融合直推式学习和语义理解的词语倾向性识别
2016-02-23赵君喆焦翠珍戴文华
闻 彬,饶 彬,赵君喆,焦翠珍,戴文华
(湖北科技学院 计算机科学与技术学院,湖北 咸宁 437100)
融合直推式学习和语义理解的词语倾向性识别
闻 彬,饶 彬,赵君喆,焦翠珍,戴文华
(湖北科技学院 计算机科学与技术学院,湖北 咸宁 437100)
目前词语情感倾向性识别研究主要分为机器学习和语义理解,机器学习不能很好地识别通用领域词语,语义理解又存在准确率和召回率不够高的问题,因此文中提出了一种融合直推式学习和语义理解的词语倾向性识别方法。首先对HowNet知识库体系进行改进,在已有的四种义原的基础上,提出第五义原—情感义原;然后将第五义原手工融入到HowNet知识库中,再在此基础上提出词语情感相似度计算方法计算词语的情感值;最后将该方法融合直推式学习以判定词语情感倾向性。通过实验结果表明,与支持向量机和原语义理解方法相比,该方法在识别情感词上取得了较好的效果。
词语倾向性识别;机器学习;语义理解;意见挖掘;情感义原;HowNet
1 概 述
由于越来越多用户乐于在互联网上分享自己的观点和意见,使得互联网中这类信息迅速膨胀,仅靠传统的人工方法难以有效及时地获取网上的海量信息,更难以提供准确的分析和处理,因此,迫切需要相关的自然语言处理技术来处理这些相关的评价信息。意见挖掘技术在此背景下应运而生,并引起了广泛的关注。
意见挖掘的目的是发现文本中作者所持有的主观态度,为产品推荐、舆情监控和观点抽取等提供支持。现有的意见挖掘技术主要分为基于语义理解的和基于机器学习的。其中基于机器学习的方法典型的有:朴素贝叶斯(Naïve Bayes,NB)、支持向量机(Support Vector Machine,SVM)、最大信息熵(Maximum Entropy,ME)等。
机器学习方法在处理特定领域语料时有着较高的准确率,但是分类器设计复杂,训练语料标注工作繁琐,同时,当涉及到通用语料时,机器学习往往不能得到较好的效果。而基于语义理解的方法则可以解决这类问题。语义理解的方法从情感词出发,构建文本的情感模型,从而判断出文本的情感倾向性,因此,如何识别情感词是语义理解方法的核心。
目前国内外研究词语倾向性的方法主要分为两种—基于统计学的方法和基于语义理解的方法。基于统计学的方法主要是利用机器学习来获取词语的情感倾向性。
在英文方面,Hatzivassiloglou和McKeown[1]使用监督学习的方法对词语进行情感语义倾向性判别;Turney等[2]利用点互信息(PMI-IR)方法搜索引擎的“NEAR”操作来计算待定词与具有强烈倾向性的种子词集合的关联程度;Yu等[3]挑选出若干极性较强的形容词(情感词)构建一个种子词集合,通过计算新词和种子词的共现概率来判断新词的语义倾向性。在文本情感分类方面,Pang等[4]利用人工标注语料,分别使用朴素贝叶斯、最大熵和支持向量机三种分类模型对影视文本进行分类,Sinno Jialin Pan[5]、Xavier Glorot[6]和Blitzer[7]等众多学者利用领域适应算法分析文本的情感倾向性;Wan[8]利用已有的英文情感语料库完成中文文本的情感分类。基于语义理解的方法主要有基于现存的本体知识库,例如中文的HowNet和英文的Wordnet。在英文处理方面,Jaap等[9]利用WordNet的同义词关系确定形容词的褒贬;Baccianella等[10]基于WordNet构建了认可度最高的SentiWordNet;Maks和Vossen[11]基于词典模型进行情感分析和意见挖掘;在中文处理方面,具有代表性的是朱嫣岚等[12]采用基于HowNet的语义相似度和语义相关场两种方法计算词语的倾向性。同时国内很多学者[13-14]研究建立情感词典来处理观点挖掘等问题,但是到目前为止还没有一部权威的情感词典可供借鉴。
因此文中首先在HowNet知识库定义的四个义原的基础上,人工添加HowNet第五义原—情感义原[15],然后利用改进的HowNet知识库计算词语之间的情感相似度,再融合直推式学习判定情感词极性。
2 融合直推式学习和语义理解的词语倾向性识别
2.1 基于HowNet的情感词判别方法
HowNet语义相似度的方法反映词语语义的相似程度,也即两个词语在不同上下文环境中在词语替换的情况下不改变文本句法语义结构的程度。因此,利用词语的语义相似度概念计算词语的情感值。
HowNet中若词语有多种表达含义,则词语有多个义项,每个义项又由多个义原组成。那么词语的语义相似度计算实际上是义原的相似度计算[16]。
对于两个词语Word1和Word2,假设词语Word1有n个义项Y1,Y2,…,Yn,词语Word2有l个义项Z1,Z2,…,Zl,则词语的相似度计算如式(1)所示:
(1)
将词语相似度的计算转换成概念之间的相似度计算。
2.2 HowNet义原相似度计算
在HowNet中用义原表示词语概念,所以概念相似度计算就是义原相似度计算。
由于所有义原构成了一个树状义原层次体系,因此可以使用公式(2)计算两个义原p1,p2之间的语义距离。
(2)
其中,d是p1和p2在树状义原层次体系中的路径距离;α是一个可调节的参数。
2.3 概念情感相似度计算
在HowNet知识库中概念分成四个义原:“第一基本义原”、“其他基本义原”、“关系义原”和“符号义原”。但是HowNet中的这四种义原的相似度计算没有考虑词语的情感语义。词语概念S1,S2之间的相似度计算如式(3)所示。
(3)
文中在计算情感相似度时引入了情感义原作为词语概念的第五义原,并人工挑选HowNet中的情感词加入第五义原:“desired/良”、“undesired/莠”。
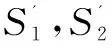
(4)
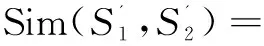
(5)

2.4 基于概念情感相似度的词语情感语义值
计算出词语概念情感相似度之后,结合训练集对测试集中的词语计算情感值。计算方法如式(6)。
(6)
其中,Sentiment(word)表示测试集中词语word的情感值;Sim(word,Set_Pi)表示词语word与褒义训练集Set_Pi的相似性;Sim(word,Set_Nj)表示词语word与贬义训练集Set_Nj的相似性。
2.5 直推式学习
通过上面的基于HowNet的情感词计算方法,可以得到每个词语的情感值。文献[15]中实验证明,该方法可以取得较好的实验效果,因此在此方法的基础上进行进一步研究,将直推式方法融入其中。将每次判定出来的情感词加入到训练集中,如果判定该词语为褒义情感词,则加入到褒义测试集中;如果判定为贬义情感词,则加入到贬义训练集中;若属于中性词,则放回待测测试集中。然后用新的训练集和测试集重复该工作,直到所有词的极性不再改变为止,显而易见,该过程必然是收敛的,直推式算法详细过程如下所示。
Step1:建立训练集和测试集;
Step2:对测试词集利用文中提出的方法计算词语情感值,并判定词语的情感倾向性;
Step3:若待判定词语判定为正面情感词,则从测试集中移动到正面训练集中;若为负面情感词,则从测试集移动到负面训练集中;若为中性词,则将该词放回测试集中等待下一次判定;
Step4:重复Step2-3直到测试集和训练集中的词语不再改变。
3 实验结果及分析
首先构造出初始训练集和测试集。为了达到更好的实验效果,尽量选择极性较强的中文词语作为训练集,具体训练集组成如表1所示,其中褒义贬义各包含20个情感词。

表1 训练集
为了能够达到较好的通用性,文中从新浪、网易、百度三大平台下载新闻语料12 854篇,然后利用中科院分词工具ICTCLAS对文本进行分词处理;再根据停用词表删除停用词;由于词语中只有名词、形容词和动词才存在情感,因此抽取出所有的名词、形容词和动词,最后进行人工调整得到测试集词语共6 961个,其中褒义情感词1 989,贬义情感词2 056,中性词2 916。
对于知网知识库中的词语,人工标注“desired/良”和“undesired/莠”,标注数据如表2所示。
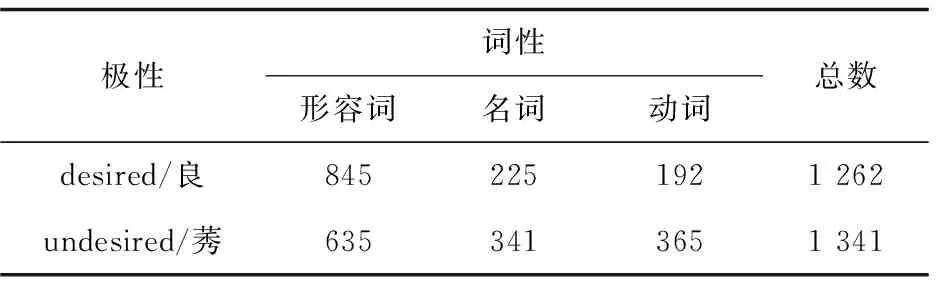
表2 良莠标注情况
对于2.3中的参数,文献[15]中对θ1,θ2设置进行了实验,并根据实验结果发现当设置为0.7和0.3时可以达到最好的实验效果。在HowNet中对参数β1,β2,β3,β4分别设置为:0.5,0.3,0.15,0.05。对2.4中的计算词语情感值的阈值,文献[15]也进行了讲解,并将其设置如式(7)所示。
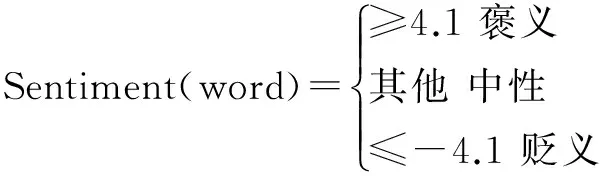
(7)
实验利用三种方法进行验证:支持向量机(SupportVectorMachine,SVM)、原语义理解方法(SemanticComprehension,SC)以及融合直推式学习和语义理解(TransductiveLearning&SemanticComprehension,TL&SC)。利用准确率(Precision)、召回率(Recall)和F(F-measure)值作为判定准则。其中SVM方法中将褒义词、贬义词和中性词平均分成三部分,然后以其中一部分作为训练集,另外两部分作为测试集,依次替换三部分角色。基于篇幅限制,表3列出的SVM结果是循环三次后所取得的平均值。SC和TL&SC方法的实验结果见表4和表5。
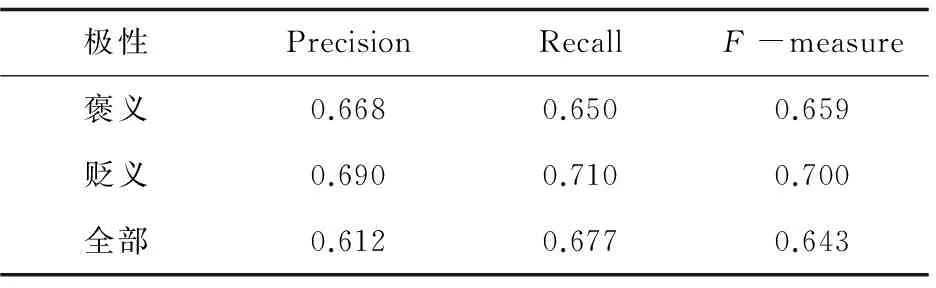
表3 SVM实验结果
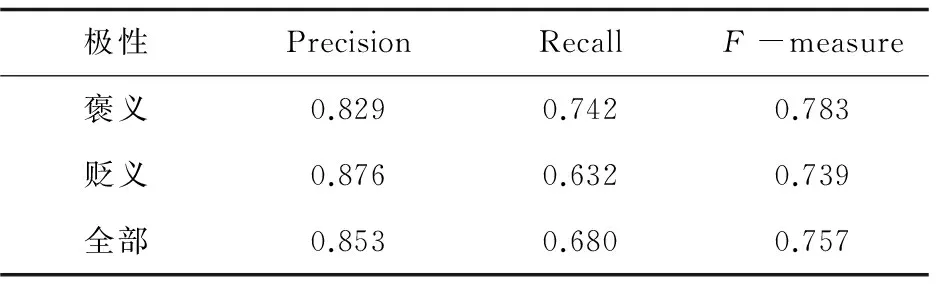
表4 SC实验结果
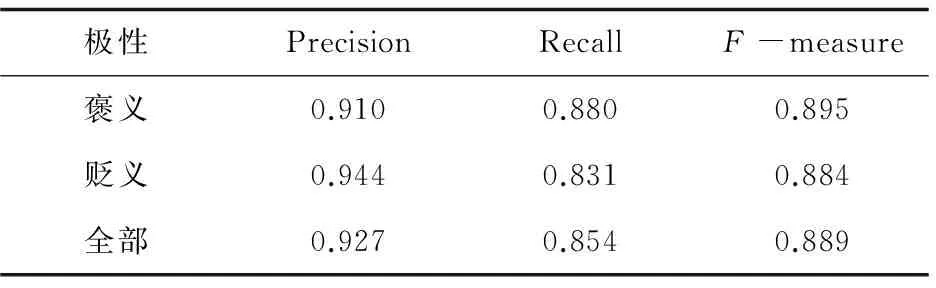
表5 TL&SC实验结果
三个实验数据对比如图1所示。
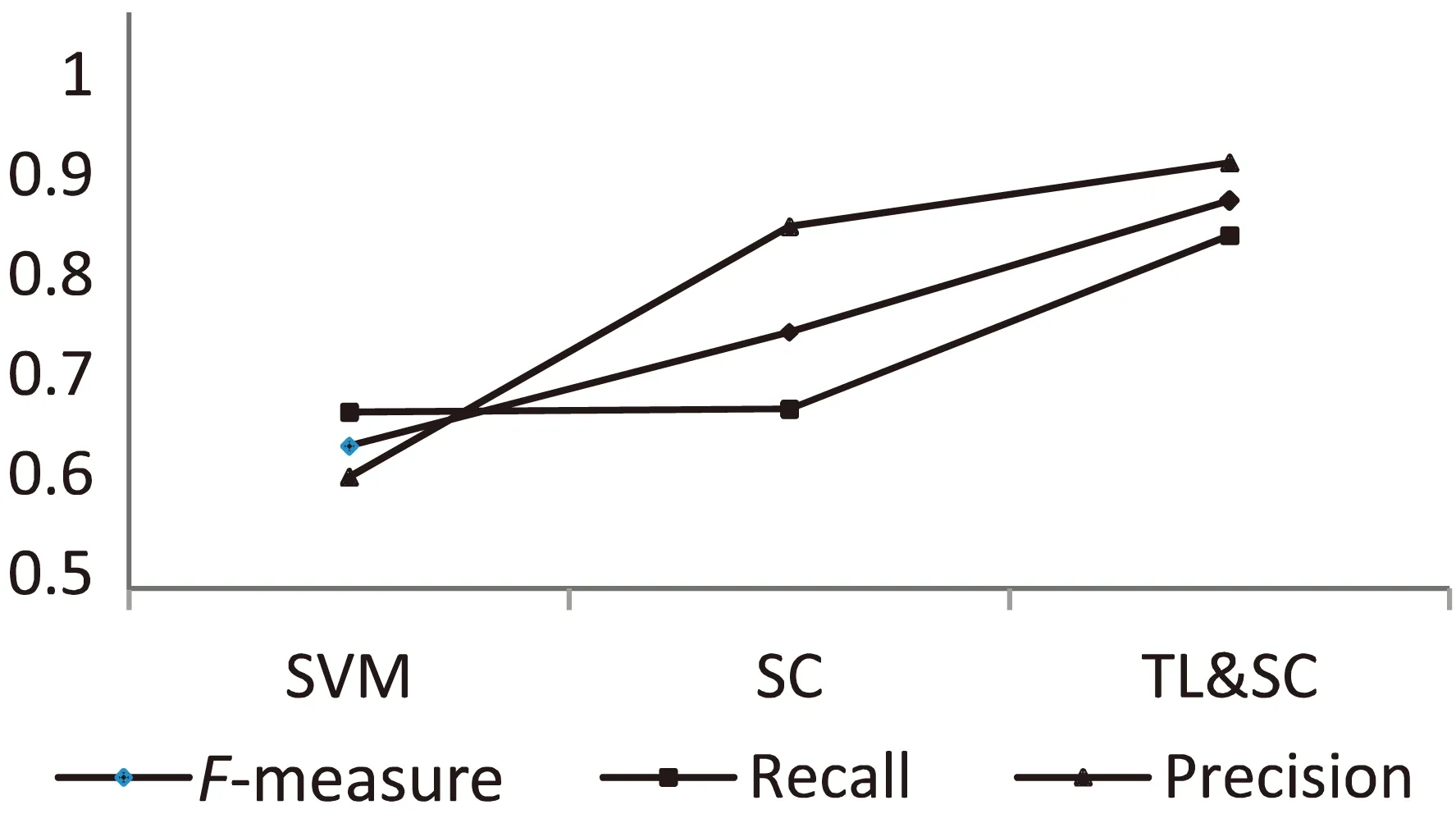
图1 三种方法结果比较
从图中可以很容易看出,在处理通用文本时,SVM方法得分都不是很高;当使用文中提出的SC方法时,准确率有明显提升,但是不足的是召回率不能达到较高效果;最后使用TL&SC时,可以看到,不管是准确率、召回率还是F值,相对于其他两种方法,都达到了较为理想的效果。
4 结束语
文中所提方法利用了HowNet知识库计算词语的情感相似度,然后根据计算得到的词语情感值结合阈值来判断词语的情感倾向性,再将该方法融入直推式学习中。文中针对支持向量机、原语义理解方法和融合语义理解和直推式学习三种方法分别进行了实验,结果表明,针对通用领域获取的词语,第三种方法不论在准确率、召回率还是在F值上都有明显的性能提升。
当然,文中方法也存在不足之处:由于针对单个词语判定情感倾向性,这样势必忽略了特定语义环境下词语的情感倾向性,如何获取这些情感词是未来的研究方向之一;同时文中利用ICTCLAS进行分词、词性标注处理,这样会忽略掉许多网络(非常态)用语,而这些网络用语却表达了极强的极性,如果能结合网络环境判定出这些词语也是未来的重要研究方向。
[1]HatzivassiloglouV,McKeownKR.Predictingthesemanticorientationofadjectives[C]//Proceedingsofthe35thannualmeetingofassociationforcomputationallinguisticsandthe8thconferenceoftheEuropeanchapteroftheACL.[s.l.]:[s.n.],1997:174-181.
[2]PeterT,MichaelL.Measuringpraiseandcriticism:inferenceofsemanticorientationfromassociation[J].ACMTransactionsonInformationSystems,2003,21(4):315-346.
[3]YuHong,HatzivassiloglouV.Towardsansweringopinionqu-estions:separatingfactsfromopinionsandidentifyingthepo-
larityofopinionsentences[C]//ProcofEMNLP-03.Sapporo,Japan:[s.n.],2003:129-136.
[4]PangBo,LeeL,VaithyanathanS.Thumbsup?Sentimentclassificationusingmachinelearningtechniques[C]//Proceedingsofthe2002conferenceonempiricalmethodsinnaturallanguageprocessing.Philadelphia:AssociationforComputationLinguistics,2002:79-86.
[5]PanSJ,NiXiaochuan,SunJiantao,etal.Cross-domainsentimentclassificationviaspectralfeaturealignment[C]//Proceedingsofthe19thinternationalconferenceonWorldWideWeb.[s.l.]:[s.n.],2010:751-760.
[6]GlorotX,BordesA,BengioY.Domainadaptationforlarge-scalesentimentclassification:adeeplearningapproach[C]//Procof28thinternationalconferenceonmachinelearning.Bellevue,WA,USA:[s.n.],2011.
[7]BlitzerJ,DredzeM,PereiraF.Biographies,bollywood,boomboxesandblenders:domainadaptationforsentimentclassification[C]//ProcofACL.[s.l.]:[s.n.],2007:187-205.
[8]WanXiaojun.Co-trainingforcross-lingualsentimentclassification[C]//Proceedingsofthe47thannualmeetingoftheACLandthe4thIJCNLPoftheAFNLP.[s.l.]:[s.n.],2009:235-243.
[9]KampsJ,MarxM,MokkenRJ,etal.UsingWordNettomeasuresemanticorientationofadjectives[C]//Proceedingsofthe4thinternationalconferenceonlanguageresourcesandevaluation.Lisbon,Portugal:[s.n.],2004:1115-1118.
[10]BaccianellaS,EsuliA,SebastianiF.SentiWordNet3.0:anenhancedlexicalresourceforsentimentanalysisandopinionmining[C]//Proceedingsofthe7thconferenceoninternationallanguageresourcesandevaluation.Valletta,Malta:[s.n.],2010:2200-2204.
[11]MaksI,VossenP.Alexiconmodelfordeepsentimentanalysisandopinionminingapplications[J].DecisionSupportSystems,2012,53(4):680-688.
[12] 朱嫣岚,闵 锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[13] 徐琳宏,林鸿飞,杨志豪.基于语义理解的文本倾向性识别机制[J].中文信息学报,2007,21(1):96-100.
[14]WenBin,DaiWenhua,ZhaoJunzhe.Sentencesentimentalclassificationbasedonsemanticcomprehension[C]//Procoffifthinternationalsymposiumoncomputationalintelligenceanddesign.[s.l.]:[s.n.],2012:458-461.
[15] 闻 彬,何婷婷,罗 乐,等.基于语义理解的文本情感分类方法研究[J].计算机科学,2010,37(6):261-264.
[16] 刘 群,李素建.基于《知网》的词汇语义相似度的计算[C]//第三届汉语词汇语义学研讨会.台北:出版者不详,2002.
Identifying of Word Sentiment Orientation of Transductive Learning and Semantic Comprehension
WEN Bin,RAO Bin,ZHAO Jun-zhe,JIAO Cui-zhen,DAI Wen-hua
(College of Computer Science and Technology,Hubei University of Science and Technology,Xianning 437100,China)
At present,the research on word sentiment orientation identification is mainly divided into machine learning and semantic comprehension,but machine learning cannot handle general field words effectively,semantic comprehension also cannot get high scores at precision and recall,therefore,a new fusion method between transductive learning and semantic comprehension for judging word polarity was put forward in this paper.Firstly the HowNet knowledge base system is improved,on the basis of four primitive,the fifth primitive—sentimental primitive was proposed,which was integrated into HowNet manually,on the basis of this,then a new word sentimental similarity calculation method was proposed to compute word’s sentimental value.At last,combine this way with transductive learning for identifying word’s sentimental orientation.The performance of experiment shows that compared with SVM or traditional semantic comprehension,it can get better results.
word sentiment orientation;machine learning;semantic comprehension;opinion mining;sentimental primitive;HowNet
2015-04-20
2015-07-22
时间:2016-01-04
国家自然科学基金面上项目(61373108);湖北省教育厅科研项目(Q20112809,B20082803);湖北省教育厅人文社会科学研究项目(13g389)
闻 彬(1982-),男,讲师,硕士,研究方向为自然语言处理、机器学习。
http://www.cnki.net/kcms/detail/61.1450.TP.20160104.1453.016.html
TP391.1
A
1673-629X(2016)01-0074-04
10.3969/j.issn.1673-629X.2016.01.015
