基于Hadoop的大数据增量计算探讨
2016-01-15王剑宇刘凤良姜薇
王剑宇 刘凤良 姜薇
摘要:增量计算是针对许多在线大数据集每隔一段时间都会因为新数据添加进来产生缓慢增长,需要对整个数据集重新计算,导致效率低和计算资源浪费的问题提出的。文章通过分析增量计算的一般模式,参考已有增量计算系统的思想,探讨了如何基于开源大数据处理框架Hadoop,依托其最新的YARN模式架构具有通用性的增量计算系统。
关键词:增量计算;结果缓存复用;Hadoop;YARN
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2015)18-0008-03
1.概述
很多在线大数据集每隔一段时间都会因为新的数据添加进来产生缓慢增长,并且已有的数据也会删除或者修改。当数据集发生变动后,需要对其重新进行计算,考虑到有时变动只是很小的一部分,或者对之前的计算结果影响很小等这类情况,若为此就对变动后的整个数据集全部进行计算必然存在效率低下和计算资源浪费的问题。就是针对这一问题提出的。增量计算的思路是每次只针对新增加的内容和其影响到的旧计算结果重新进行计算,之前计算的结果大部分是可以复用的,这可以减少计算资源的使用,同时也提高了效率。
2.增量计算的一般模式及现有典型系统
2.1增量计算模式
增量计算的模式主要有两大类,即“结果缓存复用”和“变化传播”。“结果缓存复用”模式在设计技术方案时,是从那些计算结果没有发生改变的旧数据的角度考虑的,将这些旧的结果存储起来,致力于对其最大化的复用。“变化传播”模式是从新数据和受影响的旧数据这个角度设计方案的,首先计算新数据的结果,然后判断受其影响的旧数据有那些,然后重新计算其结果,在这个结果的基础上再去判断那些旧结果会受到影响,若影响达到一个阈值,那就重新计算,迭代这个过程,完成增量计算。
2.2现有典型系统简介
增量计算在很多场景下可以很大的提高计算效率。现有典型的增量系统根据依赖的计算平台可以分为两类,一类是基于自建平台的,如Google的Percolator、Microsoft的Kineograph和DryadInc;另一类是基于Hadoop平台的,如:Yahoo的CBP、基于Hadoop 1.x的Incoop和IncMR等。Percolator和Kineograph属于“变化传播”模式,Dryadlnc、CBP和Incoop属于“结果缓存复用”模式。
Percolator是Google在2010年6月上线的用于更新索引的“咖啡因”系统的项目名,其实质是建立在Bigtable上的一种和MapReduce计算方式互补的增量计算模式。全局性的统计,用MapReduce来做,而局部的更新用Percolator。Kineograph是一个支持增量计算的分布式准实时流式图挖掘系统。当连续不断的数据流人系统后,不用每次都对所有数据重新计算,而是用增量计算对挖掘结果进行更新。Dryadlnc是建立在DGA批处理系统Dryadf上的增量计算系统,它是将上次的计算结果存储到缓存服务器中,下次计算时先到缓存中去找可复用的结果,而不是重新计算,这种方式可以显著的提高计算速度。
以上这类方案主要是科技巨头企业依托自身的软硬件资源,针对自己特定的业务需求构建的,不具有通用性,难以复制,我们只能借鉴其设计思想。相对的,互联网上一些基于开源软件平台的增量计算解决方案更具操作性和可用性,如采用较为复杂的技术对Hadoop进行改造的Incoop和IncMR,但是由于其基于Hadoopl.x,具有明显缺陷,架构的灵活性和效率不是很好。所以设计一个可扩展、可维护的基于开源平台的增量计算系统是有研究和应用价值的。
3.Hadoop的机制及实现增量计算的构想
3.1Hadoop框架
Hadoop是一个开源软件框架,用来开发和处理大规模数据,其最核心的设计包括用来存储海量数据的HDFS和对数据进行计算的MapReduce。目前在大数据技术的应用和研究领域,Hadoop是主流的基础软件平台,发展迅速,最新的版本是2.x系列,加入了YARN、NameNode Federation和HA等新特性,为实现增量计算提供了一个支撑环境。
1)HDFS
是指分布式文件存储系统,即Hadoop Distributed Filesystern,在实际存储时,首先将不同大小的文件切割成固定大小的数据块,然后由主控服务器统一分配存储管理。
2)MapReduce和YARN
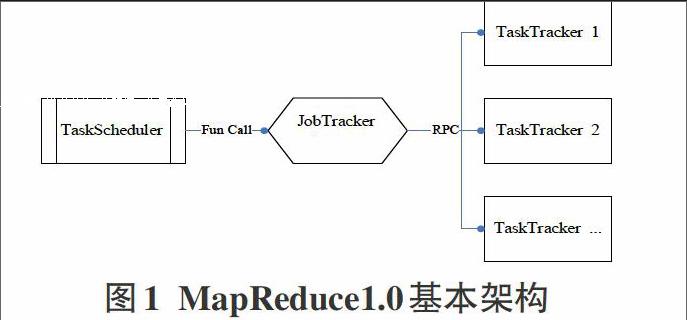
MapReduce是Hadoop的计算框架,其基本架构如图1,这种模式也被称为MapReduce1.0版本,其中最核心的是JobTracker,它是集群的“管理者”,负责作业管理、状态监控、任务调度器等功能。同时作为集群事务的集中处理点的JobTracker,需要完成的任务太多,最大的问题是存在单点故障,造成过多的资源消耗和资源利用不足。
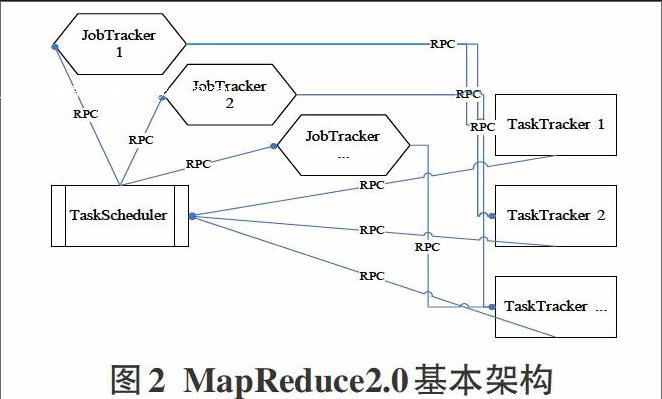
Yarn是MapReduce2.0版本,最大的变化是将JobTracker的两个主要功能资源管理和作业控制拆分成两个独立的进程。
资源管理进程负责整个集群的cpu、储存等资源管理,与具体应用程序无关;作业控制进程与应用程序相关,一个作业控制进程只负责一个作业。如图2所示,YARN可以说是一个资源统一管理平台,其不局限于MapReduce一种计算模型,而是可以融人多种计算框架,并对这些框架统一管理调度,如果想加入一个新的计算框架,就把该框架分装成一个Application—Mastero
3.2基于Hadoop YARN实现增量计算的构想
现有典型的基于Hadoop的开源增量系统架构有2011年的Incoop和2012年的Incmr,存在的问题主要是他们基于的软件平台是Hadoop1.0,并且对软件底层框架进行了复杂的修改,导致系统的不易扩展,同时继承了MapReduce V1.0的缺点。通过吸取这些系统当中有益的设计思想,并基于Hadoop2.x这个平台,使得构建一个低人侵性、可维护扩展、透明和高效的增量系统成为可能。
