]。
目前,主要有两种入侵检测方法:误用检测和异常检测。误用检测的检测速度快、误报警率低,但其只能检测出数据中已知的入侵模式,无法检测新出现的入侵行为,且需要实时的更新数据库[2]。异常检测系统能够检测出新的入侵行为,但通常具有较高的误报警率[3]。基于模糊if-then规则[4]的模糊系统在很多应用领域已得到成功应用。为此,学者们也提出了多种基于模糊系统的IDS,例如,文献[5]提出一种基于模糊规则学习模型的入侵检测方案,创建了基于权重的模糊检测规则,并引入一种反馈学习算法,用于对检测规则的改进。文献[6]提出一种基于模糊关联规则挖掘的入侵检测方案,实现了从数据集属性到模糊映射的过程,并利用K-means聚类算法为量化属性建立模糊集合和模糊隶属函数,增强关联规则的客观性。
一般情况下,若模糊模型的精确性较高,其解释性相对较差。而具备较高解释性的模糊模型,其精确性又较低[7]。精确性与解释性较好折衷的模糊模型,具有简单的结构和较少的参数,运算量低,泛化能力强。由于模糊逻辑的知识表达能力与进化计算的全局自学习能力可以互补[8]。所以,可引用进化计算来改进模糊系统。其中,遗传算法是进化计算理论体系中最具代表性的算法,因此可形成一种有效的遗传模糊系统。
本文基于遗传模糊系统的思想,提出一种融合模糊规则和Pittsburgh型遗传算法的网络入侵检测系统。首先,通过一种启发式过程来确定每个模糊if-then规则后件类和确定性分数。然后,利用Pittsburgh型遗传算法进化模糊系统的规则,进行协同进化,最终通过模糊规则实现入侵检测。实验结果表明,本文方案能够精确的检测网络攻击。
1 基于模糊规则的模式分类
1.1 模糊规则分类
本文假设模式分类问题为具有连续属性的n-维模式空间中的c-类问题。同时还假设给定m个实向量并将其作为来自c个类的训练模式c≤m。
由于模式空间为[0,1]n,所以每种模式的属性值为在本文中,将每个数据集的属性值规范化到单位区间[0,1]。
本文提出的模糊分类器系统中,使用如下形式的if-then规则。
其中,Rj为第j个if-then规则的标签,Aji,K,Ajn为单位区间[0,1]上的前件模糊集,Cj为后件类(即给定C类中的一类),CFj为模糊if-then规则Rj的确定性分数。本文将一组典型的语言值用作图1中的前件模糊集,并通过把每种属性域划分为对称的三角模糊集,明确图1中每个语言值的隶属函数。值得注意的是,对于特定模式分类问题,本文在模糊分类系统中可以使用任何定制的隶属度函数,如图1所示:
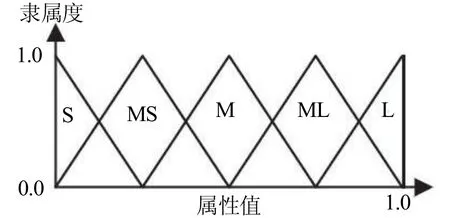
图1 五个语言值的隶属度函数(S:小,MS:中小,M:中,ML:中大,L:大)
在n维模式分类问题中,模糊if-then规则的总数为5n。当属性的数量(即n)很大时(如n=41的入侵检测问题),有可能在单模糊规则库中使用所有5n个模糊if-then规则。
本文模糊分类系统搜索相对数量较小的具有高分类能力的模糊if-then规则(如100个规则)。由于每个模糊if-then规则的后件类和确定性分数可以通过简单的启发式过程从训练模式中确定,所以本文模糊分类系统的任务是,为一个模糊if-then规则集生成前件模糊集的组合。然而,该任务对于高维模式分类器问题来说是很难的,因为搜寻空间涉及5n个组合(如在n=13时,多于1 000万个)。
为此,在本文模糊分类器系统中,通过利用启发式过程来确定每个模糊if-then后件类Ci和确定性分数CFj。步骤如下描述。
1.2 Ci和CFj的确定
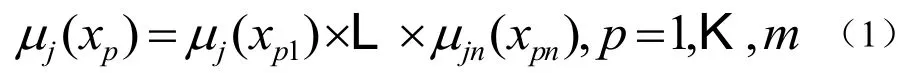
步骤2:对于每个类,计算具有模糊if-then规则Rj的训练模式的兼容性分数为式(2):
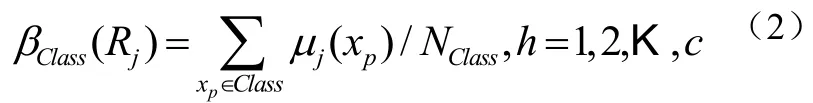
上式中,βClass(Rj)为类h中具有模糊if-then规则Rj的训练模式的兼容性分数总和。NClass为对应类为h的训练模式的数量。
步骤3:找出具有最大βClassh(Rj)值的类ˆj为式(3):
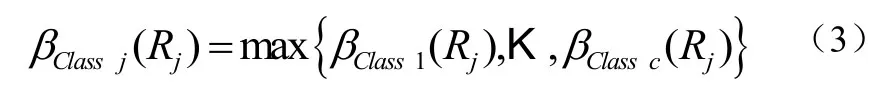
如果两个或更多的类具有最大值,则不能确定唯一模糊if-then规则的后件类Cj。在这种情况下,令Cj为φ。如果没有与模糊if-then规则Rj相配的训练模式(即,对于则还将后件类Cj指定为φ。
步骤4:如果后件类Cj为φ,则令模糊if-then规则Rj的确定性分数CFj=0。否则,用以下公式计算确定性分数CFj为式(4)、(5):

通过本文提出的启发式过程,可以指定任意前件模糊集组合的后件类和确定性分数。
本文模糊分类器系统的任务是生成前件模糊集的组合,用以生成具有高分类能力的规则集S。然后,通过S中的单优先规则来分类,其确定如为式(6):
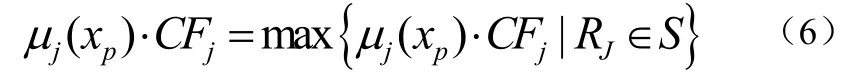
也就是说,优先原则选出具有最大兼容性和确定性分数CFj。如果不存在与输入的模式一致的模糊规则(即,对于则拒绝分类。
本文中,将每个模糊if-then规则编码为字符串。利用下面的符号来表示五个语言值:1:小;2:中小;3:中;4:中大,5:大。例如,若模糊if-then规则被编码为—1342”,即x1为小,x2为中,x3为中大,x4为中小,则类cj满足CF=CFj。
入侵检测是一个高维度的分类问题,在该问题中,将41维的特征向量作为输入,将5个类作为其输出。所以在本文中,种群中和每个规则集中的所有规则的类标签都相同。因此,在分类问题中,对于每个类重复遗传模糊规则生成算法。
本文目标分类器由c个分类器组成。每个分类器独立发展,将获得的模糊规则集组合用于最终分类器系统的结构中。目标分类器的结构如图2所示:
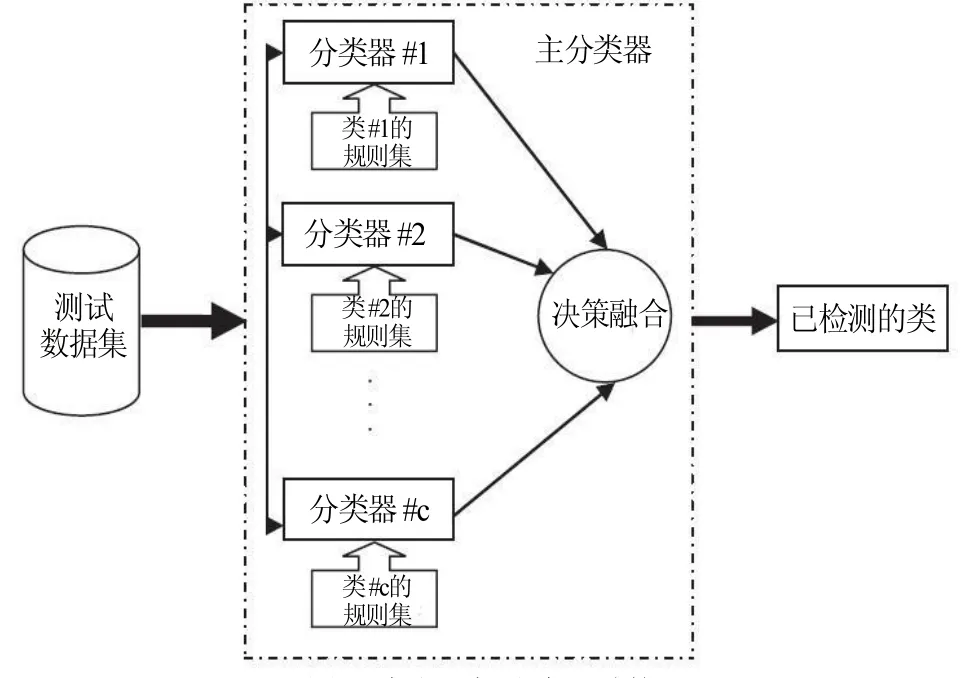
图2 本文目标分类器结构
2 Pittsburgh遗传算法优化模糊规则
Pittsburgh型遗传算法[9]中,每一条染色体代表一个完整的模糊模型,种群中多个染色体形成多个待选择的模糊模型,交叉与变异操作产生新的模糊模型,基于适应度函数的选择操作使较优的模糊模型能够产生下一代个体。因为染色体的适应度值即代表着染色体的优劣,,所以Rttsburgh型遗传算法不需要适应度函数的权值分配策略[10]。
本文提出一种融合Pittsburgh型遗传算法和模糊系统的入侵检测方案,其算法的执行步骤如下:
步骤1(初始化):生成模糊规则集的原始群体。步骤2(遗传操作):通过遗传操作生成模糊规则集。步骤3(替换):利用新生成的规则集替换一部分当前群体。
步骤4(终止):如果满足停止条件,则终止该算法,否则,回到步骤2。
该模糊分类器系统的每个步骤详细描述如下:
步骤1 初始化
初始化步骤中,根据直接规则生成方法产生每个规则集中的每条规则,生成Nset规则集。根据方程(7)计算每个规则集的适用度为式(7):
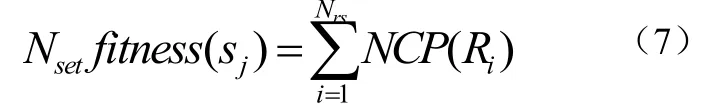
上式中,sj为群体中的第j个规则集,Nrs为每个规则集中的规则数,NCP(Ri)为被Ri正确分类的训练模式的数量。
步骤2 遗传操作
基于方程(8)所示的选择概率,从当前群体中选择一对模糊规则集,以生成下一个群体的新模糊规则为式(8):
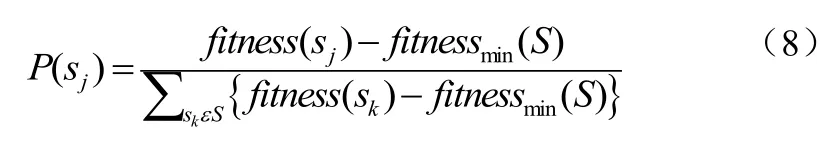
上式中,fitnessmin(S)为群体中模糊规则的最小适应度值。迭代该过程直到选出模糊规则集的预设数。
为了从每对所选的规则集中生成新的规则集,本文以交叉概率Pc执行单点交叉操作,其中,交叉截止点是随机确定的,且父代和子代的强度相同,如图3所示:
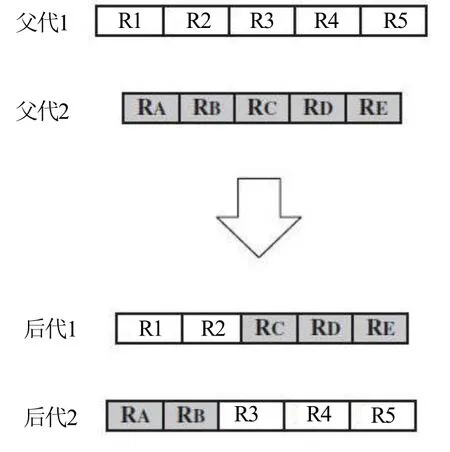
图3 单点交叉示意图
执行交叉操作到每对都有一个预设的交叉概率。当交叉操作结束时,将父代的字符串选作为后代。
利用Michigan型变异算法,执行变异操作来修正每个生成的规则集,其中变异概率为Pm。在执行完变异操作之后,确定变异个体的后件类。如果该后件类与变异操作之前的个体的类相同,则接受变异个体;否则,重复变异操作直到预设的迭代数Mrepeat。在执行完选择、交叉和变异步骤之后,根据方程(7)评估每个生成个体的适应度值。
步骤3.替换
利用新生成的规则替换当前种群中预设数目的模糊if-then规则,替换概率为PrepR。即,在本文模糊分类器系统中,从当前种群中移除百分之PrepR具有最小适应度值的较差规则。并添加具有百分之新生成的模糊if-then规则(PrepR为替换百分比)。
步骤4.终止
当Pittsburgh遗传模糊分类算法迭代次数达到预先设定的最大遗传代数时,停止迭代过程。
3 实验及分析
3.1 实验环境
本文在2.95 GHz Intel i3酷睿双核处理器和4GB RAM的Windows 7系统上进行实验。
实验从KDDCup99随机选择10%作为标准数据集,KDDCup99提取自1998 DARPA入侵检测评价程序,这个数据库包括军用网络环境中仿真的各种入侵,常用作评价入侵检测技术的基准。该数据集有41个特征,每个记录加一个包含23个攻击的类标签,其已经标记为正常或攻击。其中,恶意攻击包含四种类别分别为:探测(PRB)攻击、拒绝服务(DoS)攻击、非法远程闯(R2L)攻击和非法提升权限(U2R)攻击。将实验数据分成两部分:训练数据和测试数据,分别涉及大约25000和27000条数据。训练数据用来根据目标问题中给定的规则产生模型,接下来该模型将用于测试数据,以获得验证精度。
在本文提出的基于遗传模糊系统的IDS中,设定遗传算法所使用的参数如下:种群大小为20;交叉概率(Pc)为0.9;变异概率(Pm)为0.1;变异迭代数(Mrepeat)为20;替代率(PrepR)为20;最大遗传代数为20。
3.2 性能指标
规则在测试阶段执行的好坏取决于分类精度测量的可靠性。一般情况下,标准分类准确率可以写为式(9):

然而,大多数非线性分类问题的类分布极不平衡。因此式(9)不能有效的测量模型的准确率。因此本文采用新的评估指标,具体形式如式(10):
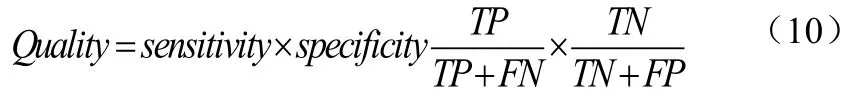
式(10)中:
(1)真阳性(TP):拥有由规则预测的类的规则覆盖实例数。
(2)假阳性(FP):拥有不同于由规则预测类的规则覆盖实例数。
(3)真阴性(TN):拥有不同于由规则预测类的规则不覆盖实例数。
(4)假阴性(FN):拥有由规则预测类的规则不覆盖实例数。
3.3 性能比较
首先,将本文方案应用到测试集上,验证本文方案的性能。本文方案在测试集上的实验结果如表1所示:
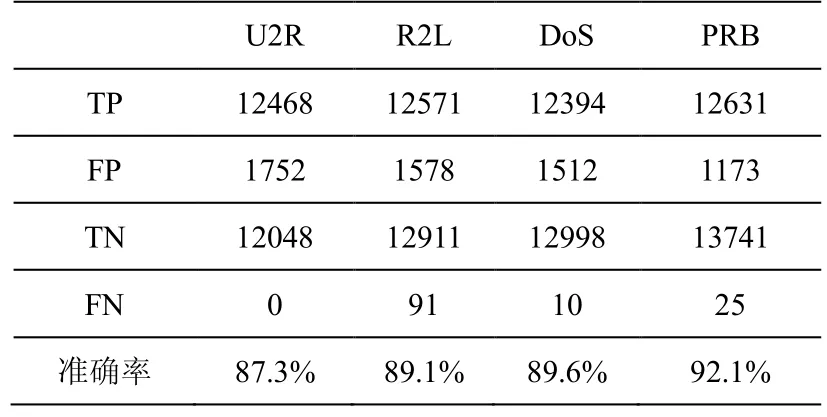
表1 本文算法在测试集上的实验结果
为了更好地体现本文所提方案的优越性,将本文所提方案与其它几种较为先进的方法在各个数据集上的实验结果进行了比较,包括文献[5]提出的基于模糊规则学习的入侵检测方案和文献[6]提出的模糊关联规则+K-means的入侵检测方案。列出了各种方案的比较结果如表2所示:
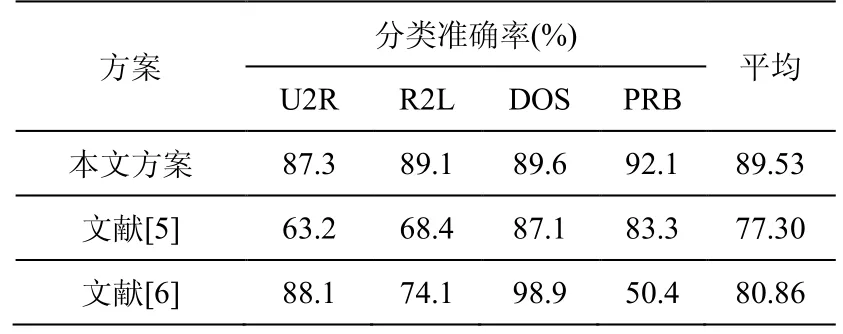
表2 各种IDS的入侵检测分类准确率比较
可以看出,本文IDS的在R2L和PRB类的分类率明显高于其他方案,整体准确分类率也远远高于其它方案,分别比文献[5]和文献[6]方案性能提高了12.3%和8.67%。这是因为本文使用的基于遗传模糊系统的IDS比其他方法更可靠。
4 总结
本文提出一种融合模糊规则和Pittsburgh型遗传算法的网络入侵检测方案。通过一种启发式过程来确定每个模糊if-then规则后件类和确定性分数。利用Pittsburgh型遗传算法协同进化模糊系统的规则。实验表明,本文方法对U2R、R2L、DoS和PRB类攻击的整体检测率达到了89.53%,具有很高的性能。
在今后工作中,将考虑使用多目标演化模糊系统来提取一个易于理解的模糊分类器,进一步提高本文IDS性能。
[1] 肖寅东, 王厚军, 田书林. 高速网络入侵检测系统中包头解析方法[J]. 仪器仪表学报, 2012, 33(6): 1414-1419.
[2] 高苗粉, 秦勇, 李勇,等. 网络入侵检测系统自体集检测中的概率匹配高效寻优机制[J]. 计算机应用, 2013, 33(1): 156-159.
[3] Elngar A A, Elanda[A], Ghaleb F M. A real-time anomaly network intrusion detection system with high accuracy[J]. Information Sciences Letters, 2013, 35(3): 49-56.
[4] 李晶皎, 许哲万, 王爱侠,等. 基于移动模糊推理的DoS攻击检测方法[J]. 东北大学学报:自然科学版, 2012, 33(10): 1394-1398.
[5] Elhag S, Fernández A, Bawakid A, et al. On the combination of genetic fuzzy systems and pairwise learning for improving detection rates on intrusion detection systems[J]. Expert Systems with Applications, 2015, 42(1): 193-202.
[6] Khamphakdee N, Benjamas N, Saiyod S. Improving intrusion detection system based on snort rules for network probe attacks detection with association rules technique of data mining[J]. Journal of Ict Research & Applications, 2015, 8(3): 234-250.
[7] 周豫苹, 方建安. 神经模糊理论在入侵检测系统中的应用研究[J]. 微电子学与计算机, 2010, 27(9): 126-129. [8] 李晶皎, 许哲万, 王爱侠,等. 基于移动模糊推理的DoS攻击检测方法[J]. 东北大学学报:自然科学版, 2012, 33(10): 1394-1398.
[9] Mehta S B, Chaudhury S, Bhattacharyya A, et al. Tissue classification in magnetic resonance images through the hybrid approach of Pittsburgh and Pittsburg genetic algorithm.[J]. Applied Soft Computing, 2011, 11(4): 3476-3484.
[10] Li W, Gong Z. Pittsburgh-based variable-length encoding of genetic algorithm for k-anonymization[C]// Information Science and Engineering (ICISE), 2010 2nd International Conference on. 2010: 1295-1298.
A Network Intrusion Detection Schemer Based on Fuzzy Rule with Genetic Algorithm Optimization
Luan Yufei, Zhao Xudong, Yasen·Aizezi
(Xinjiang Police College, Urumqi 830011, China)
For the issue of the security problem of computer network, a network intrusion detection schemer based on fuzzy rule and Pittsburgh genetic algorithm is proposed. Firstly, a heuristic procedure is set to determine the consequent class and the certainty score of each fuzzy if-then rule. Then, the rules of fuzzy system are evolved by crossover and mutation operations of the Pittsburgh genetic algorithm, to generate the fuzzy rules of high classification rate. Finally, the intrusion detection is realized by the fuzzy system after cooperative evolved. Experiments on DARPA data sets show that the proposed scheme can accurately detect U2R, R2L, DoS and PRB attacks, and has high security.
Network intrusion detection; Fuzzy rule; Pittsburgh genetic algorithm; Rules optimization
TP393
A
1007-757X(2016)10-0022-04
2016.01.22)
新疆维吾尔自治区自然科学基金科研项目(2015211A016)
栾玉飞(1982-),男,新疆人,新疆警察学院,讲师,硕士,研究领域:计算机网络、信息安全等,乌鲁木齐 830013
赵旭东(1977-),男,安徽芜湖人,新疆警察学院,讲师,硕士,研究领域:信息安全、软件工程等,乌鲁木齐 830013
亚森·艾则孜(1975-),男,新疆库车人,新疆警察学院,教授,硕士,国家电子数据司法鉴定员,研究领域:信息安全、自然语言处理等,乌鲁木齐 830013
