基于SolrCloud的网络百科检索服务的实现
2016-01-24郝强高占春
郝强++高占春

摘要:网络百科是一部在线百科全书,为用户提供了资源丰富、内容详实的网络查询工具。网络百科检索服务是基于SolrCloud搭建的检索平台,服务部署在集群上,具有集中式的信息配置、自动容错、近实时搜索和查询时自动负载均衡的特点。本文介绍了SolrCloud平台的搭建方案,结合数据特点设计了索引结构,增加了中文分词器和中文词表,提高了在创建索引和检索索引过程中的中文分词效果。在SolrCloud平台基础上,本文根据搜索引擎原理提出了搜索引擎优化方案,进一步提升了搜索效果。通过在创建索引时对关键字段设置多颗粒度分词模式,在检索索引时对不同颗粒度分词设置不同的权重,提高检索效果;通过挖掘数据内在的引用关系为文档质量评分,提高优质文档在搜索结果中的排名。实验数据表明,优化方法对网络百科检索服务效果有很大的提升。
关键词:计算机软件;搜索引擎优化;SolrCloud;中文分词
中图分类号:TP311
文献标识码:A
DOI:10.3969/j.issn.1003-6970.2015.12.024
本文著录格式:郝强,高占春.基于SolrCloud的网络百科检索服务的实现[J].软件,2015,36(12):103-107
0 引言
1.网络百科是一个包罗万象的在线百科全书,涉及经济、政治、文化等各个方面。网络百科的主体为词条,分为中文和英文,由千万量级的词条构成了庞大的知识库,具有很强的知识性和科普价值,同时又鼓励用户参与创建和修改词条,使网络百科在丰富权威的同时,也具有趣味性和快更新的特点。
2.在海量的数据中,按照用户的需求高效、准确地检索出词条和同条内容是一项极具挑战的任务。搜索引擎技术可以通过对数据文档创建索引,实现对相关查询的高效快速检索,为用户返回相当数量的排序搜索结果。并且可以根据实际的数据特点,通过多种手段对搜索引擎的进行优化,提高搜索结果的准确率。
3.在处理大规模数据时,不但需要考虑检索的效果,也需要考虑计算机的运算能力和故障风险。分布式搜索技术在集群上搭建服务,通过负载均衡降低了机器的运算负担,通过并行计算提高了集群的运算能力,通过分布式存储提高了整个集群的容灾能力。
4.本文使用SokCloud搭建分布式搜索引擎,为海量数据提供了高效准确的检索服务,并提出了优化搜索的方法,实验数据表明优化方法有效提高了搜索的准确率。
l SolrCloud介绍
Solr是一个基于Lucene的全文搜索服务器。Solr与Lucene相比,提供了更为丰富的查询语言,提供了提供了基于Http的可返回json、xml等格式的接口。Solr提供了配置接口和扩展接口,并能对查询性能进行优化。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,SolrCloud将服务部署在集群上,通过Zookeeper进行集群管理。SolrCloud在Solr的功能基础上,具有4个新特性,包括集中式的配置信息,自动容错,近实时搜索和查询时自动负载均衡。SolrCloud为大数据量检索提供了良好的解决方案。
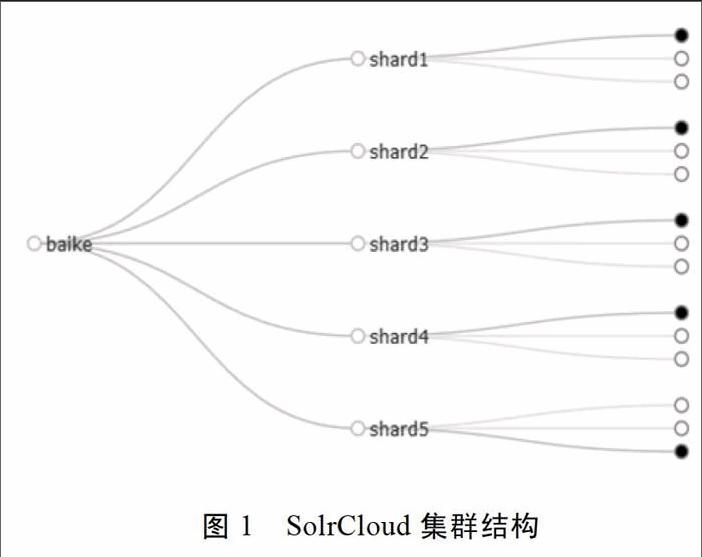
SolrCloud集群中collection是一个逻辑意义上的完整索引。一个collection通常被分成一个或多个shard,同一个collection的所有shard具有相同的配置。一个shard有一个或多个replica作为副本,每个shard的replica中会选举出一个leader。
2 SolrCloud部署
2.1 SolrCloud搭建
网络百科检索服务使用的是solr-5.2.1版本,solr-5.2.1需要运行在jdkl.7及以上版本。分析网络百科数据量大小,以及自动容错和负载均衡的需要,网络百科检索服务创建了名为baike的collection,baike分为5个shard,每个shard有3个replica。SolrCloud管理页面展示的集群结构见下图。
搜索服务部署在5台机器上,每台机器分配4G内存和16G存储空间。分别在5台机器上部署solr-5.2.1,在一台机器的configsets目录下创建属于网络百科检索服务的配置目录baike_configs,并在该机器上启动SolrCloud创建baike实例,在其余4台机器上启动SolrCloud并加入该baike实例。这5台机器组成了SolrCloud集群。
2.2 分词器和词表
网络百科检索服务是基于词的倒排索引的查询。词是表达语义的最小单元,对于以英文为代表的的西方拼音语言来说,词之间有明显的分界符,英文以空格作为天然的分隔符。与西方拼音语言不同,中文继承于古代汉语传统,词之间没有明确的分隔符。古代汉语中词通常就是单个字,而现代汉语中双字或多字居多。因此,中文搜索服务在索引创建和索引检索之前,需要对文本中的句子进行分词,然后才能做相应的其他处理。
分词器的分词效果直接影响了创建索引的内容以及检索的准确度。中文分词算法可分为三大类:基于字典、词库匹配的分词方法;基于词频度统计的分词方法和基于知识理解的分词方法。目前,成熟的中文分词器主要有IKAnalyzer、Paoding、MMSEG、ICTCLAS等。其中,IKAnalyzer和Paoding是基于字符串匹配的分词器,加入一些启发式规则,比如“正向/反向最大匹配”、“长词优先”等策略优化。ICTCLAS分词理论使用的模型是层叠隐马尔可夫模型,该分词器除了具有中文分词和词性标注功能外,还支持新词识别。
通过对分词器的分词效果、执行效率和是否符合SolrCloud接口的综合考量,在网络百科检索服务选择了MMSEG分词器。MMSEG由Chih-Hao Tsai开发,使用了加入3段回溯式方法的基于词表的分词。MMSEG提供了三种模式,simple、max-word和complex。网络百科检索服务使用了细颗粒度分词的max-word模式和加入了四个过滤规则的粗颗粒度分词的complex模式。并收集整理了自定义词表。关于增加中文分词器的schema.xml配置如下。
2.3 网络百科索引
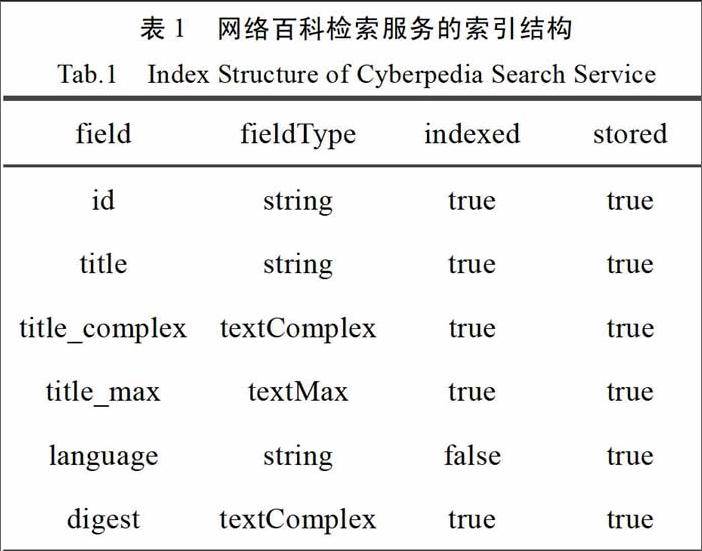
网络百科的数据结构为词条标题、词条摘要、词条正文、词条语言和词条图片,在数据库中存储的对应字段为title、digest、content、1anguage、picture。结合网络百科的数据结构,设计的索引数据结构见下表。
表l中,field列是索引中的字段名,fieldType列是索引中该字段的处理类型,indexed为布尔值,代表该字段数据是否被用来建立索引,stored为布尔值,代表该字段数据是否存储。其中title对应词条标题,language对应词条语言,digest对应词条摘要。
与词条的字段结构相比,索引字段中增加id字段,作为SolrCloud创建索引的唯一标识字段,同时需要在schema.xml中将该id字段配置成uniqueKey。
索引字段中添加title_complex和title_max字段,这两个字段是对title字段数据的复制,目的是实现对title字段的多颗粒度的分词,为此需要在schema.xml中增加配置如下。
3 SolrCloud优化
3.1 优化概述
检索服务本质上是索引创建和索引检索的过程。在海量的网络资源中,每一个网页都是一个文档。在创建索引的时候,首先将每一个文档进行分词得到词,然后按词生成倒排索引,倒排索引中存储了文档编号,也就是2.3节中的id字段。用户在查询时输入查询内容。在检索索引的时候,首先将用户的查询内容进行分词得到词,然后按词在倒排索引中进行检索,最后对检索结果处理,对检索出的文档进行评分,按照评分对检索结果排名,将最终结果返回给用户。
评分越高,说明文档内容与用户查询的相关性越高。每个文档由词组成,每个词有一个权重,那么一个文档中的所有词可以组成一个向量,表达式如下。
将每一个词作为N维空间中的一维,将网络百科检索服务中的文档中词组成的词向量与用户输入查询内容中的词组成的词向量放在N维空间中,比较不同文档的词向量与查询的词向量的夹角。
文档与查询的相关性大小可以使用文档的词向量与查询的词向量之间的夹角大小表示。文档的词向量与查询的词向量之间夹角越小,文档的相关性越大。向量夹角可以使用余弦定理计算出来,计算公式如下。
结合以上公式和分析,从以下几点对SolrCloud搭建搜索服务进行优化。
(1)对文档和查询语句进行准确地分词;
(2)对关键字段使用多颗粒度分词模式;
(3)对文档内容进行评分,提高优质文档在搜索结果中的排名。
其中,(l)已经在2.2节介绍。
3.2 多颗粒度查询
多颗粒度是指对语句分词时切分的词的粒度的大小。颗粒度大,平均词的字数较多,语句分词后词的数量较少;相反,颗粒度小,平均词的字数较少,语句分词后词的数量较多。在汉语中,词是表达意思最基本的单位,但是不同的人对于词的颗粒度理解是不同的。例如,某个语句中出现了“联想公司”,有些人会将“联想公司”看作一个整体,这是粗颗粒度分词;有些人会认为“联想”是修饰“公司”的定语,那么分词为“联想”和“公司”两个词,这是细颗粒度分词。
通常,粗颗粒度的词会携带更多的信息,在消除不确定性上发挥更大的作用。粗颗粒度的词在语义上更加明确。虽然粗颗粒度的词有诸多好处,但是在检索服务的实现中,并不能只使用这一种分词方法。比如在创建索引时将“清华大学”看作一个整体,那么用户在搜索“清华”时就无法找到“清华大学”的文档。
在网络百科检索服务的设计中对关键字段title进行了多颗粒度的分词,通过字段的复制方法将title复制成title_complex和title max,并分别使用了完全匹配模式分词、MMSeg的complex模式的粗颗度分词和MMSeg的max模式的细颗粒度分词。同时,对于不同分词模式的结果,在评分阶段给以不同的权重。因为不同颗粒度的词所表达的信息量不同,通常粗颗粒度的词会携带更多的信息,所以完全匹配模式的分词给以最高的权重,complex模式的分词次之,max模式的分词给以最小的权重。分词的颗粒度对查询结果排名影响的计算公式如下
公式(4)中,coord(query,doc)表示一个文档中包含查询词的数量,表示了该文档与查询语句的相关性。文档中包含查询词的数量越多,coord(query,doc)的分数越高,导致搜索结果的评分score(query,doc)越高。term.getBoost()表示了查询内容中每种颗粒度的分词对查询结果的影响。根据上面介绍的设置不同分词模式的权重,不同分词颗粒度对评分的影响大小也是不同的。颗粒度越大,term.getBoost()的分数越高,导致搜索结果的评分score(query,doc)越高。所以完全匹配模式的评分对最终评分的影响最大,粗颗粒度分词模式对最终评分的影响次之,细颗粒度分词模式对最终评分的影响最小。
3.3 文档评分
搜索结果的好坏即取决于查询与网页的相关性,也取决于网页的质量。在网络百科检索服务的设计中,通过文档之间的相互引用关系来评价词条内容的质量。网络百科中的词条都经过专业编辑,词条的内容是可靠的,所以一个词条被越多的文档引用,那么它的内容就越重要,所获得的评分就会越高。该词条的评分会影响到搜索结果的评分,最终影响词条在搜索结果中的排名。
网络百科检索服务是通过solr4j编写程序创建索引的。首先,使用分布式并行运算统计出词条的被引用情况并加以处理;然后创建索引时,为每个词条的SolrInputDocument对象,通过setDocument Boost()方法将处理后的文档质量评分存入索引。
文档评分会影响搜索结果中文档的排名,搜索结果评分的计算公式如下。
公式(5)中doc.getBoost()表示文档评分。文档评分越高,在搜索结果的评分也会越高。
3.4 实验结果
在搭建了SolrCloud平台基础上,从三个方面对网络百科检索服务进行优化,以提高搜索效果。增加分词器和词表,提高对文档和查询内容的分词效果;设置分词的多种模式,并在检索时对不同分词颗粒度设置不同的权重;对文档质量进行打分,提高优质文档在搜索结果中的排名。通过实验,上述三种方法有效提高了网络百科检索服务的搜索效果。实验结果见下图。
在实验中,通过比较不同优化方法对搜索准确率的影响来评估对搜索效果的影响。在无优化的搜索实验中,搜索的准确率为56.2%。在分词优化的实验中,对SolrCloud增加了中文分词器和多种颗粒度分词,搜索的准确率为80.6%,比无优化的搜索准确率提高了43.4%。在分词+评分优化的实验中,不但增加了中文分词器和多种颗粒度分词,还对文档质量进行评分,评分结果影响查询搜索的排名,该种方法实验中搜索的准确率为85.3%,比无优化的搜索准确率提高了51.8%。实验数据表明,对SolrCloud的优化方法对搜索效果有较大提升,最终的搜索结果准确率更高。
4 结论
网络百科检索服务使用SolrCloud搭建检索海量网络百科数据的平台,为用户提供了高效优质的查询功能。结合网络百科的数据字段设计了索引的结构,分析了搜索引擎原理并提出了优化检索服务的方法,为SolrCloud增加了中文分词器和词表,结合实际数据设置了多种颗粒度分词模式,挖掘数据内在引用关系为文档质量评分。优化方法有效提高了SolrCloud的搜索效果。
